First of all, I’m an Embedded Systems engineer trying to use TensorFlow Lite Micro to classify paintings, or pictures in general. I started out with Edge Impulse because, well, it’s an easy way to get started. I managed to get the public car detection project to work on an ESP32-cam in not too much time.
But then; classifying paintings… I don’t know why, but it appears there is one dominant class which gets classified more easily than others. That’s the case with three portraits and one unknown class. The confusion matrix, test dataset and test with my mobile phone (with which I’ve made the dataset) all look and work good. When I quantize the model and deploy it to an ESP32, everything appears to work, but one class specifically overshadows another one.
In short; training a MobileNetV1 96×96 rgb network results in a great confusion matrix identifying three portraits. When deployed to an ESP32, one specific class appears to not work. The other three (unknown and two portraits) seem to work correct.
What could be wrong here? Oh and btw, if anyone knows good resources for an embedded systems engineer to get to know ML better, that’s more than welcome.
I downloaded that code to test it on my machine, and I want to save it. So I simply added at the end of the file:
vae.save('model_keras_example')
But that does not work it seems:
WARNING:tensorflow:Skipping full serialization of Keras layer <__main__.VAE object at 0x2abb26a278b0>, because it is not built. Traceback (most recent call last): File "/home/drozd/GAN/keras_example_vae.py", line 199, in <module> vae.save('model_keras_example') File "/opt/ebsofts/TensorFlow/2.6.0-foss-2021a-CUDA-11.3.1/lib/python3.9/site-packages/keras/engine/training.py", line 2145, in save save.save_model(self, filepath, overwrite, include_optimizer, save_format, File "/opt/ebsofts/TensorFlow/2.6.0-foss-2021a-CUDA-11.3.1/lib/python3.9/site-packages/keras/saving/save.py", line 149, in save_model saved_model_save.save(model, filepath, overwrite, include_optimizer, File "/opt/ebsofts/TensorFlow/2.6.0-foss-2021a-CUDA-11.3.1/lib/python3.9/site-packages/keras/saving/saved_model/save.py", line 75, in save saving_utils.raise_model_input_error(model) File "/opt/ebsofts/TensorFlow/2.6.0-foss-2021a-CUDA-11.3.1/lib/python3.9/site-packages/keras/saving/saving_utils.py", line 84, in raise_model_input_error raise ValueError( ValueError: Model <__main__.VAE object at 0x2abb26a278b0> cannot be saved because the input shapes have not been set. Usually, input shapes are automatically determined from calling `.fit()` or `.predict()`. To manually set the shapes, call `model.build(input_shape)`.
I guess I’m not familiar enough with custom models defined as a class. What seems to be the problem here?
Within the Mogao Caves, a cultural crossroads along what was the Silk Road in northwestern China, lies a natural reserve of tens of thousands of historical documents, paintings and statues of the Buddha.
So I’ve been fighting with this error for quite a few days and desperate. I’m currently working on a CNN with 70 images.
The size of X_train = 774164.
But, whenever I try to run this –> history = cnn.fit(X_train, y_train, batch_size=batch_size, epochs=epoch, validation_split=0.2) it leaks my memory and I get the next error:
W tensorflow/core/common_runtime/bfc_allocator.cc:457] Allocator (GPU_0_bfc) ran out of memory trying to allocate 5.04GiB (rounded to 5417907712)requested by op _EagerConst
If the cause is memory fragmentation maybe the environment variable ‘TF_GPU_ALLOCATOR=cuda_malloc_async’ will improve the situation.
I’m working with a bunch of guys that are developing a new platform for cloud GPU rental, and we’re still in the conception stages atm. I understand that not all of you are using GPU clouds, but for those of you who are, are there any features you think that current platforms are missing? Do you think there’s much room for improvement in the platforms you’ve used so far? What’s your favourite platform?
It would be great to get some insight from people who know what theyre talking about 🙂 TIA!
SANTA CLARA, Calif., Feb. 22, 2022 (GLOBE NEWSWIRE) — NVIDIA will present at the following event for the financial community: Morgan Stanley Technology, Media & Telecom ConferenceMonday, …
Clara Parabricks v3.7 supports gene panels, RNA-Seq, short tandem repeats, and updates to GATK (4.2) and DeepVariant (1.1), and PON support for Mutect2.
In the January 2022 release of Clara Parabricks v3.7, NVIDIA expanded the scope of the toolkit to new data types while continuing to improve upon existing tools:
Added support for analysis of RNASeq analysis
Added support for UMI-based gene panel analysis with an accelerated implementation of Fulcrum Genomics’ fgbio pipeline
Added support for mutect2 Panel of Normals (PON) filtering to bring the accelerated mutectcaller in line with the GATK best practices for calling tumor-normal samples
Incorporated a bam2fq method that enables accelerated realignment of reads to new references
Added support for short tandem repeat assays with ExpansionHunter
Accelerated post-calling VCF analysis steps by up to 15X
Updated HaplotypeCaller to match GATK v4.1 and updated DeepVariant to v1.1.
Clara Parabricks v3.7 significantly broadens the scope of what Clara Parabricks can do while continuing to invest in the field-leading whole genome and whole exome pipelines.
Enabling reference genome realignment with bam2fq and fq2bam
To address recent updates to the human reference genome and make realigning reads tractable for large studies, NVIDIA developed a new bam2fq tool. Parabricks bam2fq can extract reads in FASTQ format from BAM files, providing an accelerated replacement for tools like GATK SamToFastq or bazam.
Combined with Parabricks fq2bam, you can fully realign a 30X BAM file from one reference (for example, hg19) to an updated one (hg38 or CHM13) in 90 minutes using eight NVIDIA V100 GPUs. Internal benchmarks have shown that realigning to hg38 and rerunning variant calling captures several thousand more true-positive variants in the Genome in a Bottle HG002 truth set compared to relying solely on hg19.
The improvements in variant calls from realignment are almost the same as initially aligning to hg38. While this workflow was possible before, it was prohibitively slow. NVIDIA has finally made reference genome updates practical for even the largest of WGS studies in Clara Parabricks.
More options for RNASeq transcript quantification and fusion calling in Clara Parabricks
With version 3.7, Clara Parabricks adds two new tools for RNASeq analysis as well.
Transcript quantification is one of the most performed analyses for RNASeq data. Kallisto is a rapid method for expression quantification that relies on pseudoalignment. While Clara Parabricks already included STAR for RNASeq alignment, Kallisto adds a complementary method that can run even faster.
Fusion calling is another common RNASeq analysis. In Clara Parabricks 3.7, Arriba provides a second method for calling gene fusions based on the output of the STAR aligner. Arriba can call significantly more types of events than STAR-Fusion, including the following:
Viral integration sites
Internal tandem duplications
Whole exon duplications
Circular RNAs
Enhancer-hijacking events involving immunoglobulin and T-cell receptor loci
Breakpoints in introns and intergenic regions
Together, the addition of Kallisto and Arriba make Clara Parabricks a comprehensive toolkit for many transcriptome analyses.
Simplifying and accelerating gene panel and UMI analysis
While whole genome and whole exome sequencing are increasingly common in both research and clinical practice, gene panels dominate the clinical space.
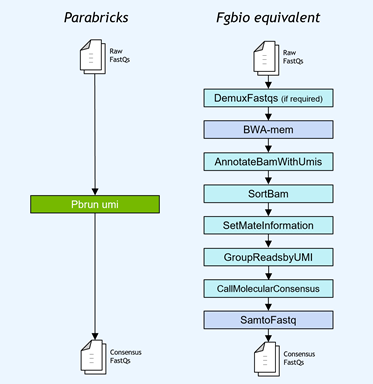
Gene panel workflows commonly use unique molecular identifiers (UMIs) attached to reads to improve the limits of detection for low-frequency mutations. NVIDIA accelerated the Fulcrum Genomics fgbio UMI pipeline and consolidated the eight-step pipeline into a single command in v3.7, with support for multiple UMI formats.
Figure 1. The Fulcrum Genomics Fgbio UMI pipeline accelerated with a single command on Clara Parabricks
Detecting changes in short tandem repeats with ExpansionHunter
Short tandem repeats (STRs) are well-established causes of certain neurological disorders as well as historically important markers for fingerprinting samples for forensic and population genetic purposes.
NVIDIA enabled genotyping of these sites in Clara Parabricks by adding support for ExpansionHunter in version 3.7. It’s now easy to go from raw reads to genotyped STRs entirely using the Clara Parabricks command-line interface.
Improving MuTect somatic mutation calls with PON support
It is common practice to filter somatic mutation calls against a set of mutations from known normal samples, also called a Panel of Normals (PON). NVIDIA added support for both publicly available PON sets and custom PONs to the mutectcaller tool, which now provides an accelerated version of the GATK best practices for somatic mutation calling.
Accelerating post-calling VCF annotation and quality control
In the v3.6 release, NVIDIA added the vbvm, vcfanno, frequencyfiltration, vcfqc, and vcfqcbybam tools that made post-calling VCF merging, annotation, filtering,filtering, and quality control easier to use.
The v3.7 release improved upon these tools by completely rewriting the backend of vbvm, vcfqc and vcfqcbybam, all of which are now more robust and up to 15x faster.
In the case of vcfanno, NVIDIA developed a new annotation tool called snpswift, which brings more functionality and acceleration while retaining the essential functionality of accurate allele-based database annotation of VCF files. The new snpswift tool also supports annotating a VCF file with gene name data from ENSEMBL, helping to make sense of coding variants. While the new post-calling pipeline looks similar to the one from v3.6, you should find that your analysis runs even faster.
With Clara Parabricks v3.7, NVIDIA is demonstrating a commitment to making Parabricks the most comprehensive solution for accelerated analysis of genomic data. It is an extensive toolkit for WGS, WES, and now RNASeq analysis, as well as gene panel and UMI data.
For more information about version 3.7, see the following resources:
Am I the only one that has webpage problems? Today I wanted to see some tutorials on their page and some links downloads xml files instead of showing the actual page.
With more than 11,000 stores across Thailand serving millions of customers, CP All, the country’s sole licensed operator of 7-Eleven convenience stores, recently turned to AI to dial up its call centers’ service capabilities. Built on the NVIDIA conversational AI platform, the Bangkok-based company’s customer service bots help call-center agents answer frequently asked questions and Read article >
This is, without a doubt, the best time to jump into cloud gaming. GeForce NOW RTX 3080 memberships deliver up to 1440p resolution at 120 frames per second on PC, 1600p and 120 FPS on Mac, and 4K HDR at 60 FPS on NVIDIA SHIELD TV, with ultra-low latency that rivals many local gaming experiences. Read article >

 Clara Parabricks v3.7 supports gene panels, RNA-Seq, short tandem repeats, and updates to GATK (4.2) and DeepVariant (1.1), and PON support for Mutect2.
Clara Parabricks v3.7 supports gene panels, RNA-Seq, short tandem repeats, and updates to GATK (4.2) and DeepVariant (1.1), and PON support for Mutect2.