I am trying to run a CNN model on a computer with an AMD Raedon 5500. I ran the previous models on computers with Nvidia cards and they worked but for some reason tensorflow cannot see the GPU. It says the list of physical devices is empty. I know that the GPU is in PCI slot 3 and not 1, would that be an issue?
I have a sequence of 20 numbers, 1 – 20 and all numbers must be put in to sequence once. I have a formula which generates a score for each sequence input. What would be the best Machine Learning approach to find the sequence with the lowest score. It is very noisy and has many minimums.
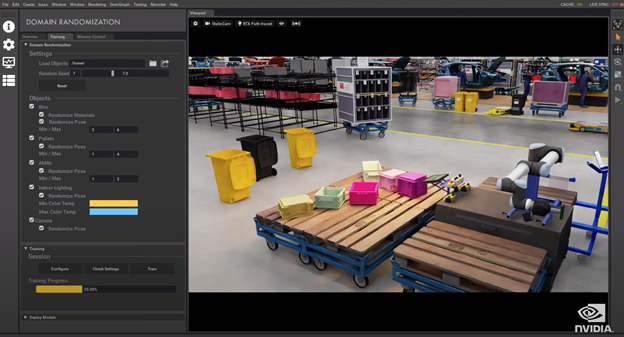
The new Isaac simulation engine not only creates better photorealistic environments, but also streamlines synthetic data generation and domain randomization to build ground-truth datasets to train robots in applications from logistics and warehouses to factories of the future.
The new Isaac simulation engine not only creates better photorealistic environments, but also streamlines synthetic data generation and domain randomization to build ground-truth datasets to train robots in applications from logistics and warehouses to factories of the future.
NVIDIA Omniverse is the underlying foundation for NVIDIA’s simulators, including the Isaac platform — which now includes several new features. Discover the next level in simulation capabilities for robots with NVIDIA Isaac Sim open beta, available now.
Built on the Omniverse platform, Isaac Sim is a robotics simulation application and synthetic data generation tool. It allows roboticists to train and test their robots more efficiently by providing a realistic simulation of the robot interacting with compelling environments that can expand coverage beyond what is possible in the real world.
This release of Isaac Sim also adds improved multi-camera support and sensor capabilities, and a PTC OnShape CAD importer to make it easier to bring in 3D assets. These new features will expand the breadth of robots and environments that can be successfully modeled and deployed in every aspect: from design and development of the physical robot, then training the robot, to deploying in a “digital twin” in which the robot is simulated and tested in an accurate and photorealistic virtual environment.
Summary of Key New Features
Multi-Camera Support
Fisheye Camera with Synthetic Data
ROS2 Support
PTC OnShape Importer
Improved Sensor Support
Ultrasonic Sensor
Force Sensor
Custom Lidar Patterns
Downloadable from NVIDIA Omniverse Launcher
Isaac Sim sending multi-camera sensor data to Rviz (ROS Visualization Tool)
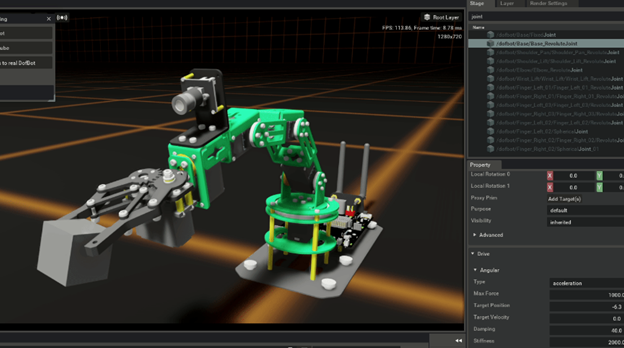
Controlling the Dofbot Manipulation Robot in Isaac Sim
Isaac Sim Enables More Robotics Simulation
Developers have long seen the benefits of having a powerful simulation environment for testing and training robots. But all too often, the simulators have had shortcomings which limited their adoption. Isaac Sim addresses these drawbacks with the benefits described below.
Realistic Simulation
In order to deliver realistic robotics simulations, Isaac Sim leverages the Omniverse platform’s powerful technologies including advanced GPU-enabled physics simulation with PhysX 5, photorealism with real-time ray and path tracing, and Material Definition Language (MDL) support for physically-based rendering.
Modular, Breadth of Applications
Isaac Sim is built to address many of the most common robotics use cases including manipulation, autonomous navigation, and synthetic data generation for training data. Its modular design allows users to easily customize and extend the toolset to accommodate many applications and and environments.
Seamless Connectivity and Interoperability
Isaac Sim benefits from Omniverse Nucleus and Omniverse Connectors, enabling collaborative building, sharing, and importing of environments and robot models in Universal Scene Description (USD). Easily connect the robot’s brain to a virtual world through Isaac SDK and ROS/ROS2 interface, fully-featured Python scripting, plugins for importing robot and environment models.
Synthetic Data Generation in Isaac Sim Bootstraps Machine Learning
Synthetic Data Generation is an important tool that is increasingly used to train the perception models found in today’s robots. Getting real-world, properly labeled data is a time consuming and costly endeavor. But in the case of robotics, some of the required training data could be too difficult or dangerous to collect in the real world. This is especially true of robots that must operate in close proximity to humans.
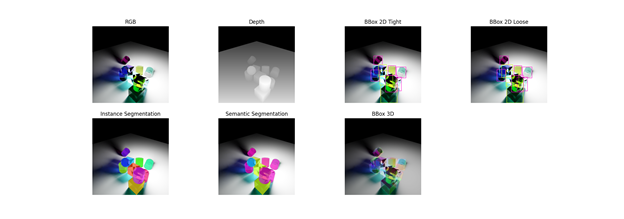
Isaac Sim has built-in support for a variety of sensor types that are important in training perception models. These sensors include RGB, depth, bounding boxes, and segmentation.
Ground Truth Synthetic Data with Glass Objects
In the open beta, we have the ability to output synthetic data in the KITTI format. This data can then be used directly with the NVIDIA Transfer Learning Toolkit to enhance model performance with use case-specific data.
Domain Randomization
Domain Randomization varies the parameters that define a simulated scene, such as the lighting, color and texture of materials in the scene. One of the main objectives of domain randomization is to enhance the training of machine learning (ML) models by exposing the neural network to a wide variety of domain parameters in simulation. This will help the model to generalize well when it encounters real world scenarios. In effect, this technique helps teach models what to ignore.
Domain Randomization of a Factory Scene
Isaac Sim supports the randomization of many different attributes that help define a given scene. With these capabilities, the ML engineers can ensure that the synthetic dataset contains sufficient diversity to drive robust model performance.
Randomizable Parameters
Color
Movement
Scale
Light
Texture
Material
Mesh
Visibility
Rotation
In Isaac Sim open beta, we have enhanced the domain randomization capabilities by allowing the user to define a region for randomization. Developers can now draw a box around the region in the scene that is to be randomized and the rest of the scene will remain static.
More Information on Isaac Sim
Check out the latest Isaac Sim GTC 2021 session, Sim-to-Real.
Also, learn more about importing your own robot with the following tutorial.
Learn more about using Isasac Sim to train your Jetbot by exploring these developer blogs:.
Join the thousands of developers who have worked with Isaac Sim across the robotics community via our early access program. Get started with the next step in robotics simulation by downloading Isaac Sim.
I’m trying to train an encoder-decoder model. The code is provided from my Udemy’s instructor. His training rate is high (0.9xxx), same thing for my classmates. When I copy exactly the code and run it on Google Colab (I literally just changed directory paths), my rate is extremely low (around 0.1-0.2 and just stuck there). It ends up the model almost doesn’t learn anything. I even use the same data. Is this even possible?
I have installed CUDA 10.1 and cuDNN 7.6.5. I checked the path in environment variables and it was the same as what was in a tutorial. I then created a new environment in anaconda and installed cudatoolkit 10.1 and cudnn 7.6.5. After, I installed tensorflow version 2.3.0. Then I tried tf.test.is_built_with_cuda(), which returned False. Also, print(device_lib.list_local_devices()) only showed my CPU. I tried restarting my laptop which didn’t seem to do anything and I have been trying different solutions for hours. I feel like I’m going crazy now and can’t think what could be wrong. Any help here would be massively appreciated.
Sorry if this is too trivial for this sub, but I’m a noob so here I go: I try to train an Odometry-model for my 4-wheeled robot using Tensorflow. I have my dataset with the sensordata (wheelencoders, acceleration) and X, Y, speed_x, speed_y as my labels.
So far so good, but because my algorithm needs the predictions of the timestep before as inputs to make the next prediction, I need: a RNN? Or something else for Time series prediction? I’m lost, please help me figure out the method I need to look into for this. Cheers
Is it like the coding exercises on coursera, where the main “skeleton” is filled out and you just have to add stuff like the model architecture and number of epochs? or do they just give the problem and you have to type everything from scratch?
The NVIDIA Cumulus Linux 4.2.0 release introduces a new feature called auto BGP, which makes BGP ASN assignment in a two-tier leaf and spine network configuration quick and easy. Auto BGP does the work for you without making changes to standard BGP behavior or configuration so that you don’t have to think about which numbers … Continued
The NVIDIA Cumulus Linux 4.2.0 release introduces a new feature called auto BGP, which makes BGP ASN assignment in a two-tier leaf and spine network configuration quick and easy.
Auto BGP does the work for you without making changes to standard BGP behavior or configuration so that you don’t have to think about which numbers to allocate to your switches. This helps you build optimal ASN configurations in your data center and avoid suboptimal routing and path hunting, which occurs when you assign the wrong spine ASNs.
If you don’t care about ASNs, then this feature is for you. If you do, you can always configure BGP the traditional way where you have control over which ASN to allocate to your switch. What I like about this feature is that you can mix and match. You don’t have to use auto BGP across all switches in your configuration. Instead, you can use it to configure one switch but allocate ASN numbers manually to other switches.
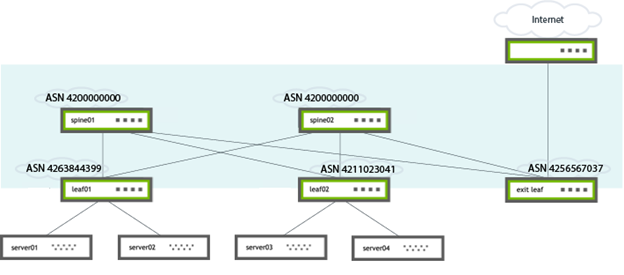
ASN assignment
Cumulus Linux uses private 32-bit ASN numbers in the range 4200000000 through 4294967294. This is the private space defined in RFC 6996. Each leaf is assigned a random and unique value in the range 4200000001 through 4294967294 and is based on a hash of the switch MAC address. Each spine is assigned 4200000000; the first number in the range.
Figure 1 shows the ASN numbers assigned to switches in a leaf and spine configuration.
Figure 1. Auto BGP ASN assignment
Configuring auto BGP
Use a simple NCLU command with the keyword leaf or spine:
net add bgp auto leaf
net add bgp auto spine
The auto BGP leaf and spine keywords are only used to configure the ASN. The configuration files and net show commands display the ASN number only.
This post explains why you need a DPU-based SmartNIC and discusses some Smart NIC use cases.
In the first post of this series, I argued that it is a function and not a form that distinguishes a SmartNIC from a data processing unit (DPU). I introduced the category of datacenter NICs called SmartNICs, which include both hardware transport and a programmable data path for virtual switch acceleration. These capabilities are necessary but not sufficient for a NIC to be a DPU. A true DPU must also include an easily extensible, C-programmable Linux environment that enables datacenter architects to virtualize all resources in the cloud and make them appear as local. To understand why DPUs need this, I go back to what created the need for DPUs in the first place.
Why the world needs DPUs
One of the most important reasons why the world needs DPUs is that modern workloads and datacenter designs impose too much networking overhead on the CPU cores. With faster networking (now up to 200 Gb/s per link), the CPU just spends too much of its valuable cores classifying, tracking, and steering network traffic. These expensive CPU cores are designed for general purpose application processing, and the last thing needed is to consume all this processing power simply looking at and managing the movement of data. After all, application processing that analyzes data and produces results is where the real value creation occurs.
The introduction of compute virtualization makes this problem worse, as it creates more traffic on the server both internally–between VMs or containers—and externally to other servers or storage. Applications such as software-defined storage (SDS), hyperconverged infrastructure (HCI), and big data also increase the amount of east-west traffic between servers, whether virtual or physical, and often Remote Direct Memory Access (RDMA) is used to accelerate data transfers between servers.
Through traffic increases and the use of overlay networks such as VXLAN, NVGRE, or GENEVE, increasingly popular for public and private clouds, adds further complications to the network by introducing layers of encapsulation. Software-defined networking (SDN) imposes additional packet steering and processing requirements and adds additional burden to the CPU with even more work, such as running the Open vSwitch (OVS).
DPUs can handle all this virtualization (SR-IOV, RDMA, overlay network traffic encapsulation, OVS offload) faster, more efficiently, and at lower cost than standard CPUs.
Another reason: Security isolation
Sometimes, you might want to isolate the networking from the CPU for security reasons. The network is the most likely vector for a hacker attack or malware intrusion and the first place you’d look to detect or stop a hack. It’s also the most likely place to implement in-line encryption.
The DPU, being a NIC, is the first, easiest, best place to inspect network traffic, block attacks, and encrypt transmissions. This has both performance and security benefits, as it eliminates the frequent need to route all incoming and outgoing data back to the CPU and across the PCIe bus. It provides security isolation by running separately from the main CPU. If the main CPU is compromised, then the DPU can still detect or block malicious activity. The DPUs can work to detect or block attacks without immediately involving the CPU.
A newer use case for DPUs is to virtualize software-defined storage, hyperconverged infrastructure, and other cloud resources. Before the virtualization explosion, most servers just ran local storage, which is not always efficient but it’s easy to consume. Every OS, application, and hypervisor knows how to use local storage.
Then came the rise of network storage: SAN, NAS, and more recently NVMe over Fabrics (NVMe-oF). However, not every application is natively SAN-aware. Some operating systems and hypervisors, like Windows and VMware, don’t speak NVMe-oF yet. Something DPUs can do is virtualize networked storage, which is more efficient and easier to manage, to look like local storage, which is easier for applications to consume. A DPU could even virtualize GPUs or other neural network processors so that any server can access as many GPUs as it needs whenever it needs them, over the network.
A similar advantage applies to software-defined storage and hyperconverged infrastructure. Both use a management layer, often running as a VM or as a part of the hypervisor itself, to virtualize and abstract the local storage and the network to make it available to other servers or clients across the cluster. This is wonderful for rapid deployments on commodity servers and is good at sharing storage resources. However, the layer of management and virtualization soaks up many CPU cycles that should be running the applications. As with standard servers, the faster the networking runs and the faster the storage devices are, the more CPU must be devoted to virtualizing these resources.
Here again is where the intelligent DPU creates efficiencies. First, it offloads and helps virtualize the networking. They accelerate the private and public cloud, which is why they are sometimes called CloudNICs. They can offload both the networking and much or all the storage virtualization. DPUs can also offload a wide variety of functions for SDS and HCI, such as compression, encryption, deduplication, RAID, reporting, and so on. This is all in the name of sending more expensive CPU cores back to what they do best: running applications.
Figure 1. DPU is a programmable, specialized, electronic circuit board with hardware acceleration of data processing for datacentric computing
Must have hardware acceleration
Having covered the major DPU use cases, you know when you need them and where they can provide the greatest benefit. They must be able to accelerate and offload network traffic. They also might need to virtualize storage resources, share GPUs over the network, support RDMA, and perform encryption.
Now what are the top DPU requirements? First, all DPUs must have hardware acceleration. Hardware acceleration offers the best performance and efficiency, which also means more offloading with less spending. The ability to have dedicated hardware for certain functions is key to the justification for a DPU.
Must be programmable
For the best performance, most of the acceleration functions must run on hardware. For the greatest flexibility, the control and programming of these functions must run in software.
There are many functions that could be programmed on a DPU, a few of which are outlined in the feature table of my previous post. Usually, the specific offload methods, encryption algorithms, and transport mechanisms don’t change much, but the routing rules, flow tables, encryption keys, and network addresses change all the time. The former functions are the data plane and the latter functions are the control plane. The data plane rules and algorithms can be coded into silicon after they are standardized and established. The control plane rules and programming change too quickly to be hard-coded in silicon but can be run on an FPGA (modified occasionally, but with difficulty) or in a C-programmable Linux environment (modified easily and often).
DPU function
Use case
Run in hardware (data plane)
Run in hardware (control plane)
Packet inspection
Intrusion detection, firewall
Packet filtering, header inspection and rewrite
Rules, reporting, packet content inspection
Flow table processing
vRouter, OVS, firewall
Packet switching
Define switching rules and flow tables
Encryption
Security, privacy
Encryption/decryption
Key management
RDMA
Faster networking
Transport, networking
Addressing, connections
DPDK/OVS
NFV
Packet switching
Rules, reporting
VXLAN overlays
Private/public cloud
Encryption/decryption, VTFP
Overlay definitions
NVMe-oF
Flash storage
NVMe-oF protocol, RDMA
Connection setup, RAID, provisioning
Table 1. DPU function guidelines
How much programming has to live on the DPU?
You have a choice on how much of a DPU’s programming is done on the adapter. That is, the adapter’s handling of packets must be hardware-accelerated and programmable, but the control of that programming can live on the adapter or elsewhere. If it’s the former, we say the adapter has a programmable data plane for executing the packet processing rules and control plane for setting up and managing the rules. In the latter case, the adapter only does the data plane while the control plane lives somewhere else, like the CPU.
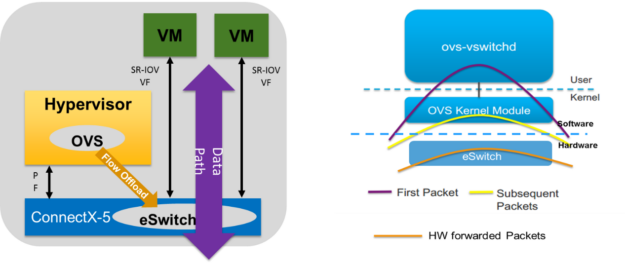
For example with Open vSwitch, the packet switching can be done in software or hardware, and the control plane can run on the CPU or on the DPU. With a regular foundational or dumb NIC, all the switching and control is done by software on the CPU. With a SmartNIC, the switching is run on the adapter’s ASIC but the control is still on the CPU. With a true DPU, the switching is done by ASIC-type hardware on the adapter while the control plane also runs on the adapter in easily programmable Arm cores.
Figure 2. ConnectX-5 SmartNIC offloads OVS switching to NIC hardware
Which is best, DPU or SmartNIC?
To achieve application efficiency in the datacenter, both transport offload and a programmable data path with hardware offload for virtual switching are vital functions. According to the definition, these functions are part of a SmartNIC and are table stakes on the path to a DPU. However, just transport and programmable virtual switching offload by themselves don’t raise a SmartNIC to the level of a DPU.
Customers often tell us they must have a DPU because they need programmable virtual switching hardware acceleration. This is mainly because another vendor competitor with an expensive, barely programmable offering has told them a “DPU” is the only way to achieve this. In this case, we are happy to deliver the same functionality with the ConnectX family of SmartNICs, which are very smart NICs after all.
But by my reckoning, there are a few more things required to take a NIC to the exalted level of a DPU, such as running the control-plane on the NIC and offering C-programmability with a Linux environment. In those cases, we’re proud to offer the BlueField DPU, which includes all the smarter NIC features of ConnectX adapters plus from 4 to 16 64-bit Arm cores, all running Linux, of course, and easily programmable.
As you plan your next infrastructure build-out or refresh, remember these key points:
DPUs are increasingly useful for offloading networking functions and virtualizing resources like storage, networking, and GPUs
SmartNICs (or smarter NICs) accelerate data plane tasks in hardware but run the control plane in software
The control plane software and other management software can run on the regular CPU or on a DPU.
NVIDIA offers best-in class, intelligent SmartNICs (ConnectX), FPGA NICs (Innova), and fully programmable data plan/control plane DPUs (BlueField programmable DPU).
For more information, see the following resources:
I’m a bit out of my depth here. I know just enough to use tensorflow’s object detection api to do transfer learning on a model from the model zoo, and train a custom object detector. What I’d like to do is add a confusion matrix to the tensorboard visualization I get when I run the main training script in the model garden repository. Currently, I get a bunch of scalar graphs (mAP, AR@K , loss) and images (visualization of model output vs gt). I don’t think I did anything special to create these visualizations. I assume they’re implemented somewhere, and i’m too new to know where. I found a pretty concise tutorial for adding a confusion matrix visualization to tensorboard here (https://towardsdatascience.com/exploring-confusion-matrix-evolution-on-tensorboard-e66b39f4ac12), but I don’t feel like I understand where I would ‘intervene’ or inject my changes into the model_main training script that i’m using (this is the one found in models/research/object_detection of tf’s ‘model garden’). If anyone has had a similar case, or knows of a demo that I might be able to follow I’d be grateful.

 The new Isaac simulation engine not only creates better photorealistic environments, but also streamlines synthetic data generation and domain randomization to build ground-truth datasets to train robots in applications from logistics and warehouses to factories of the future.
The new Isaac simulation engine not only creates better photorealistic environments, but also streamlines synthetic data generation and domain randomization to build ground-truth datasets to train robots in applications from logistics and warehouses to factories of the future.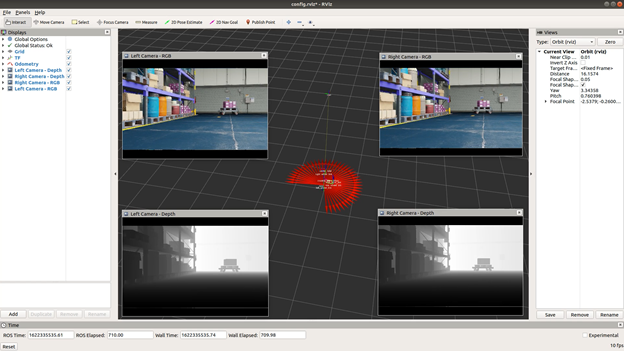
 This post explains why you need a DPU-based SmartNIC and discusses some Smart NIC use cases.
This post explains why you need a DPU-based SmartNIC and discusses some Smart NIC use cases.