
submitted by /u/o-rka
[visit reddit] [comments]
 In this post, I introduce new features of NVIDIA FLARE v2.1 and walk through proof-of-concept and production deployments of the NVIDIA FLARE platform.
In this post, I introduce new features of NVIDIA FLARE v2.1 and walk through proof-of-concept and production deployments of the NVIDIA FLARE platform.
NVIDIA FLARE (NVIDIA Federated Learning Application Runtime Environment) is an open-source Python SDK for collaborative computation. FLARE is designed with a componentized architecture that allows researchers and data scientists to adapt machine learning, deep learning, or general compute workflows to a federated paradigm to enable secure, privacy-preserving multi-party collaboration.
This architecture provides components for securely provisioning a federation, establishing secure communication, and defining and orchestrating distributed computational workflows. FLARE provides these components within an extensible API that allows customization to adapt existing workflows or easily experiment with novel distributed applications.

Figure 1 shows the high-level FLARE architecture with the foundational API components, including tools for privacy preservation and secure management of the platform. On top of this foundation are the building blocks for federated learning applications, with a set of federation workflows and learning algorithms.
Alongside the core FLARE stack are tools that allow experimentation and proof-of-concept (POC) development with the FL Simulator, coupled with a set of tools used to deploy and manage production workflows.
In this post, I focus on getting started with a simple POC and outline the process of moving from POC to a secure, production deployment. I also highlight some of the considerations when moving from a local POC to a distributed deployment.
Getting started with NVIDIA FLARE
To help you get started with NVIDIA FLARE, I walk through the basics of the platform and highlight some of the features in version 2.1 that help you bring a proof-of-concept into a production federated learning workflow.
Installation
The simplest way to get started with NVIDIA FLARE is in a Python virtual environment as described in Quickstart.
With just a few simple commands, you can prepare a FLARE workspace that supports a local deployment of independent server and clients. This local deployment can be used to run FLARE applications just as they would run on a secure, distributed deployment, without the overhead of configuration and deployment.
$ sudo apt update $ sudo apt install python3-venv $ python3 -m venv nvflare-env $ source nvflare-env/bin/activate (nvflare-env) $ python3 -m pip install -U pip setuptools (nvflare-env) $ python3 -m pip install nvflare
Preparing the POC workspace
With the nvflare pip package installed, you now have access to the poc command. The only argument required when executing this command is the desired number of clients.
(nvflare-env) $ poc -h
usage: poc [-h] [-n NUM_CLIENTS]
optional arguments:
-h, --help show this help message and exit
-n NUM_CLIENTS, --num_clients NUM_CLIENTS
number of client folders to create
After executing this command, for example poc -n 2 for two clients, you will have a POC workspace with folders for each of the participants: admin client, server, and site clients.
(nvflare-env) $ tree -d poc
poc
├── admin
│ └── startup
├── server
│ └── startup
├── site-1
│ └── startup
└── site-2
└── startup
Each of these folders contains the configuration and scripts required to launch and connect the federation. By default, the server is configured to run on localhost, with site clients and the admin client connecting on ports 8002 and 8003, respectively. You can launch the server and clients in the background by running, for example:
(nvflare-env) $ for i in poc/{server,site-1,site-2}; do
./$i/startup/start.sh;
done
The server and client processes emit status messages to standard output and also log to their own poc/{server,site-?}/log.txt file. When launched as shown earlier, this standard output is interleaved. You may launch each in a separate terminal to prevent this interleaved output.
Deploying a FLARE application
After connecting the server and site clients, the entire federation can be managed with the admin client. Before you dive into the admin client, set up one of the examples from the NVIDIA FLARE GitHub repository.
(nvflare-env) $ git clone https://github.com/NVIDIA/NVFlare.git (nvflare-env) $ mkdir -p poc/admin/transfer (nvflare-env) $ cp -r NVFlare/examples/hello-pt-tb poc/admin/transfer/
This copies the Hello PyTorch with Tensorboard Streaming example into the admin client’s transfer directory, staging it for deployment to the server and site clients. For more information, see Quickstart (PyTorch with TensorBoard).
Before you deploy, you also install a few prerequisites.
(nvflare-env) $ python3 -m pip install torch torchvision tensorboard
Now that you’ve staged the application, you can launch the admin client.
(nvflare-env) $ ./poc/admin/startup/fl_admin.sh Waiting for token from successful login... Got primary SP localhost:8002:8003 from overseer. Host: localhost Admin_port: 8003 SSID: ebc6125d-0a 56-4688-9b08-355fe9e4d61a login_result: OK token: d50b9006-ec21-11ec-bc73-ad74be5b77a4 Type ? to list commands; type "? cmdName" to show usage of a command. >
After connecting, the admin client can be used to check the status of the server and clients, manage applications, and submit jobs. For more information about the capabilities of the admin client, see Operating NVFLARE – Admin Client, Commands, FLAdminAPI.
For this example, submit the hello-pt-tb application for execution.
> submit_job hello-pt-tb Submitted job: 303ffa9c-54ae-4ed6-bfe3-2712bc5eba40
At this point, you see confirmation of job submission with the job ID, along with status updates on the server and client terminals showing the progress of the server controller and client executors as training is executed.
You can use the list_jobs command to check the status of the job. When the job has finished, use the download_job command to download the results of the job from the server.
> download_job 303ffa9c-54ae-4ed6-bfe3-2712bc5eba40 Download to dir poc/admin/startup/../transfer
You can then start TensorBoard using the downloaded job directory as the TensorBoard log directory.
(nvflare-env) $ tensorboard
--logdir=poc/admin/transfer
This starts a local TensorBoard server using the logs that were streamed from the clients to the server and saved in the server’s run directory. You can open a browser to http://localhost:6006 to visualize the run.
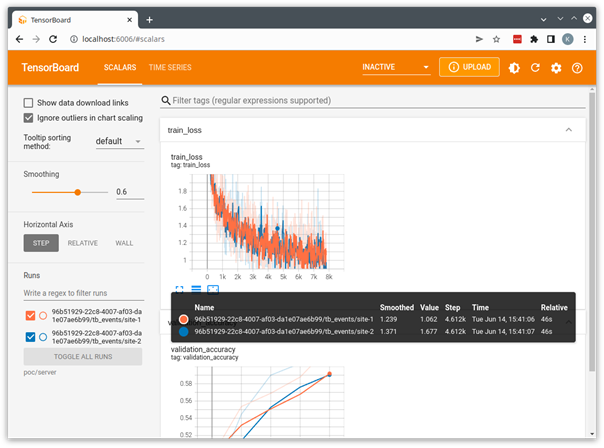
The example applications provided with NVIDIA FLARE are all designed to use this POC mode and can be used as a starting point for the development of your own custom applications.
Some examples, like the CIFAR10 example, define end-to-end workflows that highlight the different features and algorithms available in NVIDIA FLARE and use the POC mode, as well as secure provisioning discussed in the next section.
Moving from proof-of-concept to production
NVIDIA FLARE v2.1 introduces some new concepts and features aimed at enabling robust production federated learning, two of the most visible being high availability and support for multi-job execution.
- High availability (HA) supports multiple FL servers and automatically activates a backup server when the currently active server becomes unavailable. This is managed by a new entity in the federation, the overseer, that’s responsible for monitoring the state of all participants and orchestrating the cutover to a backup server when needed.
- Multi-job execution supports resource-based multi-job execution by allowing for concurrent runs, provided that the resources required by the jobs are satisfied.
Secure deployment with high availability
The previous section covered FLARE’s POC mode in which security features are disabled to simplify local testing and experimentation.
To demonstrate high availability for a production deployment, start again with a single-system deployment like that used in POC mode and introduce the concept of provisioning with the OpenProvision API.
Similar to the poc command, NVIDIA FLARE provides the provision command to drive the OpenProvision API. The provision command reads a project.yml file that configures the participants and components used in a secure deployment. This command can be used without arguments to create a copy of sample project.yml as a starting point.
For this post, continue to use the same nvflare-venv Python virtual environment as configured in the previous section.
(nvflare-env) $ provision No project.yml found in current folder. Is it OK to generate one for you? (y/N) y project.yml was created. Please edit it to fit your FL configuration.
For a secure deployment, you must first configure the participants in the federation. You can modify the participants section of the sample project.yml file to create a simple local deployment as follows. The changes from the default project.yml file are shown in bold text.
participants:
# change overseer.example.com to the FQDN of the overseer
- name: overseer
type: overseer
org: nvidia
protocol: https
api_root: /api/v1
port: 8443
# change example.com to the FQDN of the server
- name: server1
type: server
org: nvidia
fed_learn_port: 8002
admin_port: 8003
# enable_byoc loads python codes in app. Default is false.
enable_byoc: true
components:
There are a few important points in defining the participants:
- The name for each participant must be unique. In the case of the overseer and servers, these names must be resolvable by all servers and clients, either as fully qualified domain names or as hostnames using
/etc/hosts(more on that to come). - For a local deployment, servers must use unique ports for FL and admin. This is not required for a distributed deployment where the servers run on separate systems.
- Participants should set
enable_byoc: trueto allow the deployment of apps with code in a/customfolder, as in the example applications.
The remaining sections of the project.yml file configure the builder modules that define the FLARE workspace. These can be left in the default configuration for now but require some consideration when moving from a secure local deployment to a true distributed deployment.
With the modified project.yml, you can now provision the secure startup kits for the participants.
(nvflare-env) $ provision -p project.yml
Project yaml file: project.yml.
Generated results can be found under workspace/example_project/prod_00. Builder's wip folder removed.
$ tree -d workspace/
workspace/
└── example_project
├── prod_00
│ ├── admin@nvidia.com
│ │ └── startup
│ ├── overseer
│ │ └── startup
│ ├── server1
│ │ └── startup
│ ├── server2
│ │ └── startup
│ ├── site-1
│ │ └── startup
│ └── site-2
│ └── startup
├── resources
└── state
As in POC mode, provisioning generates a workspace with a folder containing the startup kit for each participant, in addition to a zip file for each. The zip files can be used to easily distribute the startup kits in a distributed deployment. Each kit contains the configuration and startup scripts as in POC mode, with the addition of a set of shared certificates used to establish the identity and secure communication among participants.
In secure provisioning, these startup kits are signed to ensure that they have not been modified. Looking at the startup kit for server1, you can see these additional components.
(nvflare-env) $ tree workspace/example_project/prod_00/server1
workspace/example_project/prod_00/server1
└── startup
├── authorization.json
├── fed_server.json
├── log.config
├── readme.txt
├── rootCA.pem
├── server.crt
├── server.key
├── server.pfx
├── signature.json
├── start.sh
├── stop_fl.sh
└── sub_start.sh
To connect the participants, all servers and clients must be able to resolve the servers and overseer at the name defined in project.yml. For a distributed deployment, this could be a fully qualified domain name.
You can also use /etc/hosts on each of the server and client systems to map the server and overseer name to its IP address. For this local deployment, use /etc/hosts to overload the loop-back interface. For example, the following code example adds entries for the overseer and both servers:
(nvflare-env) $ cat /etc/hosts 127.0.0.1 localhost 127.0.0.1 overseer 127.0.0.1 server1 127.0.0.1 server2
Because the overseer and servers all use unique ports, you can safely run all on the local 127.0.0.1 interface.
As in the previous section, you can loop over the set of participants to execute the start.sh scripts included in the startup kits to connect the overseer, servers, and site clients.
(nvflare-env) $ export WORKSPACE=workspace/example_project/prod_00/
(nvflare-env) $ for i in $WORKSPACE/{overseer,server1,server2,site-1,site-2}; do
./$i/startup/start.sh &
done
From here, the process of deploying an app using the admin client is the same as in POC mode with one important change. In secure provisioning, the admin client prompts for a username. In this example, the username is admin@nvidia.com, as configured in project.yml.
Considerations for secure, distributed deployment
In the previous sections, I discussed POC mode and secure deployment on a single system. This single-system deployment factors out a lot of the complexity of a true secure, distributed deployment. On a single system, you have the benefit of a shared environment, shared filesystem, and local networking. A production FLARE workflow on distributed systems must address these issues.
Consistent environment
Every participant in the federation requires the NVIDIA FLARE runtime, along with any dependencies implemented in the server and client workflow. This is easily accommodated in a local deployment with a Python virtual environment.
When running distributed, the environment is not as easy to constrain. One way to address this is running in a container. For the examples earlier, you could create a simple Dockerfile to capture dependencies.
ARG PYTORCH_IMAGE=nvcr.io/nvidia/pytorch:22.04-py3
FROM ${PYTORCH_IMAGE}
RUN python3 -m pip install -U pip
RUN python3 -m pip install -U setuptools
RUN python3 -m pip install torch torchvision tensorboard nvflare
WORKDIR /workspace/
RUN git clone https://github.com/NVIDIA/NVFlare.git
The WorkspaceBuilder referenced in the sample project.yml file includes a variable to define a Docker image:
# when docker_image is set to a Docker image name, # docker.sh is generated on server/client/admin docker_image: nvflare-pyt:latest
When docker_image is defined in the WorkspaceBuilder config, provisioning generates a docker.sh script in each startup kit.
Assuming this example Dockerfile has been built on each of the server, client, and admin systems with tag nvflare-pyt:latest, the container can be launched using the docker.sh script. This launches the container with startup kits mapped in and ready to run. This of course requires Docker and the appropriate permissions and network configuration on the server and client host systems.
An alternative would be to provide a requirements.txt file, as shown in many of the online examples, that can be pip installed in your nvflare-venv virtual environment before running the distributed startup kit.
Distributed systems
In the POC and secure deployment environments discussed so far, we’ve assumed a single system where you could leverage a local, shared filesystem, and where communication was confined to local network interfaces.
When running on distributed systems, you must address these simplifications to establish the federated system. Figure 3 shows the components required for a distributed deployment with high availability, including the relationship between the admin client, overseer, servers, and client systems.
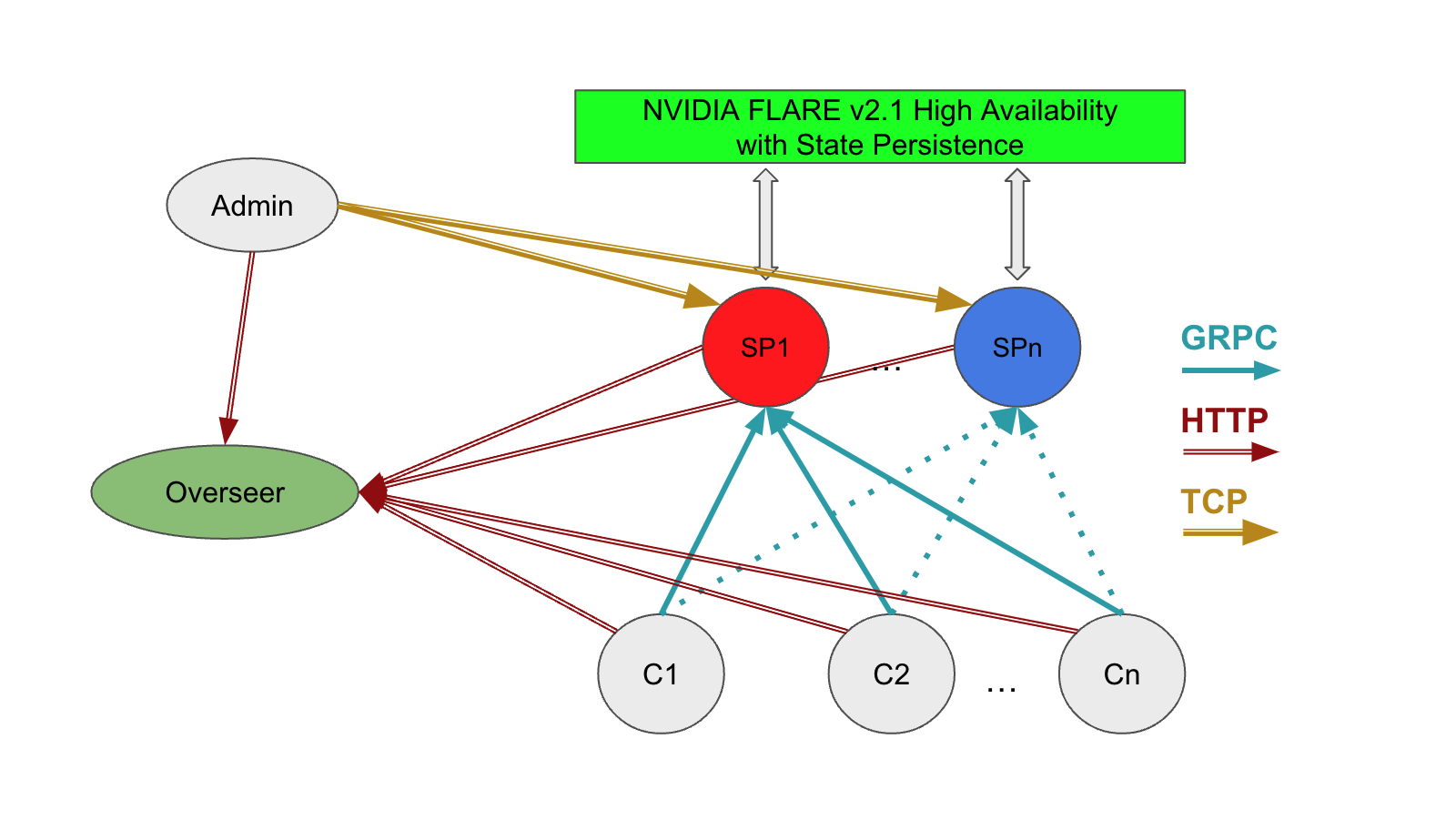
In this model, you must consider the following:
- Network: Client systems must be able to resolve the overseer and service providers at their fully qualified domain names or by mapping IP addresses to hostnames.
- Storage: Server systems must be able to access shared storage to facilitate cutover from the active (hot) service provider, as defined in the
project.ymlfilesnapshot_persistor. - Distribution of configurations or startup kits to each of the participants
- Application configuration and the location of client datasets
Some of these considerations can be addressed by running in a containerized environment as discussed in the previous section, where startup kits and datasets can be mounted on a consistent path on each system.
Other aspects of a distributed deployment depend on the local environment of the host systems and networks and must be addressed individually.
Summary
NVIDIA FLARE v2.1 provides a robust set of tools that enable a researcher or developer to bring a federated learning concept to a real-world production workflow.
The deployment scenarios discussed here are based on our own experience building the FLARE platform, and on the experience of our early adopters bringing federated learning workflows to production. Hopefully, these can serve as a starting point for the development of your own federated applications.
We are actively developing the FLARE platform to meet the needs of researchers, data scientists, and platform developers, and welcome any suggestions and feedback in the NVIDIA FLARE GitHub community!
 Learn more about the NVIDIA NVUE object-oriented, schema-driven model of a complete Cumulus Linux system. The API enables you to configure any system element.
Learn more about the NVIDIA NVUE object-oriented, schema-driven model of a complete Cumulus Linux system. The API enables you to configure any system element.
When network engineers engage with networking gear for the first time, they do it through a command-line interface (CLI). While CLI is still widely used, network scale has reached new highs, making CLI inefficient for managing and configuring the entire data center. Natively, networking is no exception as the software industry has progressed to automation.
Network vendors have all provided different approaches to automate the network as they have branched out from the traditional CLI syntax. Unfortunately, this new branch in the industry has divided the network engineers and IT organizations into two groups: CLI-savvy teams and automation-savvy teams.
This segmentation creates two sets of problems. First, the CLI-savvy teams have difficulty closing the automation gap, limiting their growth pace. Second, finding network automation talent is a challenge, as most developers do not possess networking skills, and most network engineers do not possess automation skills.
To merge the two groups and solve these two problems, NVIDIA introduced a paradigm shift in the CLI approach called NVIDIA User Experience (NVUE).
NVUE is an object-oriented, schema-driven model of a complete Cumulus Linux system (hardware and software). NVUE provides a robust API that allows multiple interfaces to show and configure any element within the system. The NVUE CLI and REST API use the same API to interface with Cumulus Linux.
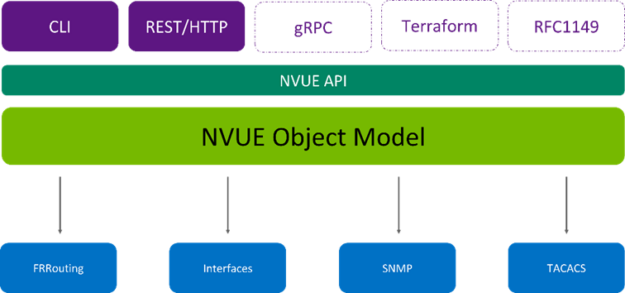
Having all the interfaces use the same object model guarantees consistent results regardless of how an engineer interfaces with the system. For example, the CLI and REST API use the same methods to configure a BGP peer.
REST and CLI are expected for any network device today. An object model can be directly imported into a programming language like Python or Java. This enables you to build configurations for one device or an entire fabric of devices. The following code example shows what an NVUE Python interface might look like in the future:
from nvue import Switch spine01 = Switch() x = 1 while xThe benefits of this revolutionary approach are two-fold:
- For the CLI-savvy, going from CLI to building full automation is an evolution, not an entirely new process.
- Because REST is more common among developers than other networking-oriented models such as YANG, a developer with no networking skills can collaborate with a CLI-savvy network engineer and take the team a considerable step forward towards automating the network.
The more an organization automates its ongoing operation, the more it can focus on innovation rather than operation and serve its ever-growing business needs.
Try it out
One of the most valuable aspects of Cumulus Linux is the ability to try all our features and functions virtually. You can use NVIDIA Air to start using NVUE today and see what you think of the future of network CLIs and programmability.
Finally, there’s a family car any kid would want to be seen in. Beijing-based startup Li Auto this week rolled out its second electric vehicle, the L9. It’s a full-size SUV decked out with the latest intelligent driving technology. With AI features and an extended battery range of more than 800 miles, the L9 promises Read article >
The post Family Style: Li Auto L9 Brings Top-Line Luxury and Intelligence to Full-Size SUV With NVIDIA DRIVE Orin appeared first on NVIDIA Blog.
Categories
An Easy Introduction to Speech AI
 A simple introduction to speech AI technology, use cases and benefits for practitioners.
A simple introduction to speech AI technology, use cases and benefits for practitioners.
Sign up for the latest Speech AI News from NVIDIA.
Artificial intelligence (AI) has transformed synthesized speech from monotone robocalls and decades-old GPS navigation systems to the polished tone of virtual assistants in smartphones and smart speakers.
It has never been so easy for organizations to use customized state-of-the-art speech AI technology for their specific industries and domains.
Speech AI is being used to power virtual assistants, scale call centers, humanize digital avatars, enhance AR experiences, and provide a frictionless medical experience for patients by automating clinical note-taking.
According to Gartner Research, customers will prefer using speech interfaces to initiate 70% of self-service customer interactions (up from 40% in 2019) by 2023. The demand for personalized and automated experiences only continues to grow.
In this post, I discuss speech AI, how it works, the benefits of voice recognition technology, and examples of speech AI use cases.
What is speech AI, and what are the benefits?
Speech AI uses AI for voice-based technologies: automatic speech recognition (ASR), also known as speech-to-text, and text-to-speech (TTS). Examples include automatic live captioning in virtual meetings and adding voice-based interfaces to virtual assistants.
Similarly, language-based applications such as chatbots, text analytics, and digital assistants use speech AI as part of larger applications or systems, alongside natural language processing (NLP). For more information, see the Conversational AI glossary.

There are many benefits of speech AI:
- High availability: Speech AI applications can respond to customer calls during and outside of human agent hours, allowing contact centers to operate more efficiently.
- Real-time insights: Real-time transcripts are dictated and used as inputs for customer-focused business analyses such as sentiment analysis, customer experience analysis, and fraud detection.
- Instant scalability: During peak seasons, speech AI applications can automatically scale to handle tens of thousands of requests from customers.
- Enhanced experiences: Speech AI improves customer satisfaction by reducing holding times, quickly resolving customer queries, and providing human-like interactions with customizable voice interfaces.
- Digital accessibility: From speech-to-text to text-to-speech applications, speech AI tools are helping those with reading and hearing impairments to learn from generated spoken audio and written text.
Who is using speech AI and how?
Today, speech AI is revolutionizing the world’s largest industries such as finance, telecommunications, and unified communication as a service (UCaaS).

Companies starting out with deep-learning, speech-based technologies and mature companies augmenting existing speech-based conversational AI platforms benefit from speech AI.
Here are some specific examples of speech AI driving efficiencies and business outcomes.
Call center transcription
About 10 million call center agents are answering 2 billion phone calls daily worldwide. Call center use cases include all of the following:
- Trend analysis
- Regulatory compliance
- Real-time security or fraud analysis
- Real-time sentiment analysis
- Real-time translation
For example, automatic speech recognition transcribes live conversations between customers and call center agents for text analysis, which is then used to provide agents with real-time recommendations for quickly resolving customer queries.
Clinical note taking
In healthcare, speech AI applications improve patient access to medical professionals and claims representatives. ASR automates note-taking during patient-physician conversations and information extraction for claims agents.
Virtual assistants
Virtual assistants are found in every industry enhancing user experience. ASR is used to transcribe an audio query for a virtual assistant. Then, text-to-speech
generates the virtual assistant’s synthetic voice. Besides humanizing transactional situations, virtual assistants also help the visually impaired interact with non-braille texts, the vocally challenged to communicate with individuals, and children to learn how to read.
How does speech AI work?
Speech AI uses automatic speech recognition and text-to-speech technology to provide a voice interface for conversational applications. A typical speech AI pipeline consists of data preprocessing stages, neural network model training, and post-processing.
In this section, I discuss these stages in both ASR and TTS pipelines.
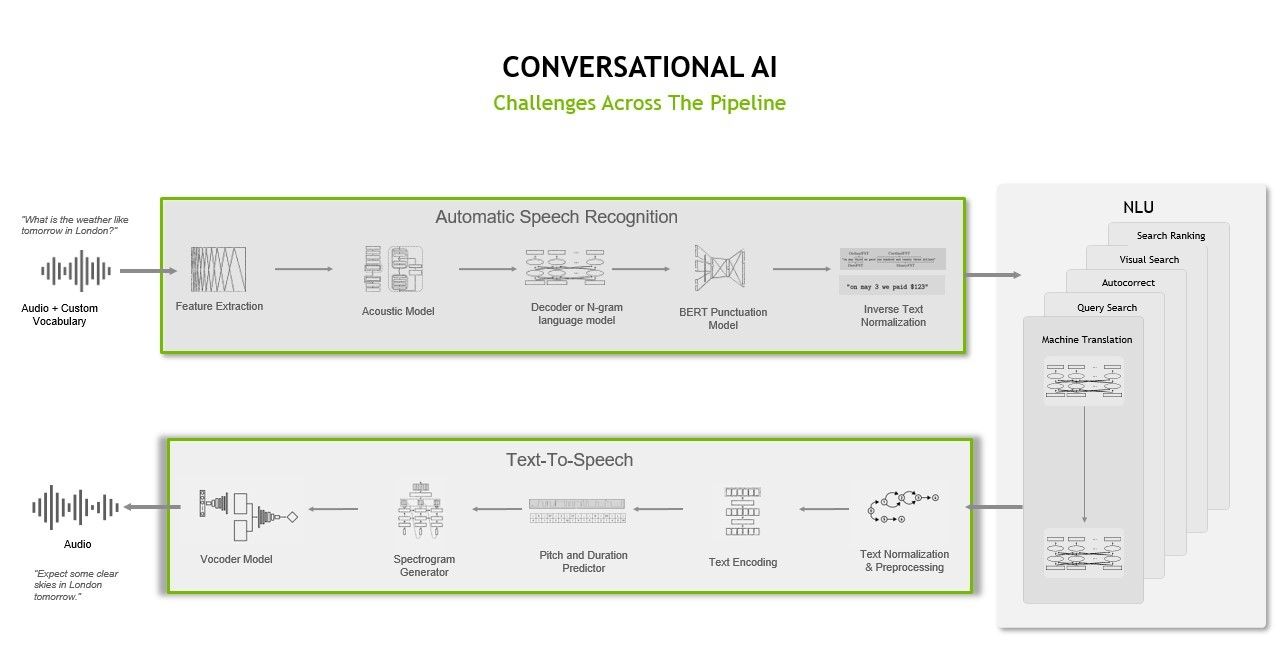
Automatic speech recognition
For machines to hear and speak with humans, they need a common medium for translating sound into code. How can a device or an application “see” the world through sound?
An ASR pipeline processes and transcribes a given raw audio file containing speech into corresponding text while minimizing a metric known as the word error rate (WER).
WER is used to measure and compare performance between types of speech recognition systems and algorithms. It is calculated by the number of errors divided by the number of words in the clip being transcribed.
ASR pipelines must accomplish a series of tasks, including feature extraction, acoustic modeling, as well as language modeling.
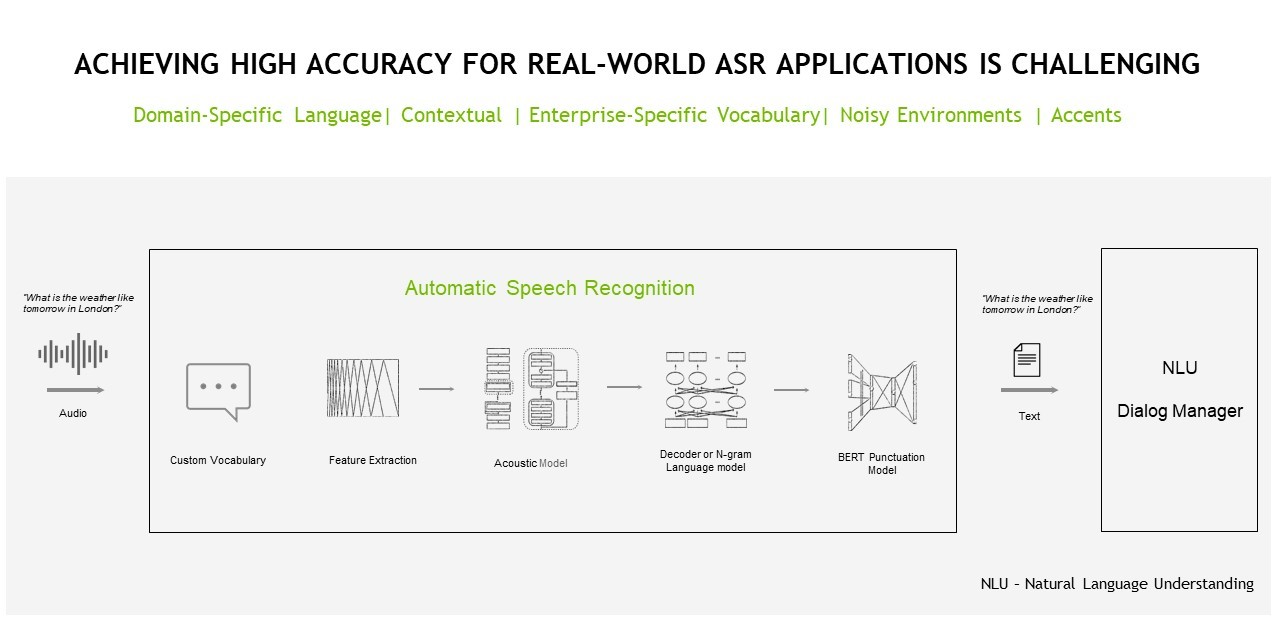
The feature extraction task involves converting raw analog audio signals into spectrograms, which are visual charts that represent the loudness of a signal over time at various frequencies and resemble heat maps. Part of the transformation process involves traditional signal preprocessing techniques like standardization and windowing.
Acoustic modeling is then used to model the relationship between the audio signal and the phonetic units in the language. It maps an audio segment to the most likely distinct unit of speech and corresponding characters.
The final task in an ASR pipeline involves language modeling. A language model adds contextual representation and corrects the acoustic model’s mistakes. In other words, when you have the characters from the acoustic model, you can convert these characters to sequences of words, which can be further processed into phrases and sentences.
Historically, this series of tasks was performed using a generative approach that required using a language model, pronunciation model, and acoustic model to translate pronunciations to audio waveforms. Then, either a Gaussian mixture model or hidden Markov model would be used to try to find the words that most likely match the sounds from the audio waveform.
This statistical approach was less accurate and more intensive in both time and effort to implement and deploy. This was especially true when trying to ensure that each time step of the audio data matched the correct output of characters.
However, end-to-end deep learning models, like connectionist temporal classification (CTC) models and sequence-to-sequence models with attention, can generate the transcript directly from the audio signal and with a lower WER.
In other words, deep learning-based models like Jasper, QuartzNet, and Citrinet enable companies to create less expensive, more powerful, and more accurate speech AI applications.
Text-to-speech
A TTS or speech synthesis pipeline is responsible for converting text into natural-sounding speech that is artificially produced with human-like intonation and clear articulation.
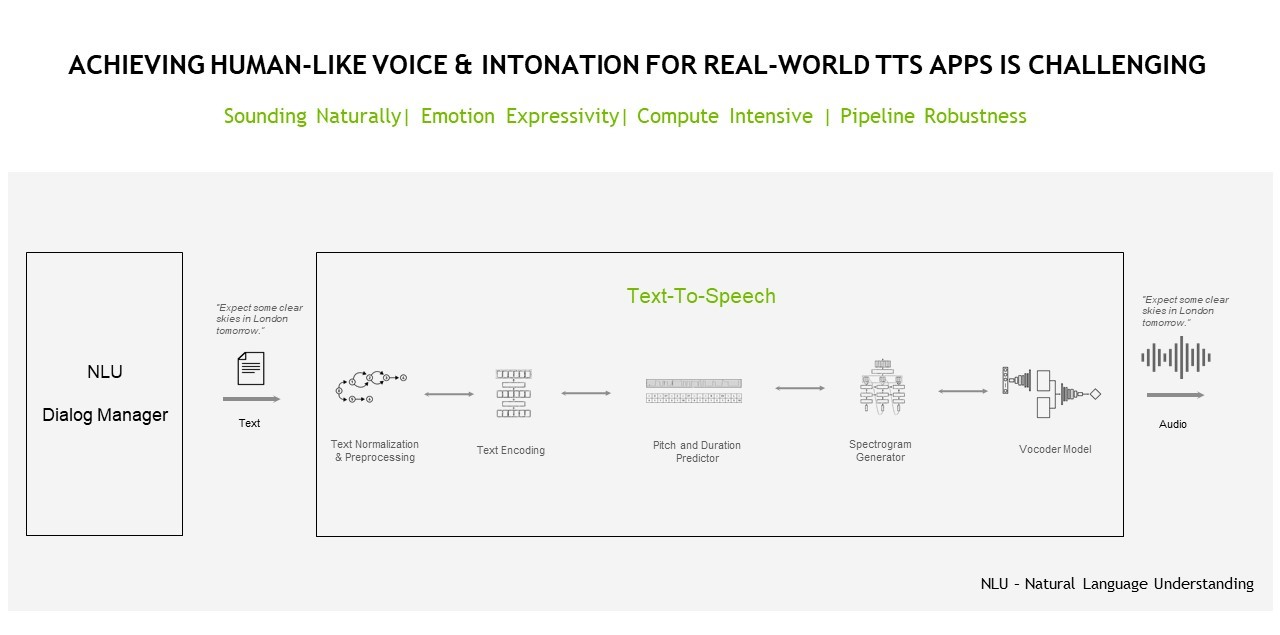
TTS pipelines potentially must accomplish a number of different tasks, including text analysis, linguistic analysis, and waveform generation.
During the text analysis stage, raw text (with symbols, abbreviations, and so on) is converted into full words and sentences, expanding abbreviations, and analyzing expressions. The output is passed into linguistic analysis for refining intonation, duration, and otherwise understanding grammatical structure. As a result, a spectrogram or mel-spectrogram is produced to be converted into continuous human-like audio.
The preceding approach that I walked through is a typical two-step process requiring a synthesis network and a vocoder network. These are two separate networks trained for the subsequent purposes of generating a spectrogram from text (using a Tacotron architecture or FastPitch) and generating audio from the spectrogram or other intermediate representation (like WaveGlow or HiFiGAN).
As well as the two-stage approach, another possible implementation of a TTS pipeline involves using an end-to-end deep learning model that uses a single model to generate audio straight from the text. The neural network is trained directly from text-audio pairs without depending on intermediate representations.
The end-to-end approach decreases complexity as it reduces error propagation between networks, mitigates the need for separate training pipelines, and minimizes the cost of manual annotation of duration information.
Traditional TTS approaches also tend to result in more robotic and unnatural-sounding voices that affect user engagement, particularly with consumer-facing applications and services.
Challenges in building a speech AI system
Successful speech AI applications must enable the following functionality.
Access to state-of-the-art models
Creating highly trained and accurate deep learning models from scratch is costly and time-consuming.
By providing access to cutting-edge models as soon as they’re published, even data and resource-constrained companies can use highly accurate, pretrained models and transfer learning in their products and services out-of-the-box.
High accuracy
To be deployed globally or to any industry or domain, models must be customized to account for multiple languages (a fraction of the 6,500 spoken languages in the world), dialects, accents, and contexts. Some domains use specific terminology and technical jargon.
Real-time performance
Pipelines consisting of multiple deep learning models must run inferences in milliseconds for real-time interactivity, precisely far less than 300 ms, as most users start to notice lags and communication breakdowns around 100 ms, preceding which conversations or experiences begin to feel unnatural.
Flexible and scalable deployment
Companies require different deployment patterns and may even require a mix of cloud, on-premises, and edge deployment. Successful systems support scaling to hundreds of thousands of concurrent users with fluctuating demand.
Data ownership and privacy
Companies should be able to implement the appropriate security practices for their industries and domains, such as safe data processing on-premises or in an organization’s cloud. For example, healthcare companies abiding by HIPAA or other regulations may be required to restrict access to data and data processing.
The future of speech AI
Thanks to advancements in computing infrastructure, speech AI algorithms, increased demand for remote services, and exciting new use cases in existing and emerging industries, there is now a robust ecosystem and infrastructure for speech AI-based products and services.
As powerful as the current applications of speech AI are in driving business outcomes, the next generation of speech AI applications must be equipped to handle multi-language, multi-domain, and multi-user conversations.
Organizations that can successfully integrate speech AI technology into their core operations will be well-equipped to scale their services and offerings for use cases yet to be listed.
Categories
Just Released: CUTLASS v2.9
 The latest version of CUTLASS offers users BLAS3 operators accelerated by tensor cores, Python integrations, GEMM compatibility extensions, and more.
The latest version of CUTLASS offers users BLAS3 operators accelerated by tensor cores, Python integrations, GEMM compatibility extensions, and more.
Thanks to the GeForce cloud, even Mac users can be PC gamers. This GFN Thursday, fire up your Macbook and get your game on. This week brings eight more games to the GeForce NOW library. Plus, members can play Genshin Impact and claim a reward to start them out on their journeys streaming on GeForce Read article >
The post Making an Impact: GFN Thursday Transforms Macs Into GeForce Gaming PCs appeared first on NVIDIA Blog.
A camera begins in the sky, flies through some trees and smoothly exits the forest, all while precisely tracking a car driving down a dirt path. This would be all but impossible in the real world, according to film and photography director Brett Danton.
The post Meet the Omnivore: Director of Photography Revs Up NVIDIA Omniverse to Create Sleek Car Demo appeared first on NVIDIA Blog.
 The NVIDIA Swin UNETR model is the first attempt for large-scale transformer-based self-supervised learning in 3D medical imaging.
The NVIDIA Swin UNETR model is the first attempt for large-scale transformer-based self-supervised learning in 3D medical imaging.
At the Computer Vision and Pattern Recognition Conference (CVPR), NVIDIA researchers are presenting over 35 papers. This includes work on Shifted WINdows UNEt TRansformers (Swin UNETR)—the first transformer-based pretraining framework tailored for self-supervised tasks in 3D medical image analysis. The research is the first step in creating pretrained, large-scale, and self-supervised 3D models for data annotation.
As a transformer-based approach for computer vision, Swin UNETR employs MONAI, an open-source PyTorch framework for deep learning in healthcare imaging, including radiology and pathology. Using this pretraining scheme, Swin UNETR has set new state-of-the-art benchmarks for various medical image segmentation tasks and consistently demonstrates its effectiveness even with a small amount of labeled data.
Swin UNETR model training
The Swin UNETR model was trained on an NVIDIA DGX-1 cluster using eight GPUs and the AdamW optimization algorithm. It was pretrained on 5,050 publicly available CT images from various body regions of healthy and unhealthy subjects selected to maintain a balanced dataset.
For self-supervised pretraining of the 3D Swin Transformer encoder, the researchers used a variety of pretext tasks. Randomly cropped tokens were augmented with different transforms such as rotation and cutout. These tokens were used for masked volume inpainting, rotation, and contrastive learning, for the encoder to learn a contextual representation of training data, without increasing the burden of data annotation.
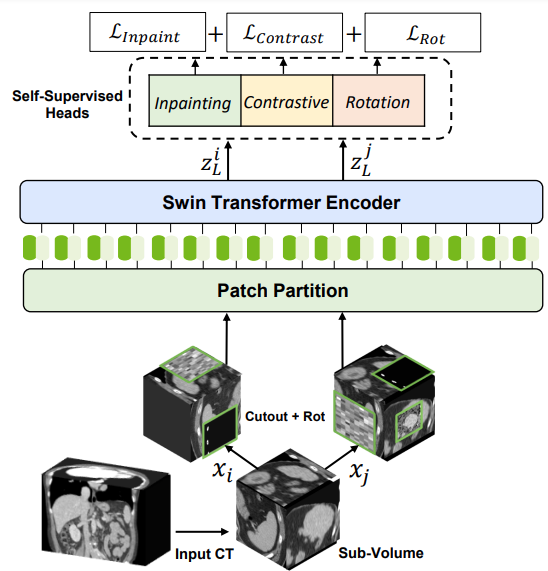
The technology behind Swin UNETR
Swin Transformers adopts a hierarchical Vision Transformer (ViT) for local computing of self-attention with nonoverlapping windows. This unlocks the opportunity to create a medical-specific ImageNet for large companies and removes the bottleneck of needing a large quantity of high-quality annotated datasets for creating medical AI models.
Compared to CNN architectures, the ViT demonstrates exceptional capability in self-supervised learning of global and local representations from unlabeled data (the larger the dataset, the stronger the pretrained backbone). The user can fine-tune the pretrained model in downstream tasks (for example, segmentation, classification, and detection) with a very small amount of labeled data.
This architecture computes self attention in local windows and has shown better performance in comparison to ViT. In addition, the hierarchical nature of Swin Transformers makes them well suited for tasks requiring multiscale modeling.
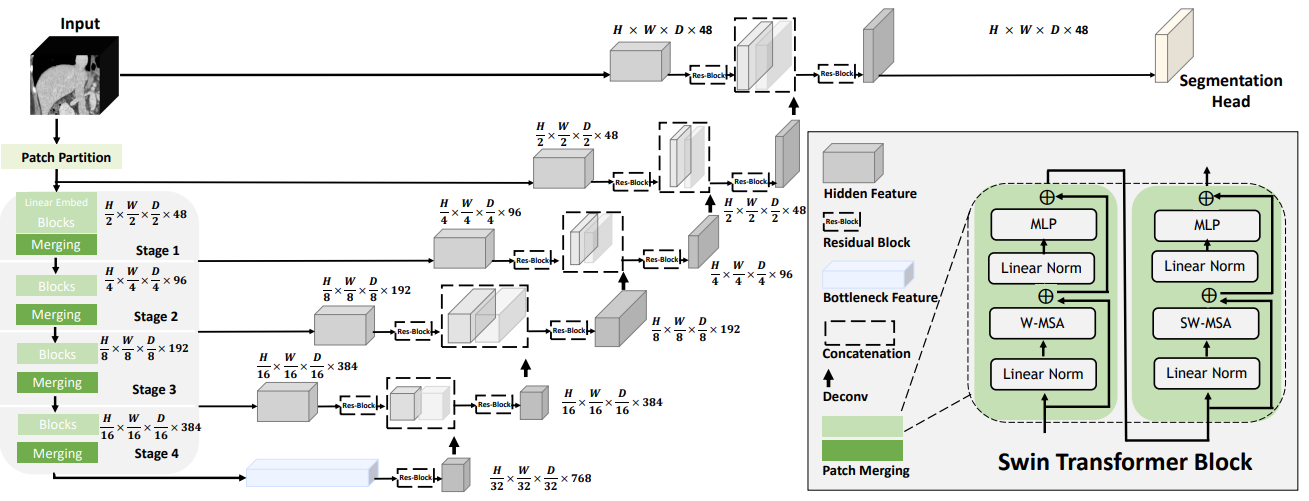
Following the success of the pioneering UNETR model with a ViT-based encoder that directly uses 3D patch embeddings, Swin UNETR uses a 3D Swin Transformer encoder with a pyramid-like architecture.
In the encoder of the Swin UNETR, self-attention is computed in local windows since computing naive global self-attention is not feasible for high-resolution feature maps. In order to increase the receptive field beyond the local windows, window-shifting is used to compute the region interaction for different windows.
The encoder of the Swin UNETR is connected to a residual UNet-like decoder at five different resolutions by skip connections. It can capture multiscale feature representations for dense prediction tasks, such as medical image segmentation.
Swin UNETR model performance
After fine-tuning with the Beyond the Cranial Vault (BTCV) Segmentation Challenge on 13 abdominal organs in CT and the segmentation tasks from the Medical Segmentation Decathlon (MSD) dataset, the model achieved state-of-the-art accuracy on the public leaderboards.
BTCV
In the BTCV, Swin UNETR obtained an average Dice of 0.918, outperforming other top-ranked models.
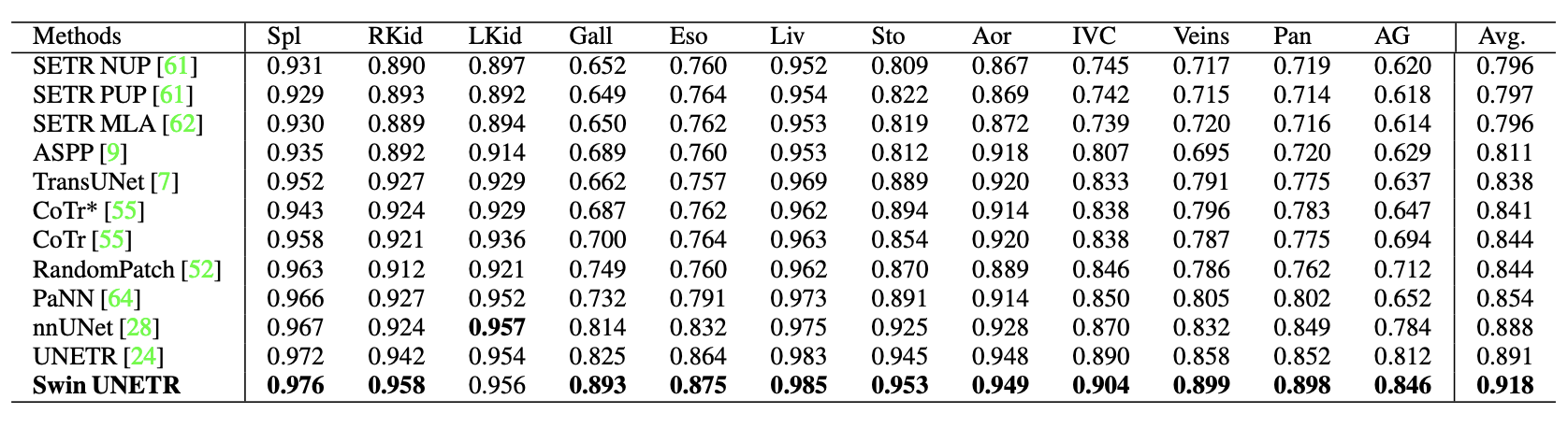
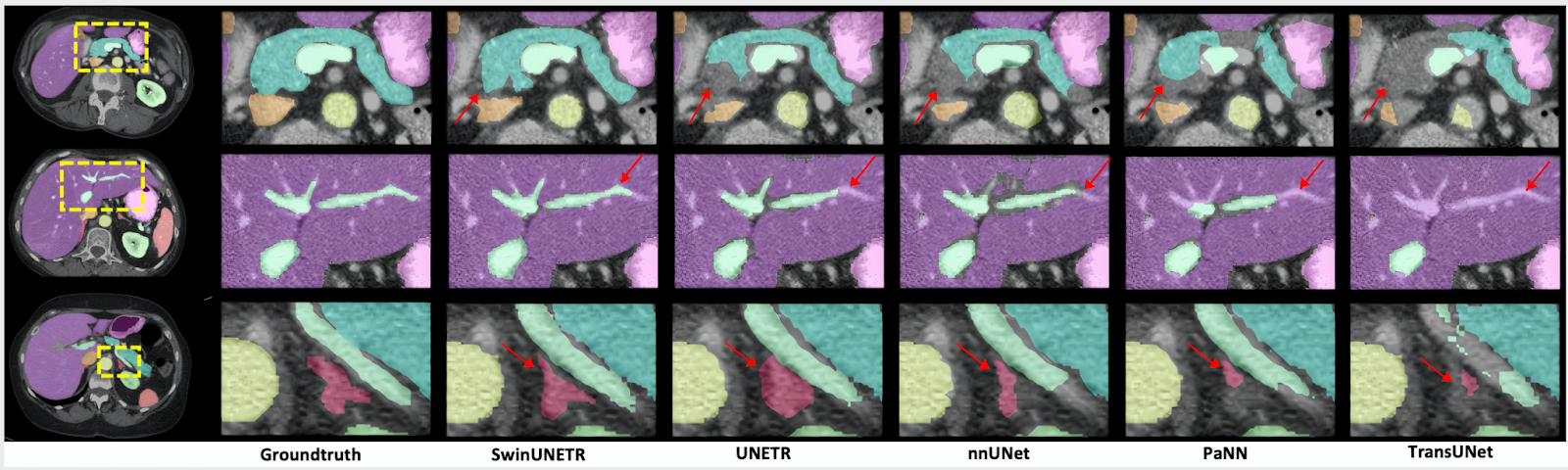
There are improvements compared to prior state-of-the-art methods for smaller organs, such as the splenic and portal veins (3.6%), pancreas (1.6%), and adrenal glands (3.8%.) Small organ data label segmentation is an excruciatingly difficult task for a radiologist. The improvement can be seen in the figure below.
MSD
In the MSD, Swin UNETR achieved state-of-the-art performance in brain tumor, lung, pancreas, and colon. The results are comparable for the heart, liver, hippocampus, prostate, hepatic vessel, and spleen. Overall, Swin UNETR presented the best average Dice of 78.68% across all 10 tasks and achieved the top ranking on the MSD leaderboard.
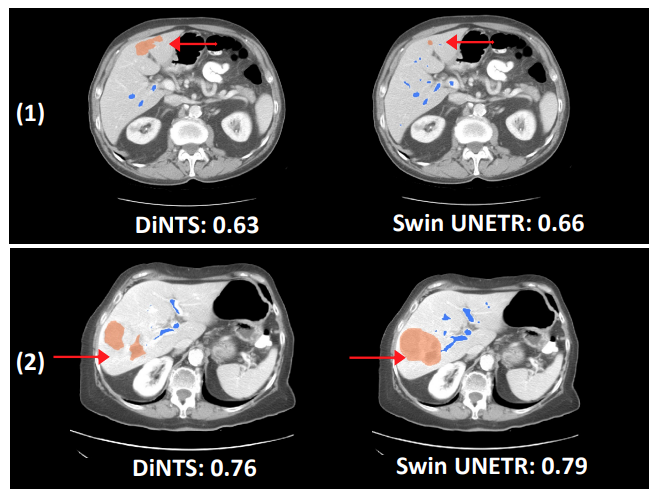
Swin UNETR has shown better segmentation performance using significantly fewer training GPU hours compared to DiNTS—a powerful AutoML methodology for medical image segmentation. For instance, qualitative segmentation outputs for the task of hepatic vessel segmentation demonstrate the capability of Swin UNETR to better model the long-range spatial dependencies.
Conclusion
The Swin UNETR architecture provides a much-needed breakthrough in medical imaging using transformers. Given the need in medical imaging to build accurate models quickly, with Swin UNETR data scientists can pretrain on a large corpus of unlabeled data. This reduces cost and time associated with expert annotation by radiologists, pathologists, and other clinical teams. Here we show SOTA segmentation performance which are used for organ detection and automatic volume measurements.
To learn more:
- Check out this work at the CVPR conference.
- Read the study Self-Supervised Pre-Training of Swin Transformers for 3D Medical Image Analysis.
- Download the SwinUNETR code on GitHub.
 Read how OctoML CLI and NVIDIA Triton automate model optimization and containerization to run models on any cloud or data center, at scale, and at much lower cost.
Read how OctoML CLI and NVIDIA Triton automate model optimization and containerization to run models on any cloud or data center, at scale, and at much lower cost.