
submitted by /u/limapedro
[visit reddit] [comments]
 Get the latest on NVIDIA AI Enterprise on VMware Cloud Foundation, VMware Cloud Director, and new curated labs with VMware Tanzu and Domino Data.
Get the latest on NVIDIA AI Enterprise on VMware Cloud Foundation, VMware Cloud Director, and new curated labs with VMware Tanzu and Domino Data.
The new year has been off to a great start with NVIDIA AI Enterprise 1.1 providing production support for container orchestration and Kubernetes cluster management using VMware vSphere with Tanzu 7.0 update 3c, delivering AI/ML workloads to every business in VMs, containers, or Kubernetes.
New LaunchPad labs
New NVIDIA AI Enterprise labs for IT admins and MLOps are available on NVIDIA LaunchPad:
- VMware vSphere with Tanzu
- Domino Enterprise MLOps platform
NVIDIA AI Enterprise with VMware vSphere with Tanzu
Enterprises can get started quickly with NVIDIA AI Enterprise running on VMware vSphere with Tanzu through the free LaunchPad program that provides immediate, short-term access to NVIDIA AI running on private accelerated compute infrastructure.
A newly added curated lab gives you hands-on experience using VMware Tanzu Kubernetes Grid service to manage a containerized workload using the frameworks provided in the NVIDIA AI Enterprise software suite. In this lab, you can configure, optimize, and orchestrate resources for AI and data science workloads with VMware Tanzu. You get experience using the NGC registry, NVIDIA operators, Kubernetes, and server virtualization, all by running vSphere with Tanzu on NVIDIA-Certified Systems.
NVIDIA AI Enterprise with the Domino Enterprise MLOps platform
MLOps administrators also have something to get excited about, with the addition of another new curated lab available soon on NVIDIA LaunchPad.
NVIDIA AI Enterprise provides validation for the Domino Data Lab Enterprise MLOps Platform with VMware vSphere. Enterprises can run through the lab and get hands-on experience on how to scale data science workloads with the Domino MLOps platform. Data scientists and AI researchers will be able to launch the Domino Workspaces on-demand with container images configured with the latest data science tools and frameworks, included in NVIDIA AI Enterprise, accelerated with NVIDIA GPUs.
The Domino MLOps Platform enables automatic storing and versioning of code, data, and results. When IT administrators try this lab, they use familiar management tools provided by VMware vSphere with Tanzu. Deployed on NVIDIA-Certified Systems, IT now has the confidence of enterprise-grade security, manageability, and support.
New AI Enterprise integrations with VMware
Service providers, telcos, and hybrid cloud enterprises using VMware now have access to NVIDIA AI on the following products:
- VMware Cloud Foundation
- VMware Cloud Director
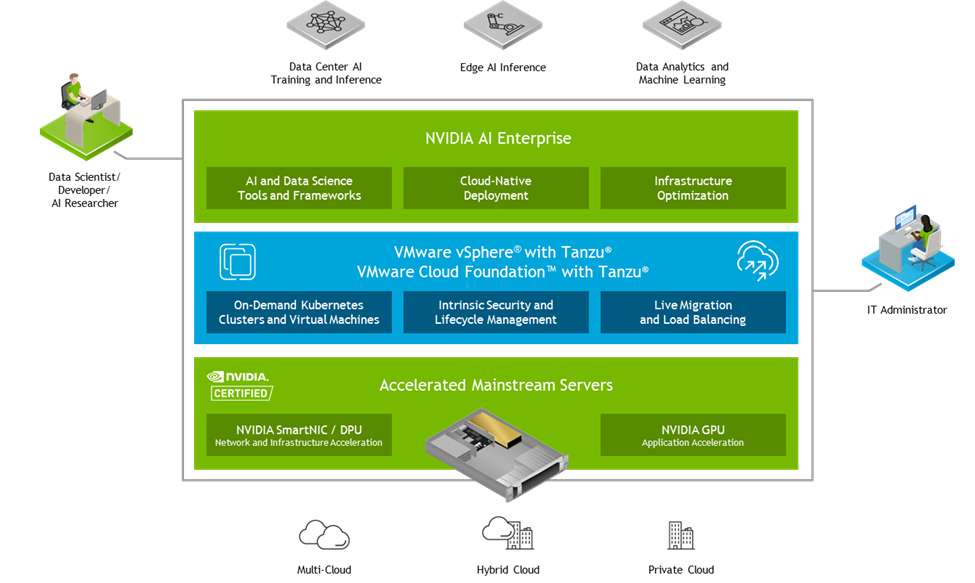
Enterprise AI together with VMware Cloud Foundation
NVIDIA and VMware have expanded support for NVIDIA AI Enterprise to VMware’s flagship hybrid-cloud platform, VMware Cloud Foundation 4.4. Further democratizing AI for every enterprise, the AI-Ready enterprise platform combines the benefits of the full stack VMware Cloud Foundation environment with the NVIDIA software suite running on GPU accelerated mainstream servers that are NVIDIA-Certified. This provides you with the tools and frameworks you need for successfully developing and deploying AI, while enabling IT administrators with full control of infrastructure resources.
The integration of VMware Cloud Foundation with Tanzu and NVIDIA AI Enterprise enables enterprises to extend their software-defined private cloud platform to support a flexible and easily scalable AI-ready infrastructure. Administrators can deploy, configure, and manage IT infrastructure in an automated fashion, using powerful tools like vSphere Distributed Resource Scheduler for initial placement and VMware vMotion for migration of VMs running NVIDIA GPUs.
IT admins benefit from this integration, but so do AI practitioners who can now easily consume admin-assigned resources for their AI and data analytics workloads to get them from development and deployment to scaling quickly.
Addressing the growing demand for AI in the cloud with VMware Cloud Director
As cloud providers are seeing increased demand from customers for modern applications that require accelerated compute, VMware Cloud Director 10.3.2 has added support for NVIDIA AI Enterprise. These service providers can now leverage vSphere support to run AI/ML workloads on NVIDIA Ampere-based GPUs with capabilities like vMotion, multi-tenancy GPU services combined with the most fundamental AI tools and frameworks all managed through VMware Cloud Director.
NVIDIA AI Enterprise with VMware Cloud Director enables industries like cloud service providers and telcos to provide new services for their customers. One example is intelligent video analytics (IVA) using GPU-accelerated computer vision to provide real-time insights for boosting public safety, lowering theft, and improving customer experiences.
Start your AI journey
Get started with NVIDIA AI Enterprise on LaunchPad for free. Apply now for immediate access to the software suite running on NVIDIA-Certified Systems.
Come join us at GTC, March 21-24 to hear and see NVIDIA, VMware, and our partners share more details about these new and exciting integrations. Register today.
Categories
What happens during validation in keras?
Hello I am training a model for semantic segmentation using dice loss and as a metric.
model.compile(...., loss=diceLoss, metrics=[dice_coef])
I noticed that in an epoch, the loss and dice_coef are equal. However, val_loss is never equal val_dice_coef. What is the reason behind that? I feel like something is being done (turned on/off) during validation.
I hope any of this makes sense. Thanks!
Edit: i am using segmentation-models library, using a unet with pretrained weights. I tried looking into the source code; but I couldn’t figure out what’s happening.
submitted by /u/potato-question-mark
[visit reddit] [comments]
 Building one-click delivery of PC-based VR applications to standalone devices by streaming from the Cloud using NVIDIA CloudXR SDK and Innoactive Portal.
Building one-click delivery of PC-based VR applications to standalone devices by streaming from the Cloud using NVIDIA CloudXR SDK and Innoactive Portal.
Given how prevalent streaming technologies are today, it is easy to forget that on-demand, globally available applications used to be considered a radical idea. But as the popularity of AR and VR grows, the race is on to push streaming even further. With the demand for realistic content and consumer-grade hardware comes a critical challenge: How to build applications that look good on any device without compromising on the quality and performance requirements of immersive experiences?
To help solve this problem, the team at Innoactive has integrated the NVIDIA CloudXR streaming solution into their VR application deployment platform, Innoactive Portal. Customers like SAP, Deloitte, Linde Engineering, and Volkswagen Group are using the platform to deliver immersive training seamlessly to users whenever and wherever they are.
Portal is a user-centric, enterprise-grade deployment platform for managing and accessing VR content with a single click from any device. What makes Portal unique is the ability to deploy content across platforms and devices including PC VR, standalone VR, and PC 3D applications.
Using both the server and client components of the NVIDIA CloudXR SDK, with improvements in cloud computing frameworks, Portal makes it possible to build an application for PC VR and streaming to all-in-one headsets or other low-compute devices. All end users do is select the application from their library to stream it.
Overcoming the Distribution Bottlenecks of XR

While there are several other enterprise VR platforms out there, Portal makes the process painless for both creators and end users by alleviating three of the most critical bottlenecks in distributing XR content:
- The platform’s secure cloud infrastructure provides customers with centralized control of their content and users, ensuring access for only those who need it.
- The one-click streaming architecture makes content easy to use for users who may not be familiar with navigating in VR.
- The NVIDIA CloudXR support of more complex distribution models, like that of Portal, results in several cost-saving benefits, like the ability to build an application one time and deploy it to any device, anywhere.
It’s been technically possible to use NVIDIA CloudXR to stream a VR application for some time, but Innoactive wanted to provide this functionality to casual and even first-time VR users. They faced a set of challenges to make this happen:
- When users want to start a cloud streamed VR experience, they need a suitable NVIDIA GPU-powered machine available to them on-demand.
- This server running NVIDIA CloudXR not only requires good performance to perform the rendering, it also must be available to users worldwide.
- At the same time, it is important to be as resource-aware as possible. To reach a broad audience, all of this must happen with minimal complexity for the user.
To deliver this zero-friction experience, Innoactive needed to build on top of both the client and server side of the NVIDIA CloudXR SDK.
Building a scalable server architecture for NVIDIA CloudXR
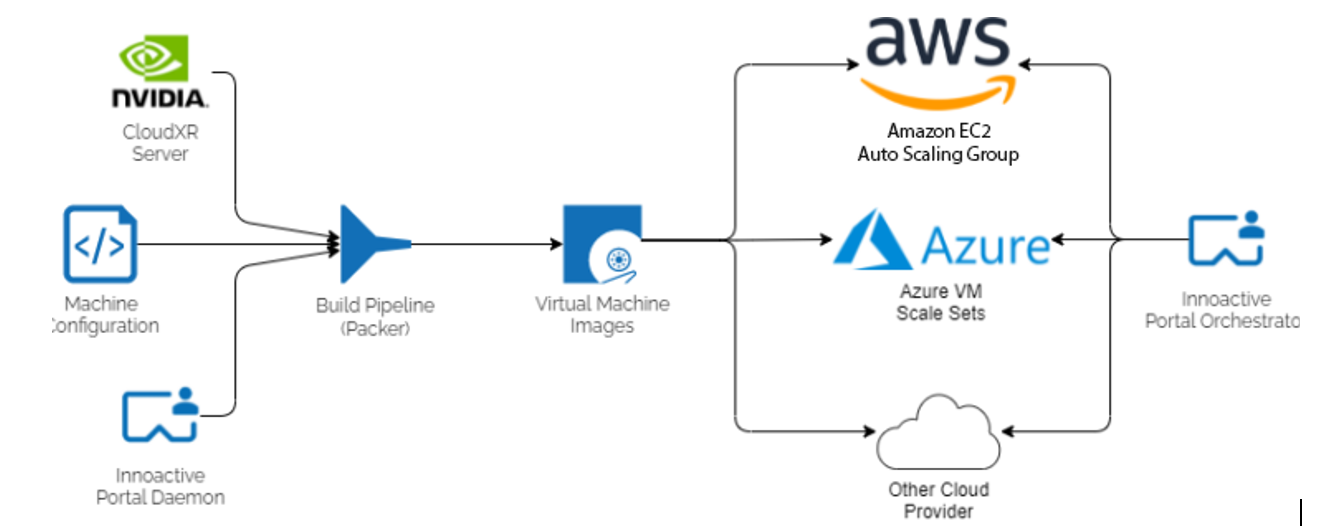
On the server, it is important to ensure that an NVIDIA GPU-powered machine is available on-demand to each user, no matter how many users are trying to access machines, or where or when those users require access.
Relying on cloud providers like Amazon Web Services (AWS) and Microsoft Azure for the compute resources is a logical solution. However, Portal was built with the guiding principle of being an open platform supporting all types of VR content as well as all types of environments to be deployed in.
This agnosticism of cloud providers implies that a service is needed, capable of supporting cloud-rendering machines on either cloud service. In turn this provides the most flexibility to customers who have already decided for one or the other upfront. It also enables Portal to provide maximum coverage and performance to end users by being able to switch to another data center with better latency or performance, independently of the respective provider.
For this reason, Innoactive relies on building custom virtual machine (VM) images with preinstalled software components for any cloud provider. They use a tool called Packer and enable the resulting VMs to be scaled using the respective cloud provider’s VM scale set functionality.
By building for today but planning for tomorrow, Innoactive ensures that this process can be replicated in the future and adapted to work with new cloud providers. Services are now capable of dynamically allocating rendering resources whenever and wherever needed.
When going to production with cloud-rendered VR, the cost of remote rendering resources must stay as low as possible to provide a positive business case. At the same time, ensuring a great user experience requires a high level of performance, which in turn can quickly become expensive. Thus, the Portal team was tasked to find the optimal cost and performance trade-off.
One huge cost driver apart from the size of a VM is its uptime. The target is to pay for what is needed and no more. However, waiting too long to boot up a machine can make the process feel clumsy or untimely.
Due to the on-demand design of Portal, reducing user wait time is key to getting them into a cloud-rendered experience as fast as possible. Portal detects when users start engaging with it and prepares a VM in anticipation of them launching a VR application. This dramatically reduces the load time for when they launch an application, from a matter of minutes to a matter of seconds.
After the cloud-rendered session is complete, Portal’s cloud-rendering orchestration service automatically removes the machine using the respective cloud provider’s endpoints for scaling. This again ensures that only uptime is paid for, not dead time. Portal can adapt its rendering capabilities depending on the use case. For example, it can ensure that the GPU rendering pool is sufficiently large on days that are planned for VR training at a corporation while minimizing the pool size in times of low activity.
To optimize the cost-performance ratio, you should understand customer and regional differences. Keeping latency at a minimum during a session is one of the most important factors to guaranteeing a great experience. Generally, the closer a server is to the end users, the lower the latency and lag is between user input and the streamed application.
To ensure that users are allocated the nearest server, multiple algorithms are used, one example being IP lookups to narrow down user geolocations. In the future, relying on the 5G network and edge computing will further improve performance.
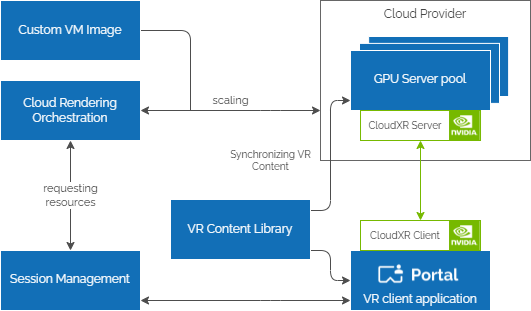
With the previously mentioned architecture and optimizations, Portal supports users with the intent to render a VR application remotely using NVIDIA CloudXR. Portal takes care of allocating rendering resources in the cloud, synchronizes the desired VR content to the remote machine and executes the NVIDIA CloudXR Server so that users can connect. All users do is select the desired VR content.
While providing value on its own, having a preconfigured, ready-to-roll remote rendering machine is just half of the equation. It still requires users to boot up their streaming client and configure it manually by entering the server IP address, which is not something novices are comfortable with.
Building an NVIDIA CloudXR client into Portal
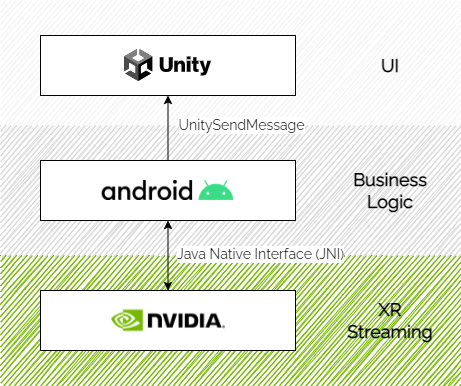
By integrating the NVIDIA CloudXR SDK within the client application, Portal takes away these manual steps to provide a smooth user experience. To keep users updated throughout every step of the process, Portal uses WebSockets built on top of ASP.NET Core SignalR. The client application’s user interface is also built using Unity, to enable fast iteration while still delivering a great user experience.
This comes with the challenge of combining the NVIDIA CloudXR SDK, which is written in C++ using the Android NDK, and an interactive Unity scene into one Portal client app. The result is a single, modular Android application featuring multiple activities that can be easily loaded to a standalone VR headset like Meta Quest 2, Vive Focus 3, or Pico Neo 3.
The user interface guides users up to the point when a remote rendering server is available. It then automatically connects to it through the NVIDIA CloudXR client and ensures that the VR application is correctly started on the server, guaranteeing a frictionless entry into the streamed experience.
The business-logic layer, written in native Android (Java), contains logic to communicate back and forth with Innoactive’s backend services and handles the entire application state. It updates the user interface layer using a proprietary protocol shipped with Unity called UnitySendMessage and initializes the native NVIDIA CloudXR client library when required.
The native NVIDIA CloudXR activity is extended to use the Java Native Interface (JNI) to communicate back lifecycle events to the business layer. The example code later in this post show this. To isolate the native Unity and NVIDIA CloudXR activities from each other properly, both are designed to run in a dedicated Android process.
The following code examples show the interfacing between Android code and NVIDIA CloudXR. First, the Android code example (Java):
import android.app.Activity;
public class MainActivity extends Activity implements ServerAvailableInterface {
// load native NVIDIA CloudXR client library (*.aar)
static {
System.loadLibrary("CloudXRClient");
}
static native void initCloudXR(String jcmdline);
@Override
public void onServerReady(String serverIpAddress) {
// initializes the native CloudXR client after server ip is known
String arguments = String.format("-s %s", serverIpAddress);
initCloudXR(arguments);
}
public void onConnected() {
// called by native CloudXR activity when it is successfully connected
System.out.println("Connected to CloudXR server")
}
Second, theNVIDIA CloudXR code example (C++):
#include #include #include // ... // called whenever the CloudXR client state changes void Client::UpdateClientState(cxrClientState state, cxrStateReason reason) { switch (state) { // ... case cxrClientState_StreamingSessionInProgress: OnCloudXRConnected(); break; // ... } } // Fired when the CloudXR client has established a connection to the server void Client::OnCloudXRConnected() { jmethodID jOnConnected = env ->GetMethodID(mainActivity, "onConnected", "()V"); env->CallVoidMethod(mainActivity, jOnConnected); } // ...
The final client application provides an intuitive interface with a minimal set of required user interactions to select the desired VR content. This interface is accessible from a second screen device independently of VR, often a laptop or phone.
With the Portal’s real-time communication, all connected clients–regardless of device–display the same status updates as a cloud-rendered session is loading. Users then receive a push notification after their content is ready in VR. When done with a session, users can directly proceed with the next streaming session without having to quit the client application.
Bundling Portal’s services together with the extended NVIDIA CloudXR client provides a globally scalable solution for users to access their VR content library from any device with just one click. Portal with NVIDIA CloudXR has changed how customers are able to deploy their PC-based VR. Where customers had a single platform per headset type, Portal now handles the complexity.
The easy-to-use, one-click frontend supports them in scaling VR-based use cases like training employees who are often new to VR. On a more technical level, customers can plan flexibly for headset deployment. They are no longer limited to PC-based VR due to the heavy calculation power that is needed to provide high-quality experiences.
Now, the power of cloud machines makes high-end rendering available on standalone devices through the Portal with NVIDIA CloudXR.
Additional resources
For more information about how Innoactive Portal has helped customers deploy VR training at scale, check out their case studies with SAP and Volkswagen Group.
For more information about NVIDIA CloudXR, see the developer page. Check out GTC 2022 this March 21-24 for the latest from NVIDIA on XR and the era of AI.
Categories
Tensorflow-gpu makes everything slow
Hello,
I hope it is okay to post this question here. I have installed tensorflow-gpu through the Anaconda Navigator because I have a RTX3090 that I would like to use. However, when using the environment that where I have tensorflow-gpu installed everything is super slow. Like just executing the model without training takes for ever. Even something as simple as
model = Sequential()
model.add(Dense(10, activation=”relu”)
model.add(Dense(1, activation=”sigmoid”)
model.compile(optimizer=”rmsprop”, loss=”binary_crossentropy”)
Does anyone have clue what might be the issue? Thank you in advance!
submitted by /u/0stkreutz
[visit reddit] [comments]
 This Jetson Project of the Month enhances synthesizer-based music by applying deep generative models to a classic Eurorack machine.
This Jetson Project of the Month enhances synthesizer-based music by applying deep generative models to a classic Eurorack machine.
Are you a fan of synthesizer-driven bands like Depeche Mode, Erasure, or Kraftwerk? Did you ever think of how cool it would be to create your own music with a synthesizer at home? And what if that process could be enhanced with the help of NVIDIA Jetson Nano?
The latest Jetson Project of the Month has found a way to do just that, bringing together a Eurorack synthesizer with a Jetson Nano to create the Neurorack. This musical audio synthesizer is the first to combine the power of deep generative models and the compactness of a Eurorack machine.
“The goal of this project is to design the next generation of musical instruments, providing a new tool for musicians while enhancing the musician’s creativity. It proposes a novel approach to think [about] and compose music,” noted the app developers, who are members of Artificial Creative Intelligence and Data Science (ACIDS) group, based at the IRCAM Laboratory in Paris, France. “We deeply think that AI can be used to achieve this quest.”
The real-time capabilities of the Neurorack rely on Jetson Nano’s processing power and Ninon Devis’ research into crafting trained models that are lightweight in both computation and memory footprint.
“Our original dream was to find a way to miniaturize deep models and allow them inside embedded audio hardware and synthesizers. As we are passionate about all forms of synthesizers, and especially Eurorack, we thought that it would make sense to go directly for this format as it was more fun! The Jetson Nano was our go-to choice right at the onset … It allowed us to rely on deep models without losing audio quality, while maintaining real-time constraints,” said Devis.
Watch a demo of the project in action here:
The developers had several key design considerations as they approached this project, including:
- Musicality: the generative model chosen can produce sounds that are impossible to synthesize without using samples.
- Controllability: the interface that they picked is handy and easy to manipulate.
- Real-time: the hardware behaves like a traditional synthesizer and is equally reactive.
- Ability to standalone: it can be played without a computer.
As the developers note in their NVIDIA Developer Forum post about this project: “The model is based on a modified Neural-Source Filter architecture, which allows real-time descriptor-based synthesis of percussive sounds.”
Neurorack uses PyTorch deep audio synthesis models (see Figure 1) to produce sounds that typically require samples, is easy to manipulate and doesn’t require a separate computer.
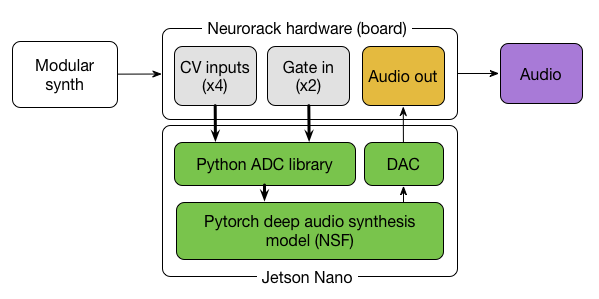
The hardware features four control voltage (CV) inputs and two gates (along with a screen, rotary, and button for handling the menus), which all communicate with specific Python libraries. The behavior of these controls (and the module itself) is highly dependent on the type of deep model embedded. For this first version of the Neurorack, the developers implemented a descriptor-based impact sounds generator, described in their GitHub documentation.
The Eurorack hardware and software were developed with equal contributions from Ninon Devis, Philippe Esling, and Martin Vert on the ACIDS team. According to their website, ACIDS is “hell-bent on trying to model musical creativity by developing innovative artificial intelligence models.”
The project code and hardware design are free, open-source, and available in their GitHub repository.
The team hopes to make the project accessible to musicians and people interested in AI/embedded computing as well.
“We hope that this project will raise the interest of both communities! Right now reproducing the project is slightly technical, but we will be working on simplifying the deployment and hopefully finding other weird people like us,” Devis said. “We strongly believe that one of the key aspects in developing machine learning models for music will lead to the empowerment of creative expression, even for nonexperts.”
More detail on the science behind this project is available on their website and in their academic paper.
Two of the team members, Devis and Esling, have formed a band using the instruments they developed. They are currently working on a full-length live act, which will feature the Neurorack and plan to perform during the next SynthFest in France this April.
Sign up now for Jetson Developer Day taking place at NVIDIA GTC on March 21. This full-day event led by world-renowned experts in robotics, edge AI, and deep learning, will give you a unique deep dive into building next-generation AI-powered applications and autonomous machines.
Categories
How would you make an intentionally bad CNN?
Hey folks,
I’m a data science lecturer and for one of my assignments this year, I want to challenge my students to fix and optimise a CNN coded in keras/TF. The gist is I need to code up a model that is BAD—something full of processing bottlenecks to slow it down, and hyperparameters that hamper the models ability to learn anything. The students will get the model, and will be tasked with “fixing” it—tidying up the input pipeline so that it runs efficiently and adjust the model parameters so that it actually fits properly.
I have a few ideas already, mostly setting up the input pipeline in a convoluted order, using suboptimal activations, etc. But I’m curious to hear other suggestions!
submitted by /u/Novasry
[visit reddit] [comments]
Hi, guys 🤗
I just want to share my Github repository for the Custom training loop with “Custom layers,” “XLA compiling,” “Distributed learning,” and “Gradient accumulator.”
As you know, TF2 operates better on a static graph, so TF2 with XLA compiling is easy and powerful. However, to my knowledge, there is no source code or tutorial for XLA compiling for distributed learning. Also, TF2 doesn’t natively provide a gradients accumulator, which is a well-known strategy for small hardware users.
My source code provides all of them and makes it possible to train ResNet-50 with 512 mini-batch sizes on two 1080ti. All parts are XLA compiled so that the training loop is sufficiently fast considering old-fashioned GPUs.
Actually, this repository is source code for a search-based filter pruning algorithm, so if you want to know about it, please look around Readme and the paper.
submitted by /u/sseung0703
[visit reddit] [comments]
Categories
Problems with version
submitted by /u/TxiskoAlonso
[visit reddit] [comments]
Categories
Problem with Tensorflow version
Hey there I need to rewrite this code for my project but I don’t now how to do it. Can some one help me?
from tensorflow.contrib.layers import flatten
I am trying to run this code on jupyter notebooks
submitted by /u/TxiskoAlonso
[visit reddit] [comments]