
 Learn how servers can be built to deliver immersive workloads and take advantage of compute power to combine streaming XR applications with AI and other computing functions.
Learn how servers can be built to deliver immersive workloads and take advantage of compute power to combine streaming XR applications with AI and other computing functions.
The current distribution of extended reality (XR) experiences is limited to desktop setups and local workstations, which contain the high-end GPUs necessary to meet computing requirements. For XR solutions to scale past their currently limited user base and support higher-end functionality such as AI services integration and on-demand collaboration, we need a purpose-built platform.
NVIDIA Project Aurora is a hardware and software platform that simplifies the deployment of enterprise XR applications onto corporate on-premises networks. This platform is also designed to support the integration of AI services within XR workloads.
Project Aurora leverages the XR streaming backbone of NVIDIA CloudXR and NVIDIA RTX Virtual Workstation (RTX vWS), bringing the horsepower of NVIDIA RTX A6000 and NVIDIA A40 to the edge to stream rich, real-time graphics from a machine room over a private 5G network.
Opportunities ahead
For XR developers, Project Aurora’s streamlined delivery of NVIDIA CloudXR streaming dramatically broadens the customer base from users tethered to high-power workstations to anyone with a simple headset or handheld device.
Users no longer need to leave their work areas to use a dedicated, attended, tethered “VR room” setup to experience high-power, high-quality immersion. Collaborators around the world, using their own separate local on-prem networks, can access and alter the same virtual environments at the same time.
Current use cases
Powerful XR use cases exist across multiple industries, allowing you to optimize workflows.
- Medical professionals can explore immersive representations of anatomical models or even real patient data to train and work.
- Manufacturing designers and engineers can shorten project lifecycles by leveraging digital twins of parts, assemblies, or entire manufacturing floors and plants.
- Those same personnel can train in a virtual manufacturing environment without the need of physical resources or floor downtime.

In collaboration with an ever-growing list of partners, NVIDIA has shown the value of moving these use cases into Project Aurora for virtualized distribution of XR over high performance networks.
BT and Ericsson
BT and Ericsson deployed a VR digital twin manufacturing solution on a 5G mobile private network using the world’s first 5G-enabled VR headset powered by the Qualcomm Snapdragon XR2 Platform. The experience runs on Masters of Pie’s Radical SDK, enabling cloud-based virtual reality within computer-aided design (CAD) software.
By seamlessly integrating the high-performance edge rendering provided by the Project Aurora platform, existing factory operations have benefited from high-fidelity VR experience that is available on the manufacturing floor.
EE 5G
Using augmented reality, The Green Planet AR Experience, powered by EE 5G, takes guests on an immersive journey into the secret kingdom of plants. Visitors travel through changing seasons on six digitally enhanced worlds, including rainforests, deserts, freshwater, and saltwater. The worlds are all powered by an Ericsson 5G standalone private network. Audiences engage and interact with the plant life by using a handheld mobile device, which acts as a window into the natural world.
The compute power of a handheld device on its own would not be nearly enough to render these volumetric models under normal conditions, but with Project Aurora, the experience is delivered seamlessly.
AT&T
AT&T recently teamed with Warner Bros., Ericsson, Qualcomm, Dreamscape, NVIDIA, and Wevr on an immersive, location-based VR experience, Chaos at Hogwarts. This proof-of-concept offers a peek into how Project Aurora combined with 5G can enhance future user-generated experiences.
By using the high-bandwidth and low-latency characteristics of 5G paired with Project Aurora’s XR infrastructure, we can change today’s architecture to one that is more comfortable for fans, more productive for creators, and more profitable for venue operators.
Project Aurora components
Project Aurora is an EGX certified server powered by a GPU/CPU configuration optimized for XR with a virtualization system using RTX vWS. The build is available through multiple OEMs (HPE, Dell) and supports multiple orchestration tools, including Linux KVM and VMWare vSphere.
NVIDIA CloudXR is layered on this virtualized workstation server to form the Project Aurora base platform. Although it is built specifically to stream XR applications, the Project Aurora server also supports any graphics-based workloads natively supported by RTX vWS.

The Project Aurora hardware and software stack is a scalable design built with the help of multiple partners. The base unit of an Aurora build consists of four highly optimized servers from Dell or HPE that support multiple NVIDIA A40 GPUs with RTX Virtual Workstation software and high-performance, low-latency NVIDIA networking components.
Network traffic has been carefully separated. It runs across multiple NVIDIA ConnectX network interface cards (NICs) and can be broken down into the following main areas:
- Internal
- External
- Storage
These traffic flows are distributed across the three NICs to provide performance, security, and redundancy in each area in the event of any NIC failure. Project Aurora is designed with a “performance first” approach, and to scale from the base level to any size client deployment.
Project Aurora partners
Project Aurora is more than just a scalable hardware and software platform. To make the Project Aurora platform easy for any IT crew to implement, NVIDIA has partnered with NVIDIA Partner Network (NPN) integration experts to assure that delivery and installation is simple, repeatable, and fully “white-glove.” Our sales distribution channel was built with the following partners:
- The Grid Factory: Immersive technology integrator specializing in NVIDIA-based technologies, such as NVIDIA CloudXR, vGPU, Omniverse, and the EGX Server architecture.
- Enterprise Integration: Value-added reseller coordinating between clients and various partners, including OEMs such as Dell and HPE and distributors such as Arrow.
- NVIDIA Pro Services (NVPS): Delivers white-glove service to facilitate the standup of durable XR experiences.
Get started with Project Aurora
With the support of the NPN partners, to activate Project Aurora’s white-glove service, just contact one of our team members. The Project Aurora team works from application sizing and site survey through the ‘last-mile’ integration steps (authentication, profiling, server/network setup, tuning parameters, etc.) to achieve a successful XR distribution system.

Project Aurora customers are actively increasing towards hundreds, even thousands of users. If you are interested in learning more about Project Aurora or would like to get involved with our distribution channel to evaluate a new use case, contact Aurora_Outreach@nvidia.com.
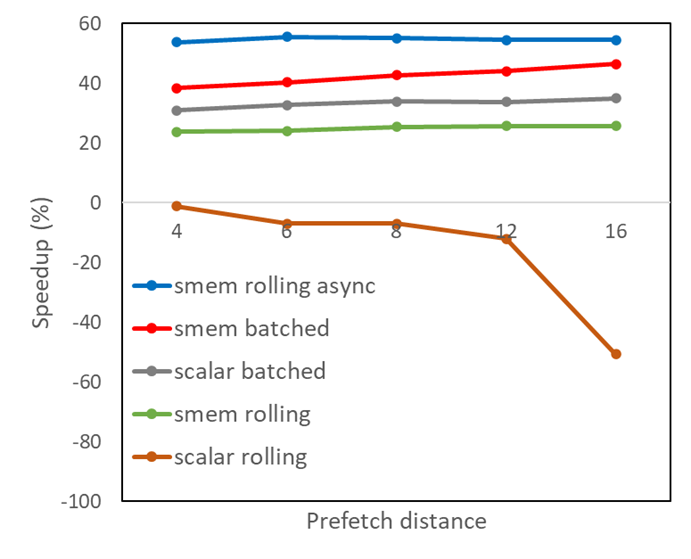
 This CUDA post examines the effectiveness of methods to hide memory latency using explicit prefetching.
This CUDA post examines the effectiveness of methods to hide memory latency using explicit prefetching.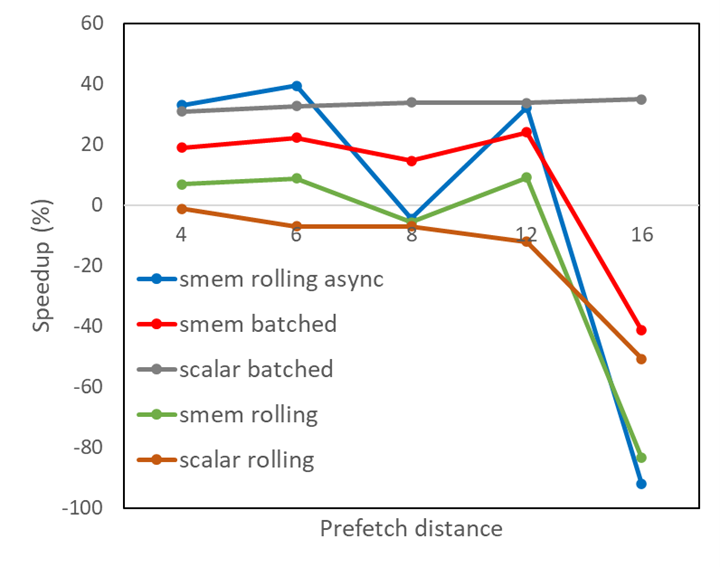
 NVIDIA Morpheus, now available for download, enables you to use AI to achieve up to 1000x improved performance.
NVIDIA Morpheus, now available for download, enables you to use AI to achieve up to 1000x improved performance.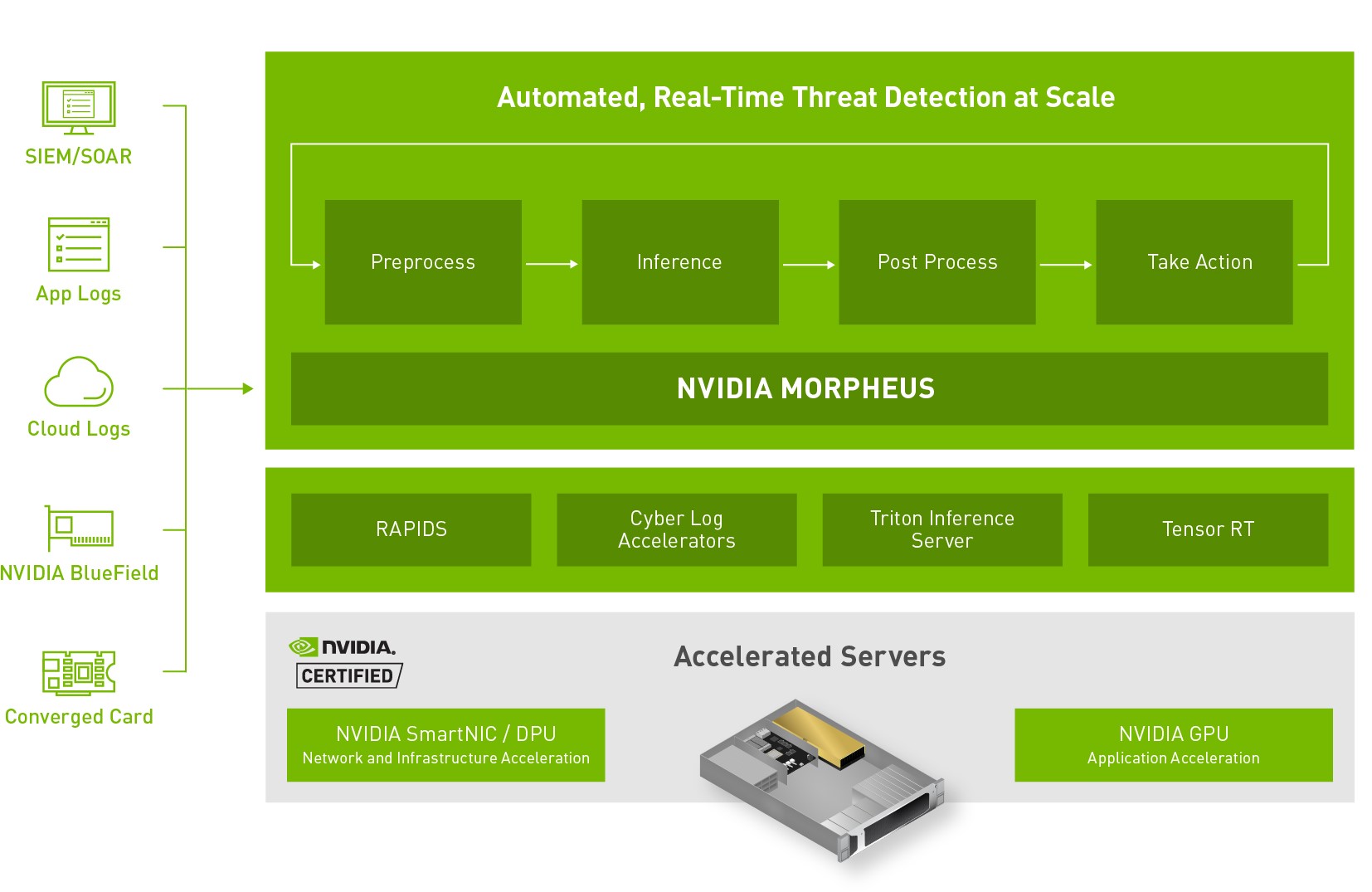



{kind=link}
{kind=link}