In the machine learning and MLOps world, GPUs are widely used to speed up model training and inference, but what about the other stages of the workflow like ETL…
In the machine learning and MLOps world, GPUs are widely used to speed up model training and inference, but what about the other stages of the workflow like ETL pipelines or hyperparameter optimization?
Within the RAPIDS data science framework, ETL tools are designed to have a familiar look and feel to data scientists working in Python. Do you currently use Pandas, NumPy, Scikit-learn, or other parts of the PyData stack within your KubeFlow workflows? If so, you can use RAPIDS to accelerate those parts of your workflow by leveraging the GPUs likely already available in your cluster.
In this post, I demonstrate how to drop RAPIDS into a KubeFlow environment. You start with using RAPIDS in the interactive notebook environment and then scale beyond your single container to use multiple GPUs across multiple nodes with Dask.
Optional: Installing KubeFlow with GPUs
This post assumes you are already somewhat familiar with Kubernetes and KubeFlow. To explore how you can use GPUs with RAPIDS on KubeFlow, you need a KubeFlow cluster with GPU nodes. If you already have a cluster or are not interested in KubeFlow installation instructions, feel free to skip ahead.
KubeFlow is a popular machine learning and MLOps platform built on Kubernetes for designing and running machine learning pipelines, training models, and providing inference services.
KubeFlow also provides a notebook service that you can use to launch an interactive Jupyter server in your Kubernetes cluster and a pipeline service with a DSL library, written in Python, to create repeatable workflows. Tools for adjusting hyperparameters and running a model inference server are also accessible. This is essentially all the tooling that you need for building a robust machine learning service.
For this post, you use Google Kubernetes Engine (GKE) to launch a Kubernetes cluster with GPU nodes and install KubeFlow onto it, but any KubeFlow cluster with GPUs will do.
Creating a Kubernetes cluster with GPUs
First, use the gcloud CLI to create a Kubernetes cluster.
$ gcloud container clusters create rapids-gpu-kubeflow
--accelerator type=nvidia-tesla-a100,count=2 --machine-type a2-highgpu-2g
--zone us-central1-c --release-channel stable
Note: Machines with GPUs have certain limitations which may affect your workflow. Learn more at https://cloud.google.com/kubernetes-engine/docs/how-to/gpus
Creating cluster rapids-gpu-kubeflow in us-central1-c...
Cluster is being health-checked (master is healthy)...
Created
kubeconfig entry generated for rapids-gpu-kubeflow.
NAME LOCATION MASTER_VERSION MASTER_IP MACHINE_TYPE NODE_VERSION NUM_NODES STATUS
rapids-gpu-kubeflow us-central1-c 1.21.12-gke.1500 34.132.107.217 a2-highgpu-2g 1.21.12-gke.1500 3 RUNNING
With this command, you’ve launched a GKE cluster called rapids-gpu-kubeflow. You’ve specified that it should use nodes of type a2-highgpu-2g, each with two A100 GPUs.
KubeFlow also requires a stable version of Kubernetes, so you specified that along with the zone in which to launch the cluster.
Then, install KubeFlow by cloning the KubeFlow manifests repo, checking out the latest release, and applying them.
$ git clone https://github.com/kubeflow/manifests
$ cd manifests
$ git checkout v1.5.1 # Or whatever the latest release is
$ while ! kustomize build example | kubectl apply -f -; do echo "Retrying to apply resources"; sleep 10; done
After all the resources have been created, KubeFlow still has to bootstrap itself on your cluster. Even after this command finishes, things may not be ready yet. This can take upwards of 15 minutes.
Eventually, you should see a full list of KubeFlow services in the kubeflow namespace.
After all your pods are in a Running state, port forward the KubeFlow web user interface, and access it in your browser.
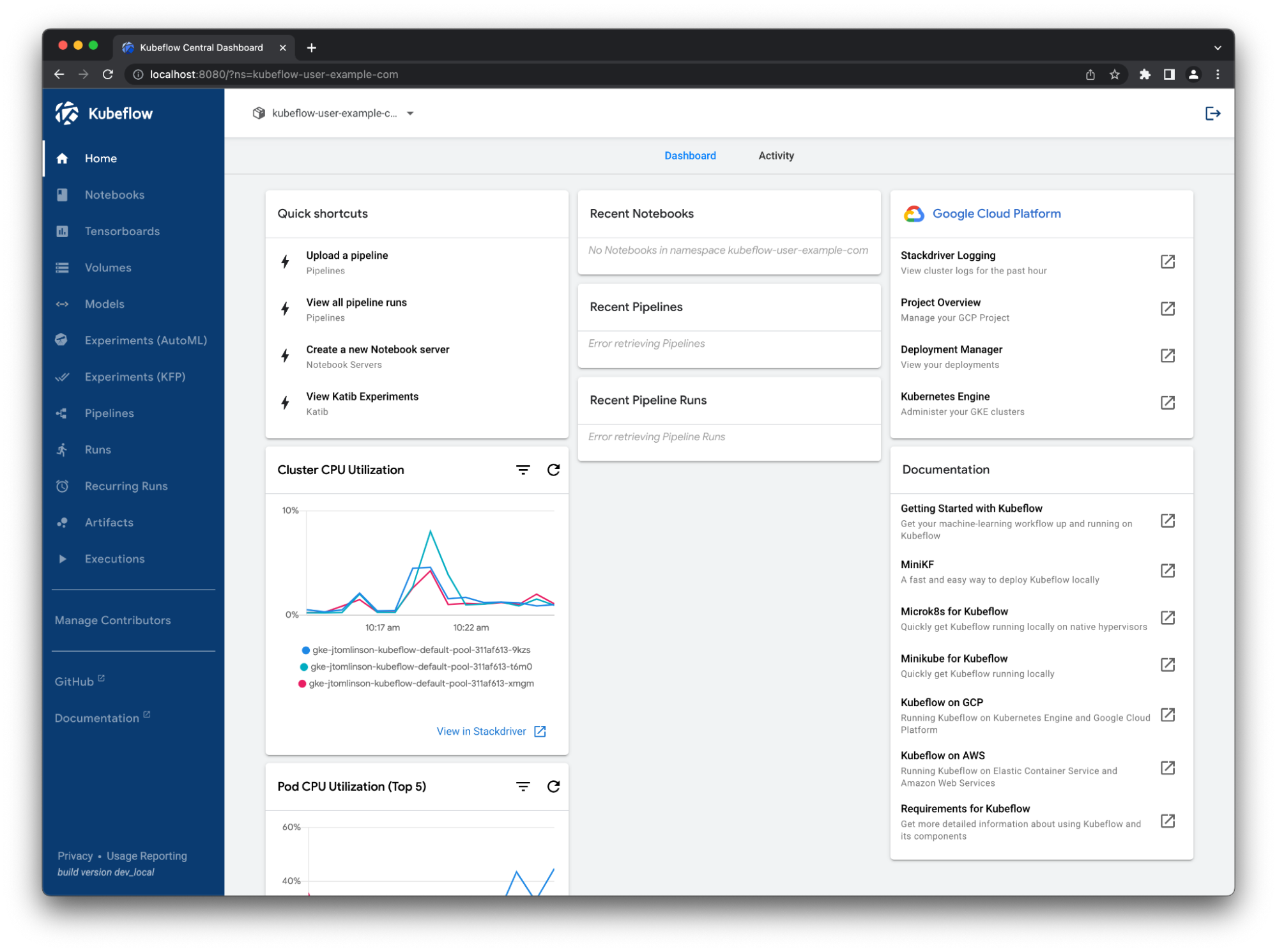
Navigate to 127.0.0.1:8080 and log in with the default credentials user@example.com and 12341234. Then, you should see the KubeFlow dashboard (Figure 1).
Before launching your cluster, you must create a configuration profile that is important for when you start using Dask later. To do this, apply the following manifest:
Now, choose a RAPIDS version to use. Typically, you want to choose the container image for the latest release. The default CUDA version installed on GKE Stable is 11.4, so choose that. As of version 11.5 and later, it won’t matter as they will be backward compatible. Copy the container image name from the installation command:
Scroll down to Configurations, check the configure dask dashboard option, scroll to the bottom of the page, and then choose Launch. You should see it starting up in your list of notebooks. The RAPIDS container images are packed full of amazing tools, so this step can take a little while.
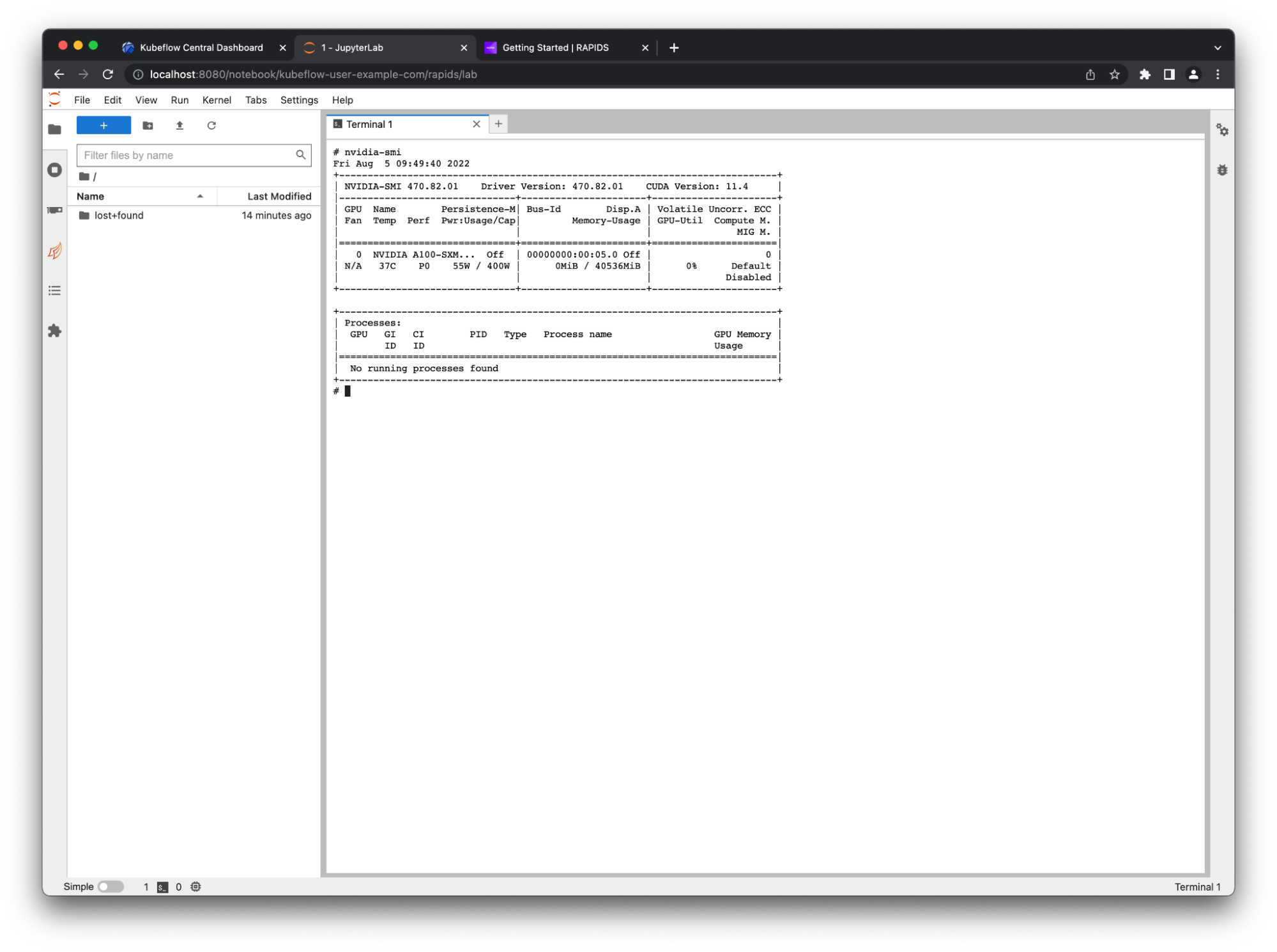
When the notebook is ready, to launch Jupyter, choose Connect. Verify that everything works okay by opening a terminal window and running nvidia-smi (Figure 2).
Figure 2. The nvidia-smi command is a great way to check that your GPU is set up
Success! Your A100 GPU is being passed through into your notebook container.
The RAPIDS container that you chose also comes with some example notebooks, which you can find in /rapidsai/notebooks. Make a quick symbolic link to these from your home directory so that you can navigate using the file explorer on the left:
ln -s /rapids/notebooks /home/jovyan/notebooks.
Navigate to those example notebooks and explore all the libraries that RAPIDS offers. For example, ETL developers that use pandas should check out the cuDF notebooks for examples of accelerated DataFrames.
Scaling your RAPIDS workflows
Many RAPIDS libraries also support scaling out your computations onto multiple GPUs spread over many nodes for added acceleration. To do this, use Dask, an open-source Python library for distributed computing.
To use Dask, create a scheduler and some workers to perform your calculations. These workers also need GPUs and the same Python environment as the notebook session. Dask has an operator for Kubernetes that you can use to manage Dask clusters on your KubeFlow cluster, so install that now.
Installing the Dask Kubernetes operator
To install the operator, you create the operator itself and its associated custom resources. For more information, see Installing in the Dask documentation.
In the terminal window that you used to create your KubeFlow cluster, run the following commands:
Verify that your resources were applied successfully by listing your Dask clusters. You shouldn’t expect to see any but the command should succeed.
$ kubectl get daskclusters
No resources found in default namespace.
You can also check that the operator pod is running and ready to launch new Dask clusters.
$ kubectl get pods -A -l application=dask-kubernetes-operator
NAMESPACE NAME READY STATUS RESTARTS AGE
dask-operator dask-kubernetes-operator-775b8bbbd5-zdrf7 1/1 Running 0 74s
Lastly, make sure that your notebook session can create and manage the Dask custom resources. To do this, edit the kubeflow-kubernetes-edit cluster role that gets applied to your notebook pods. Add a new rule to the rules section for this role to allow everything in the kubernetes.dask.org API group.
Now, create DaskCluster resources in Kubernetes to launch all the necessary pods and services for your cluster to work. You can do this in YAML through the Kubernetes API if you like but for this post, use the Python API from the notebook session.
Back in the Jupyter session, create a new notebook and install the dask-kubernetes package that you need for launching your clusters.
!pip install dask-kubernetes
Next, create a Dask cluster using the KubeCluster class. Confirm that you set the container image to match the one you chose for your notebook environment and set the number of GPUs to 1. You also tell the RAPIDS container not to start Jupyter by default and run the Dask command instead.
This can take a similar amount of time to starting up the notebook container, as it also has to pull the RAPIDS Docker image.
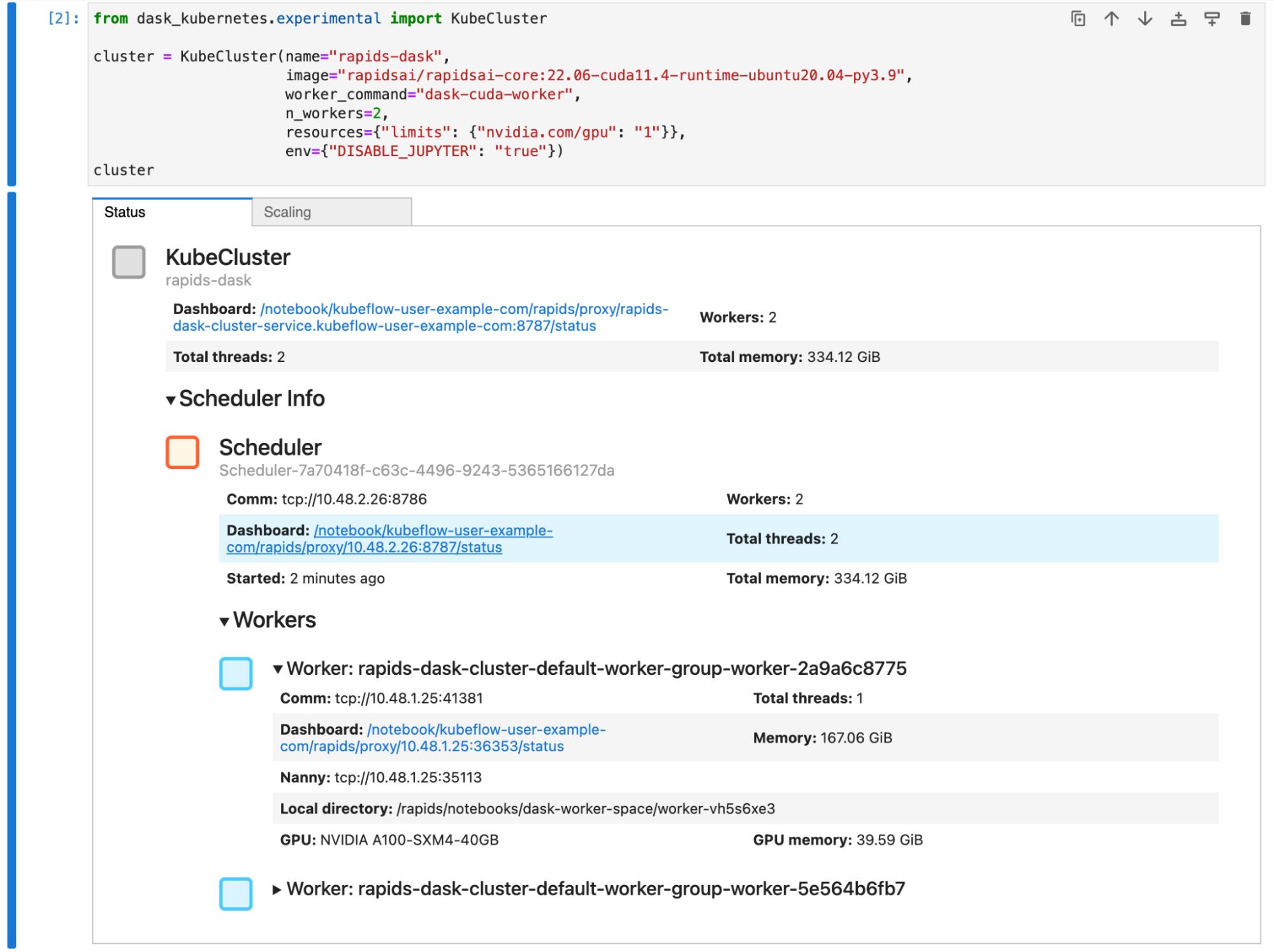
Figure 3 shows that you have a Dask cluster with two workers, and that each worker has an A100 GPU, the same as your Jupyter session.
Figure 3. Dask has many useful widgets that you can view in your notebook to show the status of your cluster
You scale this cluster up and down with either the scaling tab in the widget in Jupyter or by calling cluster.scale(n) to set the number of workers, and therefore the number of GPUs.
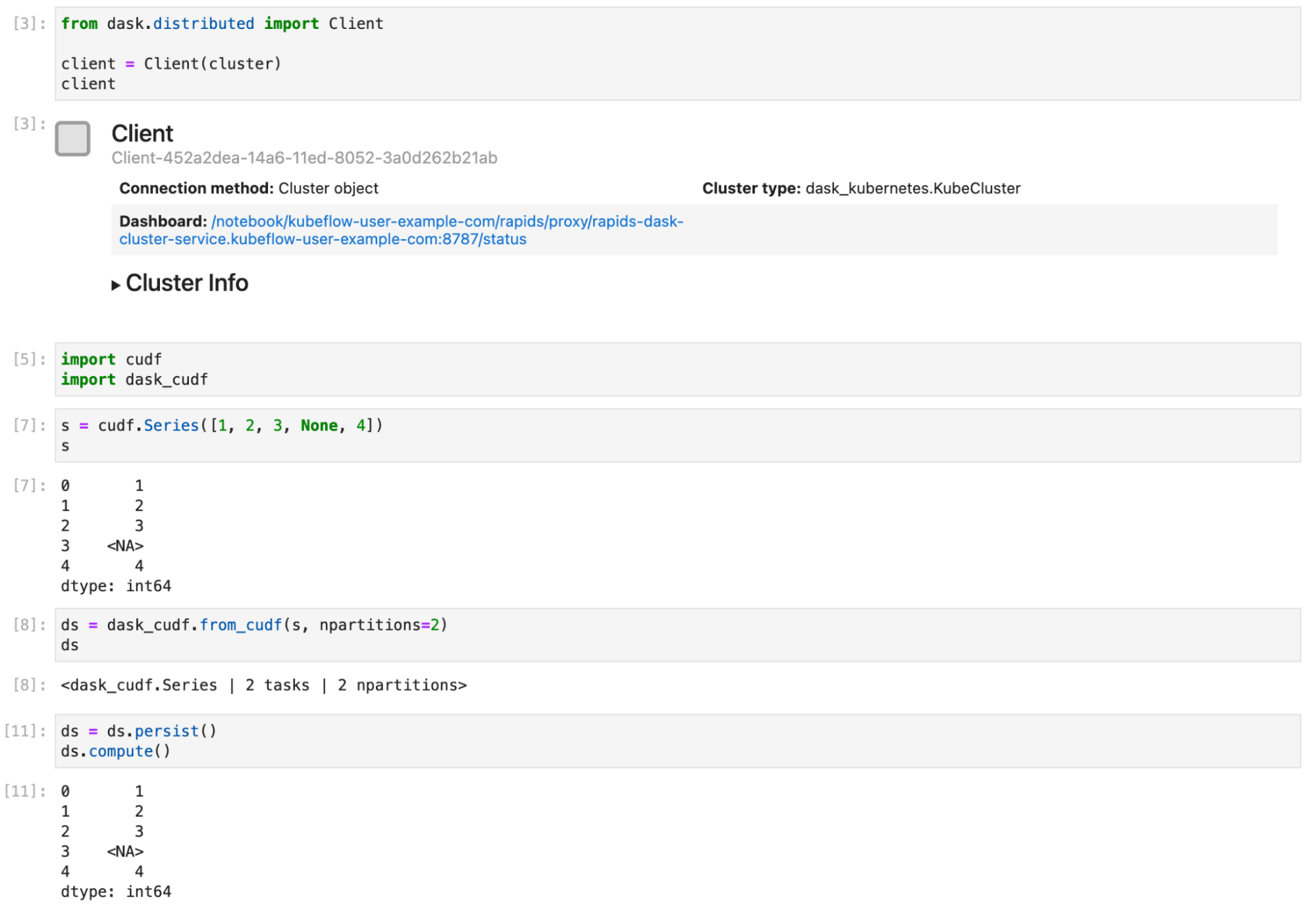
Now, connect a Dask client to your cluster. From that point on, any RAPIDS libraries that support Dask, such as dask_cudf, use your cluster to distribute your computation over all your GPUs. Figure 4 shows a short example of creating a Series object and distributing it with Dask.
Figure 4. Create a cuDF DataFrame, distributed it with Dask, then perform a computation and get the results
Accessing the Dask dashboard
At the beginning of this section, you added an extra config file with some options for the Dask dashboard. These options are necessary to enable you to access the dashboard running in the scheduler pod on your Kubernetes cluster from your Jupyter environment.
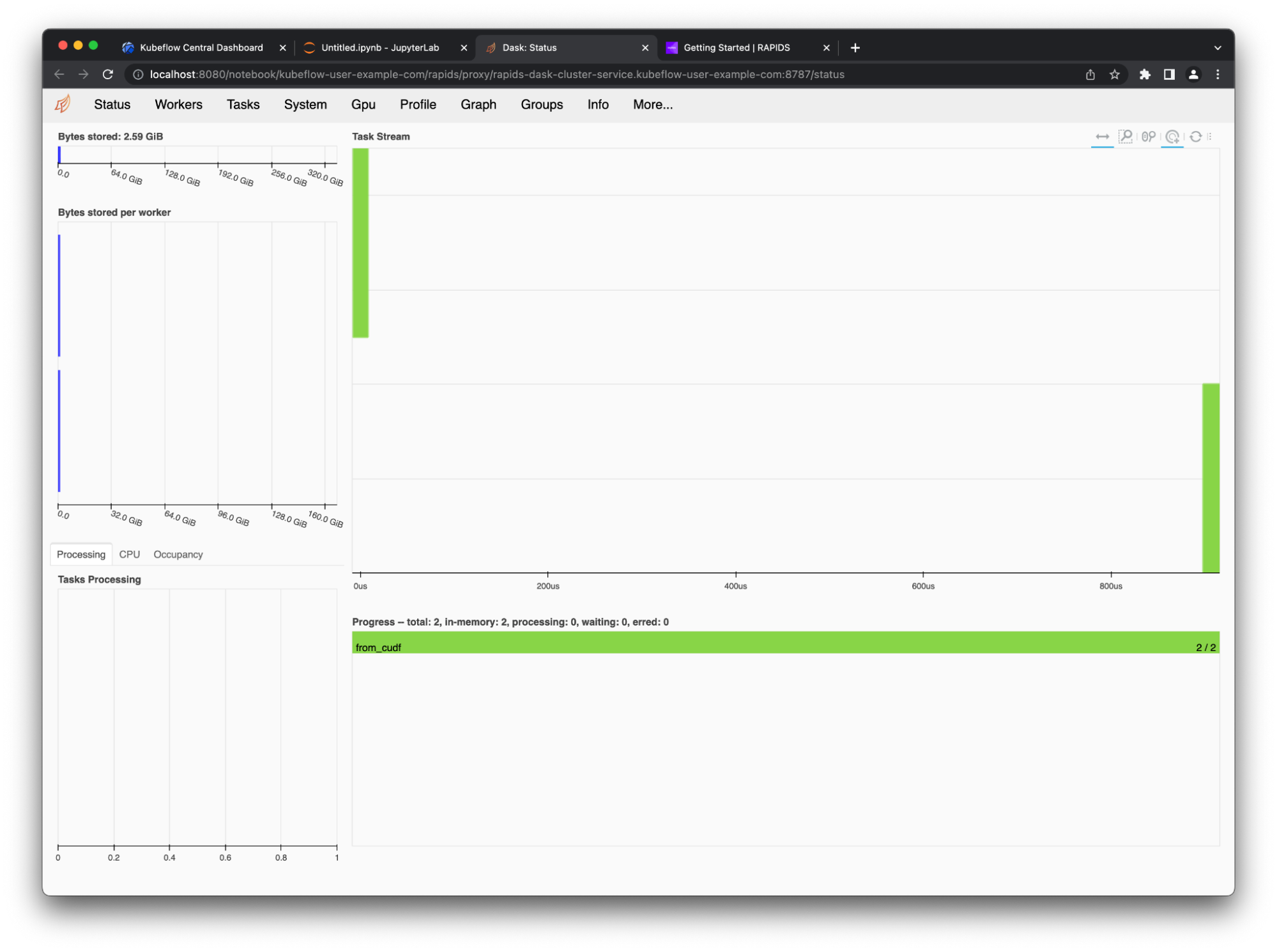
You may have noticed that the cluster and client widgets both had links to the dashboard. Select these links to open the dashboard in a new tab (Figure 5).
Figure 5. Dask dashboard with the from_cudf call
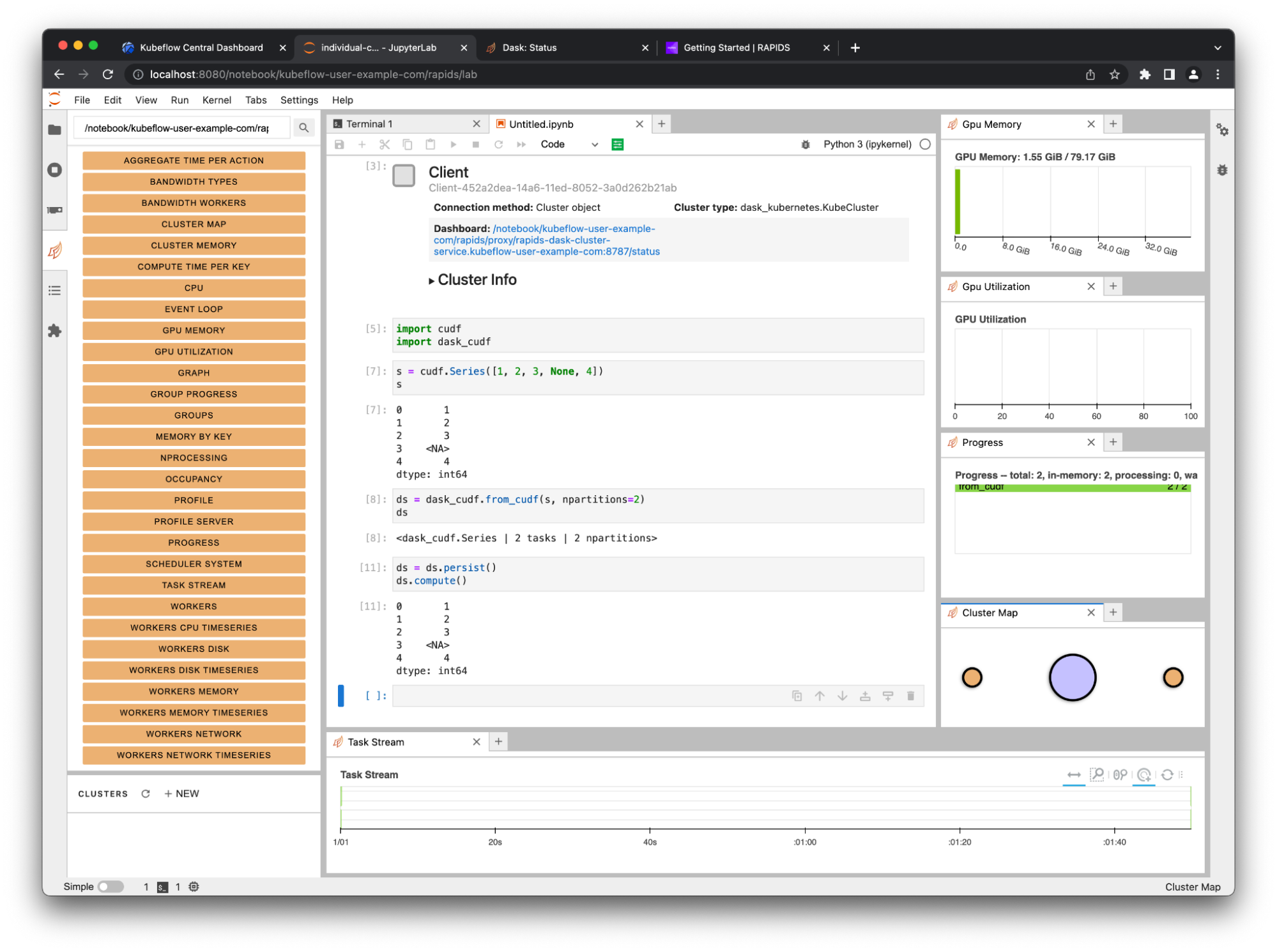
You can also use the Dask JupyterLab extension to view various plots and stats about your Dask cluster right in JupyterLab.
On the Dask tab on the left, choose the search icon. This connects JupyterLab to the dashboard through the client in your notebook. Select the various plots and arrange them in JupyterLab by dragging the tabs around.
Figure 6. The Dask dashboard has many useful plots, including some dedicated GPU metrics like memory use and utilization
If you followed along with this post, clean up all the created resources by deleting the GKE cluster created at the start.
RAPIDS integrates seamlessly with KubeFlow enabling you to use your GPU resources in the ETL stages of your workflows, as well during training and inference.
You can either drop the RAPIDS environment straight into the KubeFlow notebooks service for single-node work or use the Dask Operator for Kubernetes from KubeFlow Pipelines to scale that workload onto many nodes and GPUs.
For more information about using RAPIDS, see the following resources:

 In the machine learning and MLOps world, GPUs are widely used to speed up model training and inference, but what about the other stages of the workflow like ETL…
In the machine learning and MLOps world, GPUs are widely used to speed up model training and inference, but what about the other stages of the workflow like ETL…