Posted by Jiahui Yu, Senior Research Scientist, and Jing Yu Koh, Research Software Engineer, Google Research
In recent years, natural language processing models have dramatically improved their ability to learn general-purpose representations, which has resulted in significant performance gains for a wide range of natural language generation and natural language understanding tasks. In large part, this has been accomplished through pre-training language models on extensive unlabeled text corpora.
This pre-training formulation does not make assumptions about input signal modality, which can be language, vision, or audio, among others. Several recent papers have exploited this formulation to dramatically improve image generation results through pre-quantizing images into discrete integer codes (represented as natural numbers), and modeling them autoregressively (i.e., predicting sequences one token at a time). In these approaches, a convolutional neural network (CNN) is trained to encode an image into discrete tokens, each corresponding to a small patch of the image. A second stage CNN or Transformer is then trained to model the distribution of encoded latent variables. The second stage can also be applied to autoregressively generate an image after the training. But while such models have achieved strong performance for image generation, few studies have evaluated the learned representation for downstream discriminative tasks (such as image classification).
In “Vector-Quantized Image Modeling with Improved VQGAN”, we propose a two-stage model that reconceives traditional image quantization techniques to yield improved performance on image generation and image understanding tasks. In the first stage, an image quantization model, called VQGAN, encodes an image into lower-dimensional discrete latent codes. Then a Transformer model is trained to model the quantized latent codes of an image. This approach, which we call Vector-quantized Image Modeling (VIM), can be used for both image generation and unsupervised image representation learning. We describe multiple improvements to the image quantizer and show that training a stronger image quantizer is a key component for improving both image generation and image understanding.
Vector-Quantized Image Modeling with ViT-VQGAN
One recent, commonly used model that quantizes images into integer tokens is the Vector-quantized Variational AutoEncoder (VQVAE), a CNN-based auto-encoder whose latent space is a matrix of discrete learnable variables, trained end-to-end. VQGAN is an improved version of this that introduces an adversarial loss to promote high quality reconstruction. VQGAN uses transformer-like elements in the form of non-local attention blocks, which allows it to capture distant interactions using fewer layers.
In our work, we propose taking this approach one step further by replacing both the CNN encoder and decoder with ViT. In addition, we introduce a linear projection from the output of the encoder to a low-dimensional latent variable space for lookup of the integer tokens. Specifically, we reduced the encoder output from a 768-dimension vector to a 32- or 8-dimension vector per code, which we found encourages the decoder to better utilize the token outputs, improving model capacity and efficiency.
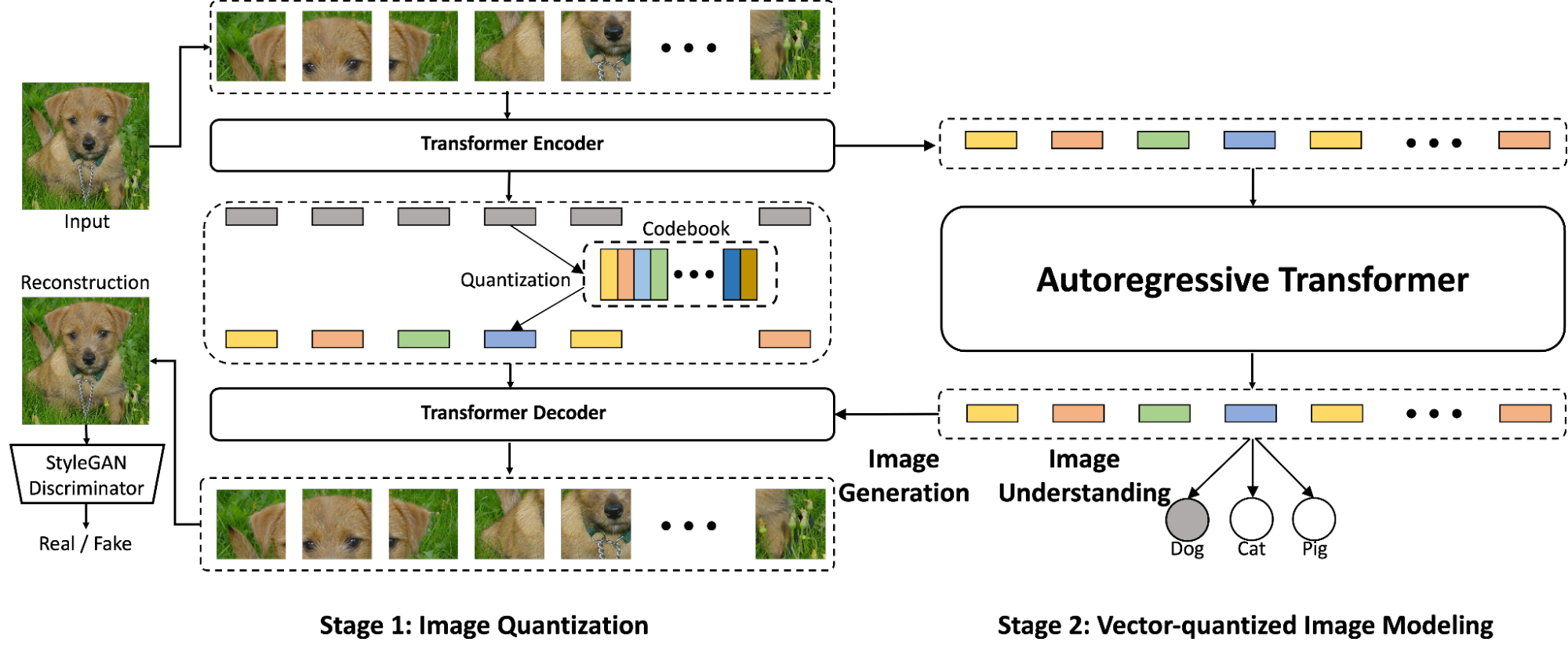
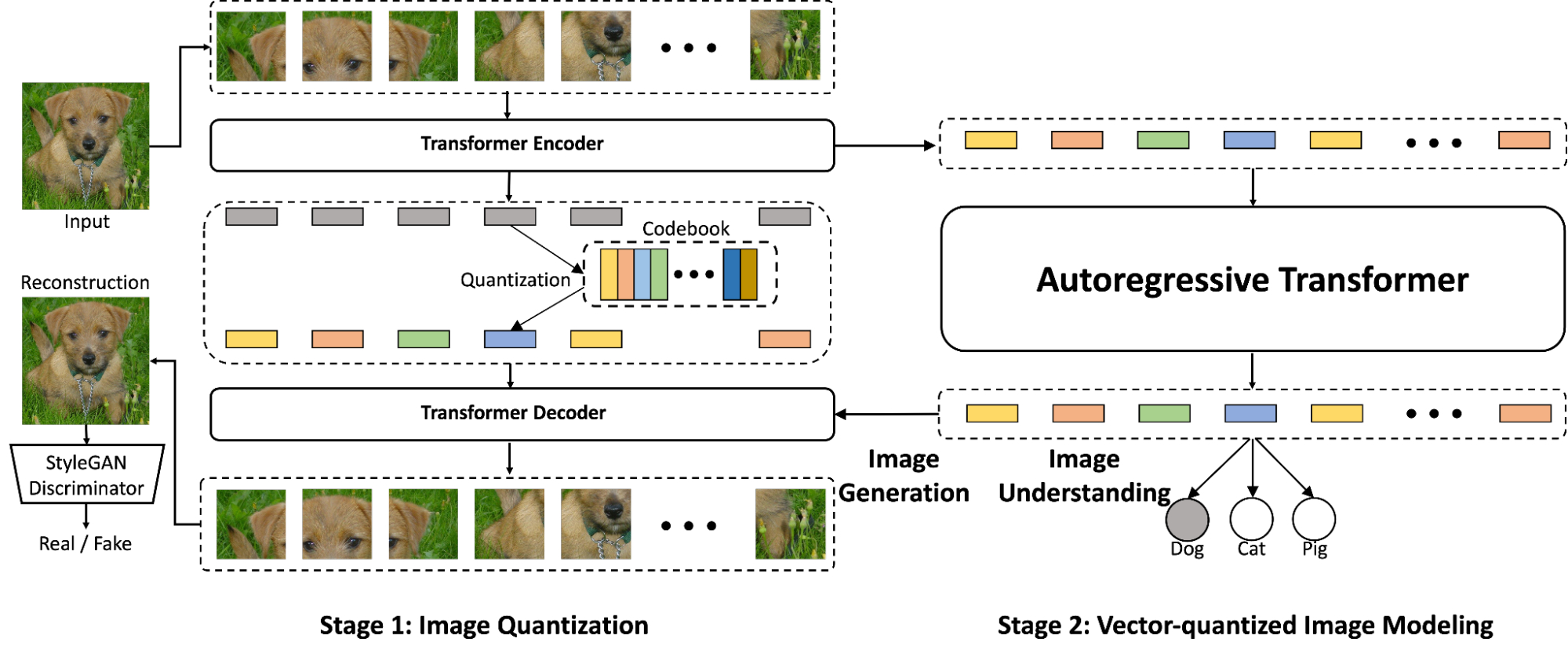 |
| Overview of the proposed ViT-VQGAN (left) and VIM (right), which, when working together, is capable of both image generation and image understanding. In the first stage, ViT-VQGAN converts images into discrete integers, which the autoregressive Transformer (Stage 2) then learns to model. Finally, the Stage 1 decoder is applied to these tokens to enable generation of high quality images from scratch. |
With our trained ViT-VQGAN, images are encoded into discrete tokens represented by integers, each of which encompasses an 8×8 patch of the input image. Using these tokens, we train a decoder-only Transformer to predict a sequence of image tokens autoregressively. This two-stage model, VIM, is able to perform unconditioned image generation by simply sampling token-by-token from the output softmax distribution of the Transformer model.
VIM is also capable of performing class-conditioned generation, such as synthesizing a specific image of a given class (e.g., a dog or a cat). We extend the unconditional generation to class-conditioned generation by prepending a class-ID token before the image tokens during both training and sampling.
 |
| Uncurated set of dog samples from class-conditioned image generation trained on ImageNet. Conditioned classes: Irish terrier, Norfolk terrier, Norwich terrier, Yorkshire terrier, wire-haired fox terrier, Lakeland terrier. |
To test the image understanding capabilities of VIM, we also fine-tune a linear projection layer to perform ImageNet classification, a standard benchmark for measuring image understanding abilities. Similar to ImageGPT, we take a layer output at a specific block, average over the sequence of token features (frozen) and insert a softmax layer (learnable) projecting averaged features to class logits. This allows us to capture intermediate features that provide more information useful for representation learning.
Experimental Results
We train all ViT-VQGAN models with a training batch size of 256 distributed across 128 CloudTPUv4 cores. All models are trained with an input image resolution of 256×256. On top of the pre-learned ViT-VQGAN image quantizer, we train Transformer models for unconditional and class-conditioned image synthesis and compare with previous work.
We measure the performance of our proposed methods for class-conditioned image synthesis and unsupervised representation learning on the widely used ImageNet benchmark. In the table below we demonstrate the class-conditioned image synthesis performance measured by the Fréchet Inception Distance (FID). Compared to prior work, VIM improves the FID to 3.07 (lower is better), a relative improvement of 58.6% over the VQGAN model (FID 7.35). VIM also improves the capacity for image understanding, as indicated by the Inception Score (IS), which goes from 188.6 to 227.4, a 20.6% improvement relative to VQGAN.
|
| Fréchet Inception Distance (FID) comparison between different models for class-conditional image synthesis and Inception Score (IS) for image understanding, both on ImageNet with resolution 256×256. The acceptance rate shows results filtered by a ResNet-101 classification model, similar to the process in VQGAN. |
After training a generative model, we test the learned image representations by fine-tuning a linear layer to perform ImageNet classification, a standard benchmark for measuring image understanding abilities. Our model outperforms previous generative models on the image understanding task, improving classification accuracy through linear probing (i.e., training a single linear classification layer, while keeping the rest of the model frozen) from 60.3% (iGPT-L) to 73.2%. These results showcase VIM’s strong generation results as well as image representation learning abilities.
Conclusion
We propose Vector-quantized Image Modeling (VIM), which pretrains a Transformer to predict image tokens autoregressively, where discrete image tokens are produced from improved ViT-VQGAN image quantizers. With our proposed improvements on image quantization, we demonstrate superior results on both image generation and understanding. We hope our results can inspire future work towards more unified approaches for image generation and understanding.
Acknowledgements
We would like to thank Xin Li, Han Zhang, Ruoming Pang, James Qin, Alexander Ku, Yuanzhong Xu, Jason Baldridge, Yonghui Wu for the preparation of the VIM paper. We thank Wei Han, Yuan Cao, Jiquan Ngiam, Vijay Vasudevan, Zhifeng Chen and Claire Cui for helpful discussions and feedback, and others on the Google Research and Brain Team for support throughout this project.





{kind=link}