
 Interested in speech recognition technology? Sign up for the NVIDIA speech AI newsletter. Over the past decade, AI-powered speech recognition systems have…
Interested in speech recognition technology? Sign up for the NVIDIA speech AI newsletter. Over the past decade, AI-powered speech recognition systems have…
Interested in speech recognition technology? Sign up for the NVIDIA speech AI newsletter.
Over the past decade, AI-powered speech recognition systems have slowly become part of our everyday lives, from voice search to virtual assistants in contact centers, cars, hospitals, and restaurants. These speech recognition developments are made possible by deep learning advancements.
Developers across many industries now use automatic speech recognition (ASR) to increase business productivity, application efficiency, and even digital accessibility. Read on to learn more about ASR, how it works, use cases, advancements, and more.
What is automatic speech recognition
Speech recognition technology is capable of converting spoken language (an audio signal) into written text that is often used as a command.
Today’s most advanced software can accurately process varying language dialects and accents. For example, ASR is commonly seen in user-facing applications such as virtual agents, live captioning, and clinical note-taking. Accurate speech transcription is essential for these use cases.
Developers in the speech AI space also use alternative terminologies to describe speech recognition such as ASR, speech-to-text (STT), and voice recognition.
ASR is a critical component of speech AI, which is a suite of technologies designed to help humans converse with computers through voice.
Why natural language processing is used in speech recognition
Developers are often unclear about the role of natural language processing (NLP) models in the ASR pipeline. Aside from being applied in language models, NLP is also used to augment generated transcripts with punctuation and capitalization at the end of the ASR pipeline.
After the transcript is post-processed with NLP, the text is used for downstream language modeling tasks including:
- Sentiment analysis
- Text analytics
- Text summarization
- Question answering
Speech recognition algorithms
Speech recognition algorithms can be implemented in a traditional way using statistical algorithms, or by using deep learning techniques such as neural networks to convert speech into text.
Traditional ASR algorithms
Hidden Markov models (HMM) and dynamic time warping (DTW) are two such examples of traditional statistical techniques for performing speech recognition.
Using a set of transcribed audio samples, an HMM is trained to predict word sequences by varying the model parameters to maximize the likelihood of the observed audio sequence.
DTW is a dynamic programming algorithm that finds the best possible word sequence by calculating the distance between time series: one representing the unknown speech and others representing the known words.
Deep learning ASR algorithms
For the last few years, developers have been interested in deep learning for speech recognition because statistical algorithms are less accurate. In fact, deep learning algorithms work better at understanding dialects, accents, context, and multiple languages, and transcribes accurately even in noisy environments.
Some of the most popular state-of-the-art speech recognition acoustic models are Quartznet, Citrinet, and Conformer. In a typical speech recognition pipeline, you can choose and switch any acoustic model you want based on your use case and performance.
Implementation tools for deep learning models
Several tools are available for developing deep learning speech recognition models and pipelines, including Kaldi, Mozilla DeepSpeech, NVIDIA NeMo, Riva, TAO Toolkit, and services from Google, Amazon, and Microsoft.
Kaldi, DeepSpeech, and NeMo are open-source toolkits that help you build speech recognition models. TAO Toolkit and Riva are closed-source SDKs that help you develop customizable pipelines that can be deployed in production.
Cloud Service Providers like Google, AWS, and Microsoft offer generic services that you can easily plug and play with.
Deep learning speech recognition pipeline
As shown in Figure 1, ASR pipeline consists of the following components: a spectrogram generator that converts raw audio to spectrograms, an acoustic model that takes the spectrograms as input and outputs a matrix of probabilities over characters over time, a decoder (optionally coupled with a language model) that generates possible sentences from the probability matrix, and finally, a punctuation and capitalization model that formats the generated text for easier human consumption.
A typical deep learning pipeline for speech recognition includes:
- Data preprocessing
- Neural acoustic model
- Decoder (optionally coupled with an n-gram language model)
- Punctuation and capitalization model.
Figure 1 shows an example of a deep learning speech recognition pipeline:
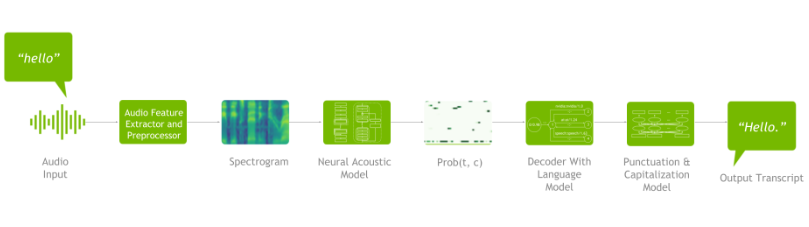
Datasets are essential in any deep learning application. Neural networks function similarly to the human brain. The more data you use to teach the model, the more it learns. The same is true for the speech recognition pipeline.
A few popular speech recognition datasets are LibriSpeech, Fisher English Training Speech, Mozilla Common Voice (MCV), VoxPopuli, 2000 HUB 5 English Evaluation Speech, AN4 (includes recordings of people spelling out addresses and names), and Aishell-1/AIshell-2 Mandarin speech corpus. In addition to your own proprietary datasets, these are some open-source datasets to get started with.
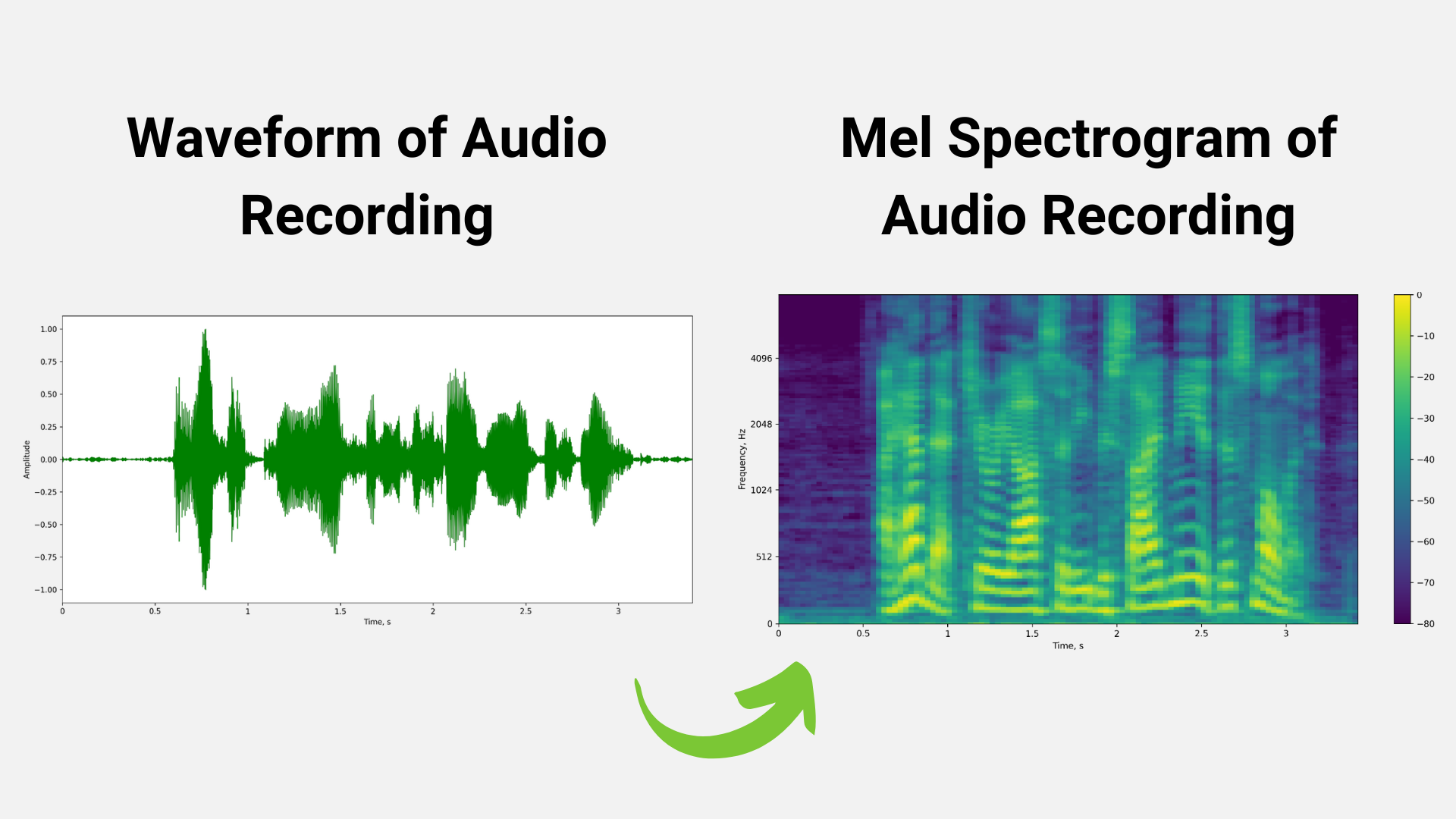
Data processing is the first step. It includes data preprocessing/augmentation techniques such as speed/time/noise/impulse perturbation and time stretch augmentation, Fast Fourier Transformations (FFT) using windowing, and normalization techniques.
For example, in Figure 2 below, the mel spectrogram is generated from a raw audio waveform after applying FFT using the windowing technique.
We can also use perturbation techniques to augment the training dataset. Figures 3 and 4 represent techniques like noise perturbation and masking being used to increase the size of the training dataset in order to avoid problems like overfitting.
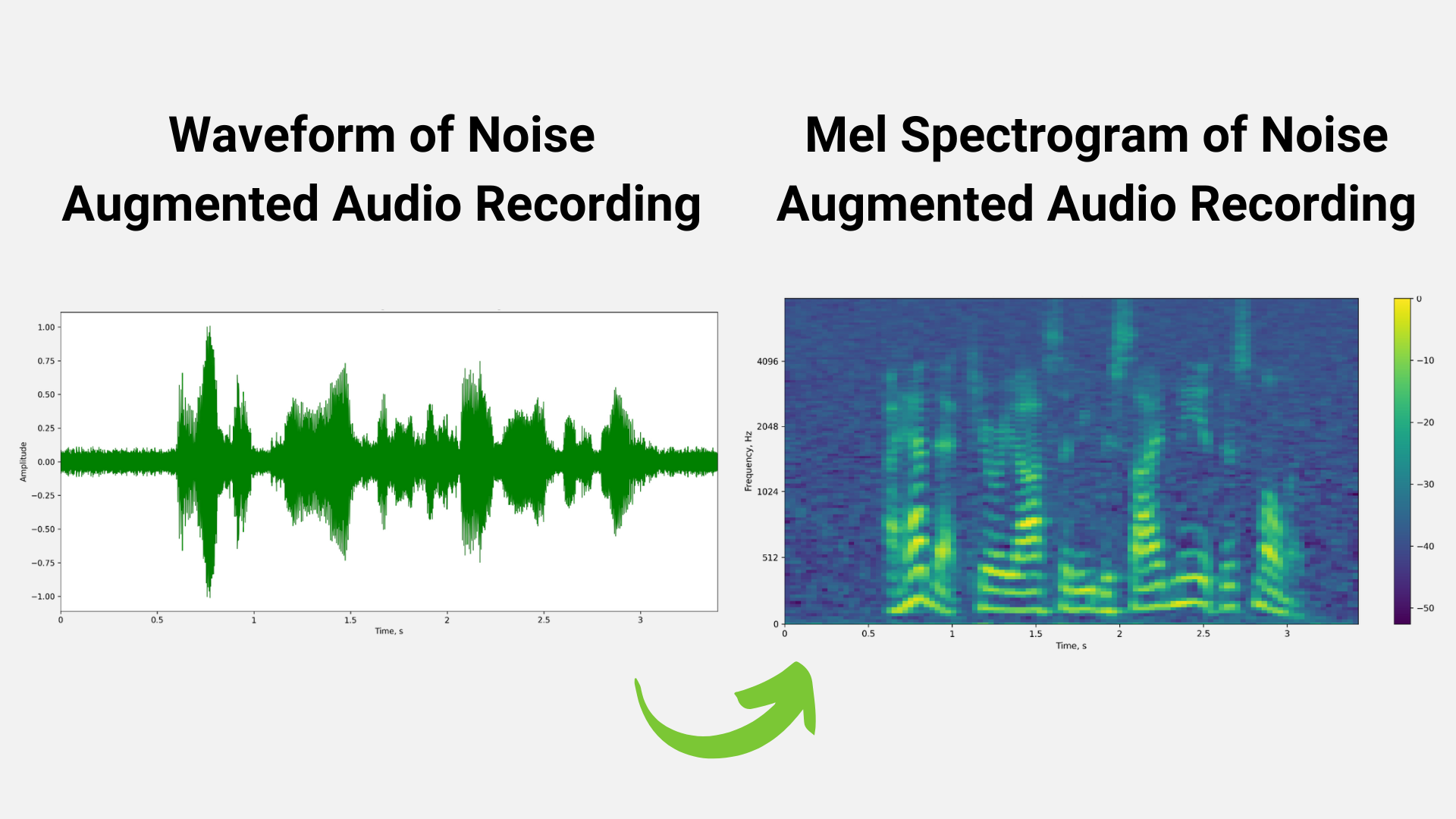
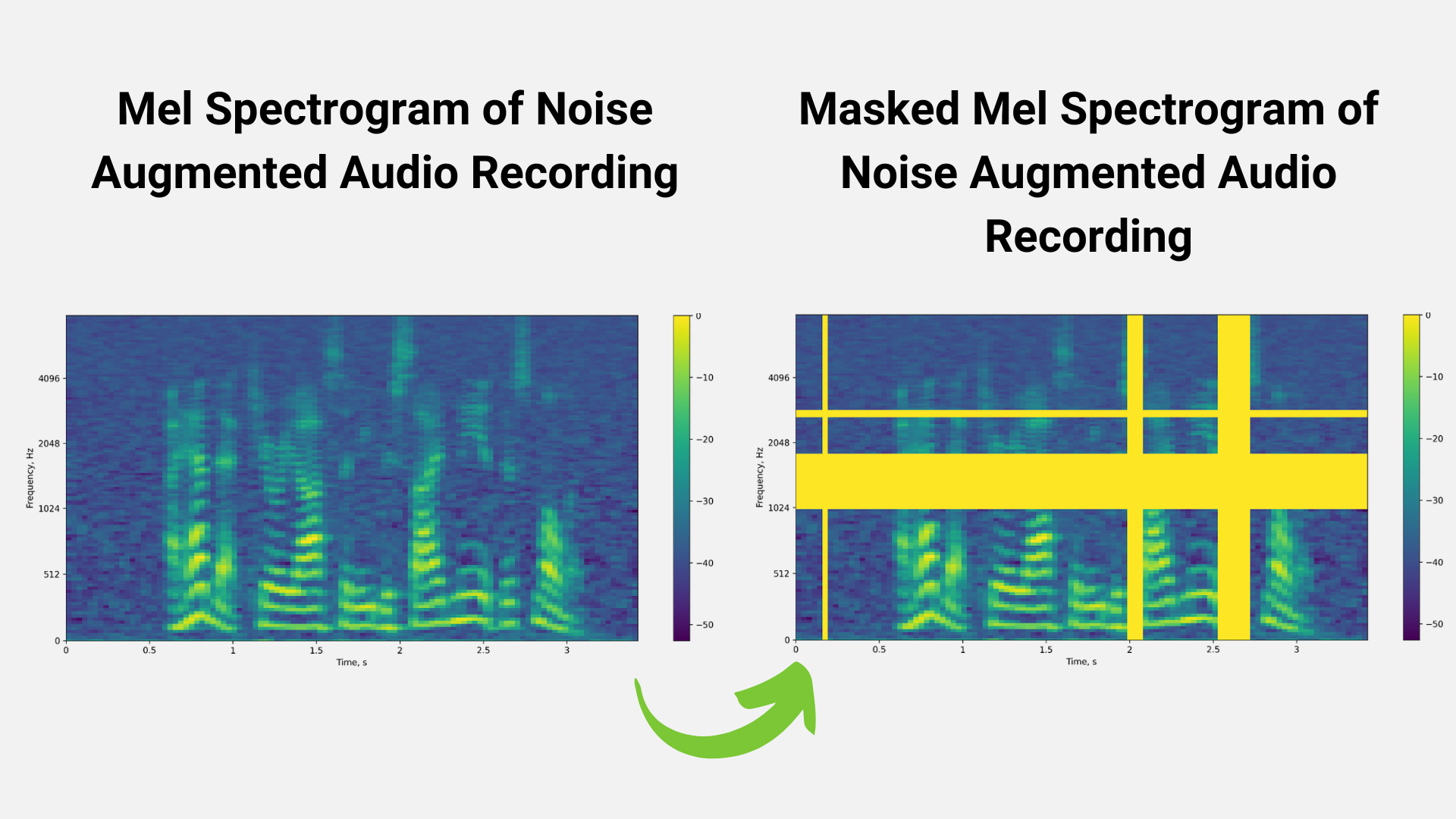
The output of the data preprocessing stage is a spectrogram/mel spectrogram, which is a visual representation of the strength of audio signal over time.
Mel spectrograms are then fed into the next stage: neural acoustic model. QuartzNet, CitriNet, ContextNet, Conformer-CTC, and Conformer-Transducer are examples of cutting-edge neural acoustic models. Multiple ASR models exist for several reasons, such as the need for real-time performance, higher accuracy, memory size, and compute cost for your use case.
However, Conformer-based models are becoming more popular due to their improved accuracy and ability to comprehend. The acoustic model returns the probability of characters/words at each time stamp.
Figure 5 shows the output of the acoustic model, with time stamps.
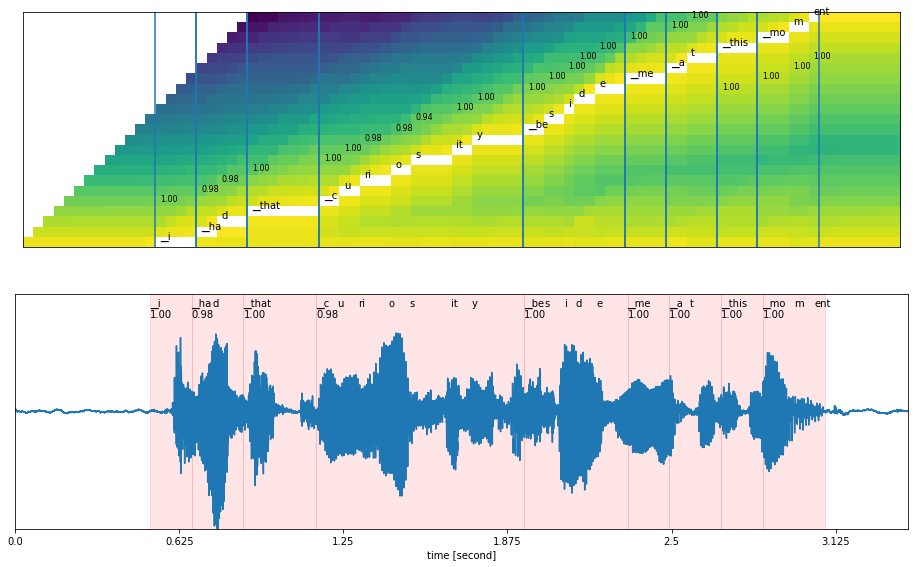
The acoustic model’s output is fed into the decoder along with the language model. Decoders include beam search and greedy decoders, and language models include n-gram language, KenLM, and neural scoring. When it comes to the decoder, it helps to generate top words, which are then passed to language models to predict the correct sentence.
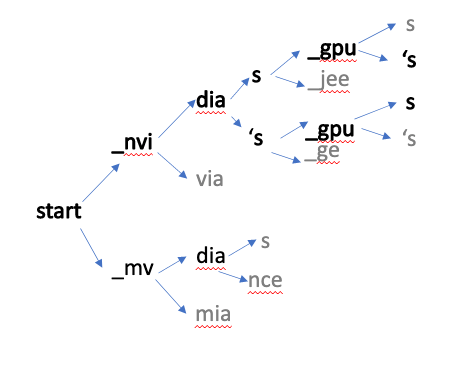
In the diagram below, the decoder selects the next best word based on the probability score. Based on the final highest score, the correct word or sentence is selected and sent to the punctuation and capitalization model.
The ASR pipeline generates text with no punctuation or capitalization.
Finally, a punctuation and capitalization model is used to improve the text quality for better readability. Bidirectional Encoder Representations from Transformers (BERT) models are commonly used to generate punctuated text.
Figure 7 illustrates a simple example of a before-and-after punctuation and capitalization model:

Speech recognition industry impact
Speech recognition could help industries such as finance, telecommunications, and Unified Communications as a Service (UCaaS) to improve customer experience, operational efficiency, and return on investment (ROI).
Finance
Speech recognition is applied in the finance industry for applications such as call center agent assist and trade floor transcripts. ASR is used to transcribe conversations between customers and call center agents/trade floor agents. The generated transcriptions can then be analyzed and used to provide real-time recommendations to agents. This adds to an 80% reduction in post-call time.
Furthermore, the generated transcripts are used for downstream tasks, including:
- Sentiment analysis
- Text summarization
- Question answering
- Intent and entity recognition
Telecommunications
Contact centers are critical components of the telecommunications industry. With contact center technology, you can reimagine the telecommunications customer center, and speech recognition helps with that. As previously discussed in the finance call center use case, ASR is used in Telecom contact centers to transcribe conversations between customers and contact center agents in order to analyze them and recommend call center agents in real time. T-Mobile uses ASR for quick customer resolution, for example.
Unified Communications as a Software (UCaaS)
COVID-19 increased demand for Unified Communications as a Service (UCaaS) solutions, and vendors in the space began focusing on the use of speech AI technologies such as ASR to create more engaging meeting experiences.
For example, ASR can be used to generate live captions in video conferencing meetings. Captions generated can then be used for downstream tasks such as meeting summaries and identifying action items in notes.
Future of ASR technology
Speech recognition is not as easy as it sounds. Developing speech recognition is full of challenges, ranging from accuracy to customization for your use case to real-time performance. On the other hand, businesses and academic institutions are racing to overcome some of these challenges and advance the use of speech recognition capabilities.
ASR challenges
Some of the challenges in developing and deploying speech recognition pipelines in production include:
- Lack of tools and SDKs that offer state-of-the-art (SOTA) ASR models makes it difficult for developers to take advantage of the best speech recognition technology.
- Limited customization capabilities that enable developers to fine-tune on domain-specific and context-specific jargon, multiple languages, dialects, and accents in order to have your applications understand and speak like you
- Restricted deployment support; for example, depending on the use case, the software should be capable of being deployed in any cloud, on-prem, edge, and embedded.
- Real-time speech recognition pipelines; for instance, in a call center agent assist use case, we cannot wait several seconds for conversations to be transcribed before using them to empower agents.
ASR advancements
Numerous advancements in speech recognition are occurring on both the research and software development fronts. To begin, research has resulted in the development of several new cutting-edge ASR architectures, E2E speech recognition models, and self-supervised or unsupervised training techniques.
On the software side, there are a few tools that enable quick access to SOTA models, and then there are different sets of tools that enable the deployment of models as services in production.
Key takeaways
Speech recognition continues to grow in adoption due to its advancements in deep learning-based algorithms that have made ASR as accurate as human recognition. Also, breakthroughs like multilingual ASR help companies make their apps available worldwide, and moving algorithms from cloud to on-device saves money, protects privacy, and speeds up inference.
NVIDIA offers Riva, a speech AI SDK, to address several of the challenges discussed above. With Riva, you can quickly access the latest SOTA research models tailored for production purposes. You can customize these models to your domain and use case, deploy on any cloud, on-prem, edge, or embedded, and run them in real-time for engaging natural interactions.
Learn how your organization can benefit from speech recognition skills with the free ebook, Building Speech AI Applications.