
 Crafted by AI for AI, GPUNet is a class of convolutional neural networks designed to maximize the performance of NVIDIA GPUs using NVIDIA TensorRT. Built using…
Crafted by AI for AI, GPUNet is a class of convolutional neural networks designed to maximize the performance of NVIDIA GPUs using NVIDIA TensorRT. Built using…
Crafted by AI for AI, GPUNet is a class of convolutional neural networks designed to maximize the performance of NVIDIA GPUs using NVIDIA TensorRT.
Built using novel neural architecture search (NAS) methods, GPUNet demonstrates state-of-the-art inference performance up to 2x faster than EfficientNet-X and FBNet-V3.
The NAS methodology helps build GPUNet for a wide range of applications such that deep learning engineers can directly deploy these neural networks depending on the relative accuracy and latency targets.
GPUNet NAS design methodology
Efficient architecture search and deployment-ready models are the key goals of the NAS design methodology. This means little to no interaction with the domain experts and efficient use of cluster nodes for training potential architecture candidates. Most important is that the generated models are deployment-ready.
Crafted by AI
Finding the best performing architecture search for a target device can be time-consuming. NVIDIA built and deployed a novel NAS AI agent that efficiently makes the tough design choices required to build GPUNets that beat the current SOTA models by a factor of 2x.
This NAS AI agent automatically orchestrates hundreds of GPUs in the Selene supercomputer without any intervention from the domain experts.
Optimized for NVIDIA GPU using TensorRT
GPUNet picks up the most relevant operations required to meet the target model accuracy with related TensorRT inference latency cost, promoting GPU-friendly operators (for example, larger filters) over memory-bound operators (for example, fancy activations). It delivers the SOTA GPU latency and the accuracy on ImageNet.
Deployment-ready
The GPUNet reported latencies include all the performance optimization available in the shipping version of TensorRT, including fused kernels, quantization, and other optimized paths. Built GPUNets are ready for deployment.
Building a GPUNet: An end-to-end NAS workflow
At a high level, the neural architecture search (NAS) AI agent is split into two stages:
- Categorizing all possible network architectures by the inference latency.
- Using a subset of these networks that fit within the latency budget and optimizing them for accuracy.
In the first stage, as the search space is high-dimensional, the agent uses Sobol sampling to distribute the candidates more evenly. Using the latency look-up table, these candidates are then categorized into a subsearch space, for example, a subset of networks with total latency under 0.5 msecs on NVIDIA V100 GPUs.
The inference latency used in this stage is an approximate cost, calculated by summing up the latency of each layer from the latency lookup table. The latency table uses input data shape and layer configurations as keys to look up the related latency on the queried layer.
In the second stage, the agent sets up Bayesian optimization loss function to find the best performing higher accuracy network within the latency range of the subspace:

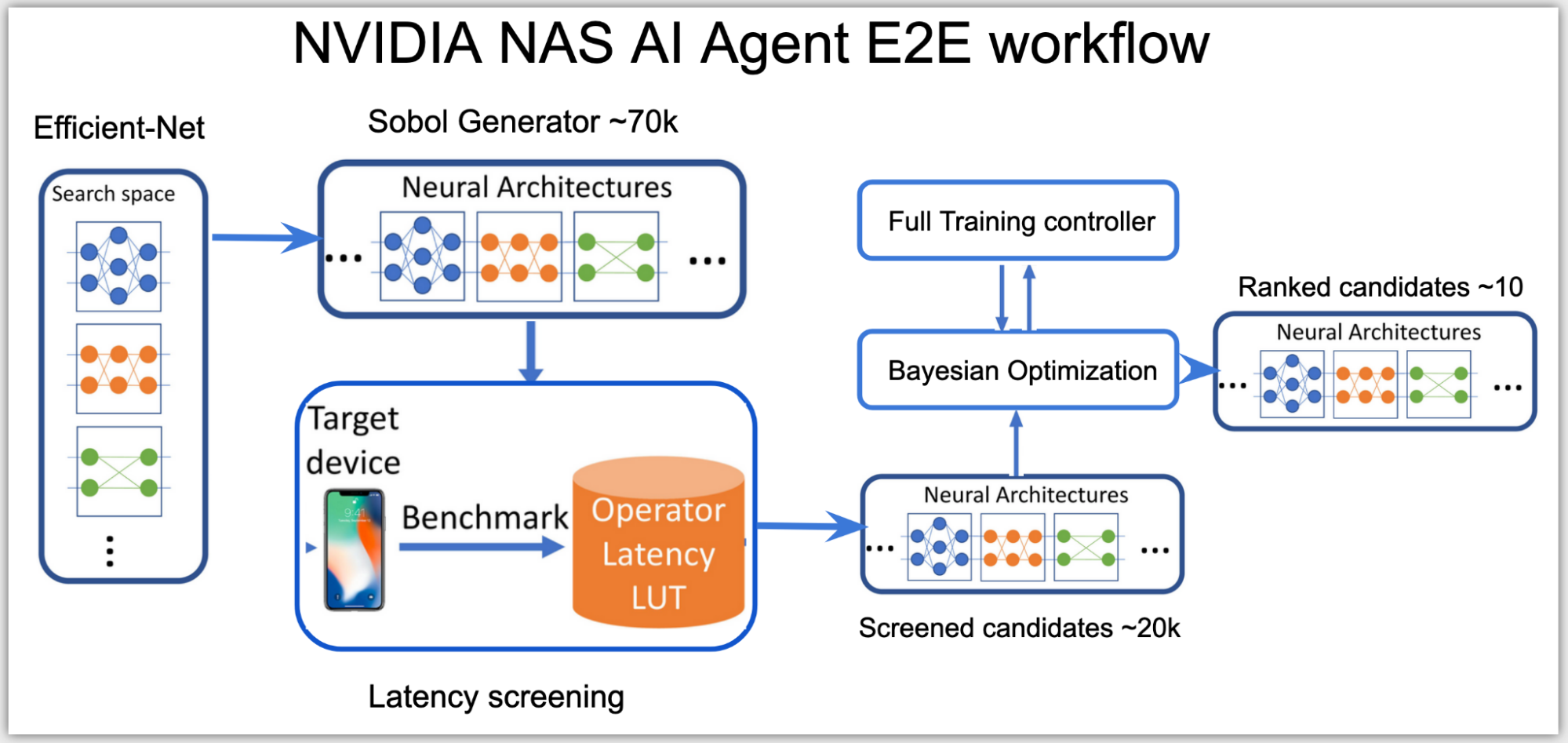
The AI agent uses a client-server distributed training controller to perform NAS simultaneously across multiple network architectures. The AI agent runs on one server node, proposing and training network candidates that run on several client nodes on the cluster.
Based on the results, only the promising network architecture candidates that meet both the accuracy and the latency targets of the target hardware get ranked, resulting in a handful of best-performing GPUNets that are ready to be deployed on NVIDIA GPUs using TensorRT.
GPUNet model architecture
The GPUNet model architecture is an eight-stage architecture using EfficientNet-V2 as the baseline architecture.
The search space definition includes searching on the following variables:
- Type of operations
- Number of strides
- Kernel size
- Number of layers
- Activation function
- IRB expansion ratio
- Output channel filters
- Squeeze excitation (SE)
Table 1 shows the range of values for each variable in the search space.
| Stage | Type | Stride | Kernel | Layers | Activation | ER | Filters | SE |
| 0 | Conv | 2 | [3,5] | 1 | [R,S] | [24, 32, 8] | ||
| 1 | Conv | 1 | [3,5] | [1,4] | [R,S] | [24, 32, 8] | ||
| 2 | F-IRB | 2 | [3,5] | [1,8] | [R,S] | [2, 6] | [32, 80, 16] | [0, 1] |
| 3 | F-IRB | 2 | [3,5] | [1,8] | [R,S] | [2, 6] | [48, 112, 16] | [0, 1] |
| 4 | IRB | 2 | [3,5] | [1,10] | [R,S] | [2, 6] | [96, 192, 16] | [0, 1] |
| 5 | IRB | 1 | [3,5] | [0,15] | [R,S] | [2, 6] | [112, 224, 16] | [0, 1] |
| 6 | IRB | 2 | [3,5] | [1,15] | [R,S] | [2, 6] | [128, 416, 32] | [0, 1] |
| 7 | IRB | 1 | [3,5] | [0,15] | [R,S] | [2, 6] | [256, 832, 64] | [0, 1] |
| 8 | Conv1x1 & Pooling & FC | |||||||
The first two stages search for the head configurations using convolutions. Inspired by EfficientNet-V2, the second and third stages use Fused-IRB. Fused-IRBs result in higher latency though, so in stages 4 to 7 these are replaced by IRBs.
The column Layers show the range of layers in the stage. For example, [1, 10] in stage 4 means that the stage can have 1 to 10 IRBs. The column Filters shows the range of output channel filters for the layers in the stage. This search space also tunes the expansion ratio (ER), activation types, kernel sizes, and the Squeeze Excitation (SE) layer inside the IRB/Fused-IRB.
Finally, the dimensions of the input image are searched from 224 to 512, at the step of 32.
Each GPUNet candidate build from the search space is encoded into a 41-wide integer vector (Table 2).
| Stage | Type | Hyperparameters | Length |
| Resolution | [Resolution] | 1 | |
| 0 | Conv | [#Filters] | 1 |
| 1 | Conv | [Kernel, Activation, #Layers] | 3 |
| 2 | Fused-IRB | [#Filters, Kernel, E, SE, Act, #Layers] | 6 |
| 3 | Fused-IRB | [#Filters, Kernel, E, SE, Act, #Layers] | 6 |
| 4 | IRB | [#Filters, Kernel, E, SE, Act, #Layers] | 6 |
| 5 | IRB | [#Filters, Kernel, E, SE, Act, #Layers] | 6 |
| 6 | IRB | [#Filters, Kernel, E, SE, Act, #Layers] | 6 |
| 7 | IRB | [#Filters, Kernel, E, SE, Act, #Layers] | 6 |
At the end of the NAS search, the returned ranked candidates is a list of these best-performing encodings, which are in turn the best-performing GPUNets.
Summary
All ML practitioners are encouraged to read the CVPR 2022 GPUNet paper, with related GPUNet training code on the NVIDIA/DeepLearningExamples GitHub repo, and run inference on the colab instance on available cloud GPUs. GPUNet inference is also available on the PyTorch hub. The colab run instance uses the GPUNet checkpoints hosted on the NGC hub. These checkpoints have varying accuracy and latency tradeoffs, which can be applied based on the requirement of the target application.