") Artificial intelligence (AI) is becoming pervasive in the enterprise. Speech recognition, recommenders, and fraud detection are just a few applications among hundreds being driven…
Artificial intelligence (AI) is becoming pervasive in the enterprise. Speech recognition, recommenders, and fraud detection are just a few applications among hundreds being driven…
Artificial intelligence (AI) is becoming pervasive in the enterprise. Speech recognition, recommenders, and fraud detection are just a few applications among hundreds being driven by AI and deep learning (DL)
To support these AI applications, businesses look toward optimizing AI servers and performance networks. Unfortunately, storage infrastructure requirements are often overlooked in the development of enterprise AI. Yet for the successful adoption of AI, it is vital to consider a comprehensive storage deployment strategy that considers AI growth, future proofing, and interoperability.
This post highlights important factors that enterprises should consider when planning data storage infrastructure for AI applications to maximize business results. I discuss cloud compared to on-premise storage solutions as well as the need for higher-performance storage within GPU-enabled virtual machines (VMs).
Why AI storage decisions are needed for enterprise deployment
The popular phrase, “You can pay me now—or pay me later” implies that it’s best to think about the future when making current decisions. Too often, storage solutions for supporting an AI or DL app only meet the immediate needs of the app without full consideration of the future cost and flexibility.
Spending money today to future-proof your AI environment from a storage standpoint can be more cost-effective in the long run. Decision-makers must ask themselves:
- Can my AI storage infrastructure adapt to a cloud or hybrid model?
- Will choosing object, block, or file storage limit flexibility in future enterprise deployments?
- Is it possible to use lower-cost storage tiers or a hybrid model for archiving, or for datasets that do not require expensive, fast storage?
The impact of enterprise storage decisions on AI deployment is not always obvious without a direct A/B comparison. Wrong decisions today can result in lower performance and the inability to efficiently scale-out business operations in the future.
Main considerations when planning AI storage infrastructure
Following are a variety of factors to consider when deploying and planning storage. Figure 1 shows an overview of data center, budget, interoperability, and storage type considerations.
| Data center | Budget | Interoperability | Storage type |
| DPU | Existing vs. new | Cloud and data center | Object/Block/File |
| Network | All Flash/HDD/Hybrid | VM environments | Flash/HDD/Hybrid |
AI performance and the GPU
Before evaluating storage performance, consider that a key element of AI performance is having high-performance enterprise GPUs to accelerate training for machine-learning, DL, and inferencing apps.
Many data center servers do not have GPUs to accelerate AI apps, so it’s best to first look at GPU resources when looking at performance.
Large datasets do not always fit within GPU memory. This is important because GPUs deliver less performance when the complete data set does not fit within GPU memory. In such cases, data is swapped to and from GPU memory, thus impacting performance. Model training takes longer, and inference performance can be impacted.
Certain apps, such as fraud detection, may have extreme real-time requirements that are affected when GPU memory is waiting for data.
Storage considerations
Storage is always an important consideration. Existing storage solutions may not work well when deploying a new AI app.
It may be that you now require the speed of NVMe flash storage or direct GPU memory access for desired performance. However, you may not know what tomorrow’s storage expectations will be, as demands for AI data from storage increase over time. For certain applications, there is almost no such thing as too much storage performance, especially in the case of real-time use cases such as pre-transaction fraud detection.
There is no “one-size-fits-all” storage solution for AI-driven apps.
Performance is only one storage consideration. Another is scale-out ability. Training data is growing. Inferencing data is growing. Storage must be able to scale in both capacity and performance—and across multiple storage nodes in many cases. Simply put, a storage device that meets your needs today may not always scale for tomorrow’s challenges.
The bottom-line: as training and inference workloads grow, capacity and performance must also grow. IT should only consider scalable storage solutions with the performance to keep GPUs busy for the best AI performance.
Data center considerations
The data processing unit (DPU) is a recent addition to infrastructure technology that takes data center and AI storage to a completely new level.
Although not a storage product, the DPU redefines data center storage. It is designed to integrate storage, processing, and networks such that whole data centers act as a computer for enterprises.
It’s important to understand DPU functionality when planning and deploying storage as the DPU offloads storage services from data center processors and storage devices. For many storage products, a DPU interconnected data center enables a more efficient scale-out.
As an example, the NVIDIA BlueField DPU supports the following functionality:
- NVMe over Fabrics (NVMe-oF)
- GPUDirect Storage
- Encryption
- Elastic block storage
- Erasure coding (for data integrity)
- Decompression
- Deduplication
Storage performance for remote storage access is as if the storage is directly attached to the AI server. The DPU helps to enable scalable software-defined storage, in addition to networking and cybersecurity acceleration.
Budget considerations
Cost remains a critical factor. While deploying the highest throughput and lowest latency storage is desirable, it is not always necessary depending on the AI app.
To extend your storage budget further, IT must understand the storage performance requirements of each AI app (bandwidth, IOPs, and latency).
For example, if an AI app has a large dataset but minimal performance requirements, traditional hard disk drives (HDD) may be sufficient while lowering storage costs substantially. This is especially true when the “hot” data of the dataset fits wholly within GPU memory.
Another cost-saving option is to use hybrid storage that uses flash as a cache to accelerate performance while lowering storage costs for infrequently accessed data residing on HDDs. There are hybrid flash/HDD storage products that perform nearly as well as all-flash, so exploring hybrid storage options can make a lot of sense for apps that don’t have extreme performance requirements.
Older, archived, and infrequently used data and datasets may still have future value, but are not cost-effective residing on expensive primary storage.
HDDs can still make a lot of financial sense, especially if data can be seamlessly accessed when needed. A two-tiered cloud and on-premises storage solution can also make financial sense depending on the size and frequency of access. There are many of these solutions on the market.
Interoperability factors
Evaluating cloud and data center interoperability from a storage perspective is important. Even within VM-driven data centers, there are interoperability factors to evaluate.
Cloud and data center considerations
Will the AI app run on-premises, in the cloud, or both? Even if the app can be run in either place, there is no guarantee that the performance of the app won’t change with location. For example, there may be performance problems if the class of storage used in the cloud differs from the storage class used on-premises. Storage class must be considered.
Assume that a job retraining a large recommender model completes within a required eight-hour window using data center GPU-enabled servers that use high-performance flash storage. Moving the same application to the cloud with equivalent GPU horsepower may cause training to complete in 24 hours, well outside the required eight-hour window. Why?
Some AI apps require a certain class of storage (fast flash, large storage cache, DMA storage access, storage class memory (SCM) read performance, and so on) that is not always available through cloud services.
The point is that certain AI applications will yield similar results regardless of data center or cloud storage choices. Other applications can be storage-sensitive.
Just because an app is containerized and orchestrated by Kubernetes in the cloud, it does not guarantee similar data center results. When viewed in this way, containers do not always provide cross–data center and cloud interoperability when performance is considered. For effective data center and cloud interoperability, ensure that storage choices in both domains yield good results.
VM considerations
Today, most data center servers do not have GPUs to accelerate AI and creative workloads. Tomorrow, the data center landscape may look quite different. Businesses are being forced to use AI to be competitive, whether conversational AI, fraud detection, recommender systems, video analytics, or a host of other use cases.
GPUs are common on workstations, but the acceleration provided by GPU workstations cannot easily be shared within an organization.
The paradigm shift that enterprises must prepare for is the sharing of server-based, GPU-enabled resources within VM environments. The availability of solutions such as NVIDIA AI Enterprise enables sharing GPU-enabled VMs with anyone in the enterprise.
Put simply, it is now possible for anyone in an enterprise to easily run power-hungry AI apps within a VM in the vSphere environment.
So what does this mean for VM storage? Storage for GPU-enabled VMs must address the shared performance requirement of both the AI apps and users of the shared VM. This implies higher storage performance for a given VM than would be required in an unshared environment.
It also means that physical storage allocated for such VMs will likely be more scalable in capacity and performance. Within a heavily shared VM, it can make sense to use dedicated all-flash storage-class memory (SCM) arrays connected to the GPU-enabled servers through RDMA over Converged Ethernet for the highest performance and scale-out.
Storage type
An in-depth discussion on the choice of object, block, or file storage for AI apps goes beyond the scope of this post. That said, I mention it here because it’s an important consideration but not always a straightforward decision.
Object storage
If a desired app requires object storage, for example, the required storage type is obvious. Some AI apps take advantage of object metadata while also benefiting from the infinite scale of a flat address space object storage architecture. AI analytics can take advantage of rich object metadata to enable precision data categorization and organization, making data more useful and easier to manage and understand.
Block storage
Although block storage is supported in the cloud, truly massive cloud datasets tend to be object-based. Block storage can yield higher performance for structured data and transactional applications.
Block storage lacks metadata information, which prevents the use of block storage for any app that is designed to provide benefit from metadata. Many traditional enterprise apps were built on a block storage foundation, but the advent of object storage in the cloud has caused many modern applications to be designed specifically for native cloud deployment using object storage.
File storage
When an AI app accesses data across common file protocols, the obvious storage choice will be file-based. For example, AI-driven image recognition and categorization engines may require access to file-based images.
Deployment options can vary from dedicated file servers to NAS heads built on top of an object or block storage architecture. NAS heads can export NFS or SMB file protocols for file access to an underlying block or object storage architecture. This can provide a high level of flexibility and future-proofing with block or object storage used as a common foundation for file storage access by AI and data center network clients.
Storage type decisions for AI must be based on a good understanding of what is needed today as well as a longer-term AI deployment strategy. Fully evaluate the pros and cons of each storage type. There is frequently no one-size-fits-all answer, and there will also be cases where all three storage types (object, block, and file) make sense.
Key takeaways on enterprise storage decision making
There is no single approach to addressing storage requirements for AI solutions. However, here are a few core principles by which wise AI storage decisions can be made:
- Any storage choice for AI solutions may be pointless if training and inference are not GPU-accelerated.
- Prepare for the possibility of needing IT resources and related storage that is well beyond current estimates.
- Don’t assume that existing storage is “good enough” for new or expanded AI solutions. Storage with higher cost, performance, and scalability may actually be more effective and efficient, over time, compared to existing storage.
- Always consider interoperability with the cloud as on-premises storage options may not be available with your cloud provider.
- Strategic IT planning should consider the infrastructure and storage benefits of DPUs.
As you plan for AI in your enterprise, don’t put storage at the bottom of the list. The impact of storage on your AI success may be greater than you think. For more information about setting up your enterprise for success with AI storage, see the following resources
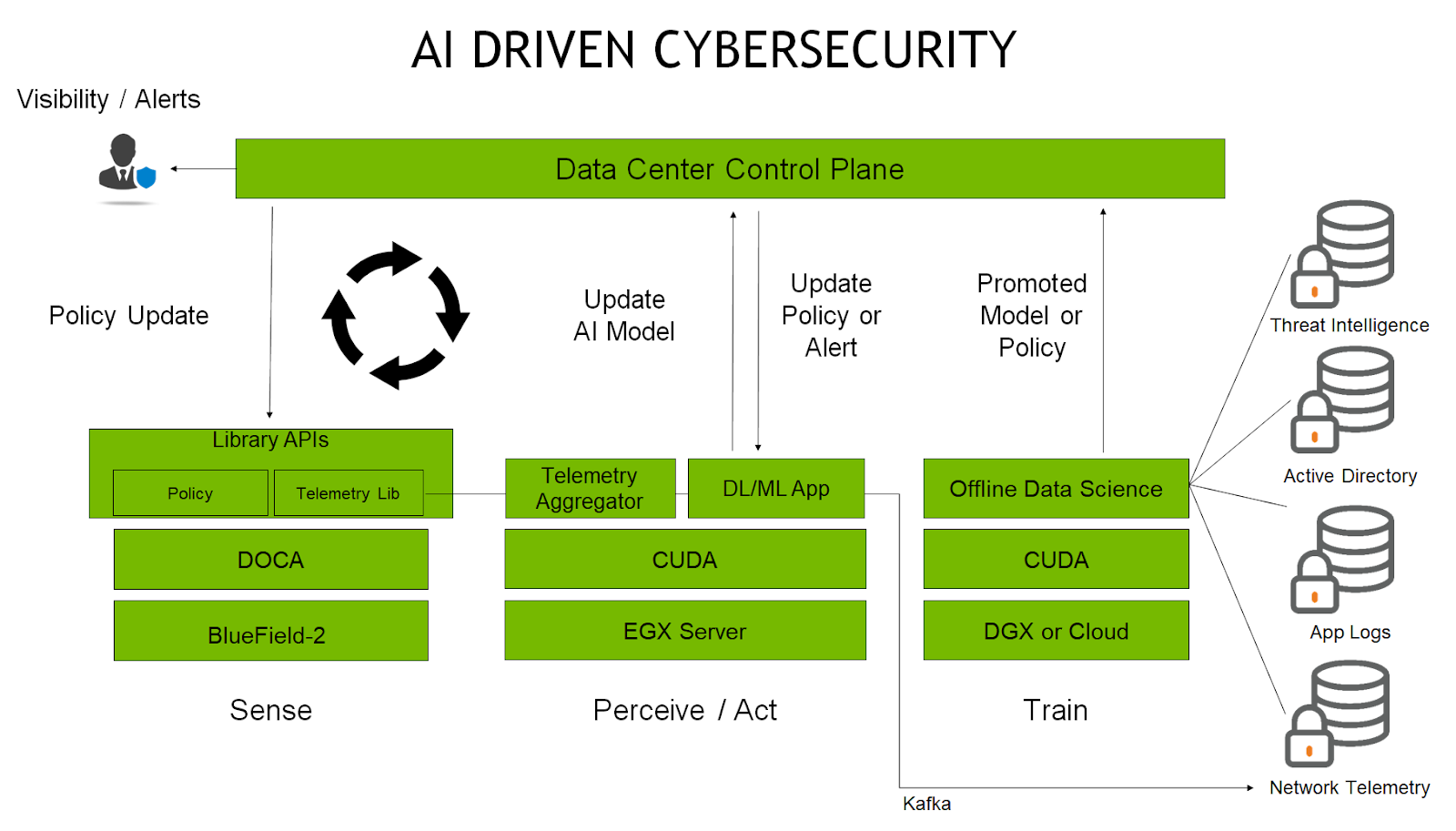
 The acceleration of digital transformation within data centers and the associated application proliferation is exposing new attack surfaces to potential security threats. These new…
The acceleration of digital transformation within data centers and the associated application proliferation is exposing new attack surfaces to potential security threats. These new…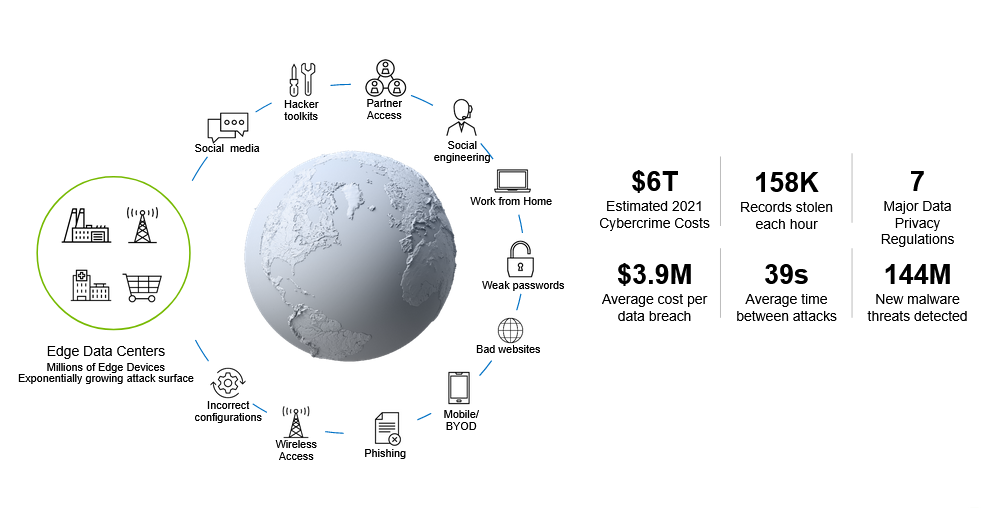
 The new ‘Level Up with NVIDIA’ webinar series offers creators and developers the opportunity to learn more about the NVIDIA RTX platform, interact with NVIDIA experts, and ask…
The new ‘Level Up with NVIDIA’ webinar series offers creators and developers the opportunity to learn more about the NVIDIA RTX platform, interact with NVIDIA experts, and ask… Imagine that you have trained your model with PyTorch, TensorFlow, or the framework of your choice, are satisfied with its accuracy, and are considering deploying it as a service….
Imagine that you have trained your model with PyTorch, TensorFlow, or the framework of your choice, are satisfied with its accuracy, and are considering deploying it as a service….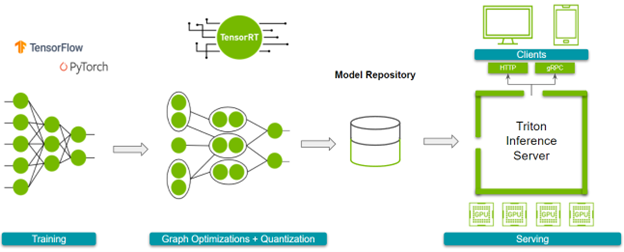
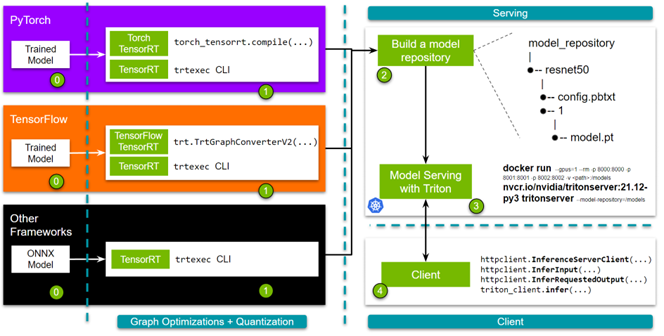
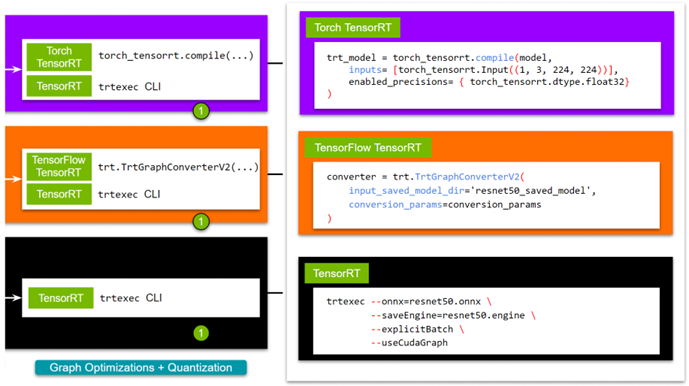
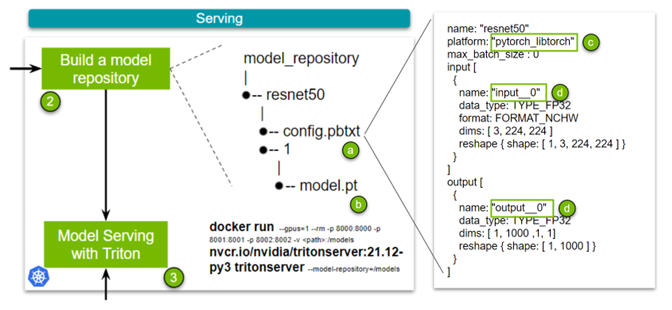
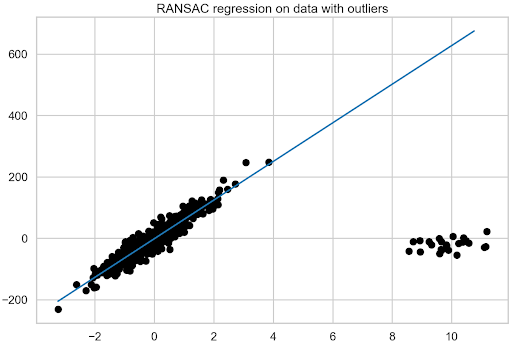
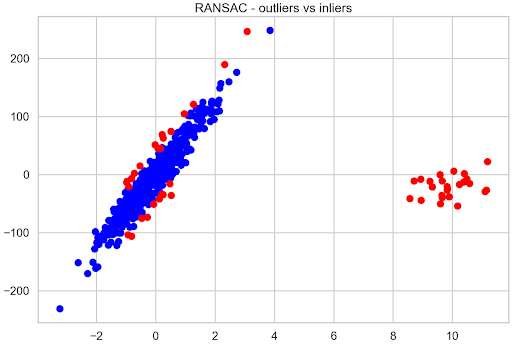
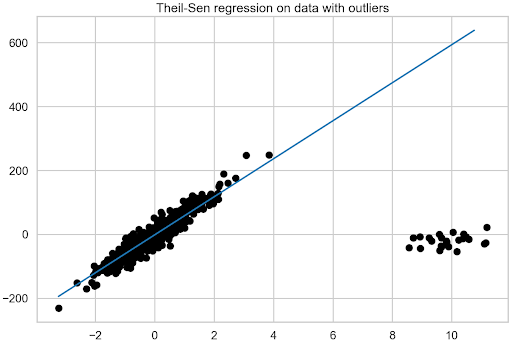
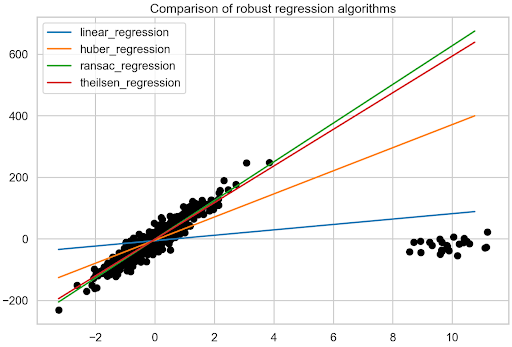
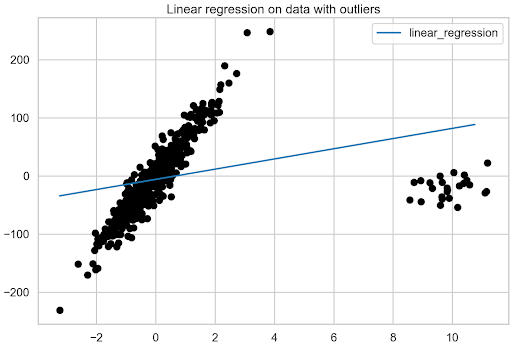
 Linear regression is one of the simplest machine learning models out there. It is often the starting point not only for learning about data science but also for building quick and…
Linear regression is one of the simplest machine learning models out there. It is often the starting point not only for learning about data science but also for building quick and…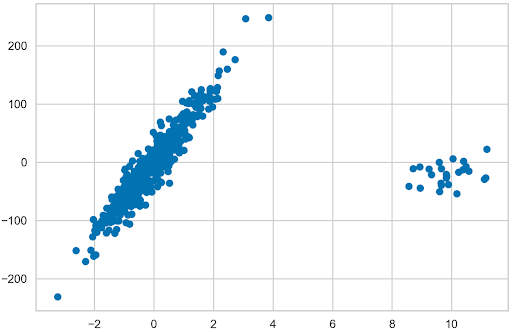
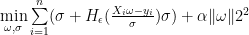
 denotes the standard deviation,
denotes the standard deviation, 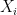 represents the set of features,
represents the set of features,  is the regression’s target variable,
is the regression’s target variable, 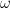 is a vector of the estimated coefficients and
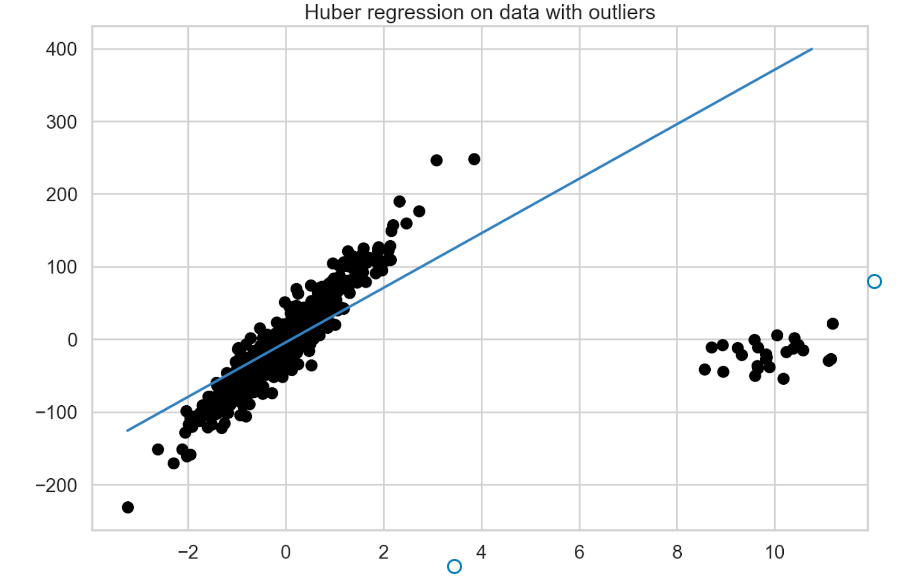
is a vector of the estimated coefficients and  is the regularization parameter. The formula also indicates that outliers are treated differently from the regular observations according to the Huber loss:
is the regularization parameter. The formula also indicates that outliers are treated differently from the regular observations according to the Huber loss: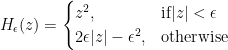
 . If the observation is considered to be regular (because the absolute value of the residual is smaller than some threshold
. If the observation is considered to be regular (because the absolute value of the residual is smaller than some threshold