
 This post introduces the adaptive routing technology for NVIDIA Spectrum Ethernet and provides preliminary performance benchmarks.
This post introduces the adaptive routing technology for NVIDIA Spectrum Ethernet and provides preliminary performance benchmarks.
The NVIDIA accelerated AI platforms and offerings such as NVIDIA EGX, DGX, OVX, and NVIDIA AI for Enterprise require optimal performance out of data center networks. The NVIDIA Spectrum Ethernet platform delivers this performance through chip-level innovation.
Adaptive routing with RDMA over Converged Ethernet (RoCE) accelerates applications by reducing network congestion issues. This post introduces the adaptive routing technology for NVIDIA Spectrum Ethernet and provides some preliminary performance benchmarks.
What is slowing my network down?
You do not have to be a cloud service provider to benefit from scale-out networking. The networking industry has already figured out that traditional network architectures with Layer 2 forwarding and spanning trees are inefficient and struggle with scale. They transitioned to IP network fabrics.
This is a great start, but in some cases, it may not be enough to address the new type of applications and the amount of traffic introduced across data centers.
A key attribute of scalable IP networks is their ability to distribute massive amounts of traffic and flows across multiple hierarchies of switches.
In a perfect world, data flows are completely uncorrelated and are therefore well distributed, smoothly load balanced across multiple network links. This method relies on modern hash and multipath algorithms, including equal-cost multipath (ECMP). Operators benefit from high port count, fixed form-factor switches in data centers of any size.
However, there are many cases where this does not work, often including ubiquitous modern workloads like AI, cloud, and storage.
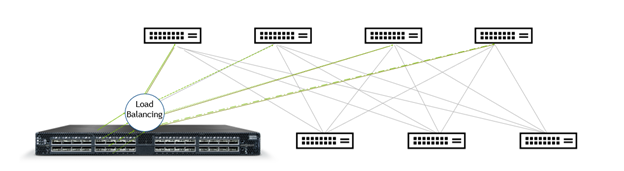
The issue is the problem of limited entropy. Entropy is a way of measuring the richness and variety of flows traveling across a given network.
When you have thousands of flows that are randomly connected from clients around the globe, your network is said to have high entropy. However, when you have just a few large flows, which happens frequently with AI and storage workloads, the large flows dominate the bandwidth and therefore have low entropy. This low entropy traffic pattern is also known as an elephant flow distribution and is evident in many data center workloads.
So why does entropy matter?
Using legacy techniques with static ECMP, you need high entropy to spread traffic evenly across multiple links without congestion. However, in elephant flow scenarios, multiple flows can align to travel on the same link, creating an oversubscribed hot spot, or microburst. This results in congestion, increased latency, packet loss, and retransmission.
For many applications, performance is dictated not only by the average bandwidth of the network but also by the distribution of flow completion time. Longtails or outliers in the completion time distribution may decrease application performance significantly. Figure 2 shows the effect of low entropy on flow completion time.
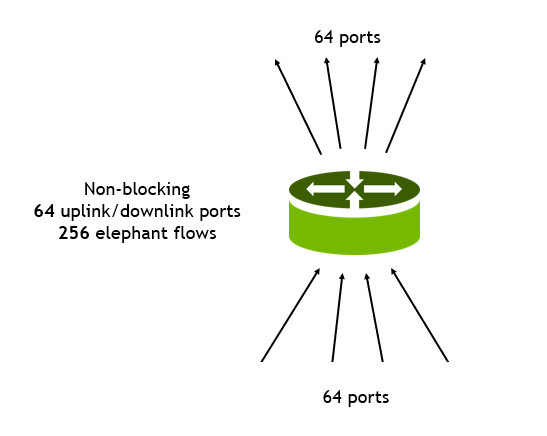
This example consists of a single top-of-rack switch with 128 ports of 100G.
- 64 ports are 100G downstream ports connecting to servers.
- 64 ports are 100G upstream ports connecting to Tier 1 switches.
- Each downstream port receives traffic of four flows of equal bandwidth: 25G per flow for a total of 256 flows.
- All traffic is handled through static hashing and ECMP.
In the best case, the bandwidth available for this configuration is not oversubscribed so the following results are possible. In the worst-case scenario, flows can take up to 2.5x longer to complete compared to the ideal (Figure 3).
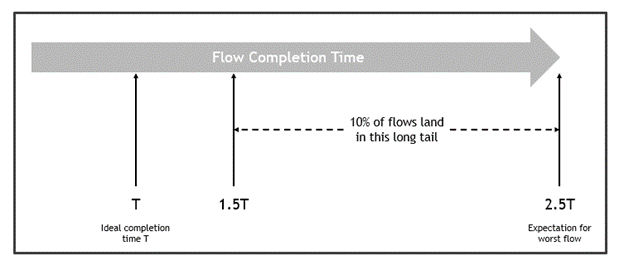
In this case, a few ports are congested while others are unused. The last-flow (worst flow) expected duration is 250% of the expected first-flow duration. In addition, 10% of flows suffer from an expected flow completion time of more than 150%. That is, there is a long tail of flows where the completion time is longer than expected. To avoid congestion with high confidence (98%), you must reduce the bandwidth of all flows to under 50%.
Why are there many flows that suffer from high completion time? This is because some ports on the ECMP are highly congested. As flows finish transmission and release some port bandwidth, the lagging flows pass through the same congested ports, causing more congestion. This is because routing is static after the header has been hashed.
Adaptive routing
NVIDIA is introducing adaptive routing to Spectrum switches. With adaptive routing, traffic forwarding to an ECMP group selects the least-congested port for transmission. Congestion is evaluated based on egress queue loads, ensuring that an ECMP group is well-balanced regardless of the entropy level. An application that issues multiple requests to several servers receives the data with minimal time variation.
How is this achieved? For every packet forwarded to an ECMP group, the switch selects the port with the minimal load over its egress queue. The queues that are evaluated are those that match the packet quality of service.
By contrast, traditional ECMP makes the port decision based on the hashing method, which often fails to yield a clear comparison. As different packets of the same flow travel through different paths of the network, they may arrive out of order to their destination. At the RoCE transport layer, the NVIDIA ConnectX NIC takes care of the out-of-order packets and forwards the data to the application in order. This renders the magic of adaptive routing invisible to the application benefiting from it.
On the sender side, ConnectX can dynamically mark traffic for eligibility to network re-ordering, thus ensuring that inter-message ordering can be enforced when required. The switch adaptive routing classifier can classify only these marked RoCE traffic to be subjected to its unique forwarding.
Spectrum adaptive routing technology supports various network topologies. For typical topologies such as Clos (or leaf/spine), the distance of the various paths to a given destination is the same. Therefore, the switch transmits the packets through the least congested port. In other topologies where distances vary between paths, The switch prefers to send the traffic over the shortest path. If congestion occurs on the shortest path, then the least-congested alternative paths are selected. This ensures that the network bandwidth is efficiently used.
Workload results
NEEDS LEAD-IN SENTENCE
Storage
To verify the effect of adaptive routing in RoCE, we started by testing simple RDMA write test applications. In these tests, which ran on multiple 50 Gb/s hosts, we divided the hosts into pairs, and each pair sent each other large RDMA write flows for a long period of time. This type of traffic pattern is typical in storage application workloads.
Figure 4 shows that the static, hash-based routing suffered from collisions on the uplink ports, causing increased flow completion time, reduced bandwidth, and reduced fairness between the flows. All problems were solved after moving to adaptive routing.
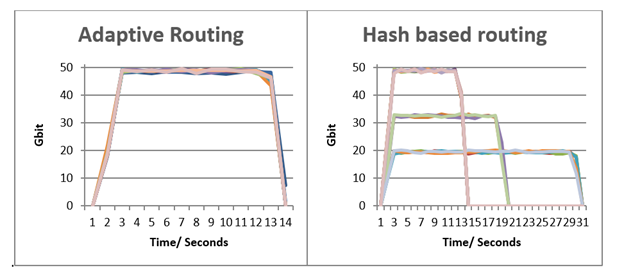
In the first graph, all flows completed at approximately the same time, with comparable peak bandwidth.
In the second graph, some of the flows achieved the same bandwidth and completion time, with other flows colliding, resulting in longer completion times and lower bandwidth. Indeed, in the ECMP case, some flows completed in an ideal completion time T of 13 seconds, while the worst-performing flows took 31 seconds, approximately 2.5x of T.
AI/HPC
To continue with evaluating adaptive routing in RoCE workloads, we tested the performance gains for common AI benchmarks on a 32-server testbed, built with four NVIDIA Spectrum switches in a two-level, fat-tree network topology. The benchmark evaluates common collective operations and network traffic patterns found in distributed AI training and HPC workloads, such as all-to-all traffic and all-reduce collective operations.
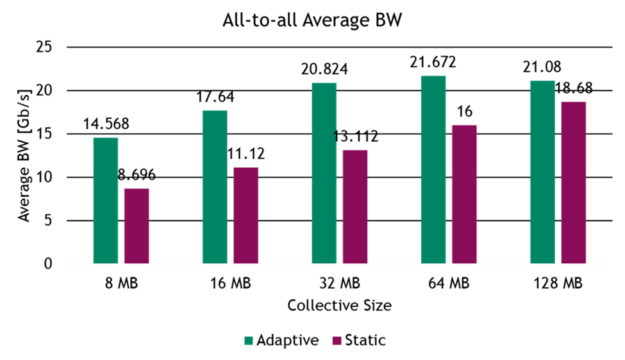
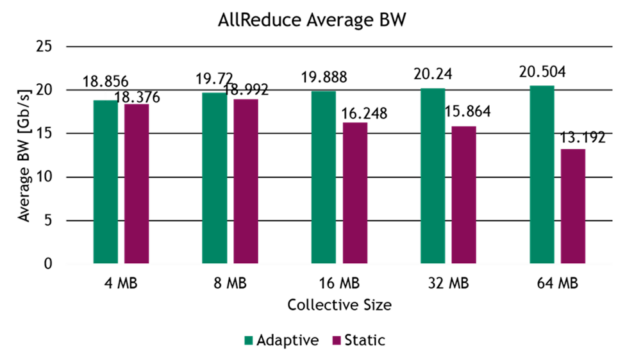
Summary
In many cases, forwarding based on static hashes leads to high congestion and variable flow completion time. This reduces application-level performance.
NVIDIA Spectrum adaptive routing solves this issue. This technology increases the network’s used bandwidth, minimizes the variability of the flow completion time and, as a result, boosts the application performance.
Combining this technology with RoCE Out Of Order support from NVIDIA ConnectX NICs, the application is transparent to the technology used. This ensures that the NVIDIA Spectrum Ethernet platform delivers the accelerated Ethernet needed for maximum data center performance.