
NVIDIA AI Platform Smashes Every MLPerf Category, from Data Center to EdgeSANTA CLARA, Calif., April 21, 2021 (GLOBE NEWSWIRE) — NVIDIA today announced that its AI inference platform, newly …
Category: Misc
 Recommender systems drive engagement on many of the most popular online platforms. As data volume grows exponentially, data scientists increasingly turn from traditional machine learning methods to highly expressive, deep learning models to improve recommendation quality. Often, the recommendations are framed as modeling the completion of a user-item matrix, in which the user-item entry is … Continued
Recommender systems drive engagement on many of the most popular online platforms. As data volume grows exponentially, data scientists increasingly turn from traditional machine learning methods to highly expressive, deep learning models to improve recommendation quality. Often, the recommendations are framed as modeling the completion of a user-item matrix, in which the user-item entry is … Continued
Recommender systems drive engagement on many of the most popular online platforms. As data volume grows exponentially, data scientists increasingly turn from traditional machine learning methods to highly expressive, deep learning models to improve recommendation quality. Often, the recommendations are framed as modeling the completion of a user-item matrix, in which the user-item entry is the user’s interaction with that item.
Most current online recommender systems are implicit rating-based, clickthrough rate (CTR) prediction tasks. The model estimates the probability of positive action (click), given user and item characteristics. One of the most popular DNN-based methods is Google’s Wide & Deep Learning for Recommender Systems, which has emerged as a general tool for solving CTR prediction tasks, thanks to its power of generalization (Deep) and memorization (Wide).
The Wide & Deep model falls into a category of content-based recommender models that are like Facebook’s deep learning recommendation model (DLRM), where input to the model consists of characteristics of the User and Item and the output is some form of rating.
In this post, we detail the new TensorFlow2 implementation of the Wide & Deep model that was recently added to the NVIDIA Deep Learning Examples repository. It provides the end-to-end training for easily reproducible results in training the model, using the Kaggle Outbrain Click Prediction Challenge dataset. This implementation touches on two important aspects of building recommender systems: dataset preprocessing and model training.
First, we introduce the Wide & Deep model and the dataset. Then, we give details on the preprocessing completed in two variants, CPU and GPU. Finally, we discuss aspects of model convergence, training stability, and performance, both for training and evaluation.
Wide & Deep model overview
Wide & Deep refers to a class of networks that use the output of two parts working in parallel—a wide model and a deep model—to make binary prediction of CTR. The wide part is a linear model of features together with their transforms, responsible for the memorization of feature interactions. The deep part is a series of fully connected layers, allowing the model better generalization for unseen cross-features interactions. The model can handle both numerical continuous features as well as categorical features represented as dense embeddings. Figure 1 shows the architecture of the model. We changed the size of the deep part from the original of 1024, 512, 256 into five fully connected layers of 1024 neurons.
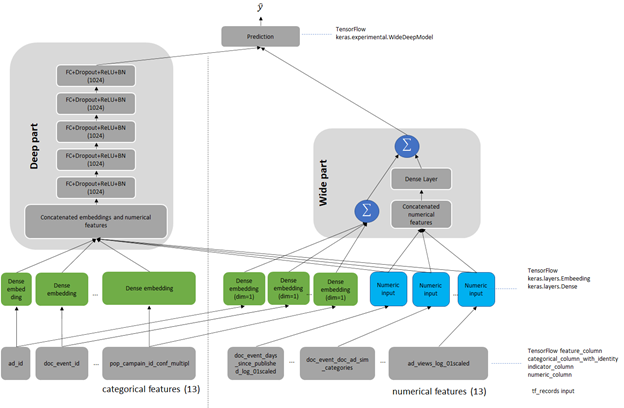
Outbrain dataset
The original Wide & Deep paper trains on the Google Play dataset. Because this data is proprietary to Google, we chose a publicly available dataset for easy reproduction. As a reference dataset, we used the Kaggle Outbrain Click Prediction Challenge data. This dataset is preprocessed to obtain a subset of the features engineered by the 19th-place finisher in the Kaggle Outbrain Click Prediction Challenge. This competition challenged competitors to predict the likelihood of a clickthrough for a particular website ad. Competitors were given information about the user, display, document, and ad to train their models. For more information, see Outbrain Click Prediction.
The Outbrain dataset is preprocessed to get feature input for the model. Each sample in the dataset consists of features of the Request (User) and Item, together with a binary output label. Request-level features describe the person and context to which to make recommendations, whereas Item-level features describe those objects to consider recommending. In the Outbrain dataset, these are ads. Request– and Item-level features contain both numerical features that you can input directly to the network. Categorical variables are represented as trainable embeddings of various dimensions. For more information about feature counts, cardinalities, embedding dimensions, and other dataset characteristics, see the WideAndDeep readme file on GitHub.
Preprocessing
As in every other recommender system, preprocessing is a key for efficient recommendation here. We present and compare two dataset preprocessing workflows: Spark-CPU and NVTabular GPU. Both produce datasets of the same number, type, and meaning of features so that the model is agnostic to the type of dataset preprocessing used. The presented preprocessing aims to produce the dataset in a form of pre-batched TFRecords to be consumed by the data loader during model training.
Scope of preprocessing
The preprocessing is described in detail in the readme of the Deep Learning Examples repository. In this post, we give only the outlook on the scope of data wrangling to create the final 26 features: 13 categorical and 13 numerical, obtained from the original Outbrain dataset. Both of the workflows consist of the following operations:
- Separating out the validation set for cross-validation.
- Filling missing data with mode, median, or imputed values.
- Joining click data, ad metadata, and document category, topic, and entity tables to create an enriched table.
- Computing seven CTRs for ads grouped by seven features.
- Computing the attribute cosine similarity between the landing page and featured ad.
- Math transformations of the numeric features (logarithmic, scaling, and binning).
- Categorizing data using hash-bucketing.
- Storing the resulting set of features in pre-batched TFRecord format.
Comparison of preprocessing workflows
To compare the NVTabular and Spark workflows, we built both from a known-good Spark-CPU workflow, included in the NVIDIA Wide & Deep TensorFlow 2 GitHub repository. For simplicity, we limited the number of dataset features to calculate during preprocessing. We chose the most common ones used in recommender systems that both workflows (Spark and NVTabular) support. Because NVTabular is a relatively new framework still in active development, we limited the scope of comparison to features supported by the NVTabular library.
When comparing Spark and NVTabular, we extracted the most important metrics that influence the choice of framework in target preprocessing. Table 1 presents a snapshot comparison of two types of preprocessing using the following metrics:
- Threshold result. The necessity of achieving MAP@12 greater than the arbitrary chosen threshold of 0.655 for the Outbrain dataset.
- Source code lines. The lines needed to achieve the set of features that the model uses for training. This single metric tries to capture how difficult it is to create and maintain the production code. It also gives an intuition about the level of difficulty when experimenting with adding new dataset features or changing existing ones.
- Total RAM consumption. This estimates the size and type of machine needed to perform preprocessing.
- Preprocessing time that is critical for recommender systems. In production environments where you must retrain the model with new data, this metric is strictly bounded with the necessity of dataset preprocessing. You can remove a too-long preprocessing time for some applications. When that time is short, you can even include the preprocessing in end-to-end training. Test the hypothesis of variable importance with the hyperparameter tuning of the network.
We did not enforce 1:1 parity between the datasets, as convergence accuracy proves the validity of the features.
| CPU preprocessing: Spark on NVIDIA DGX-1 | CPU preprocessing: Spark on NVIDIA DGX A100 | GPU preprocessing: NVTabular on DGX-1 8-GPU | GPU preprocessing: NVTabular DGX A100 8-GPU | |
| Lines of code | ~1,500 | ~1,500 | ~500 | ~500 |
| Top RAM consumption [GB] | 167.0 | 223.4 | 48.7 | 50.6 |
| Top VRAM consumption per GPU [GB] | 0 | 0 | 13 | 67 |
| Preprocessing time [min] | 45.6 | 38.5 | 3.9 | 2.3 |
Convergence accuracy
On the chosen metric for the Outbrain dataset, Mean Average Precision at 12 (MAP@12), both the features produced by Spark-CPU and NVTabular achieve similar convergence accuracy, MAP@12>0.655.
Hardware requirements
You can run the NVTabular and Spark-CPU versions on DGX-1 V100 and DGX A100 supercomputers. Spark-CPU consumes around 170 GB of RAM while the RAM footprint of NVTabular is about 3x smaller. NVTabular can run successively even on a single-GPU machine and still be an order of magnitude faster than Spark-CPU without the need of memory-optimized computers.
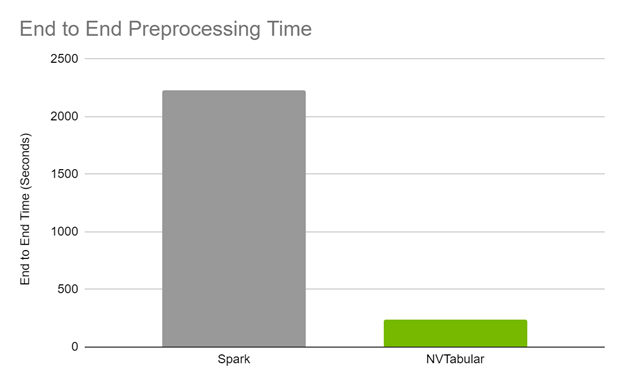
End-to-end preprocessing time
The end-to-end preprocessing time is 17x faster on GPU for DGX A100 and 12x on GPU on DGX-1 comparing Spark CPU and NVTabular GPU preprocessing.
Code brevity and legibility
The Spark code to generate the features spans over approximately 1,500 lines, while the NVTabular code is about 500 lines. The brevity in the NVTabular workflow also lends itself to legibility, as fewer lines of code and descriptive function signatures make it obvious what a given line is trying to accomplish.
The following list contains samples with side-to-side comparisons of Spark and NVTabular, showing the increase of code brevity and legibility in favor of NVTabular. The operation used in both is taking the TF-IDF cosine similarity between an ad and its landing page.
Model training and evaluation
Training the model is analyzed based on the following criteria:
- Reaching evaluation metrics.
- Fast and stable training (forward and backward pass): Constantly reaching an evaluation metric not dependent on initialization, hardware architecture, or other training features.
- Fast scoring of the evaluation set: Reaching performance throughput to mimic model’s behavior in production.
We used the Mean Average Precision at 12 (MAP@12) metric, the same as used in the original Outbrain Kaggle competition. Direct comparison of the obtained accuracies is unjustified because, for the original Kaggle competition, there were data leaks that could be artificially used for post-processing of model results, resulting in higher MAP@12 score.
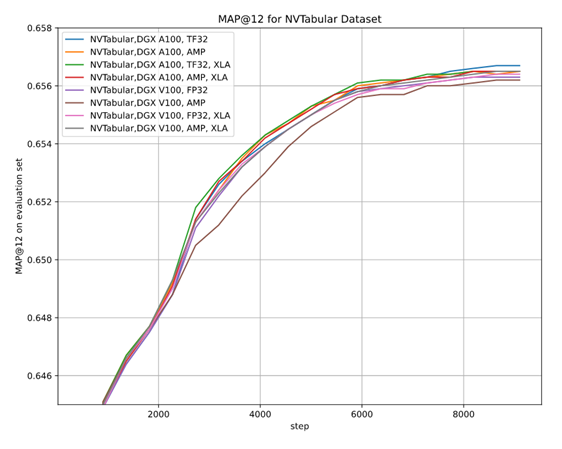
As there are multiple options for setups—two hardware architectures (A100 and V100), multiple floating-point number precisions (FP32, TF32, AMP), two versions of preprocessing (Spark-CPU and NVTabular), and the XLA optimizer, it is essential to be sure that the convergence is achieved in each setup. We performed multiple stability tests for accuracy that prove achieving MAP@12 above the selected threshold, regardless of training setup, training stability, and the impact of AMP on accuracy.
Training performance results
As stated earlier, we wanted the model to be fast in training. You can measure this in two ways: by the model throughput [samples/s] and time to train [min]. When training on CPU compared to GPU, you can experience speedups up to 108x for the NVIDIA Ampere Architecture and TF32 precision (Figure 4).
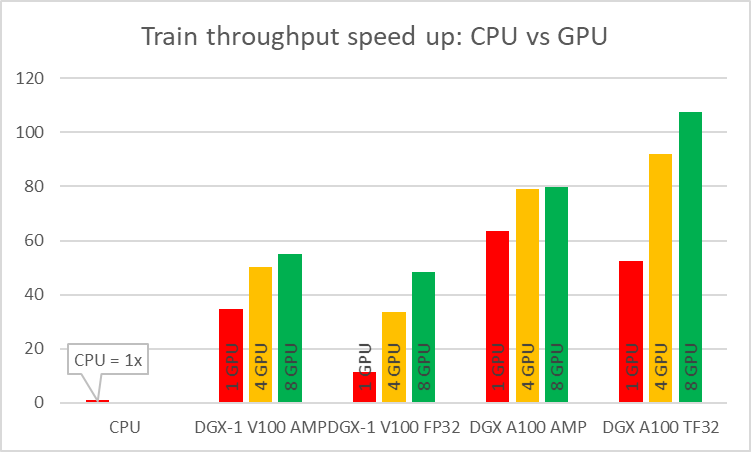
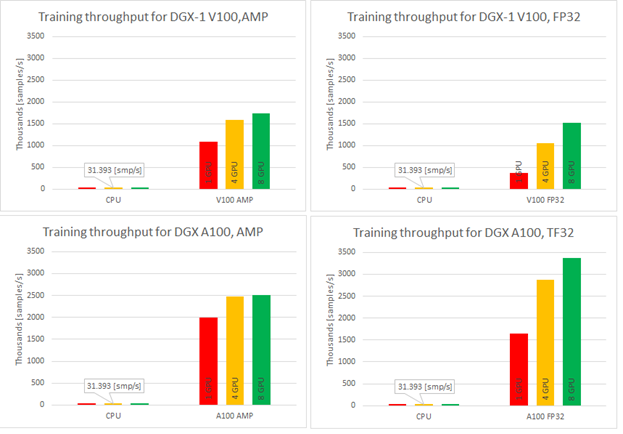
Single-GPU configurations experience up to 1.2x speedup while using AMP for Ampere architecture. This number is even better for Volta, where the speedup is over 3x. Introducing multi-GPU training in a strong scaling mode ends up in speedups of 1.2x–4.6x in comparison to single-GPU training. Comparison of Ampere and Volta architectures for FP32 and TF32 training, respectively, shows a speedup of 2.2x (single GPU) to 4.5x (eight GPUs). Ampere is also 1.4x– 1.8x faster than Volta for AMP training. Bearing in mind that you don’t lose any accuracy with AMP, XLA and multi-GPU, this brings a huge value to recommender systems models.
Training time improves significantly when training on GPU in comparison to CPU and for best configuration is faster over 100x. TFRecords dataset consumes around 40GB of disk space. For best configuration of training (8x A100, TF32 precision, XLA on) this implementation of the Wide & Deep model performs a 20-epoch training within eight minutes, resulting in less than 25[s] per epoch during training.
Evaluating performance results
Having a model that trains with such throughput is beneficial. In fact, in offline scenarios, another parameter is important: how fast you can evaluate all pairs of users and items. If you have 106 distinct users and only 103 distinct items, that gives you 109 different user-item pairs. Fast evaluation on training models is a key concept. Figure 6 shows the evaluation performance for A100 and V100 varying batch size.
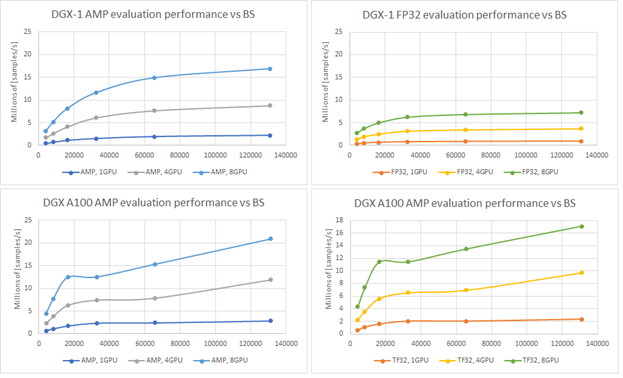
Recommendation serving usually reflects the scenario that a single batch contains scoring all items for a single user. Using the presented native evaluation, you might expect over 1,000 users scored for 4,096 batch (items) for eight GPUs A100 in TF32 precision.
End-to-end training
We define the end-to-end training time to be the entire time to preprocess the data and train the model. It is important to account for these two steps, because the feature engineering steps and training with accuracy measurement are repeated. Shortening the end-to-end training is the equivalent of bringing the model to production faster or performing more experiments at the same time. With GPU preprocessing, you can experience a massive decrease in end-to-end training (Figure 7).
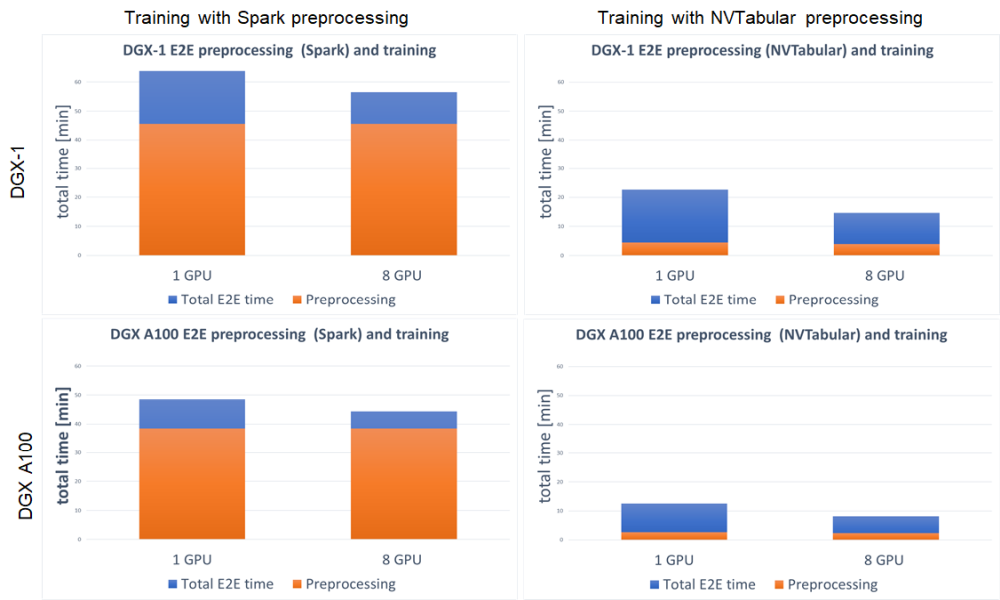
For both DGX-1 and DGX A100, the speedup in end-to-end training is tremendous. Because this setup involved training the model on GPU for both Spark and NVTabular, the speedup comes from the preprocessing steps. It results in up to 3.8x faster end-to-end training for DGX-1 and up to 5.4x for DGX A100. When using GPU for preprocessing the fraction, the important aspect is the decreased time that the preprocessing step takes in total end-to-end training, from ~75% for Spark GPU down to ~25% for NVTabular.
Summary
In this post, we demonstrated an end-to-end preprocessing and training pipeline for the Wide & Deep model. We showed you how to get at least a 10x reduction in dataset preprocessing time using GPU preprocessing with NVTabular. Such an incredible speedup enables you to quickly verify your hypotheses about the data and bring new features to production.
We also showed the stability of training while reaching the evaluation score of MAP@12 for multiple training setups:
- NVIDIA Ampere Architecture
- NVIDIA Volta Architecture
- Multi-GPU training
- AMP training
- XLA
Thanks to the great speedup that these features provide, you can train on the 8-GB dataset in less than 25s/epoch. The model throughput compared to CPU is over 100x higher on GPU. Finally, we showed the evaluation throughput that achieves 21Mln [samples] from a model checkpoint.
Future work for the Wide & Deep TensorFlow 2 implementation will concentrate on inference in Triton Server, improving the data loader to support parquet input files, and upgrading preprocessing in NVTabular to a recently released API version.
We encourage you to check our implementation of the Wide & Deep model in the NVIDIA DeepLearningExamples GitHub repository. In the comments, please tell us how you plan to adopt and extend this project.
Categories
Aligning Time Series at the Speed of Light
 To say it with the words of Eamonn Keogh: “Time series is a ubiquitous and increasingly prevalent type of data […]”. Virtually any incrementally measured signal, be it along a time axis or a linearly ordered set, can be treated as time series. Examples include electrocardiograms, temperature or voltage measurements, audio, server logs, but also … Continued
To say it with the words of Eamonn Keogh: “Time series is a ubiquitous and increasingly prevalent type of data […]”. Virtually any incrementally measured signal, be it along a time axis or a linearly ordered set, can be treated as time series. Examples include electrocardiograms, temperature or voltage measurements, audio, server logs, but also … Continued
To say it with the words of Eamonn Keogh: “Time series is a ubiquitous and increasingly prevalent type of data […]”. Virtually any incrementally measured signal, be it along a time axis or a linearly ordered set, can be treated as time series. Examples include electrocardiograms, temperature or voltage measurements, audio, server logs, but also heavy-weight data such as video and time-resolved MRI volumes. Hence, the efficient yet exact processing of the ever-increasing amount of time series data is crucial for every data scientist.
In this blog, we introduce rapidAligner – a CUDA-accelerated library to align a short time series snippet (query) in an exceedingly long stream of time series (subject) using the following three popular lock-step measures for the local alignment of uniformly sampled time series:
- Rolling Euclidean distance (sdist)
- Rolling mean-adjusted Euclidean distance (mdist)
- Rolling mean and amplitude-adjusted Euclidean distance (zdist)
The rapidAligner library is free software that can be integrated with a broad variety of popular data science and machine learning frameworks such as NumPy, CuPy, RAPIDS, Numba, and Pytorch. The source code is publicly available under NVIDIA rapidAligner.
The rest of the article is structured as follows: Section one provides a brief introduction on popular lock-step measures and (local) normalization techniques. Section two demonstrates the usage of the rapidAligner library. Section 3 concludes this blog post.
A brief introduction to time series data mining
Time series are sequences of pairs (t[i], x[i]) where the real-valued time stamps t[i] are linearly ordered and their corresponding values x[i] are quantities measured at time t[i]. If all timestamps are equally spaced, i.e., t[i+1]-t[i] = const for all i, then you can neglect time and call the sequence of measurements x[i] a uniformly sampled time series. In the following, we will simply refer to uniformly sampled time series with real-valued scalars x[i] as time series without fancy attributes.
Assume you want to compare two time series Q=(q[0], q[1], …, q[m-1]) and S=(s[0], s[1], …, s[m-1]) of same length |Q|=|S|=m. An obvious way would be to interpret Q and S as m-dimensional vectors and compute the Lp norm of their difference.
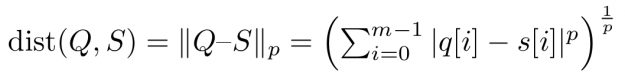
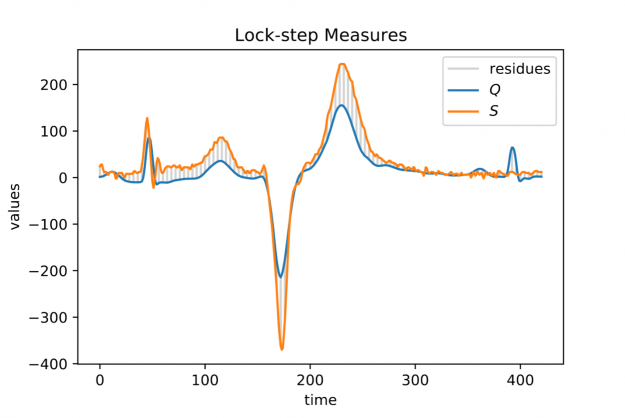
Popular choices for the parameter p are p=2 for so-called Euclidean distance and p=1 for so-called Manhattan or taxicab distance (see Figure 1). In this blog post, we address similarity measures that compare residues q[i]-s[i] using a one-to-one assignment i->i of indices – so-called lock-step measures. In a future post, we will discuss CUDA-accelerated measures using dynamic assignments of indices such as q[i]-s[j], also known as the class of elastic measures.
However, when aligning a short query Q of length |Q|=m in a long stream S of length |S|=n, i.e., 0
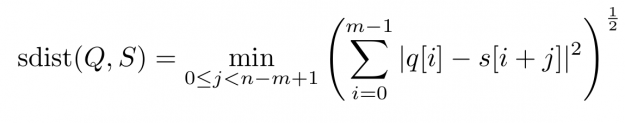
For each alignment position j you have to sum over m contributions. As a result, the asymptotic worst-case complexity to compute all lock-step alignments is proportional to the product of the time series lengths m and n — O((n-m+1) * m) to be precise. This number can be huge even for moderately sized queries and streams which may render large scale time series alignment computationally intractable when performed in a naïve way. In Section 3 we will discuss for the special case p=2 how to implement a CUDA-accelerated scheme which runs in blazingly fast log-linear time.
When looking at larger portion of an ECG stream (see Figure 2) you may observe a temporal drift in the average signal value, also known as baseline wandering. This artifact often occurs in continuously measured time series and may be caused by a broad variety of external factors such as change of skin conductivity due to sweat in ECGs, body movement affecting the electrodes in ECGs, drift of electric resistance and thus voltage due to temperature variation in power supplies, temperature drift when recording environmental quantities, seasonal effects such as Christmas, or the temporal drift of stock prices amidst a global pandemic.
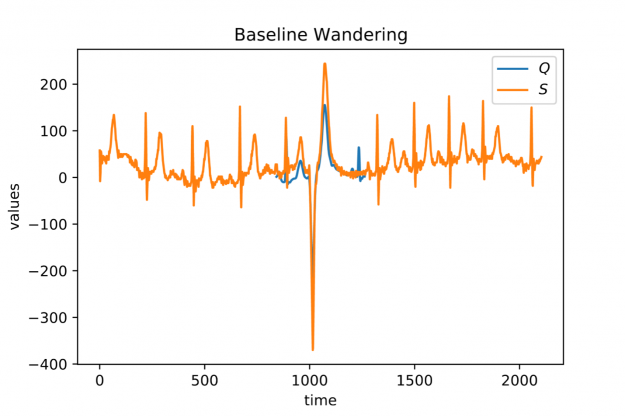
Baseline wandering is problematic when mining a stream for similar shapes – two similar shapes with different offsets on the measurement axis may have a larger distance than two dissimilar ones with similar offsets. A surprisingly simple and effective countermeasure is to introduce a normalization procedure for the query and candidate sequences. As an example, you could compute the mean value of the query muQ and for each of the n-m+1 candidate sequences muS[j] to remove the offset in the corresponding window (see Figure 3). In the following, we will call locally mean-adjusted rolling Euclidean distance mdist:
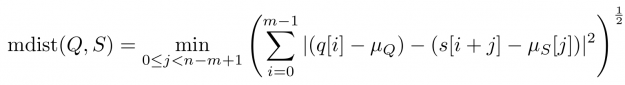
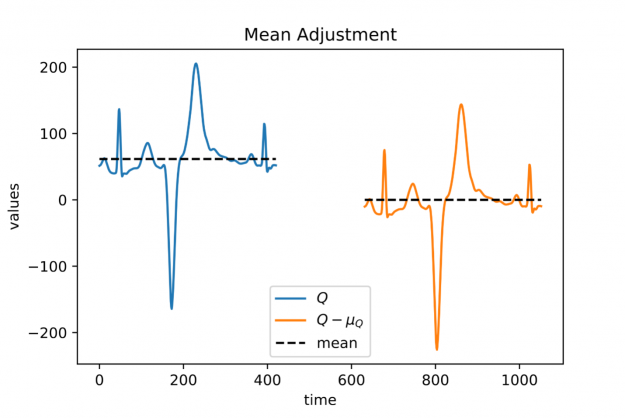
A closer look at Figure 1 and Figure 2 further reveals a temporal variation in amplitudes. The range of values in the blue query is significantly smaller than the amplitude of the orange candidate sequence in Figure 1. Temporal drift in the scale might lead to meaningless matches when mining shapes. A straightforward solution is to normalize the scale by dividing the values by the standard deviation of the query sigmaQ and alignment candidates sigmaS[j], respectively. The proposed mean and amplitude adjustment is called z-normalization referring to z-scores of normal random variables with vanishing mean and unit variance (see Figure 4). The corresponding rolling measure shall be called zdist:
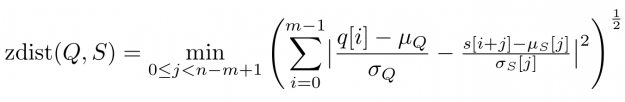
The library rapidAligner supports the CUDA-accelerated computation of the three aforementioned rolling measures sdist, mdist, and zdist in a massively parallel fashion. In the next section, you will see its simple usage from within JupyterLab.
rapidAligner in action
Let’s start crunching numbers. In this section, you will align a single heartbeat in a 22 hour ECG stream using the three discussed measures sdist, mdist, and zdist. The data set is part of the experiments listed on the website of the award-winning UCR-Suite. After cloning the rapidAligner repository you immediately import the rapidAligner library alongside with CuPY, NumPy, and Matplotlib for later validation and visualization.
In the next step, you load the ECG data. The length of the query is rather short with 421 entries, yet the stream exhibits roughly 20 million time ticks. A first inspection of the full query (blue) and the initial 1000 values of the stream (orange) reveals temporal drift in both offsets and amplitudes.
In the following, you align the query in the stream using the sdist measure computing all 20,140,000-421+1 distance scores a subsequent argmin-reduction to determine the best alignment position. For our experiments we choose a single A100 GPU in a DGX A100 server. Note that if you are only interested in the best match one could further accelerate the already rapid computation by employing a lower-bound cascade as demonstrated here. In contrast, rapidAligner’s sdist call returns alignment scores for all positions to allow for later processing such as computing a non-overlapping partition of ranked matches. We further repeat the alignment a few times for robust runtime measurement. Both compute modes “fft” and “naive” are blazingly fast and return indistinguishable results:
- “naive”: all n-m+1 alignment candidates are (optionally) normalized and compared individually with a minimal memory footprint but O(n*m) asymptotic computational complexity. This mode is still reasonably fast using warp-aggregated statistics and accumulation schemes.
- “fft”: If m > log_2(n), we can exploit the Convolution Theorem to accelerate the computation significantly resulting in O(n * log n) runtime but a higher memory footprint. This compute mode is fully independent of the query’s length and thus advisable for large input. The higher memory usage is mainly caused by computationally fast but out-of-place primitives such as CUDA-accelerated Fast Fourier Transforms and Prefix Scans.
Both the query and stream (subject) are stored as plain NumPy arrays in double precision on the CPU. As a result, the measured runtimes include costly memory transfers between the CPU and GPU. rapidAligner allows for seamless interoperability with all CUDA array interface compliant frameworks such as PyTorch, CuPy, Numba, RAPIDS, and Jax. Hence, you can further reduce the runtime when caching the data in fast GPU RAM to avoid unnecessary memory movement between CPU and GPU. Now, it becomes even more obvious that the Fourier based mode outperforms the naïve one even on short queries
That corresponds to a whopping 2.5 billion full alignments per second on a single GPU. In the following, we report runtimes exclusively using input data residing on the GPU. The match produced by sdist is already a good one but let us check if mean-adjustment improves the result:
As expected, mean adjustment returns a better match since now candidates are considered with a non-vanishing relative offset along the measurement axis. The execution times remain low with 10 ms for 20 million alignment positions. That corresponds to 2 billion full alignments per second. You could still improve the amplitude mismatch using zdist:
Et voilà, z-normalized rolling Euclidean distance reveals a doppelgänger in the database which is almost indistinguishable from the query. Performance remains high in more than 1.6 billion alignments per second. A stunning property of the Fourier mode is that the runtime is effectively independent of the query length, i.e., the runtime is constant for fixed stream length and varying query size. This becomes handy when aligning extra-ordinarily long queries.
Conclusion
Finding shapes in long streams of time series data is a computationally demanding task frequently occurring as a standalone routine or embedded as a subroutine in high-level algorithms, e.g., for the detection of anomalies. Hence, massively parallel accelerators with their unprecedented memory bandwidth such as the NVIDIA A100 GPU are ideally suited to address this challenge. rapidAligner is lightweight library processing billions of alignments per second while supporting common normalization modes for the candidate sequences. You can further employ highly optimized FFT routines cuFFT and prefix scans CUB from the CUDA-X software stack to provide an alignment mode that is independent from the query length. The source code and notebooks are publicly available under NVIDIA rapidAligner
Happy time series mining!


|
submitted by /u/xusty [visit reddit] [comments] |
No Thursday is complete without GFN Thursday, our weekly celebration of the news, updates and great games GeForce NOW members can play — all streaming from the cloud across nearly all of your devices. This week’s exciting updates to the GeForce NOW app and experience Include updated features, faster session loading and a bunch of Read article >
The post Update Complete: GFN Thursday Brings New Features, Games and More appeared first on The Official NVIDIA Blog.
GFN Thursday reaches a fever pitch this week as we take a deeper look at two major updates coming to GeForce NOW from Deep Silver in the weeks ahead. Catching Even More Rays Metro Exodus was one of the first RTX games added to GeForce NOW. It’s still one of the most-played RTX games on Read article >
The post GFN Thursday: Rolling in the Deep (Silver) with Major ‘Metro Exodus’ and ‘Iron Harvest’ Updates appeared first on The Official NVIDIA Blog.
Categories
Idea about Feature extraction
I am currently working on a system that extracts certain features out of 3D-objects (Voxelgrids to be precise), and i would like to compare those features to automatically made features when it comes to performance (classification) in a tensorflow cNN with some other data, but that is not the point here, just for background. My idea now was, to take a dataset (modelnet10), train a tensorflow cNN to classify them, and then use what it learned there on my dataset – not to classify, but to extract features.
So i want to throw away everything the cnn does,except for what it takes from the objects.
Is there anyway to get these features? and how do i do that? i certainly have no idea.
any ideas would be greatly appreciated.
submitted by /u/schlorkyy
[visit reddit] [comments]
Categories
Weird phenomenon with the Dataset API
I am developing a training pipeline, for which the tf nodes look like as follows:
index = tf.data.Dataset.from_tensor_slices(self.indices) if self.shuffle: index = index.shuffle(buffer_size=len(self.indices) images = index.map(self.make_image) coordinates = index.map(self.get_coordinates) ground_truth = coordinates.map(self.make_ground_truth) images = images.padded_batch(...) ground_truth = ground_truth.batch(...) return tf.data.Dataset.zip((images, ground_truth))
If executing the above code with shuffle == False, everything works fine. If shuffle is set to True, it seems the images and ground truths are somehow shuffled differently.
Is this an intended behaviour? How could this be easily solved?
Edit: I am using TensorFlow 2.0, but 2.1 also produces this behaviour
Edit2: Further investigation revealed further weirdness. So it seems, it is not specific to the Dataset.shuffle() method, its root cause is that there is branching in the chain of transformations. Correct me if I’m wrong, but somehow the branching causes the dataset to re-sample the same index as many times as many branches originate from the given node. If there is no shuffling, the re-sampling works as expected, but shuffling causes different indices to be fed to different branches.
I also switched to Dataset.from_generator() and I shuffle the indices in the generator (in NumPy) and it still produces the same bug.
Do you guys think this is a bug in TF? should I file an issue about this?
Or is my approach completely wrong? How could this situation be handled differently?
submitted by /u/CarpenterAcademic
[visit reddit] [comments]
Autonomous vehicles don’t just need to detect the moving traffic that surrounds them — they must also be able to tell what isn’t in motion.
The post Perceiving with Confidence: How AI Improves Radar Perception for Autonomous Vehicles appeared first on The Official NVIDIA Blog.
Categories
HPL-AI Now Runs 2x Faster on NVIDIA DGX A100
 NVIDIA announced its latest update to the HPL-AI Benchmark version 2.0.0, which will reside in the HPC-Benchmarks container version 21.4.
NVIDIA announced its latest update to the HPL-AI Benchmark version 2.0.0, which will reside in the HPC-Benchmarks container version 21.4.
NVIDIA announced its latest update to the HPL-AI Benchmark version 2.0.0, which will reside in the HPC-Benchmarks container version 21.4. The HPL-AI (High Performance Linpack – Artificial Intelligence) benchmark helps evaluate the convergence of HPC and data-driven AI workloads.
Historically, HPC workloads are benchmarked at double-precision, representing the accuracy requirements in computational astrophysics, computational fluid dynamics, nuclear engineering, and quantum computing. AI workloads on the other hand can deliver acceptable results using much lower precision for training and inference. This distinctive characteristic led to the development of technology such as the Tensor Cores. Tensor Cores provide substantial speedups in mixed-precision workloads by accelerating precisions such as TF32, BF16, FP16, INT8, and INT4.
Many vendors provide specially tuned versions of HPL for their hardware. NVIDIA is releasing the NVIDIA HPC-Benchmarks container on NGC. This container includes three different versions of the HPL benchmark for double precision arithmetic; HPL-AI, applied to mixed precision workloads, and HPCG, which performs a fixed number of multigrid preconditioned conjugate gradient (PCG) iterations at double precision.
With this latest release, the HPL-AI benchmark deliveries double the performance over the initial container released in Fall 2020. This is largely due to major improvements to load balancing at the communication layers. Multi-node communications are usually handled by the CPU, which can lead to performance bottlenecks if GPU become idle. MPI-aware communication between GPUs allows the CPU to be bypassed and keep the GPU busy. When possible data transfers are sent at a lower precision reducing the time GPUs are waiting for data. After minimizing communication, GPUs can process larger datasets to provide maximum compute efficiency. Lastly, the latest version of the NVIDIA Math Libraries are used to deliver optimal performance on an A100.
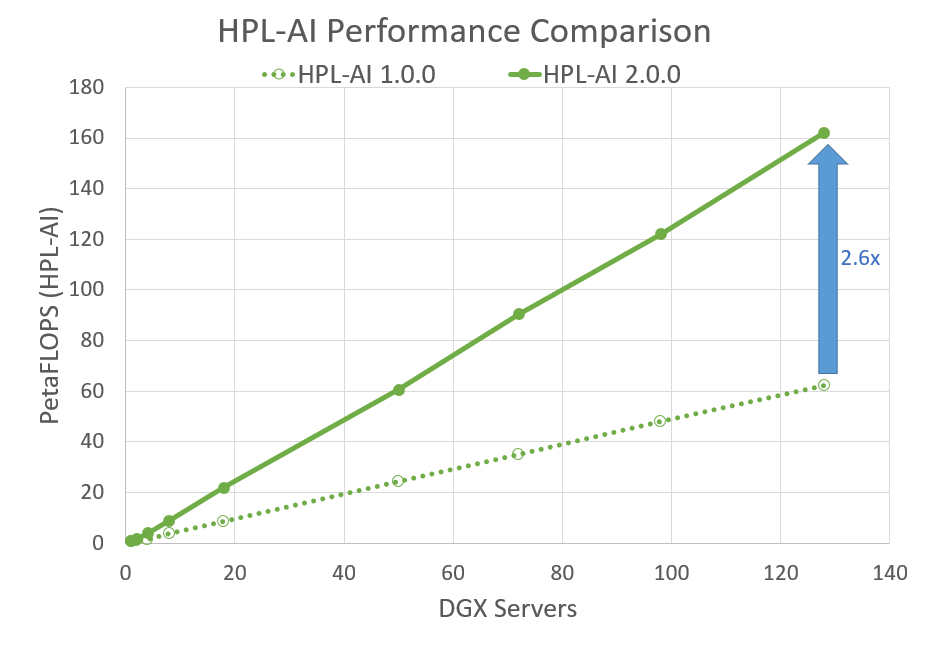
The plot below shows that with 128 DGX A100s, or 1024 NVIDIA A100 GPUs, the latest release of HPL-AI performs 2.6 times faster.
To checkout these improvements, download the latest NVIDIA HPC-Benchmark container, version 21.4, from NGC. The HPC-Benchmark landing page includes detailed instructions and additional resources. If you have any questions or issues, please send email to HPCBenchmarks@nvidia.com.