Tokyo-based startup Telexistence this week announced it will deploy NVIDIA AI-powered robots to restock shelves at hundreds of FamilyMart convenience stores in Japan. There are 56,000 convenience stores in Japan — the third-highest density worldwide. Around 16,000 of them are run by FamilyMart. Telexistence aims to save time for these stores by offloading repetitive tasks Read article >
Posted by AJ Piergiovanni and Anelia Angelova, Research Scientists, Google Research, Brain Team
Video is an ubiquitous source of media content that touches on many aspects of people’s day-to-day lives. Increasingly, real-world video applications, such as video captioning, video content analysis, and video question-answering (VideoQA), rely on models that can connect video content with text or natural language. VideoQA is particularly challenging, however, as it requires grasping both semantic information, such as objects in a scene, as well as temporal information, e.g., how things move and interact, both of which must be taken in the context of a natural-language question that holds specific intent. In addition, because videos have many frames, processing all of them to learn spatio-temporal information can be computationally expensive. Nonetheless, understanding all this information enables models to answer complex questions — for example, in the video below, a question about the second ingredient poured in the bowl requires identifying objects (the ingredients), actions (pouring), and temporal ordering (second).
An example input question for the VideoQA task “What is the second ingredient poured into the bowl?” which requires deeper understanding of both the visual and text inputs. The video is an example from the 50 Salads dataset, used under the Creative Commons license.
To address this, in “Video Question Answering with Iterative Video-Text Co-Tokenization”, we introduce a new approach to video-text learning called iterative co-tokenization, which is able to efficiently fuse spatial, temporal and language information for VideoQA. This approach is multi-stream, processing different scale videos with independent backbone models for each to produce video representations that capture different features, e.g., those of high spatial resolution or long temporal durations. The model then applies the co-tokenization module to learn efficient representations from fusing the video streams with the text. This model is highly efficient, using only 67 giga-FLOPs (GFLOPs), which is at least 50% fewer than previous approaches, while giving better performance than alternative state-of-the-art models.
Video-Text Iterative Co-tokenization The main goal of the model is to produce features from both videos and text (i.e., the user question), jointly allowing their corresponding inputs to interact. A second goal is to do so in an efficient manner, which is highly important for videos since they contain tens to hundreds of frames as input.
The model learns to tokenize the joint video-language inputs into a smaller set of tokens that jointly and efficiently represent both modalities. When tokenizing, we use both modalities to produce a joint compact representation, which is fed to a transformer layer to produce the next level representation. A challenge here, which is also typical in cross-modal learning, is that often the video frame does not correspond directly to the associated text. We address this by adding two learnable linear layers which unify the visual and text feature dimensions before tokenization. This way we enable both video and text to condition how video tokens are learned.
Moreover, a single tokenization step does not allow for further interaction between the two modalities. For that, we use this new feature representation to interact with the video input features and produce another set of tokenized features, which are then fed into the next transformer layer. This iterative process allows the creation of new features, or tokens, which represent a continual refinement of the joint representation from both modalities. At the last step the features are input to a decoder that generates the text output.
As customarily done for VideoQA, we pre-train the model before fine-tuning it on the individual VideoQA datasets. In this work we use the videos automatically annotated with text based on speech recognition, using the HowTo100M dataset instead of pre-training on a large VideoQA dataset. This weaker pre-training data still enables our model to learn video-text features.
Visualization of the video-text iterative co-tokenization approach. Multi-stream video inputs, which are versions of the same video input (e.g., a high resolution, low frame-rate video and a low resolution, high frame-rate video), are efficiently fused together with the text input to produce a text-based answer by the decoder. Instead of processing the inputs directly, the video-text iterative co-tokenization model learns a reduced number of useful tokens from the fused video-language inputs. This process is done iteratively, allowing the current feature tokenization to affect the selection of tokens at the next iteration, thus refining the selection.
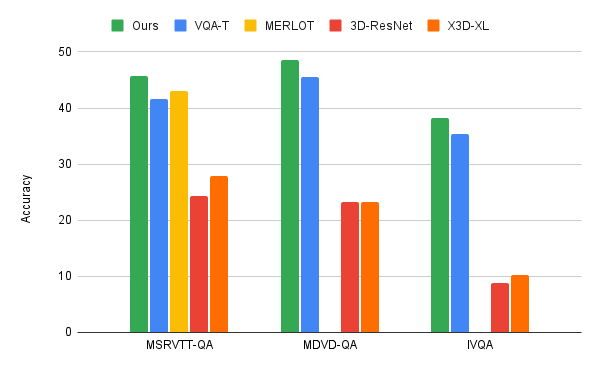
Efficient Video Question-Answering We apply the video-language iterative co-tokenization algorithm to three main VideoQA benchmarks, MSRVTT-QA, MSVD-QA and IVQA, and demonstrate that this approach achieves better results than other state-of-the-art models, while having a modest size. Furthermore, iterative co-tokenization learning yields significant compute savings for video-text learning tasks. The method uses only 67 giga-FLOPs (GFLOPS), which is one sixth the 360 GFLOPS needed when using the popular 3D-ResNet video model jointly with text and is more than twice as efficient as the X3D model. This is all the while producing highly accurate results, outperforming state-of-the-art methods.
Comparison of our iterative co-tokenization approach to previous methods such as MERLOT and VQA-T, as well as, baselines using single ResNet-3D or X3D-XL.
Multi-stream Video Inputs For VideoQA, or any of a number of other tasks that involve video inputs, we find that multi-stream input is important to more accurately answer questions about both spatial and temporal relationships. Our approach utilizes three video streams at different resolutions and frame-rates: a low-resolution high frame-rate, input video stream (with 32 frames-per-second and spatial resolution 64×64, which we denote as 32x64x64); a high-resolution, low frame-rate video (8x224x224); and one in-between (16x112x112). Despite the apparently more voluminous information to process with three streams, we obtain very efficient models due to the iterative co-tokenization approach. At the same time these additional streams allow extraction of the most pertinent information. For example, as shown in the figure below, questions related to a specific activity in time will produce higher activations in the smaller resolution but high frame-rate video input, whereas questions related to the general activity can be answered from the high resolution input with very few frames. Another benefit of this algorithm is that the tokenization changes depending on the questions asked.
Visualization of the attention maps learned per layer during the video-text co-tokenization. The attention maps differ depending on the question asked for the same video. For example, if the question is related to the general activity (e.g., surfing in the figure above), then the attention maps of the higher resolution low frame-rate inputs are more active and seem to consider more global information. Whereas if the question is more specific, e.g., asking about what happens after an event, the feature maps are more localized and tend to be active in the high frame-rate video input. Furthermore, we see that the low-resolution, high-frame rate video inputs provide more information related to activities in the video.
Conclusion We present a new approach to video-language learning that focuses on joint learning across video-text modalities. We address the important and challenging task of video question-answering. Our approach is both highly efficient and accurate, outperforming current state-of-the-art models, despite being more efficient. Our approach results in modest model sizes and can gain further improvements with larger models and data. We hope this work provokes more research in vision-language learning to enable more seamless interaction with vision-based media.
Acknowledgements This work is conducted by AJ Pierviovanni, Kairo Morton, Weicheng Kuo, Michael Ryoo and Anelia Angelova. We thank our collaborators in this research, and Soravit Changpinyo for valuable comments and suggestions, and Claire Cui for suggestions and support. We also thank Tom Small for visualizations.
For cutting-edge visual effects and virtual production, creative teams and studios benefit from digital sets and environments that can be updated in real time. A crucial element in any virtual production environment is a sky dome, often used to provide realistic lighting for virtual environments and in-camera visual effects. Legendary studio Industrial Light & Magic Read article >
NVIDIA AI tools are enabling deep learning-powered performance capture for creators at every level: visual effects and animation studios, creative professionals — even any enthusiast with a camera. With NVIDIA Vid2Vid Cameo, creators can harness AI to capture their facial movements and expressions from any standard 2D video taken with a professional camera or smartphone. Read article >
In a swift, eye-popping special address at SIGGRAPH, NVIDIA execs described the forces driving the next era in graphics, and the company’s expanding range of tools to accelerate them. “The combination of AI and computer graphics will power the metaverse, the next evolution of the internet,” said Jensen Huang, founder and CEO of NVIDIA, kicking Read article >
A glimpse into the future of AI-infused virtual worlds was on display at SIGGRAPH — the world’s largest gathering of computer graphics experts — as NVIDIA founder and CEO Jensen Huang put the finishing touches on the company’s special address.
Over the past few decades, the Internet has fundamentally changed the world and set in motion an enormous transformation in the way we consume and share…
Over the past few decades, the Internet has fundamentally changed the world and set in motion an enormous transformation in the way we consume and share information. The transformation is so complete that today, a quality web presence is vital for nearly all businesses, and interacting with the web is central to functioning effectively in the modern world.
The web has evolved from static documents to dynamic applications involving rich interactive media. Yet despite the fact that we live in a 3D world, the web remains overwhelmingly two-dimensional.
Now we find ourselves at the threshold of the web’s next major advancement: the advent of the 3D Internet or metaverse. Instead of linking together 2D pages, the metaverse will link together virtual worlds. Websites will become interconnected 3D spaces akin to the world we live in and experience every day.
Many of these virtual worlds will be digital twins reflecting the real world, linked and synchronized in real time. Others will be designed for entertainment, socializing, gaming, learning, collaboration, or commerce.
No matter what the purpose of any individual site, what will make the entire metaverse a success will be the same thing that has made the 2D web so successful: universal interoperability based on open standards and protocols.
The most fundamental standard needed to create the metaverse is the description of a virtual world. At NVIDIA, we believe the first version of that standard already exists. It is Universal Scene Description (USD) — an open and extensible body of software for describing 3D worlds that was originally developed by Pixar to enable their complex animated film production workflows.
Open sourced in 2015, USD is now being used in a wide range of industries not only in media and entertainment, but also spanning architecture, engineering, design, manufacturing, retail, scientific computing, and robotics, among others.
USD is more than a file format
USD is a scene description: a set of data structures and APIs to create, represent, and modify virtual worlds. The representation is rich. It supports not only the basics of virtual worlds like geometry, cameras, lights, and materials, but also a wide variety of relationships among them, including property inheritance, instancing and specialization.
It includes features necessary for scaling to large data sets like lazy loading and efficient retrieval of time-sampled data. It is tremendously extensible, allowing users to customize data schemas, input and output formats, and methods for finding assets. In short, USD covers the very broad range of requirements that Pixar found necessary to make its feature films.
Figure 1. A visual representation of how USD enables layered workflows for industry-specific use cases
Layers are probably the single most innovative feature of USD. Conceptually, they have some similarities to layers in Adobe Photoshop: the final composite is the result of combining the effects of all the layers in order. But instead of modifying the pixels of an image like Photoshop layers, USD layers modify the properties of the composed scene. Most importantly, they provide a powerful mechanism for collaboration.
Different users can modify the composed scene on different layers, and their edits will be non-destructive. The stronger layer will win out in the composition, but the data from the weaker layer remains accessible. Beyond direct collaboration, the ability that layers provide to non-destructively modify what others have done enables the kind of composability that has made the traditional web so successful.
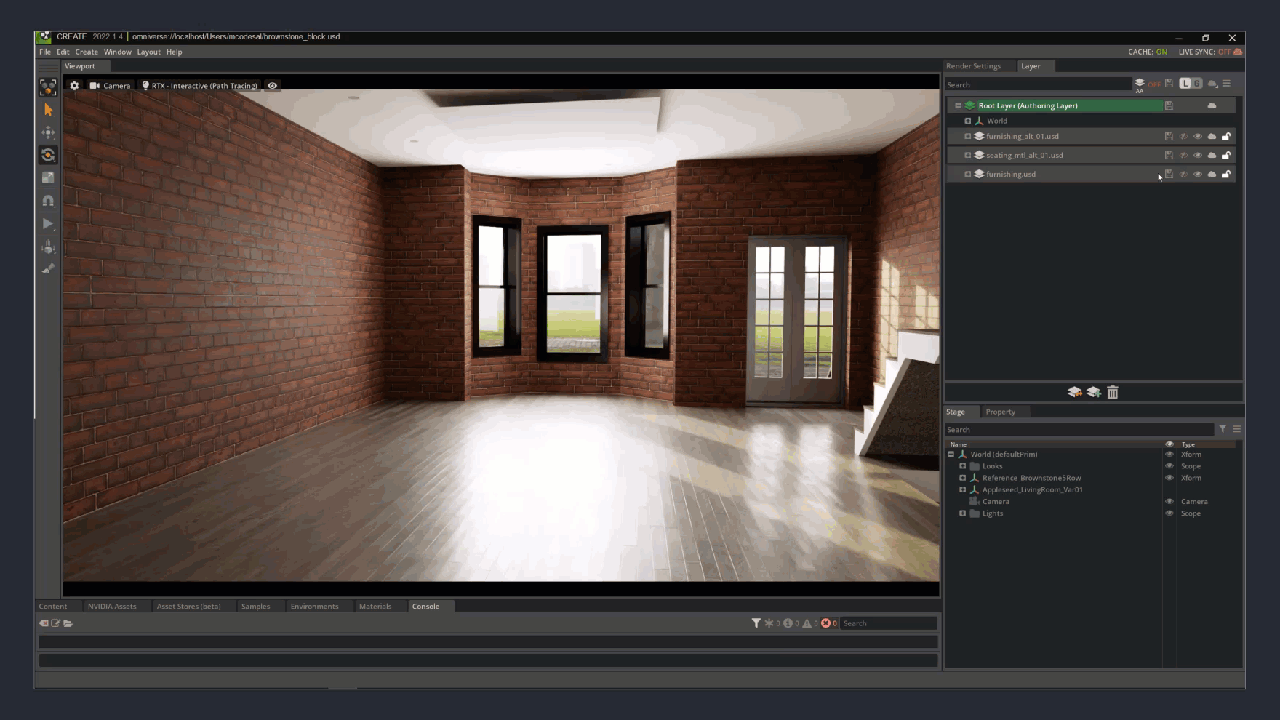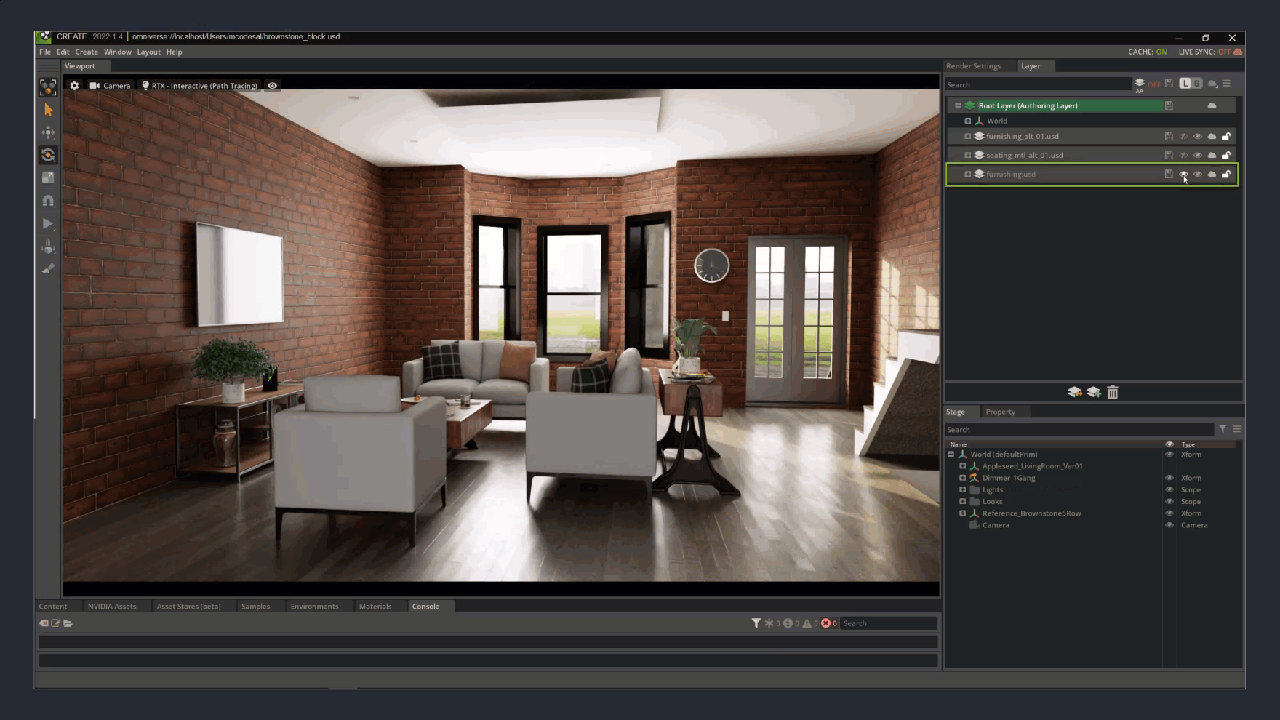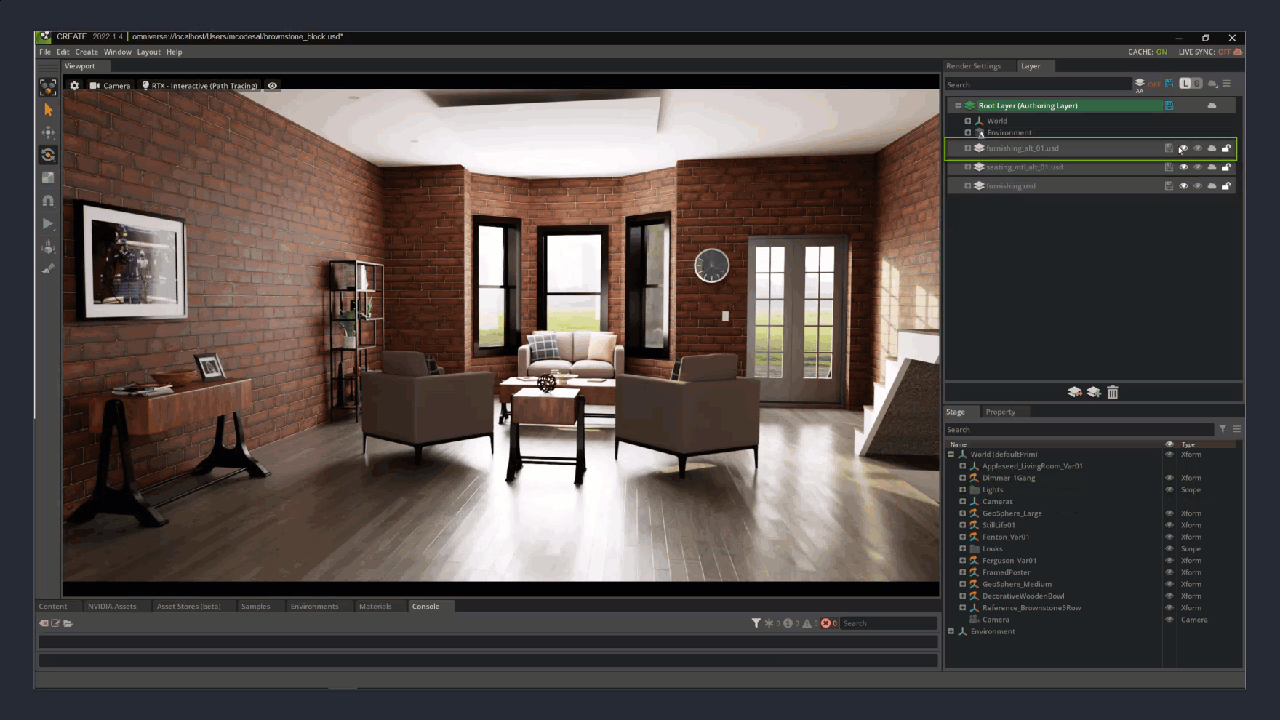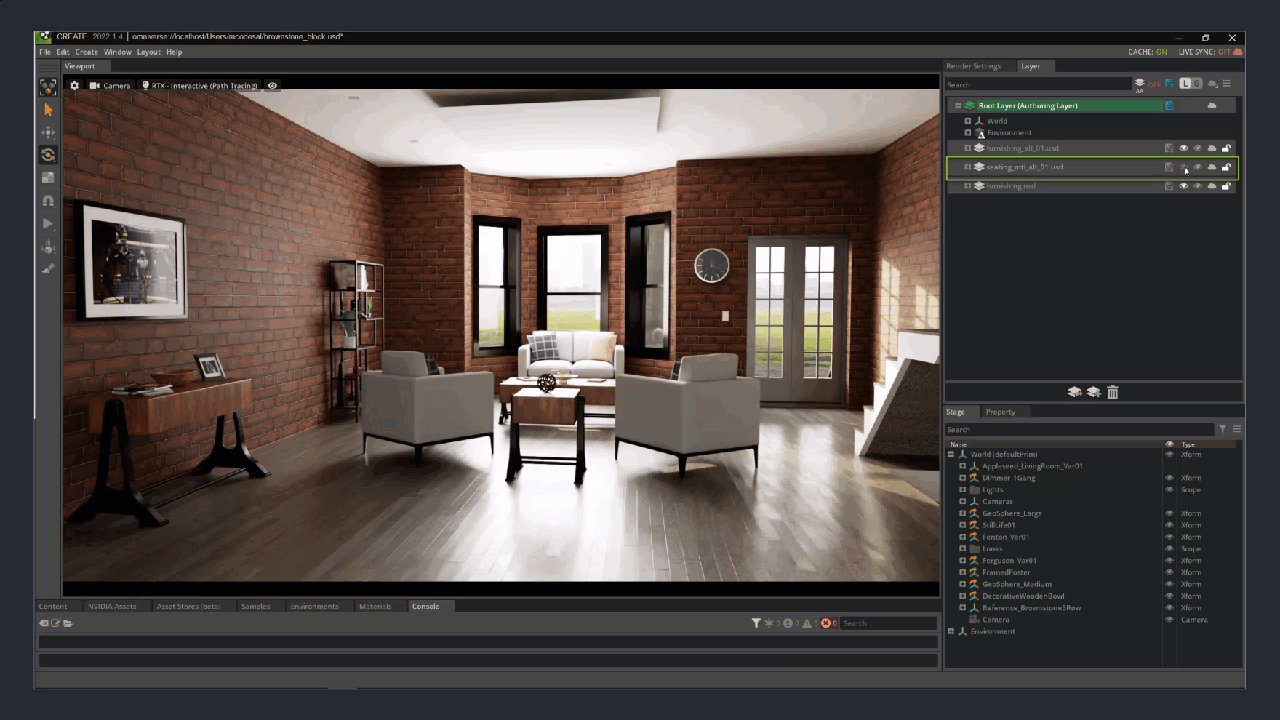
Figure 2. The layers of a Brownstone room interior created with USD: the empty room, the staged room, different seating material covers, and alternate furniture layouts and colors
NVIDIA believes that USD should serve as the HTML of the metaverse: the declarative specification of the contents of a web site. But just as HTML evolved from the limited static documents of HTML 1 to the dynamic applications of HTML 5, it is clear that USD will need to evolve to meet the needs of the metaverse. To accelerate this evolution, NVIDIA has already made a number of additions to the USD ecosystem:
Schema for rigid body dynamics simulation (with Pixar and Apple): Standardizing the representation of mass distribution, collision behavior, and other data necessary for rigid-body dynamics
In the short term, NVIDIA is developing:
glTF interoperability: A glTF file format plugin will allow glTF assets to be referenced directly by USD scenes. This means that users who are already using glTF can take advantage of the composition and collaboration features of USD without having to alter their existing assets.
Geospatial schema (WGS84): NVIDIA is developing a geospatial schema and runtime behavior in USD to support the WGS84 standard for geospatial coordinates. This will facilitate full-fidelity digital twin models that need to incorporate the curvature of the earth’s surface.
International character (UTF-8) support: NVIDIA is working with Pixar to add support for UTF-8 identifiers to USD, allowing for full interchange of content from all over the world.
USD compatibility testing and certification suite: To further accelerate USD development and adoption, NVIDIA is building an open source suite for USD compatibility testing and certification. Developers will be able to test their builds of USD and certify that their custom USD components produce an expected result.
In the longer term, NVIDIA is working with partners to fill some of the larger remaining gaps in USD:
High-speed incremental updates: USD was not designed for high-speed dynamic scene updates, but digital twin simulations will require this. NVIDIA is developing additional libraries on top of USD that enable much higher update rates to support real-time simulation.
Real-time proceduralism: USD as it currently exists is almost entirely declarative. Properties and values in the USD representation, for the most part, describe facts about the virtual world. NVIDIA has begun to augment this with a procedural graph-based execution engine called OmniGraph.
Compatibility with browsers: Today, USD is C++/Python based, but web browsers are not. To be accessible by everyone, everywhere, virtual worlds will need to be capable of running inside web browsers. NVIDIA will be working to ensure that proper WebAssembly builds with JavaScript bindings are available to make USD an attractive development option when running inside of a browser is the best approach.
Real-time streaming of IoT data: Industrial virtual worlds and live digital twins require real-time streaming of IoT data. NVIDIA is working on building USD connections to IoT data streaming protocols.
Companies across industrial and manufacturing—including Ericsson, Kroger, and Volvo—are adopting USD to enable their 3D virtual worlds and asset projects.
Get started building virtual worlds with USD
NVIDIA Omniverse is a scalable computing platform for full-design-fidelity 3D simulation workflows and a toolkit for building USD-based metaverse applications. Omniverse was built from the ground up as a USD engine and open toolkit for building custom, interoperable 3D pipelines.
You can access a wealth of USD resources from NVIDIA, available online for free. A good place to start is with NVIDIA’s hub of USD resources. To learn the basics of USD with examples in USDA and Python in a step-by-step web tutorial, sign up for the USD DLI course.
Experimenting with USD is easy with precompiled USD binaries. These Windows/Linux distributions will help you get started developing tools that take advantage of USD or start using USDView from Omniverse Launcher. For Python developers, the easiest way to start reading and writing USD layers is with the usd-core Python Package.
If you’re looking for USD sample data, numerous sample USD scenes are available, including a physics-based marbles mini-game sample and an attic scene with MDL materials rendered in Omniverse. In addition, USD SimReady Content includes component models from various industries prepared for simulation workflows.
Learn more in the Omniverse Resource Center, which details how developers can build custom USD-based applications and extensions for the platform.
Enter the NVIDIA #ExtendOmniverse contest with an extension created in Omniverse Code for a chance to win an NVIDIA RTX GPU. Join NVIDIA at SIGGRAPH 2022 to learn more about the latest Omniverse announcements and watch the Special Address on demand. And don’t miss the global premiere of the documentary, The Art of Collaboration: NVIDIA, Omniverse, and GTC on August 10 at 10 AM, Pacific time.
NVIDIA at SIGGRAPH 2022 today announced the full open sourcing of Material Definition Language (MDL)—including the MDL Distiller and GLSL backend…
NVIDIA at SIGGRAPH 2022 today announced the full open sourcing of Material Definition Language (MDL)—including the MDL Distiller and GLSL backend technologies—to further expand the MDL ecosystem.
Building the world’s most accurate and scalable models for material and rendering simulation is a continuous effort, requiring flexibility and adaptability. MDL is NVIDIA’s vision for renderer algorithm-agnostic material definitions for material exchange.
MDL unlocks material representations from current siloes, allowing them to traverse software ecosystems. It can be used to define complex, physically-accurate materials by reducing material complexity to boost performance.
Dynamic materials support
NVIDIA is open sourcing the MDL Distiller to enable best-in-class implementations of MDL support for all kinds of renderers. Built as a companion technology to the MDL SDK and language, the Distiller is a fully automated solution to simplify all MDL materials to a reduced material model of a simpler renderer. As a renderer developer, you can now provide respective MDL Distiller rules, rather than material artists providing simpler materials for simple renderers.
MDL can now be used to author one high-quality, single-truth material without the need to make compromises or variants for lesser-capable renderers. Approximations and simplifications are left to the software. Once a renderer improves the capabilities, for example, the MDL Distiller rules can be upgraded and the old materials improve without the need to re-author the content.
Workflow flexibility and efficiency
New open source GLSL backend technologies provide MDL support to renderer developers building on OpenGL or Vulkan, closing the gap to established graphics API standards. The MDL Distiller and GLSL backend will enable many more developers to leverage the power of MDL.
By unlocking material representations, artists have the freedom to work across ecosystems while maintaining material appearance. This means a material can be created once and then shared across multiple applications.
The ability to share physically-based materials between supporting applications, coupled with the flexibility of use in renderers and platforms like NVIDIA Omniverse, is a key advantage of MDL. This flexibility saves time and effort in many workflows and pipelines.
NVIDIA today announced a broad initiative to evolve Universal Scene Description (USD), the open-source and extensible language of 3D worlds, to become a foundation of the open metaverse and 3D internet.
NVIDIA today announced NeuralVDB, which brings the power of AI to OpenVDB, the industry-standard library for simulating and rendering sparse volumetric data, such as water, fire, smoke and clouds. Building on the past decade’s development of OpenVDB, the introduction at SIGGRAPH of NeuralVDB is a game-changer for professionals working in areas like scientific computing and Read article >




 Over the past few decades, the Internet has fundamentally changed the world and set in motion an enormous transformation in the way we consume and share…
Over the past few decades, the Internet has fundamentally changed the world and set in motion an enormous transformation in the way we consume and share…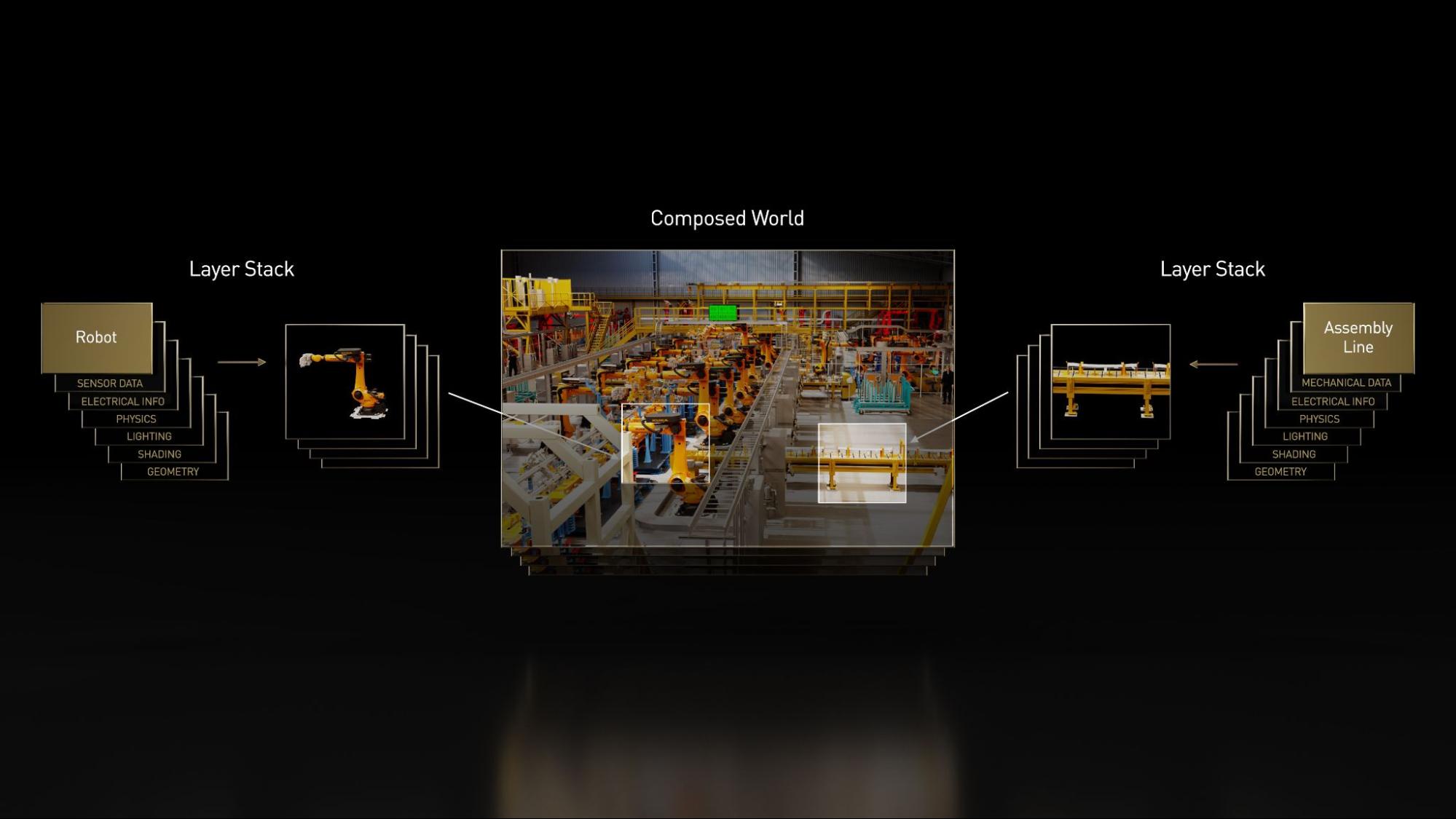
") NVIDIA at SIGGRAPH 2022 today announced the full open sourcing of Material Definition Language (MDL)—including the MDL Distiller and GLSL backend…
NVIDIA at SIGGRAPH 2022 today announced the full open sourcing of Material Definition Language (MDL)—including the MDL Distiller and GLSL backend…