Voice-enabled technology is becoming ubiquitous. But many are being left behind by an anglocentric and demographically biased algorithmic world. Mozilla Common…
Voice-enabled technology is becoming ubiquitous. But many are being left behind by an anglocentric and demographically biased algorithmic world. Mozilla Common…
Voice-enabled technology is becoming ubiquitous. But many are being left behind by an anglocentric and demographically biased algorithmic world. Mozilla Common Voice (MCV) and NVIDIA are collaborating to change that by partnering on a public crowdsourced multilingual speech corpus—now the largest of its kind in the world—and open-source pretrained models. It is now easier than ever before to develop automatic speech recognition (ASR) technology that works for speakers of many languages.
This post summarizes the top questions asked during Unlocking Speech AI Technology for Global Language Users, a recorded talk from the Speech AI Summit 2022 featuring EM Lewis-Jong of Mozilla Common Voice and Caroline de Brito Gottlieb of NVIDIA.
Do multilingual NVIDIA NeMo open-source models exist?
Caroline de Brito Gottlieb: To make Speech AI more accessible and serve a global community, we first need to understand how the world uses language. Monolingualism is an anomaly worldwide, so researchers at NVIDIA are focused on creating state-of-the-art AI for multilingual contexts.
Through NeMo, NVIDIA has released its first model for multilingual and code-switched/code-mixed speech recognition, which can transcribe audio samples into English, Latin/North American Spanish, as well as both English and Spanish used in the same sentence—a phenomenon called code-switching, or code-mixing. NVIDIA will soon have a multilingual model on NeMo for Indic languages as well.
The switching or mixing of codes is very common in multilingual communities and communities speaking multiple dialects or varieties of the same language. This poses unique challenges for existing speech AI solutions. However, the open-source NeMo model is an important step toward AI that accurately reflects and supports how global communities actually use speech in real-world contexts.
Do datasets extend beyond “language” to include domain-specific vocabulary? For example, finance and healthcare datasets may differ.
EM Lewis-Jong: Domains represented within the corpora on MCV have been historically driven by communities who choose to create datasets through the platform. That means different languages have varied domains represented in their datasets—some might be heavy on news and media, whereas others might contain more educational text. If you want to enhance domain-specific coverage in a Common Voice dataset, simply go through the process of adding text into the platform through GitHub or the Sentence Collector tool. All domains are welcome.
MCV is actively rebuilding and expanding the Sentence Collector tool to make it easier to ingest large volumes of text, and tag them appropriately. Expect to see these changes in April 2023. Also, the team has been collaborating closely with NVIDIA and other data partners to ensure the metadata schema is as interoperable as possible. Domain tagging the Common Voice corpora is a big part of that.
Caroline de Brito Gottlieb: Accounting for domain-specific language is a critical challenge, in particular when applying AI solutions across industries. That is why NVIDIA Riva offers multiple techniques, such as word boosting and vocabulary extension, for customizing ASR models to improve the recognition of specific words.
Our team primarily thinks of domain as a matter of vocabulary and terminology. This alone is a big challenge, given the different levels of specialized terminology and acronyms like GPU, FTP, and more. But it is also important to collect domain-specific data beyond just individual words to capture grammatical or structural differences; for example, the way negation is expressed in clinical practice guidelines. Designing and curating domain-specific datasets is an active area of collaboration between Common Voice and NVIDIA, and we’re excited to see progress in domain-specific ASR for languages beyond English.
How do you differentiate varied versions of Spanish, English, Portuguese, and other languages across geographies?
EM Lewis-Jong: Historically, MCV didn’t have a great system for differentiating between varied versions of a language. Communities chose between creating an entirely new dataset (organized by language), or they could use the accent field. In 2021, MCV did an intensive research exercise and discovered the following:
- Limited community awareness about variants: New communities without much context weren’t always sure about how to categorize themselves. Once they’d made the decision about whether to become a new language dataset or remain as an accent, it was difficult to change their minds.
- Dataset fragmentation: Diverse communities, such as those with large diaspora populations, may feel they need to split up entirely and set up a whole new language. This fragments the dataset and confuses contributors.
- Identity and experience: Some language communities and contributors make use of accent tags, but can feel marginalized and undermined by this. Talking about language is talking about power, and some people want to have the ability to identify their speech beyond ‘accent’ in ways that respect and represent them.
- Linguistic and orthographic diversity: Some communities felt there was no suitable arrangement for them, as their spoken language had multiple writing systems. Currently, MCV assumes a 1:1 relationship between spoken word and written word.
For these reasons, the team enabled a new category on the platform called Variant. This is intended to help communities systematically differentiate within languages, and especially to support large languages with a diverse range of speakers.
Where possible, MCV uses BCP-47 codes for tagging. BCP 47 is a flexible system that enables communities to pull out key information such as region, dialect, and orthography.
For example, the Kiswahili community might like to differentiate between Congolese Swahili and Chimwiini. Historically on the platform, this would be framed as an ‘accent’ difference—despite the fact that the variants have different vocabulary and grammar and would not be easily mutually intelligible. In other words, speakers might struggle to understand one another.
Communities are now free to choose whether and how they make use of the variant tag. MCV is rolling this out to language communities in phases. The team produced new definitions around language, variant, and accent to act as helpful guidelines for communities. These are living definitions that will evolve with the MCV community. For more information, check out How We’re Making Common Voice Even More Linguistically Inclusive.
What are some examples of successfully deployed use cases?
EM Lewis-Jong: MCV is used by researchers, engineers, and data scientists at most of the world’s largest tech companies, as well as by academics, startups, and civil society. It is downloaded hundreds of thousands of times a year.
Some recent use cases the team is very excited about include the Kinyarwanda Mbaza chatbot, which provides COVID-19 guidance, Thai language health tracking wearables for the visually impaired, financial planning apps in Kiswahili like ChamaChat and agricultural health guidance for farmers in Kenya like LivHealth.
Caroline de Brito Gottlieb: NeMo—which uses MCV, among other datasets—is also widely deployed. Tarteel AI is an AI-focused, faith-based startup focusing on religious and educational tech. The Tarteel team leveraged NVIDIA Riva and NeMo AI tooling to achieve state-of-the-art word error rate (WER) of 4% on Arabic transcription by fine-tuning an English ASR model on Arabic language data. This enabled Tarteel to develop the world’s first Quranic Arabic ASR, providing technology to support a community of 1.8 billion Muslim across the world in improving their Quran recitation through real-time feedback.
In January 2023, Riva released an out-of-the-box Arabic ASR model that can be seamlessly customized for specific dialects, accents, and domains. Another use case on Singaporean English, or Singlish, is presented in Easy Speech AI Customization for Local Singaporean Voice.
How does Mozilla collect the diversity attributes of the Common Voice data set for a language, such as age and sex?
EM Lewis-Jong: MCV enables users to self-identify and associate their clips with relevant information: variant (if your language has them), accent (an important diversity attribute), sex, and age. This year MCV will expand these options for some demographic categories, in particular sex, to be more inclusive.
This information will be associated with your clips, and then securely and safely pseudonymised before the dataset is released. You can tell MCV about your linguistic features in the usual contribution flow; however, for sensitive demographic attributes, you must create an account.
What type of ASR model is best to use when fine-tuning a particular language?
Caroline de Brito Gottlieb: NeMo is a toolkit with pretrained models that enables you to fine-tune for your own language and specific use case. State-of-the-art pretrained NeMo models are freely available on NGC, the NVIDIA hub for GPU-optimized software, and HuggingFace. Check out the extensive tutorials that can all be run on Google Colab, and a full suite of example scripts supporting multi-GPU/multi-node training.
In addition to the languages already offered in NeMo ASR, community members have used NeMo to obtain state-of-the-art results for new languages, dialects, variants, and accents by fine-tuning NeMo base models. Much of that work has used NVIDIA pretrained English language ASR models, but I encourage you to try fine-tuning on a NeMo model for a language most related to the one you are working on. You can start by looking up the family and genealogical classification of a language in Glottolog.
My native language, Yoruba, is not on MCV. What can be done to include it along with its different dialects?
EM Lewis-Jong: Anyone can add a new language to MCV. Reach out about adding your language.
There are two stages to the process: translating the site and collecting sentences.
Translating the site involves a Mozilla tool called Pontoon for translations. Pontoon has lots of languages, but if it doesn’t have yours you can request for your language to be added. Then, to make the language available on the Common Voice project, request the new language on GitHub. Get more details about site translation and how to use Pontoon.
Collecting sentences involves adding small numbers of sentences, or performing bulk imports using GitHub. Remember that sentences need to be CC0 (or public domain), or you can write your own. Learn more about sentence collection and using the Sentence Collector.
Does data augmentation factor into the need for more diversity?
Caroline de Brito Gottlieb: Speech AI models need to be robust for diverse environmental factors and contextual variations, especially as the team scales up to more languages, communities, and therefore, contexts. However, authentic data is not always available to represent this diversity.
Data augmentation is a powerful tool to enhance the size and variety of datasets by simulating speech data characteristics. When applied to training data, the resulting expanded or diversified dataset can help models generalize better to new scenarios and unseen data.
When data augmentation techniques are applied to datasets used for testing, it enables understanding the model’s performance in an expanded variety of speech data contexts. NeMo offers various data augmentation techniques such as noise perturbation, speech perturbation, and time stretch augmentation, which can be applied to training and testing data.
Do the datasets in MCV support different accents, such as speaking German with a French accent?
EM Lewis-Jong: There are as many accents as there are speakers, and all are welcome. As of December 2021, you can easily add multiple accents in your profile page.
Accents are not limited by what others have chosen. You can stipulate your accent on your own terms, making it easier for contributors to quickly identify their speech in a natural way.
For example, if you’re a French speaker originally from Germany, who learned French in a Cote D’Ivoire context, you can add accents like ‘German’ and ‘Cote D’Ivoire’ to your French clip submissions.
Summary
To create a healthier AI ecosystem, communities need to be meaningfully engaged in the data creation process. In addition, open-sourcing speech datasets and ASR models enables innovation for everyone.
If you would like to contribute to the public crowdsourced multilingual speech corpus, check out NVIDIA NeMo on GitHub and Mozilla Common Voice to get involved.
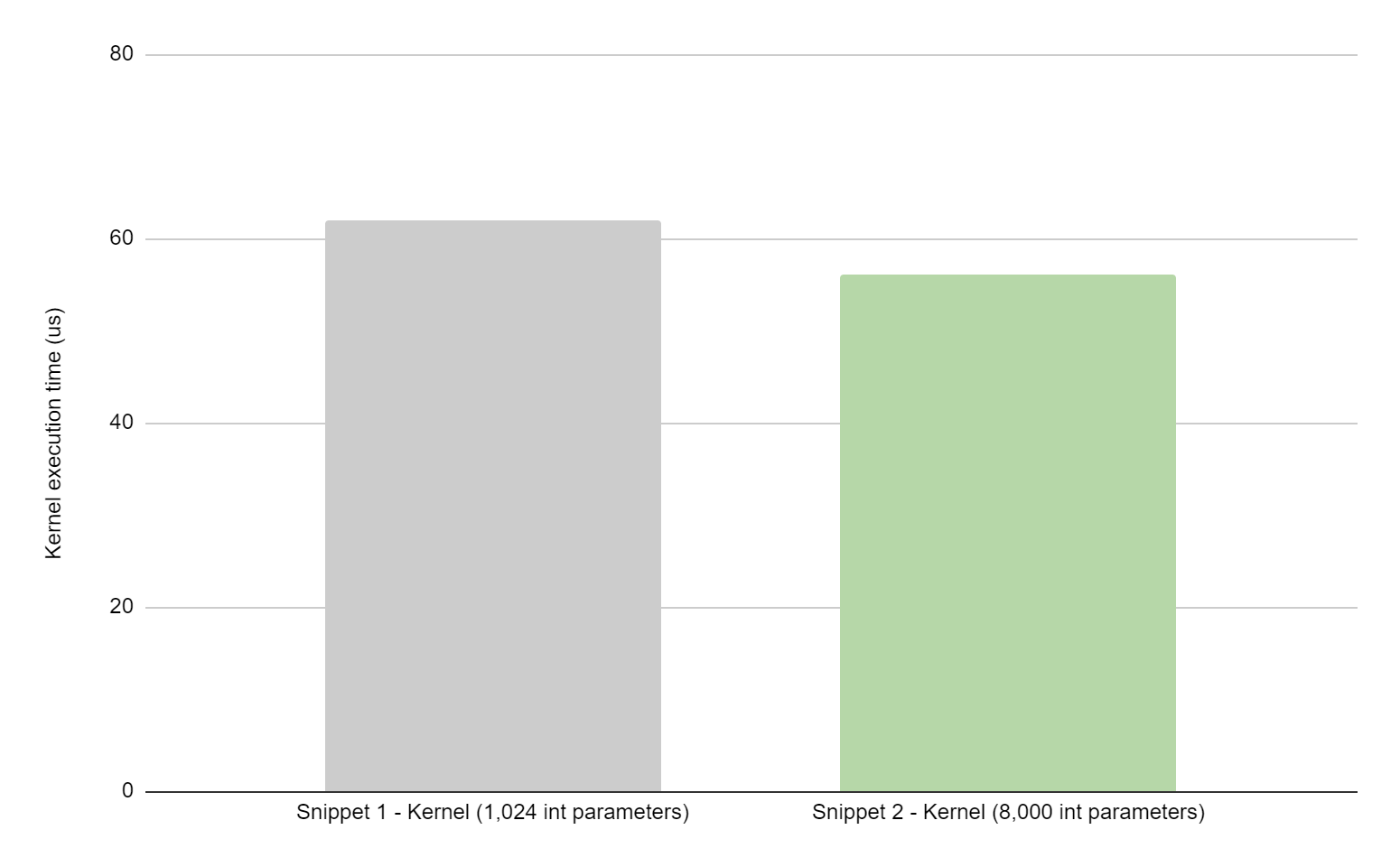
 CUDA kernel function parameters are passed to the device through constant memory and have been limited to 4,096 bytes. CUDA 12.1 increases this parameter limit…
CUDA kernel function parameters are passed to the device through constant memory and have been limited to 4,096 bytes. CUDA 12.1 increases this parameter limit…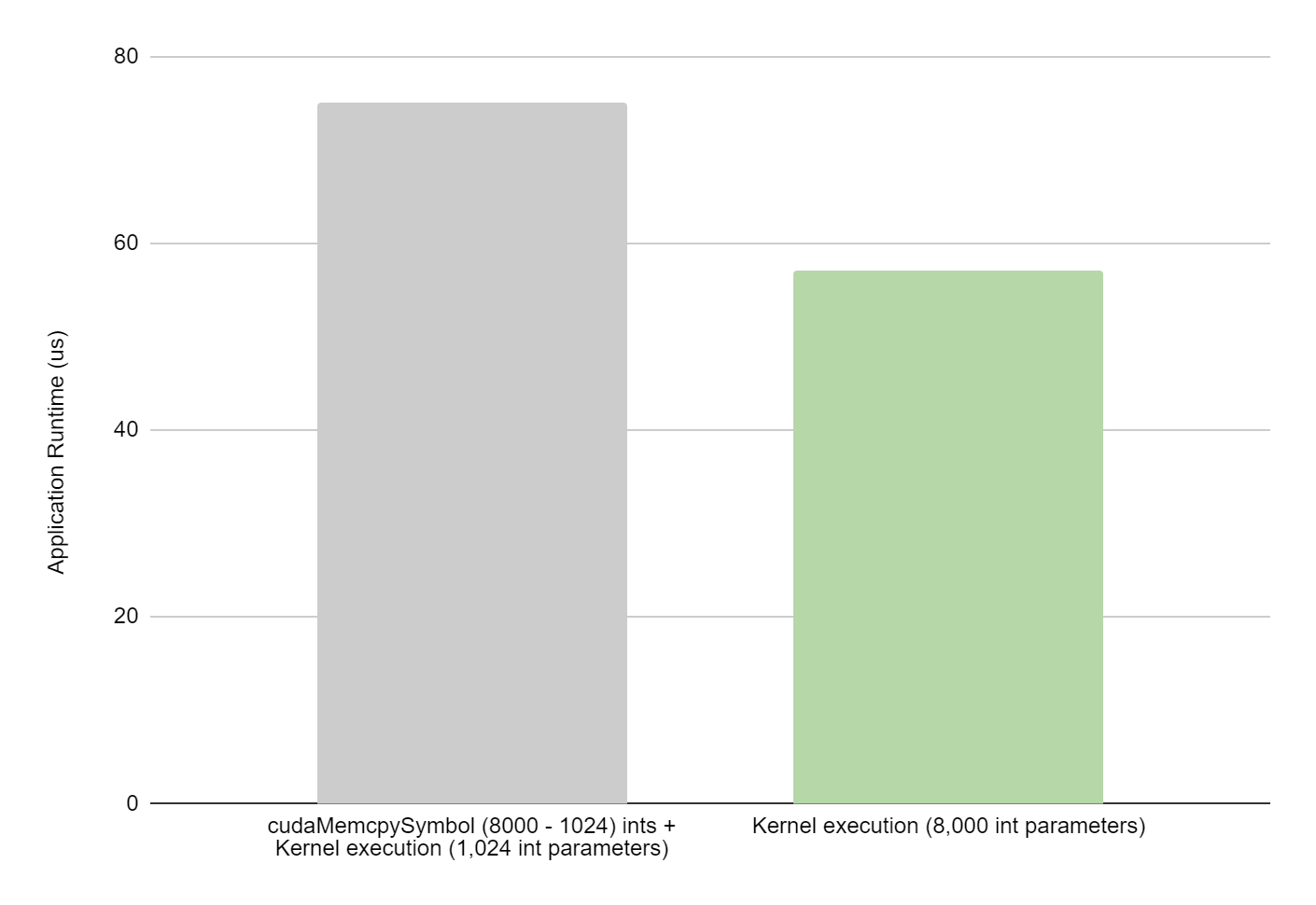
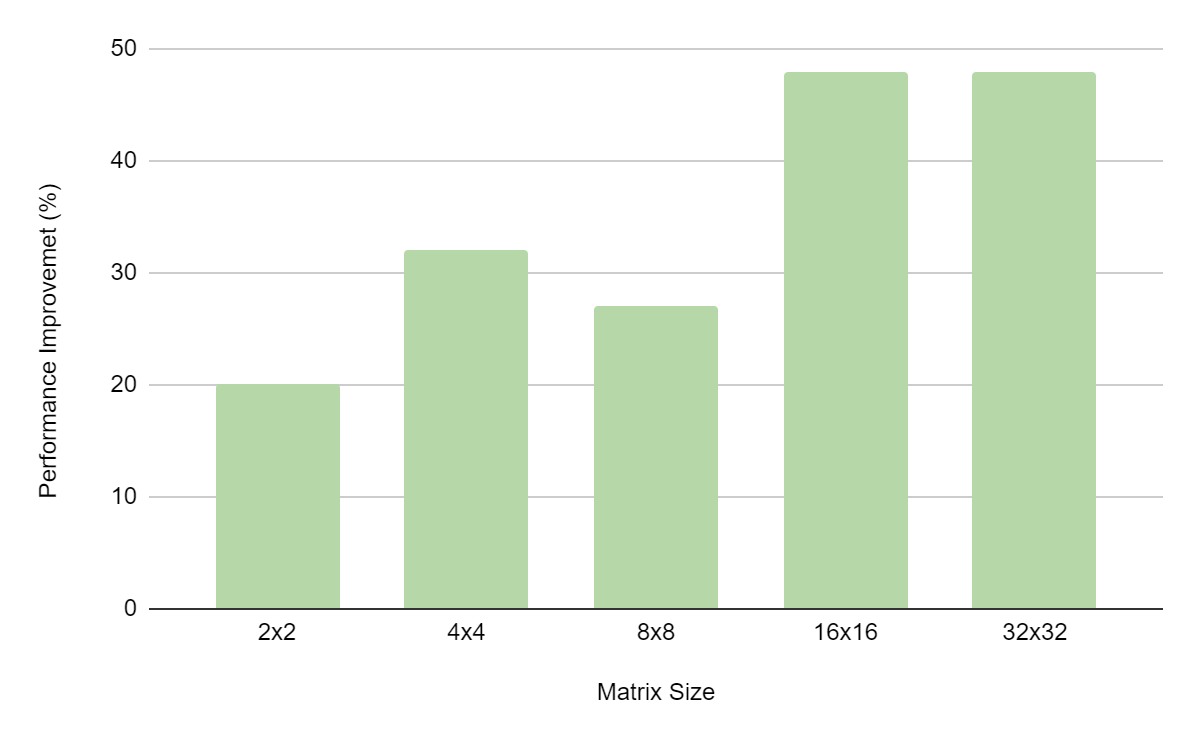
 The NVIDIA Jetson Orin Nano and Jetson AGX Orin Developer Kits are now available at a discount for qualified students, educators, and researchers.Since its…
The NVIDIA Jetson Orin Nano and Jetson AGX Orin Developer Kits are now available at a discount for qualified students, educators, and researchers.Since its…


 AI is transforming industries, automating processes, and opening new opportunities for innovation in the rapidly evolving technological landscape. As more…
AI is transforming industries, automating processes, and opening new opportunities for innovation in the rapidly evolving technological landscape. As more…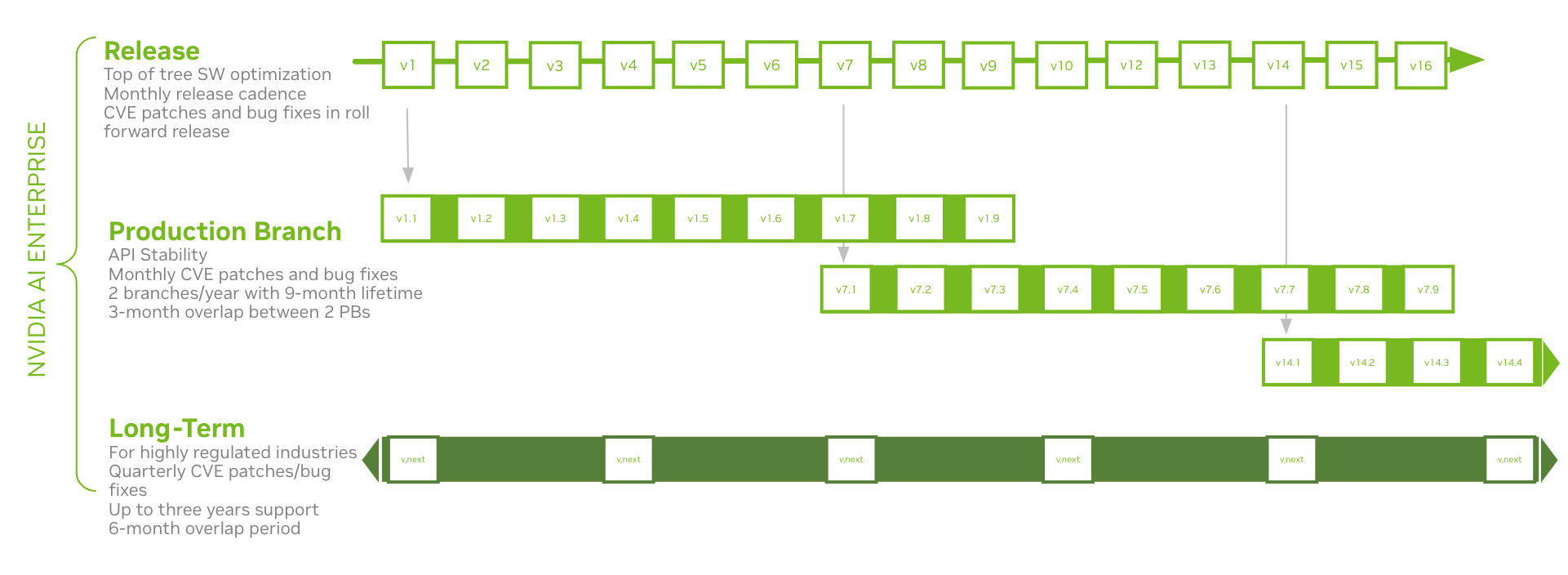
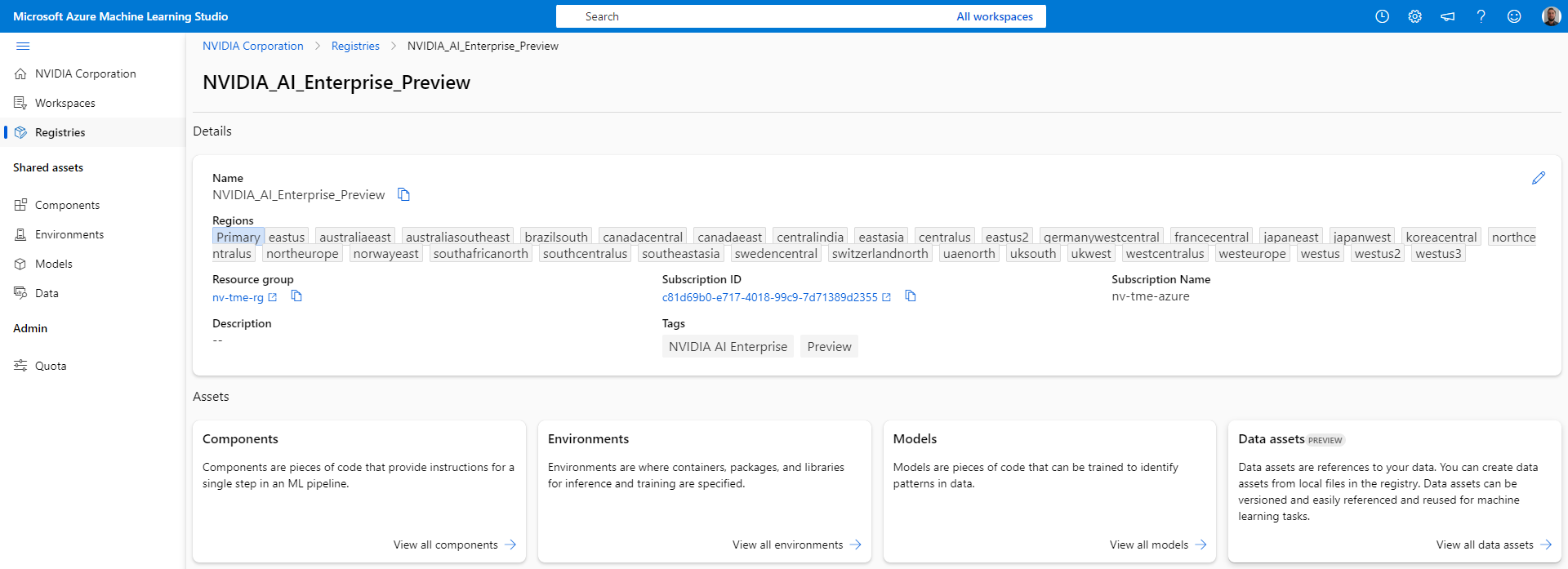
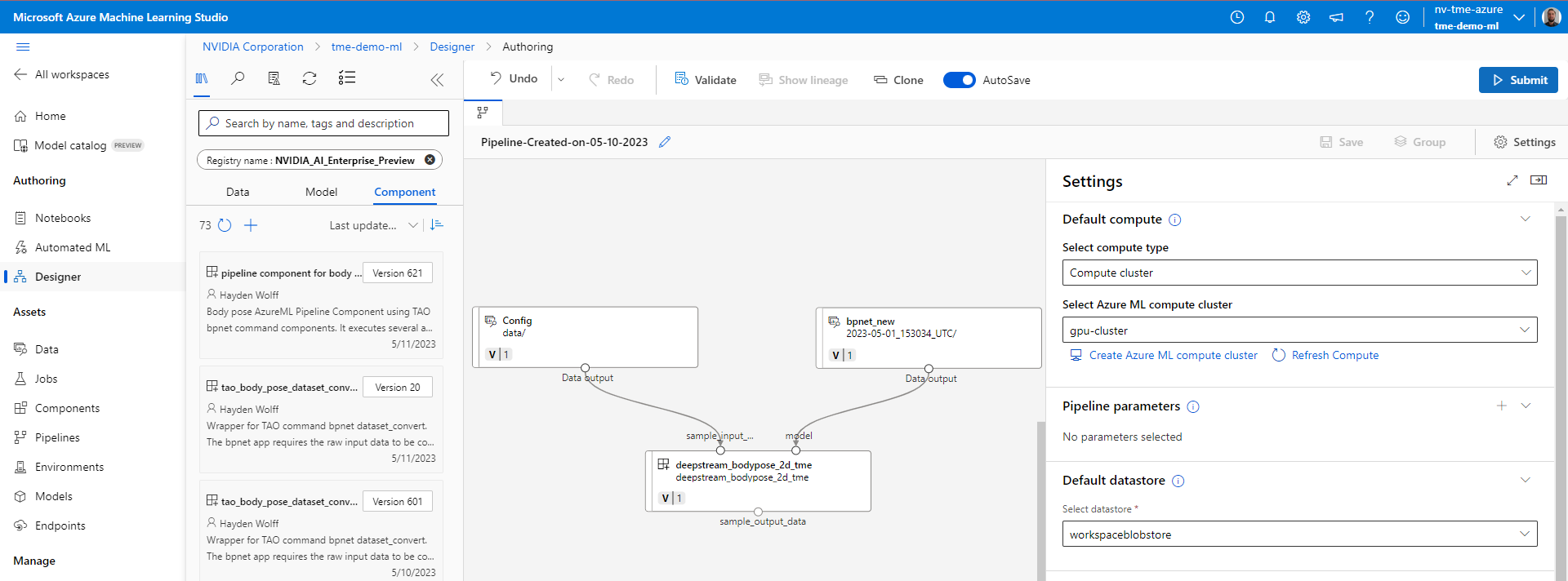
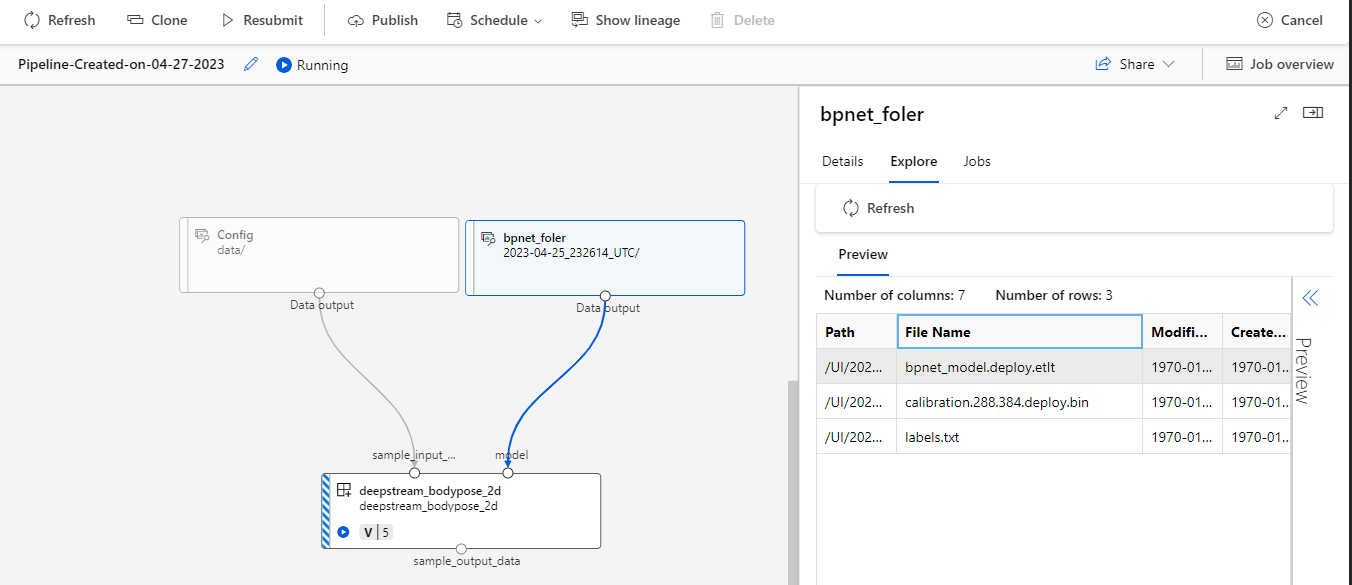



.png)
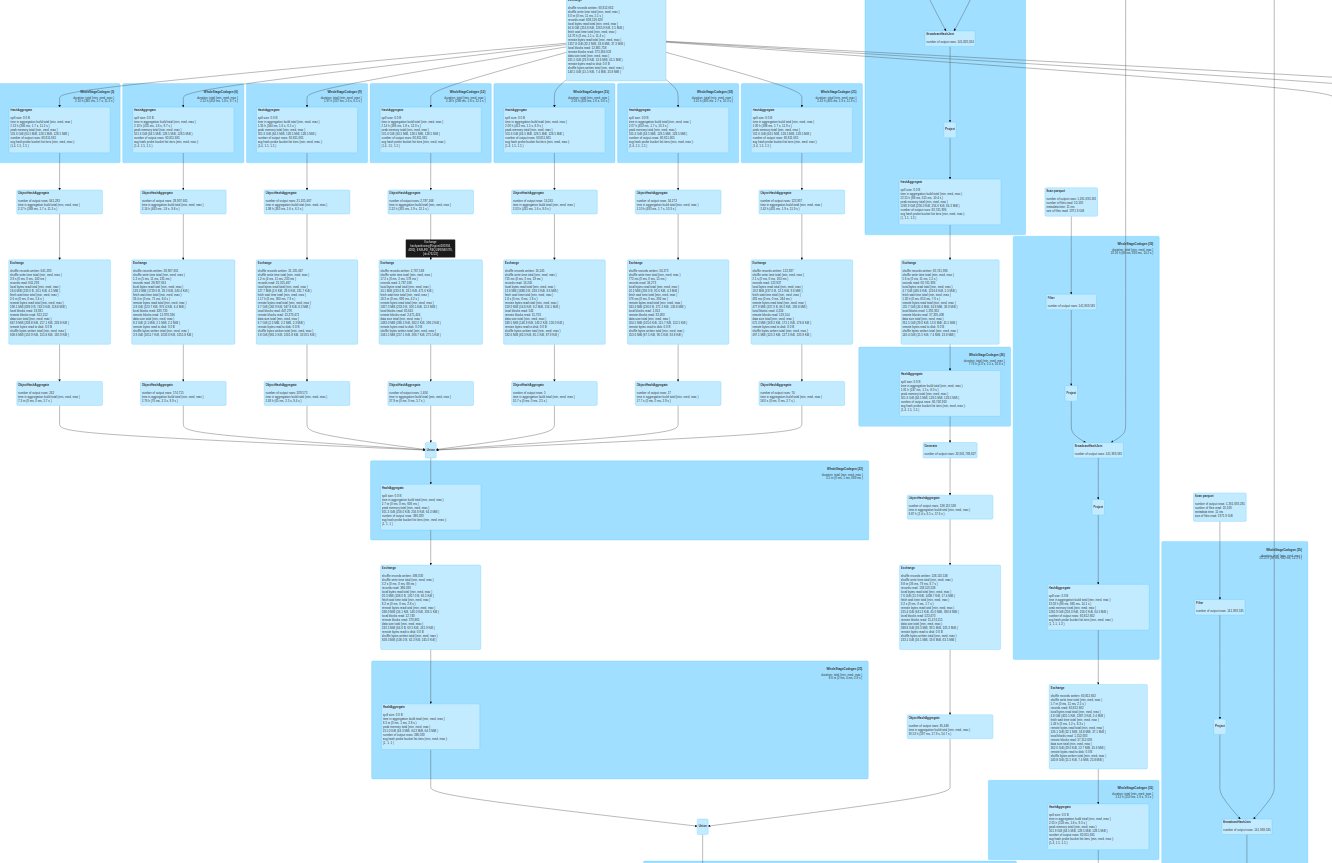
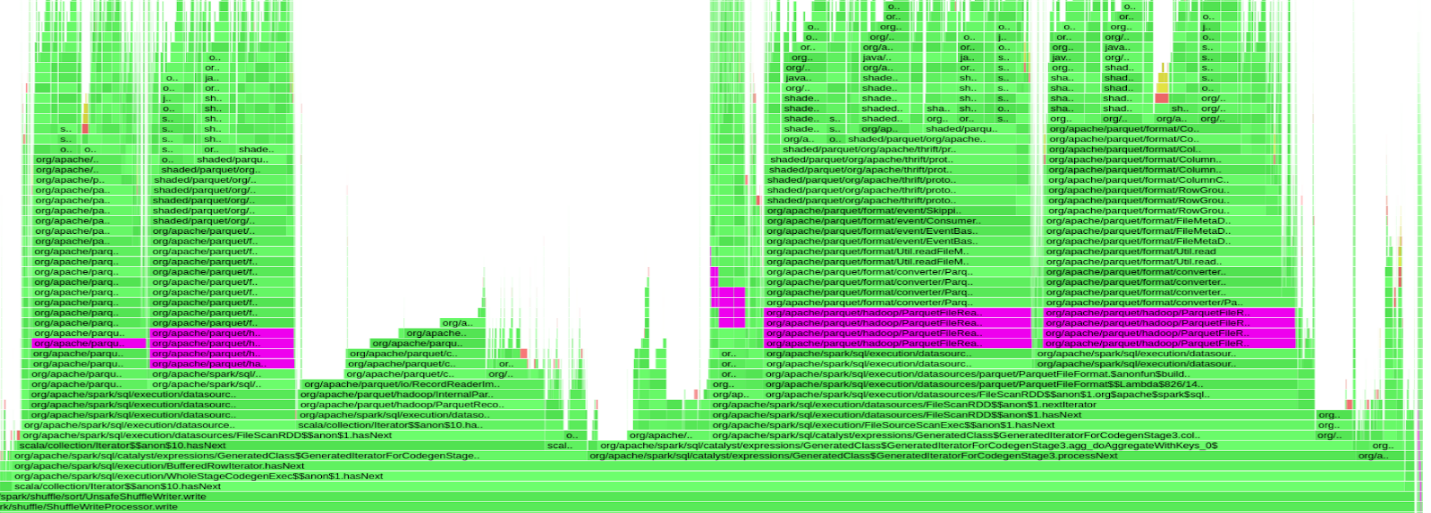
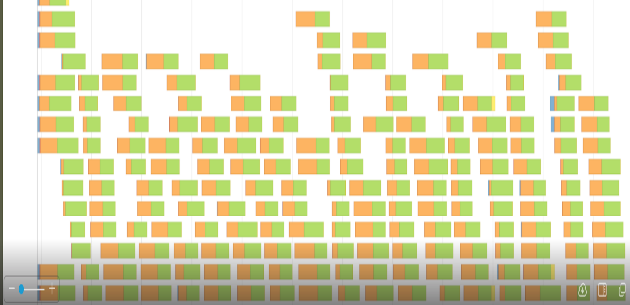
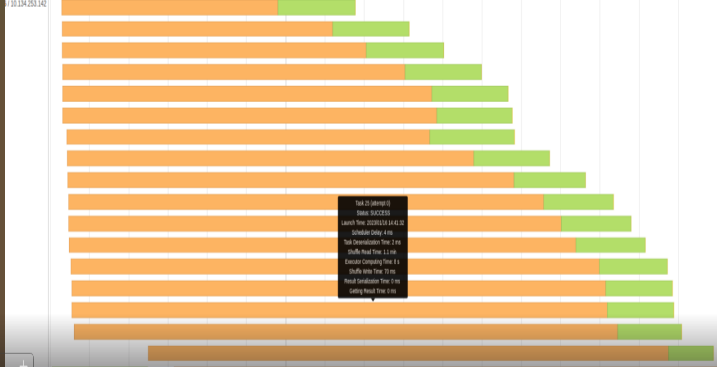
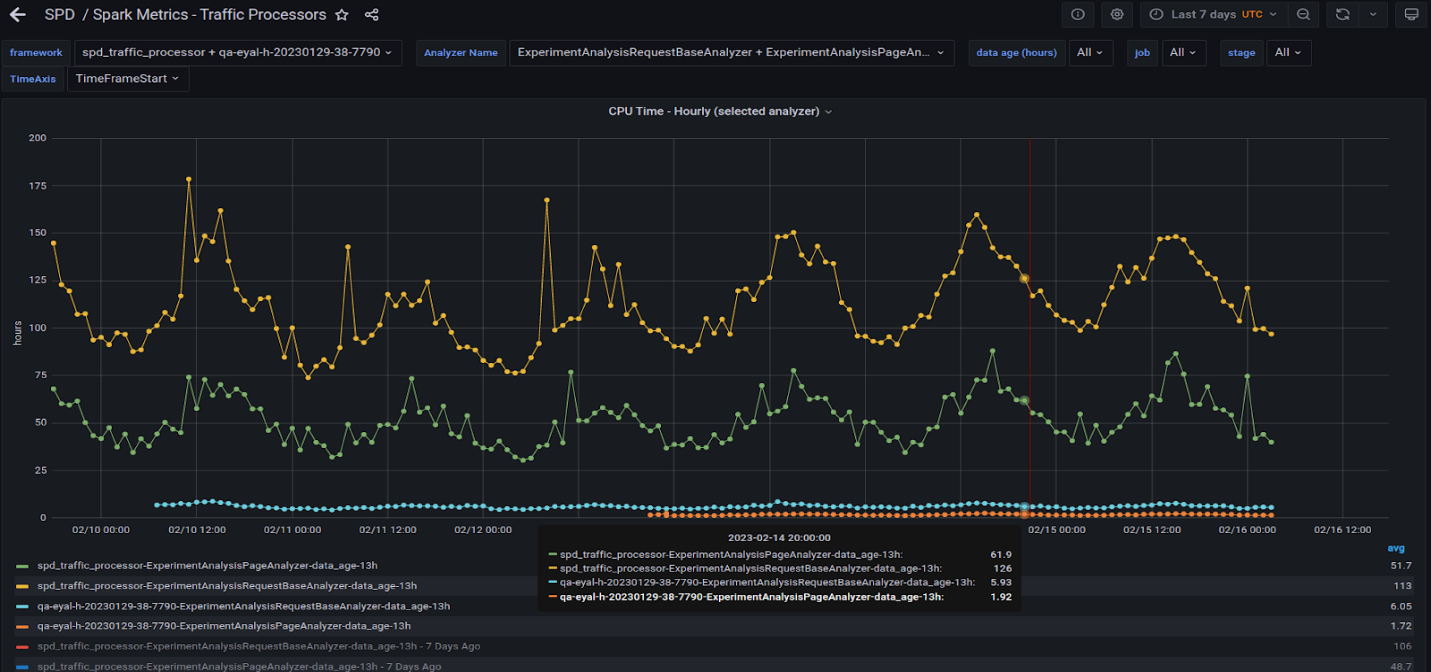
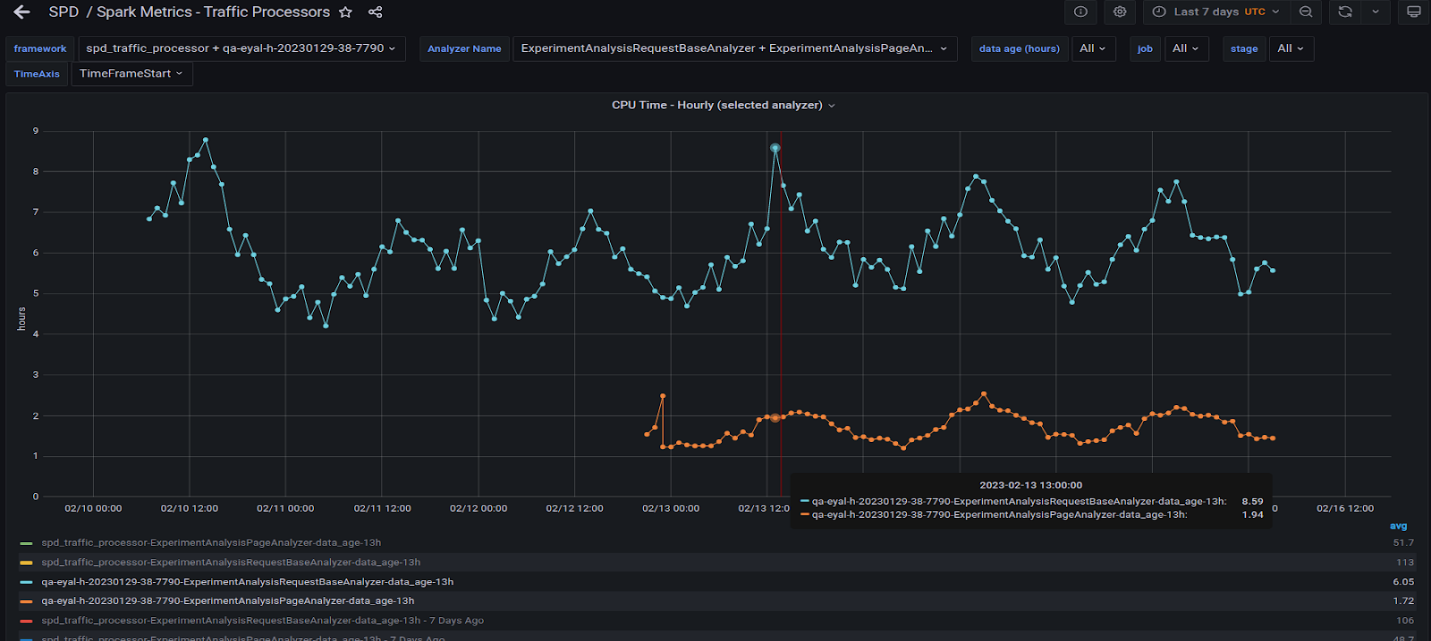
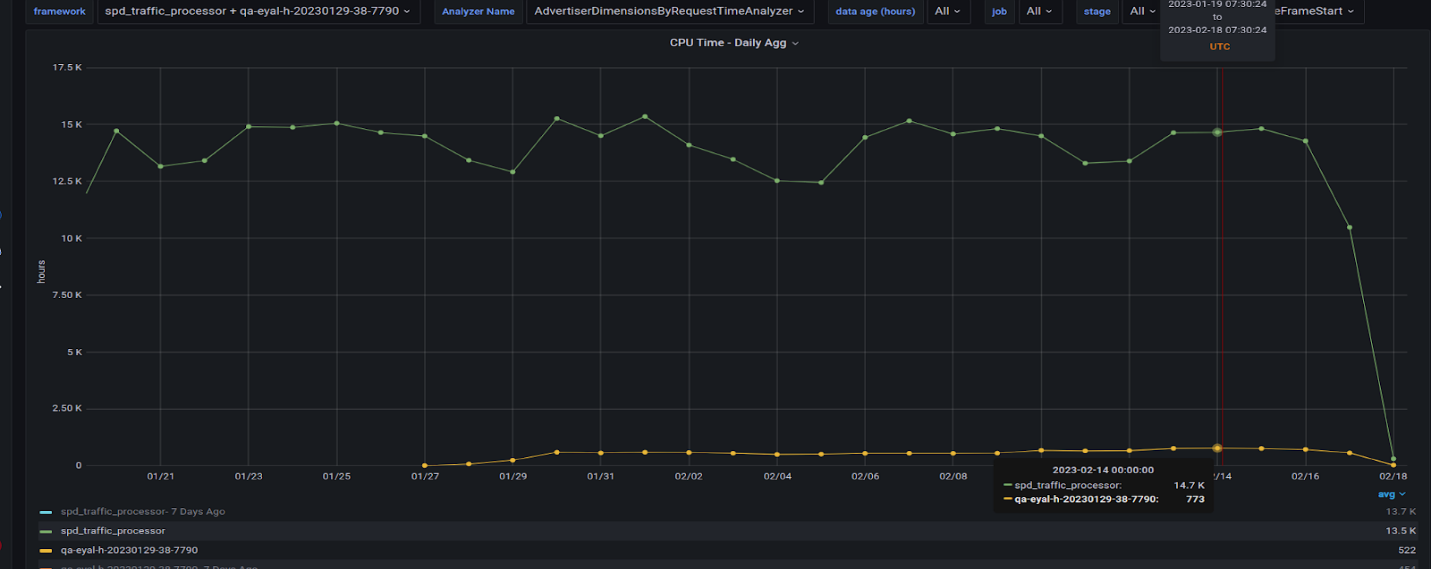
 When you see a context-relevant advertisement on a web page, it’s most likely content served by a Taboola data pipeline. As the leading content recommendation…
When you see a context-relevant advertisement on a web page, it’s most likely content served by a Taboola data pipeline. As the leading content recommendation…