
") Cloud computing is designed to be agile and resilient to deliver additional value for businesses. China Mobile (CMCC), one of China’s largest telecom operators and cloud services…
Cloud computing is designed to be agile and resilient to deliver additional value for businesses. China Mobile (CMCC), one of China’s largest telecom operators and cloud services…
Cloud computing is designed to be agile and resilient to deliver additional value for businesses. China Mobile (CMCC), one of China’s largest telecom operators and cloud services providers, offers precisely this with its Bigcloud public cloud offering.
Bigcloud provides PaaS and SaaS services tailored to the needs of enterprise cloud and hybrid-cloud solutions for mission-critical applications. CMCC understands that businesses rely on their networking and communication infrastructure to stay competitive in an increasingly always-on, digital world.
When they started experiencing enormous demand for their cloud-native services, CMCC turned to network abstraction and virtualization through Open vSwitch (OVS) to automate and gain dynamic network control of their network, assisting in handling their growing demand.
However, maintaining network performance due to the added east-west network traffic became a serious challenge.
Identifying the network challenges
With the massive adoption of cloud services, CMCC experienced enormous growth in its virtualization environment. This virtual sprawl produced an explosion of east-west traffic between servers within their data centers.
Due to the rise in network traffic, they also saw an increase in network congestion, causing higher jitter and latency and hindering overall network throughput and application performance. This was causing insufficient effective bandwidth and they were unable to keep up with the large number of network flows during peak business times.
As CMCC investigated the cause of these challenges, they determined that the root of these problems stemmed from four main issues with the Open vSwitch:
- Inefficient vSwitch capacity for VXLAN encapsulation and decapsulation rule handling due to the server CPUs being tasked with both application and networking requests.
- Poor performance of kernel-based vSwitch forwarding caused by frequent context switching between user space, kernel space, and memory, which created data copying overhead.
- DPDK-based vSwitch forwarding created competition for server CPU resources, which were already severely limited.
- Limited vSwitch flow rule capabilities due to lowered throughput due to excessive packet loss, jitter, and latency.
These challenges became a bottleneck and prevented applications from receiving the high network traffic throughput they required at the lowest possible latency.
While OVS allows for packets and flow rules to be forwarded between hosts as well as the outside world, it’s CPU-intensive and affects system performance by consuming CPU cores that should be used for customer applications and prevents full utilization of available bandwidth.
CMCC wanted to ensure network application response times stayed low, that delivered bandwidth was consistent, and that they were able to meet peak demands.
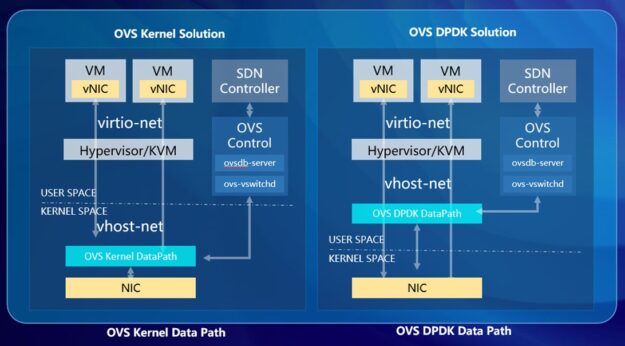
CMCC turned to two experts in this area, NVIDIA and Nokia, who jointly provided a highly efficient, software-defined networking (SDN) solution. The solution combines the offloads, performance, and efficiency of NVIDIA ConnectX SmartNIC and the NVIDIA BlueField data processing unit (DPU) technology with the agility, elasticity, and automation of the Nuage Networks Virtualized Services Platform (VSP).
Together, NVIDIA and Nuage offload the computationally intensive packet processing operations associated with OVS and free costly compute resources so they can run applications instead of SDN tasks.
SmartNIC– and DPU-powered accelerated networking
The NVIDIA ConnectX series of SmartNICs and BlueField series of DPUs offer NVIDIA Accelerated Switching and Packet Processing (ASAP2) technology, which runs the OVS data plane within the NIC hardware while leaving the OVS control plane intact and completely transparent to applications.
ASAP2 has two modes. In the first mode, the hardware data plane is built on top of SR-IOV virtual functions (VFs) so that each network VF is connected directly to its corresponding VM.
An alternate approach that is also supported is VirtIO acceleration through virtual data path acceleration (vDPA). VirtIO allows virtual machines native access to hardware devices such as the network adapters, while vDPA allows the connection to the VM to be established with the OVS data plane built between the network device and the standard VirtIO driver through device queues called Virtqueue. This enables seamless integration between VMs and accelerated networking, with the control plane to be managed on the host whereas the VirtIO data plane is accelerated by smartNIC hardware.
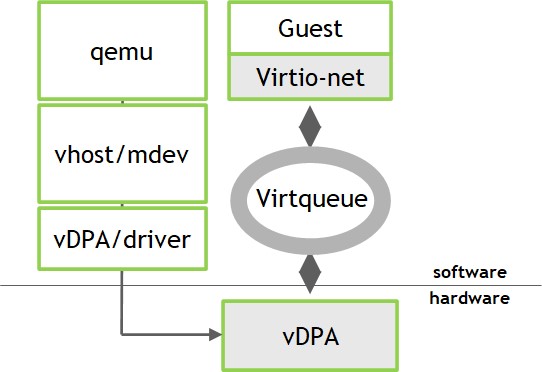
Seamless integration of Nuage Networks SDN with NVIDIA vDPA technology
Nuage Networks contribution to the solution is through their Virtualized Services Platform (VSP). VSP performs the virtual routing and switching and is the distributed forwarding module based on Open vSwitch, serving as a virtual endpoint for network services. VSP immediately recognizes any changes in the compute environment, triggering instantaneous policy-based responses in network connectivity and configuration to ensure application performance.
Nuage Networks’ VSP uses tunneling protocols such as VXLAN to encapsulate the original payload as an overlay SDN solution.
Because standard NICs don’t recognize new packet header formats, traditionally all packet manipulation operations must be performed by the CPU, potentially over-taxing the CPU and causing significant network I/O performance degradation, especially as server I/O speeds increase.
For this reason, overlay network processing needs to be offloaded to an I/O-specific hardware adapter that can handle VXLAN, like ConnectX or BlueField, to reduce CPU strain.
Performance advantages of vDPA
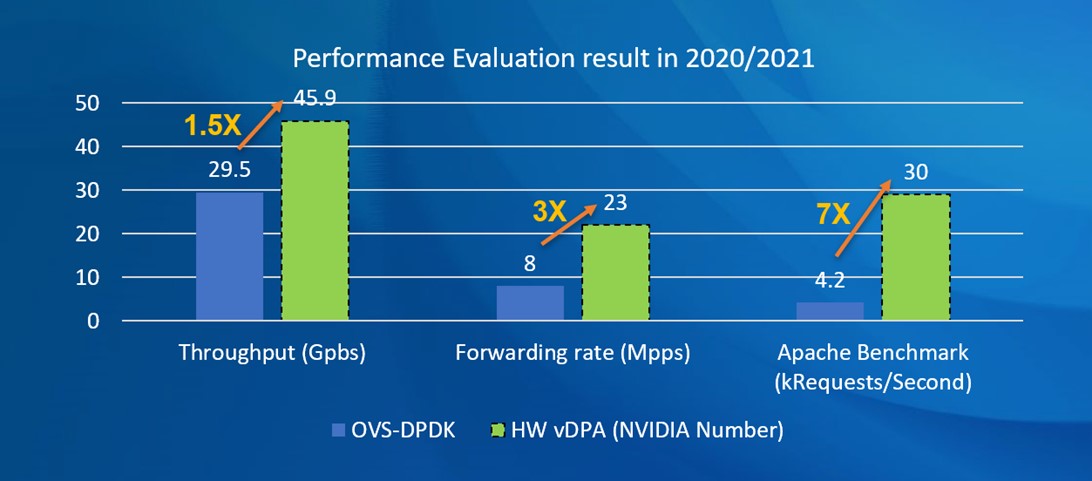
China Mobile decided to go with the VirtIO solution for maximum compatibility, and they wanted the ability to choose either straight OVS or OVS DPDK, depending on the use case. Working together, Nuage Network and NVIDIA delivered an SDN solution for China Mobile’s public cloud that is agile, scalable, and hardware-accelerated and which supports both types of network virtualization.
The joint solution using Nuage Networks VSP with NVIDIA hardware-accelerated vDPA delivered significantly faster performance. The network throughput increased by 1.5x, the packet forwarding rate was 3x faster, and the Apache benchmark supported 7x more requests per second, compared to running OVS-DPDK in software alone.
Learn more
For more information about the differentiation between OVS offload technologies, why CMCC decided to use the VirtIO/vDPA solution, and how NVIDIA can help you improve efficiencies in cloud-native technologies, see the Turbocharge Cloud-Native Application with Virtual Data Plane Accelerated Networking joint GTC session between CMCC, Nuage Networks, and NVIDIA.
 Today, NVIDIA announced general availability of NVIDIA AI Enterprise 2.1. This latest version of the end-to-end AI and data analytics software suite is optimized, certified, and…
Today, NVIDIA announced general availability of NVIDIA AI Enterprise 2.1. This latest version of the end-to-end AI and data analytics software suite is optimized, certified, and… NVIDIA spoke with Chief Wizard of Pathea, Jingyang Xu, about himself, his company, and the process of implementing NVIDIA Reflex in My Time at Sandrock, the studio’s latest…
NVIDIA spoke with Chief Wizard of Pathea, Jingyang Xu, about himself, his company, and the process of implementing NVIDIA Reflex in My Time at Sandrock, the studio’s latest…







 Nsight Graphics 2022.3 and Nsight Aftermath 2022.2 have just been released and are now available to download. Nsight Graphics 2022.3 The Nsight Graphics 2022.3 release…
Nsight Graphics 2022.3 and Nsight Aftermath 2022.2 have just been released and are now available to download. Nsight Graphics 2022.3 The Nsight Graphics 2022.3 release… If you’re wondering how an AI server is different from an AI workstation, you’re not the only one. Assuming strictly AI use cases with minimal graphics workload, obvious…
If you’re wondering how an AI server is different from an AI workstation, you’re not the only one. Assuming strictly AI use cases with minimal graphics workload, obvious… In the old days of 10 Mbps Ethernet, long before Time-Sensitive Networking became a thing, state-of-the-art shared networks basically required that packets would collide. For the…
In the old days of 10 Mbps Ethernet, long before Time-Sensitive Networking became a thing, state-of-the-art shared networks basically required that packets would collide. For the…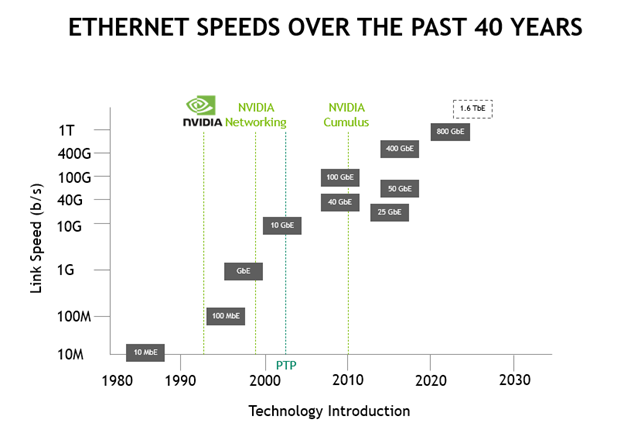



") Artificial intelligence (AI) is becoming pervasive in the enterprise. Speech recognition, recommenders, and fraud detection are just a few applications among hundreds being driven…
Artificial intelligence (AI) is becoming pervasive in the enterprise. Speech recognition, recommenders, and fraud detection are just a few applications among hundreds being driven…