A one-of-a-kind electric race car revved to life before it was manufactured — or even prototyped — thanks to GPU-powered extended reality technology. At the Automotive Innovation Forum in May, NVIDIA worked with Autodesk VRED to showcase a photorealistic Porsche electric sports car in augmented reality, with multiple attendees collaborating in the same immersive environment. Read article >
Learn how NVIDIA researchers use AI to design better arithmetic circuits that power our AI chips.
As Moore’s law slows down, it becomes increasingly important to develop other techniques that improve the performance of a chip at the same technology process node. Our approach uses AI to design smaller, faster, and more efficient circuits to deliver more performance with each chip generation.
Vast arrays of arithmetic circuits have powered NVIDIA GPUs to achieve unprecedented acceleration for AI, high-performance computing, and computer graphics. Thus, improving the design of these arithmetic circuits would be critical in improving the performance and efficiency of GPUs.
What if AI could learn to design these circuits? In PrefixRL: Optimization of Parallel Prefix Circuits using Deep Reinforcement Learning, we demonstrate that not only can AI learn to design these circuits from scratch, but AI-designed circuits are also smaller and faster than those designed by state-of-the-art electronic design automation (EDA) tools. The latest NVIDIA Hopper GPU architecture has nearly 13,000 instances of AI-designed circuits.
Figure 1. 64b adder circuits designed by PrefixRL AI (left) are up to 25% smaller than that designed by a state-of-the-art EDA tool (right) while being as fast and functionally equivalent
In Figure 1, the circuit corresponds to the (31.4µm², 0.186ns) point in the PrefixRL curve in Figure 5.
The circuit design game
Arithmetic circuits in computer chips are constructed using a network of logic gates (like NAND, NOR, and XOR) and wires. The desirable circuit should have the following characteristics:
Small: A lower area so that more circuits can fit on a chip.
Fast: A lower delay to improve the performance of the chip.
Consume less power: A lower power consumption of the chip.
In our paper, we focus on circuit area and delay. We find that power consumption is well-correlated with area for our circuits of interest. Circuit area and delay are often competing properties, so we want to find the Pareto frontier of designs that effectively trades off these properties. Put simply, we desire the minimum area circuit at every delay.
In PrefixRL, we focus on a popular class of arithmetic circuits called (parallel) prefix circuits. Various important circuits in the GPU such as adders, incrementors, and encoders are prefix circuits that can be defined at a higher level as prefix graphs.
In this work, we specifically ask the question: can an AI agent design good prefix graphs? The state-space of all prefix graphs is large O(2^n^n) and cannot be explored using brute force methods.
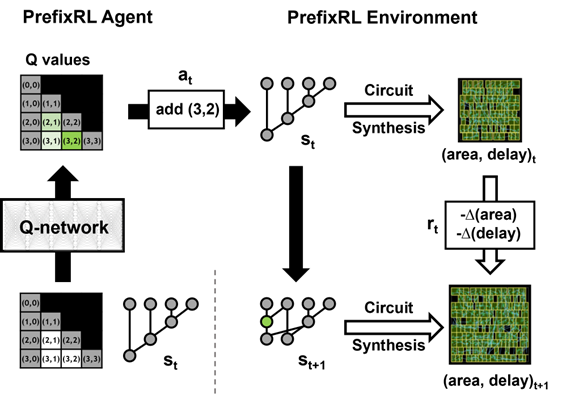
Figure 2. One iteration of PrefixRL with a 4b circuit example
A prefix graph is converted into a circuit with wires and logic gates using a circuit generator. These generated circuits are then further optimized by a physical synthesis tool using physical synthesis optimizations such as gate sizing, duplication, and buffer insertion.
The final circuit properties (delay, area, and power) do not directly translate from the original prefix graph properties, such as level and node count, due to these physical synthesis optimizations. This is why the AI agent learns to design prefix graphs but optimizes for the properties of the final circuit generated from the prefix graph.
We pose arithmetic circuit design as a reinforcement learning (RL) task, where we train an agent to optimize the area and delay properties of arithmetic circuits. For prefix circuits, we design an environment where the RL agent can add or remove a node from the prefix graph, after which the following steps happen:
The prefix graph is legalized to always maintain a correct prefix sum computation.
A circuit is generated from the legalized prefix graph.
The circuit undergoes physical synthesis optimizations using a physical synthesis tool.
The area and delay properties of the circuit are measured.
During an episode, the RL agent builds up the prefix graph step-by-step by adding or removing nodes. At each step, the agent receives the improvement in the corresponding circuit area and delay as rewards.
State and action representation and the deep reinforcement learning model
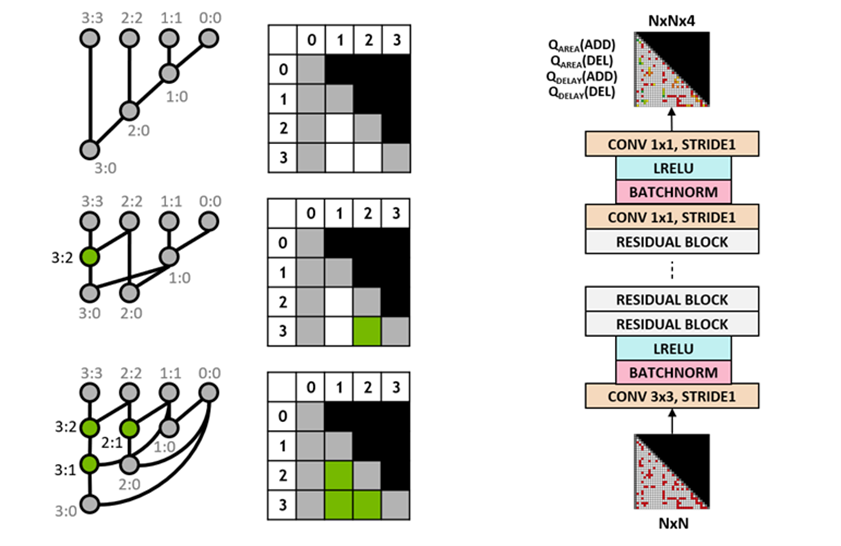
We use the Q-learning algorithm to train the circuit designer agent. We use a grid representation for prefix graphs where each element in the grid uniquely maps to a prefix node. This grid representation is used at both the input and output of the Q-network. Each element in the input grid represents whether a node is present or absent. Each element in the output grid represents the Q-values for adding or removing a node.
We use a fully convolutional neural network architecture for the agent as the input and output of the Q-learning agent are grid representations. The agent separately predicts the Q values for the area and delay properties because the rewards for area and delay are separately observable during training.
Figure 3. Representations of certain 4b prefix graphs (left) and fully convolutional Q-learning agent architecture (right)
Distributed training with Raptor
PrefixRL is a computationally demanding task: physical simulation required 256 CPUs for each GPU and training the 64b case took over 32,000 GPU hours.
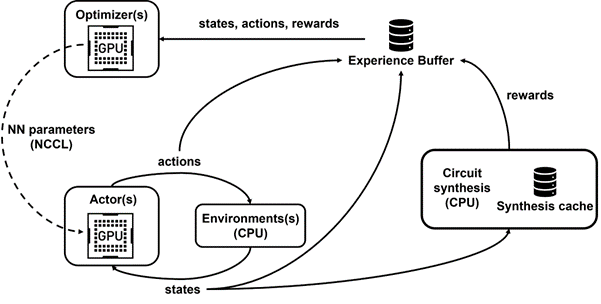
We developed Raptor, an in-house distributed reinforcement learning platform that takes special advantage of NVIDIA hardware for this kind of industrial reinforcement learning (Figure 4).
Raptor has several features that enhance scalability and training speed such as job scheduling, custom networking, and GPU-aware data structures. In the context of PrefixRL, Raptor makes the distribution of work across a mix of CPUs, GPUs, and Spot instances possible.
Networking in this reinforcement learning application is diverse and benefits from the following.
Raptor’s ability to switch between NCCL for point-to-point transfer to transfer model parameters directly from the learner GPU to an inference GPU.
Redis for asynchronous and smaller messages such as rewards or statistics.
A JIT-compiled RPC to handle high volume and low latency requests such as uploading experience data.
Finally, Raptor provides GPU-aware data structures such as a replay buffer that has a multithreaded server to receive experience from multiple workers, and batches data in parallel and prefetches it onto the GPU.
Figure 4 shows that our framework powers concurrent training and data collection, and takes advantage of NCCL to efficiently send actors the latest parameters.
Figure 4. We use Raptor for decoupled and parallelized training and reward calculation to overcome circuit synthesis latency
Reward computation
We use a tradeoff weight w from [0,1] to combine the area and delay objectives. We train various agents with various weights to obtain a Pareto frontier of designs that balance the tradeoff between area and delay.
The physical synthesis optimizations in the RL environment can generate various solutions to tradeoff between area and delay. We should drive the physical synthesis tool with the same tradeoff weight for which a particular agent is trained.
Performing physical synthesis optimizations in the loop for reward computation has several advantages.
The RL agent learns to directly optimize the final circuit properties for a target technology node and library.
The RL agent can optimize the properties of the target arithmetic circuit and its surrounding logic jointly by including the surrounding logic during physical synthesis.
However, performing physical synthesis is a slow process (~35 seconds for 64b adders), which can greatly slow RL training and exploration.
We decouple reward calculation from state update as the agent only needs the current prefix graph state to take actions, and not circuit synthesis nor previous rewards. Thanks to Raptor, we can offload the lengthy reward calculation onto a pool of CPU workers to perform physical synthesis in parallel, while actor agents step through the environment without needing to wait.
When rewards are returned by the CPU workers, the transitions can then be inserted into the replay buffer. Synthesis rewards are cached to avoid redundant computation whenever a state is reencountered.
Results
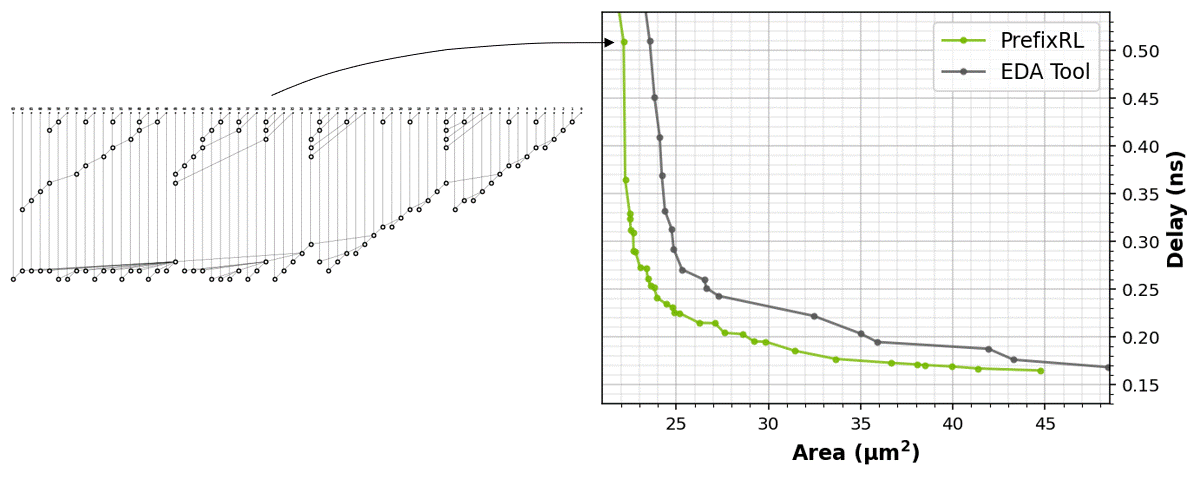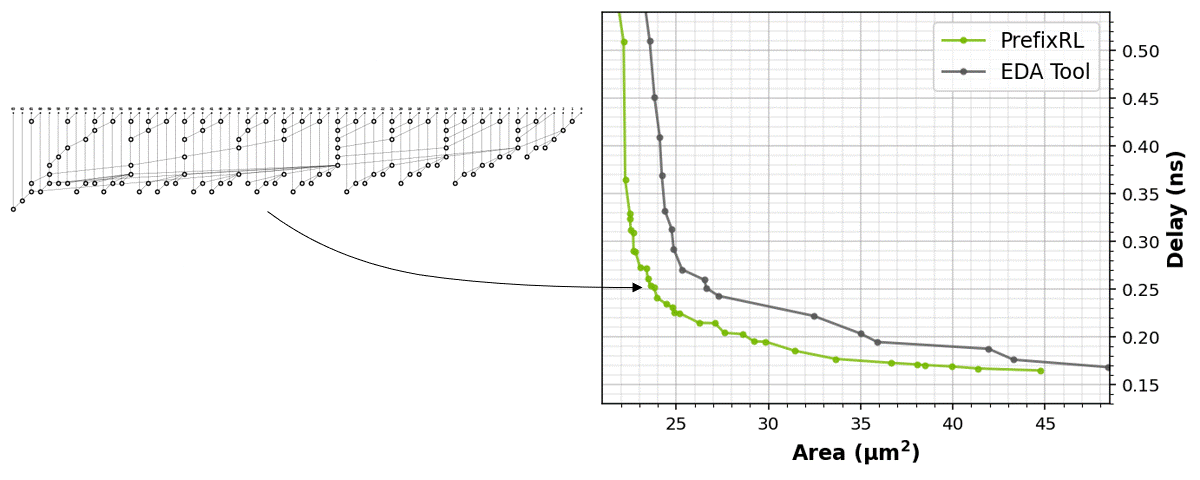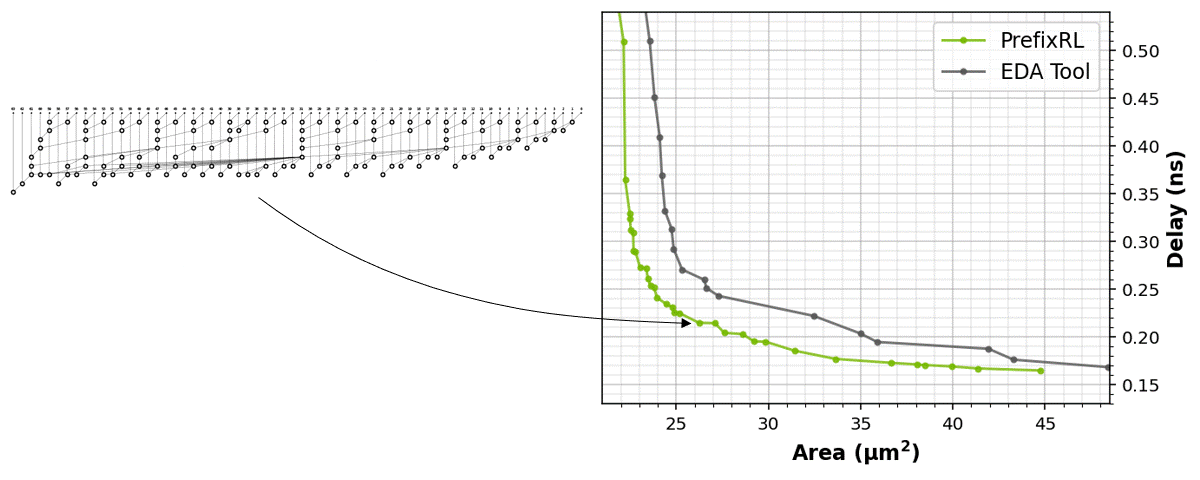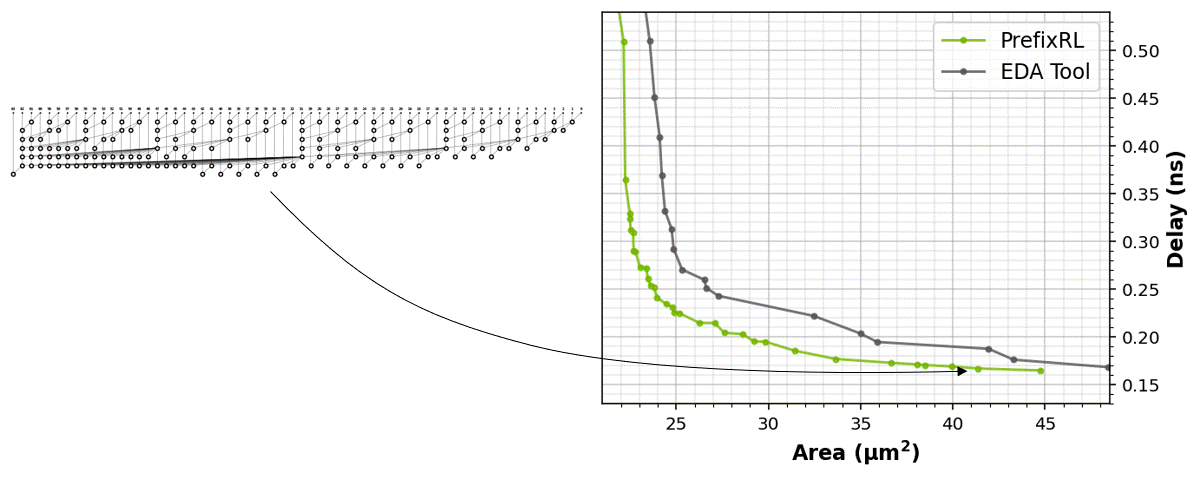
The RL agents learn to design circuits tabula rasa purely through learning with feedback from synthesized circuit properties. Figure 5 shows the latest results* that use 64b adder circuits designed by PrefixRL, Pareto-dominated adder circuits from a state-of-the-art EDA tool in area and delay.
The best PrefixRL adder achieved a 25% lower area than the EDA tool adder at the same delay. These prefix graphs that map to Pareto optimal adder circuits after physical synthesis optimizations have irregular structures.
Figure 5. PrefixRL designs arithmetic circuits that are smaller and faster than circuits designed by a state-of-the-art EDA tool. (left) The circuit architectures; (right) the corresponding 64b adder circuit properties plots
Conclusion
To the best of our knowledge, this is the first method using a deep reinforcement learning agent to design arithmetic circuits. We hope that this method can be a blueprint for applying AI to real-world circuit design problems: constructing action spaces, state representations, RL agent models, optimizing for multiple competing objectives, and overcoming slow reward computation processes such as physical synthesis.
NVIDIA’s latest corporate responsibility report shares our efforts in empowering employees and putting to work our technologies for the benefit of humanity. Amid ongoing global economic concerns and pandemic challenges, this year’s report highlights our ability to attract and retain talent that come here to do their life’s work while tackling some of the world’s Read article >
Posted by Been Kim, Research Scientist, Google Research, Brain Team, and Alison Lentz, Senior Staff Strategist, Google Research, Mural Team
Advances in computer vision and natural language processing continue to unlock new ways of exploring billions of images available on public and searchable websites. Today’s visual search tools make it possible to search with your camera, voice, text, images, or multiple modalities at the same time. However, it remains difficult to input subjective concepts, such as visual tones or moods, into current systems. For this reason, we have been working collaboratively with artists, photographers, and image researchers to explore how machine learning (ML) might enable people to use expressive queries as a way of visually exploring datasets.
Today, we are introducing Mood Board Search, a new ML-powered research tool that uses mood boards as a query over image collections. This enables people to define and evoke visual concepts on their own terms. Mood Board Search can be useful for subjective queries, such as “peaceful”, or for words and individual images that may not be specific enough to produce useful results in a standard search, such as “abstract details in overlooked scenes” or “vibrant color palette that feels part memory, part dream“. We developed, and will continue to develop, this research tool in alignment with our AI Principles.
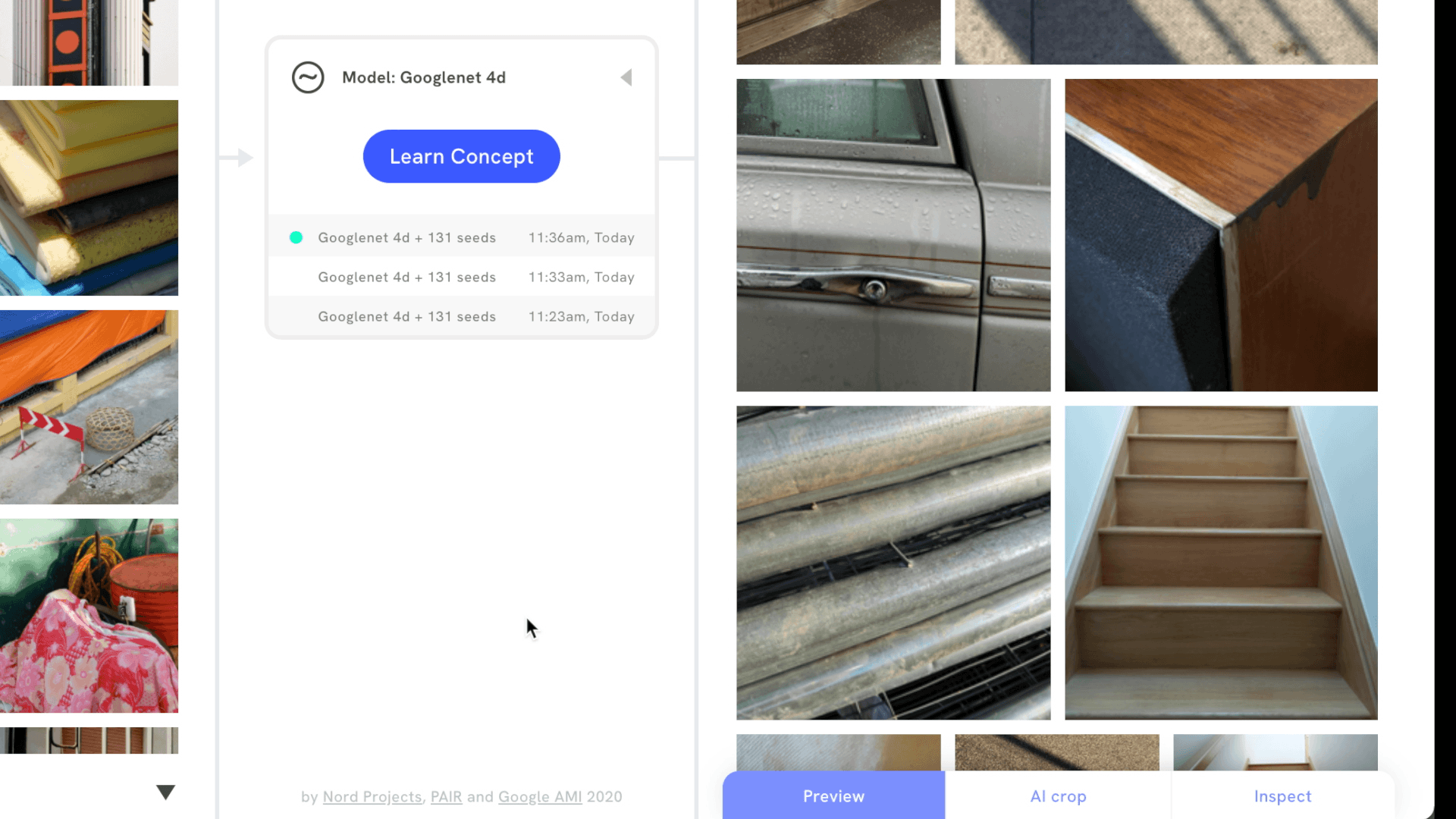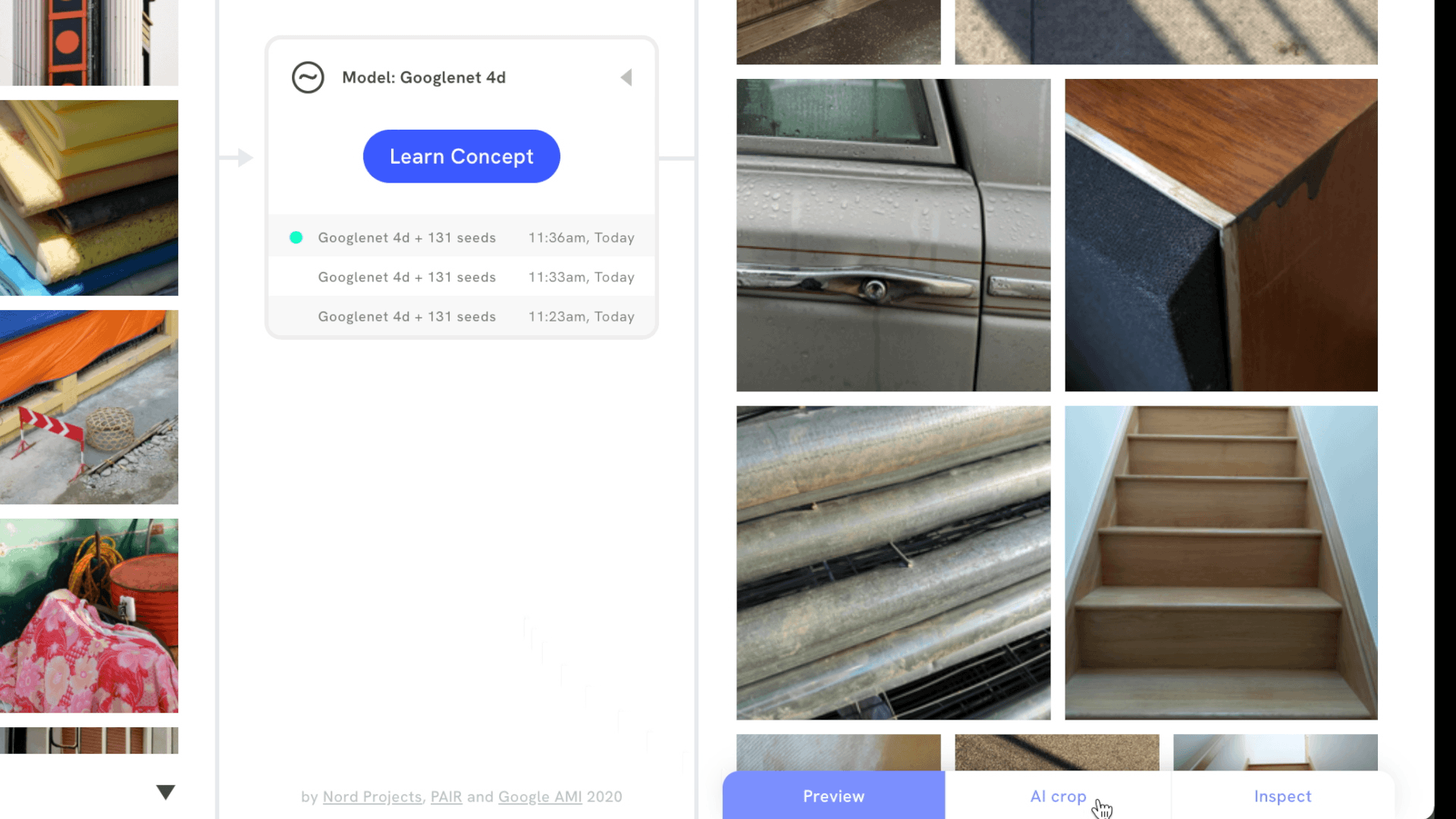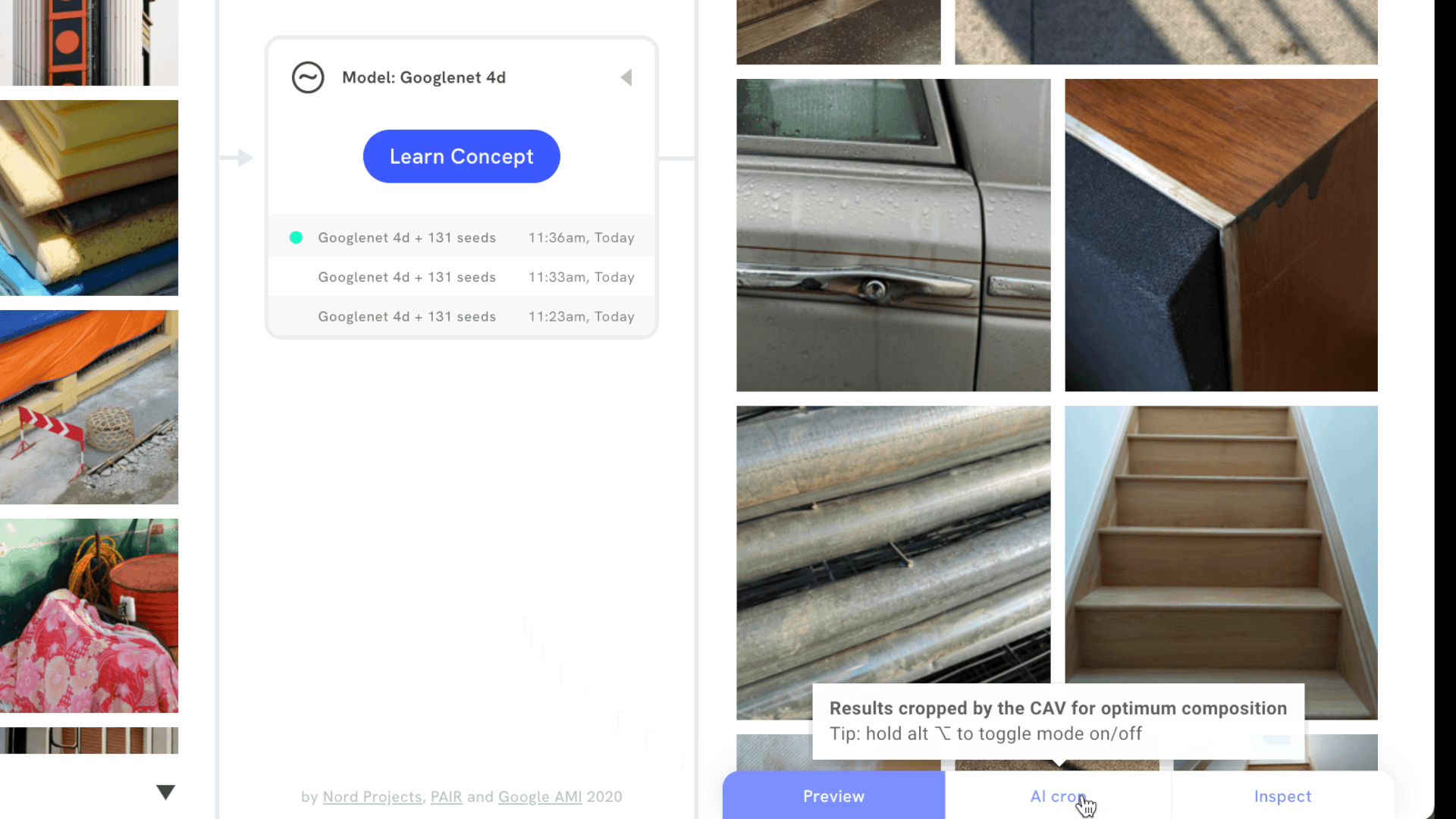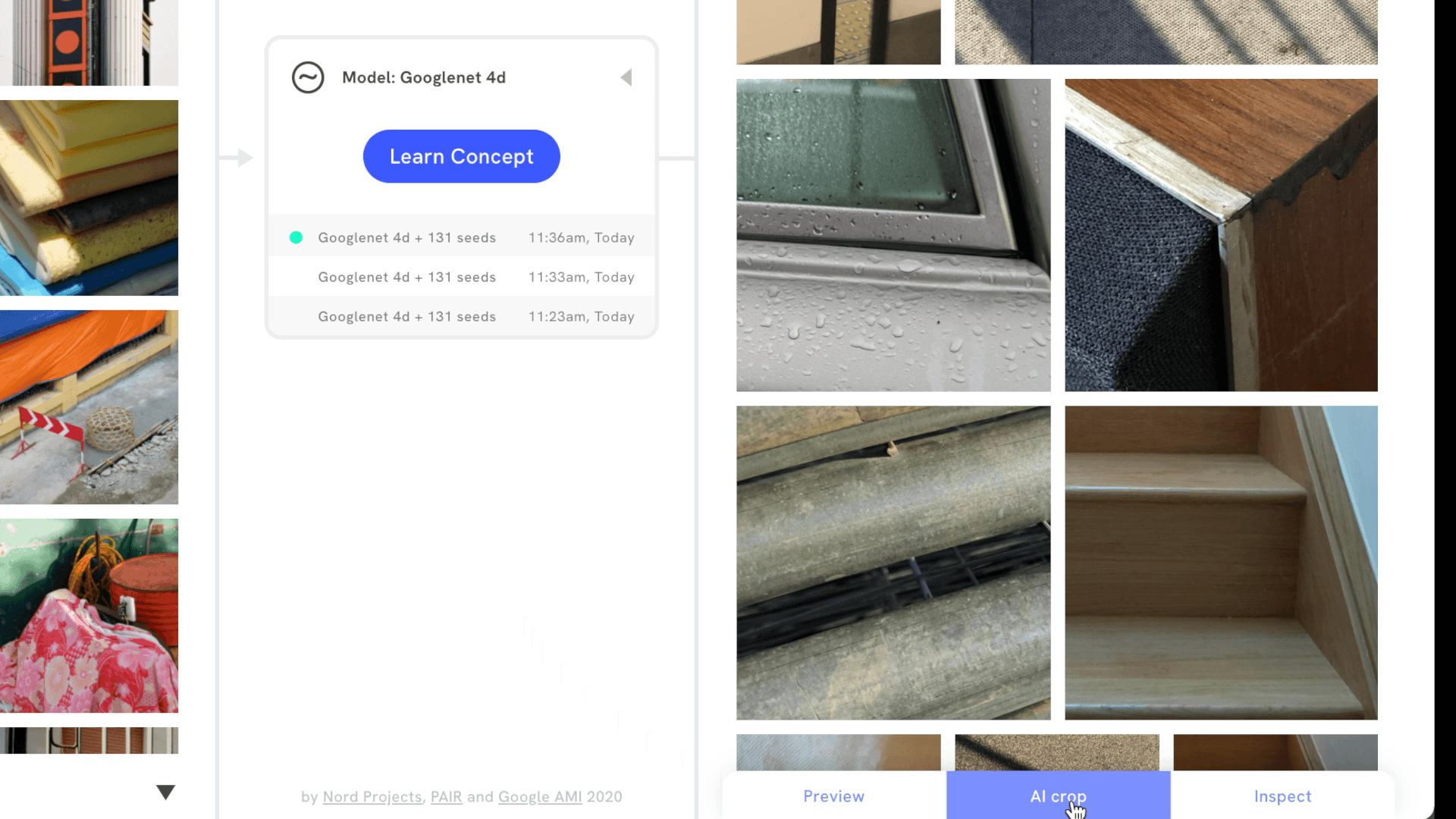
Search Using Mood Boards With Mood Board Search, our goal is to design a flexible and approachable interface so people without ML expertise can train a computer to recognize a visual concept as they see it. The tool interface is inspired by mood boards, commonly used by people in creative fields to communicate the “feel” of an idea using collections of visual materials.
With Mood Board Search, users can train a computer to recognize visual concepts in image collections.
To get started, simply drag and drop a small number of images that represent the idea you want to convey. Mood Board Search returns the best results when the images share a consistent visual quality, so results are more likely to be relevant with mood boards that share visual similarities in color, pattern, texture, or composition.
It’s also possible to signal which images are more important to a visual concept by upweighting or downweighting images, or by adding images that are the opposite of the concept. Then, users can review and inspect search results to understand which part of an image best matches the visual concept. Focus mode does this by revealing a bounding box around part of the image, while AI crop cuts in directly, making it easier to draw attention to new compositions.
Supported interactions, like AI crop, allow users to see which part of an image best matches their visual concept.
Powered by Concept Activation Vectors (CAVs) Mood Board Search takes advantage of pre-trained computer vision models, such as GoogLeNet and MobileNet, and a machine learning approach called Concept Activation Vectors (CAVs).
CAVs are a way for machines to represent images (what we understand) using numbers or directions in a neural net’s embedding space (which can be thought of as what machines understand). CAVs can be used as part of a technique, Testing with CAVs (TCAV), to quantify the degree to which a user-defined concept is important to a classification result; e.g., how sensitive a prediction of “zebra” is to the presence of stripes. This is a research approach we open-sourced in 2018, and the work has since been widely applied to medical applications and science to build ML applications that can provide better explanations for what machines see. You can learn more about embedding vectors in general in this Google AI blog post, and our approach to working with TCAVs in Been Kim’s Keynote at ICLR.
In Mood Board Search, we use CAVs to find a model’s sensitivity to a mood board created by the user. In other words, each mood board creates a CAV — a direction in embedding space — and the tool searches an image dataset, surfacing images that are the closest match to the CAV. However, the tool takes it one step further, by segmenting each image in the dataset in 15 different ways, to uncover as many relevant compositions as possible. This is the approach behind features like Focus mode and AI crop.
Three artists created visual concepts to share their way of seeing, shown here in an experimental app by design invention studio, Nord Projects.
Because embedding vectors can be learned and re-used across models, tools like Mood Board Search can help us express our perspective to other people. Early collaborations with creative communities have shown value in being able to create and share subjective experiences with others, resulting in feelings of being able to “break out of visually-similar echo chambers” or “see the world through another person’s eyes”. Even misalignment between model and human understanding of a concept frequently resulted in unexpected and inspiring connections for collaborators. Taken together, these findings point towards new ways of designing collaborative ML systems that embrace personal and collective subjectivity.
Conclusions and Future Work Today, we’re open-sourcing the code to Mood Board Search, including three visual concepts made by our collaborators, and a Mood Board Search Python Library for people to tap the power of CAVs directly into their own websites and apps. While these tools are early-stage prototypes, we believe this capability can have a wide-range of applications from exploring unorganized image collections to externalizing ways of seeing into collaborative and shareable artifacts. Already, an experimental app by design invention studio Nord Projects, made using Mood Board Search, investigates the opportunities for running CAVs in camera, in real-time. In future work, we plan to use Mood Board Search to learn about new forms of human-machine collaboration and expand ML models and inputs — like text and audio — to allow even deeper subjective discoveries, regardless of medium.
Acknowledgments This blog presents research by (in alphabetical order): Kira Awadalla, Been Kim, Eva Kozanecka, Alison Lentz, Alice Moloney, Emily Reif, and Oliver Siy, in collaboration with design invention studio Nord Projects. We thank our co-author, Eva Kozanecka, our artist collaborators, Alexander Etchells, Tom Hatton, Rachel Maggart, the Imaging team at The British Library for their participation in beta previews, and Blaise Agüera y Arcas, Jess Holbrook, Fernanda Viegas, and Martin Wattenberg for their support of this research project.
Want to learn about AI and machine learning? There are plenty of resources out there to help — blogs, podcasts, YouTube tutorials — perhaps too many. Machine learning engineer Santiago Valderrama has taken a far more focused approach to helping us all get smarter about the field. He’s created a following by posing one machine Read article >
Nothing beats the summer heat like GFN Thursday. Get ready for four new titles streaming at GeForce quality across nearly any device. Buckle up for some great gaming, whether poolside, in the car for a long road trip, or in the air-conditioned comfort of home. Speaking of summer, it’s also last call for this year’s Read article >
Posted by Yundi Qian, Software Engineer, Google Research and Mircea Trofin, Software Engineer, Google Core
The question of how to compile faster and smaller code arose together with the birth of modem computers. Better code optimization can significantly reduce the operational cost of large datacenter applications. The size of compiled code matters the most to mobile and embedded systems or software deployed on secure boot partitions, where the compiled binary must fit in tight code size budgets. With advances in the field, the headroom has been heavily squeezed with increasingly complicated heuristics, impeding maintenance and further improvements.
Recent research has shown that machine learning (ML) can unlock more opportunities in compiler optimization by replacing complicated heuristics with ML policies. However, adopting ML in general-purpose, industry-strength compilers remains a challenge.
To address this, we introduce “MLGO: a Machine Learning Guided Compiler Optimizations Framework”, the first industrial-grade general framework for integrating ML techniques systematically in LLVM (an open-source industrial compiler infrastructure that is ubiquitous for building mission-critical, high-performance software). MLGO uses reinforcement learning (RL) to train neural networks to make decisions that can replace heuristics in LLVM. We describe two MLGO optimizations for LLVM: 1) reducing code size with inlining; and 2) improving code performance with register allocation (regalloc). Both optimizations are available in the LLVM repository, and have been deployed in production.
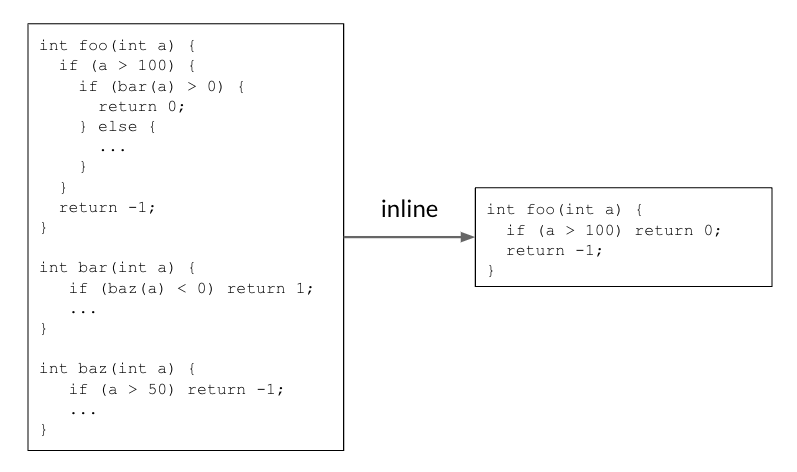
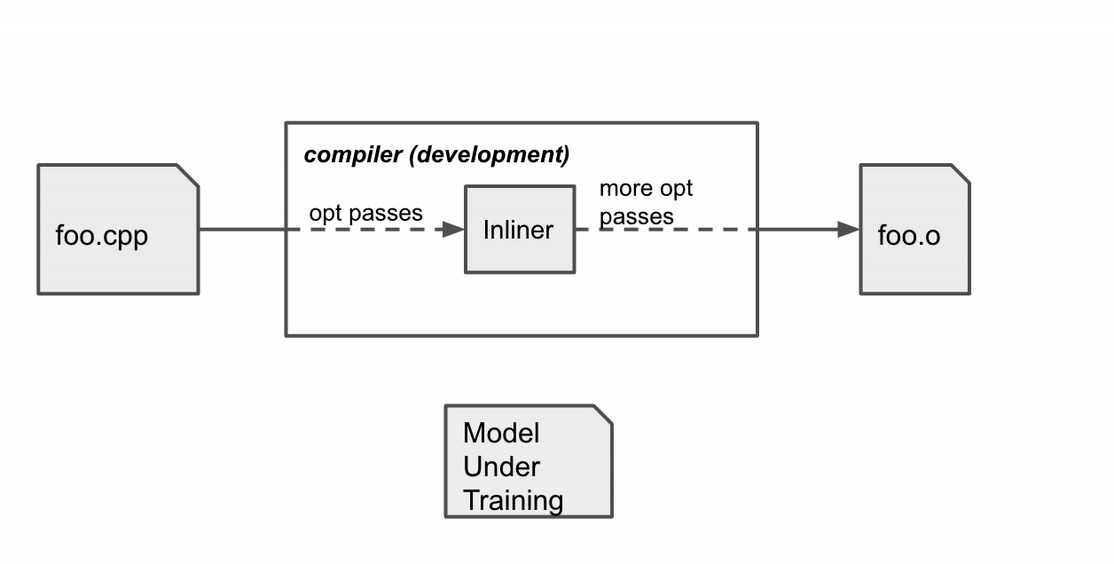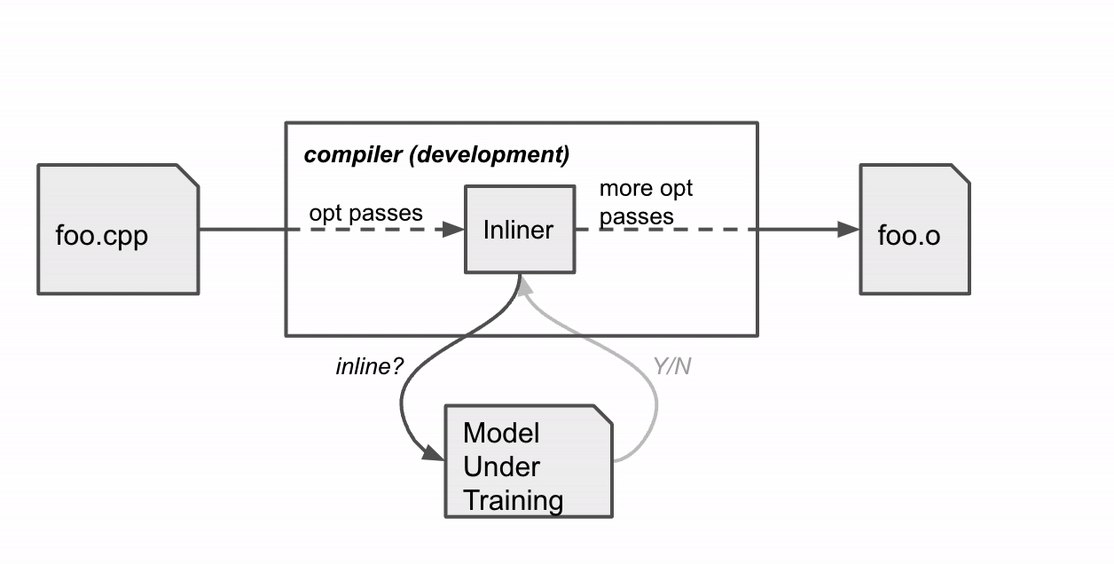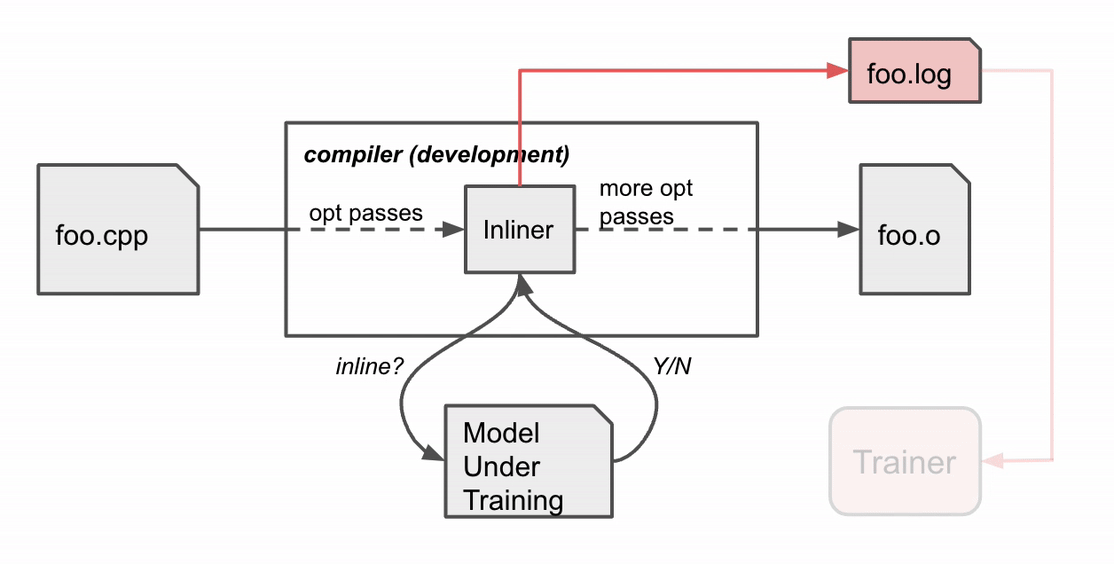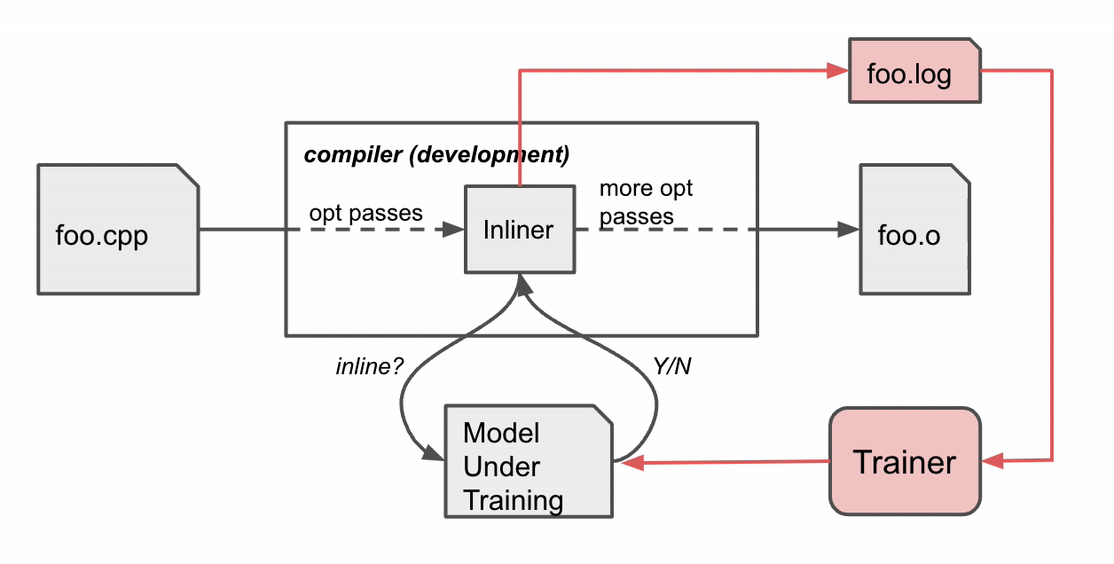
How Does MLGO Work? With Inlining-for-Size As a Case Study Inlining helps reduce code size by making decisions that enable the removal of redundant code. In the example below, the caller function foo() calls the callee function bar(), which itself calls baz(). Inlining both callsites returns a simple foo() function that reduces the code size.
Inlining reduces code size by removing redundant code.
In real code, there are thousands of functions calling each other, and thus comprise a call graph. During the inlining phase, the compiler traverses over the call graph on all caller-callee pairs, and makes decisions on whether to inline a caller-callee pair or not. It is a sequential decision process as previous inlining decisions will alter the call graph, affecting later decisions and the final result. In the example above, the call graph foo() → bar() → baz() needs a “yes” decision on both edges to make the code size reduction happen.
Before MLGO, the inline / no-inline decision was made by a heuristic that, over time, became increasingly difficult to improve. MLGO substitutes the heuristic with an ML model. During the call graph traversal, the compiler seeks advice from a neural network on whether to inline a particular caller-callee pair by feeding in relevant features (i.e., inputs) from the graph, and executes the decisions sequentially until the whole call graph is traversed.
Illustration of MLGO during inlining. “#bbs”, “#users”, and “callsite height” are example caller-callee pair features.
MLGO trains the decision network (policy) with RL using policy gradient and evolution strategies algorithms. While there is no ground truth about best decisions, online RL iterates between training and running compilation with the trained policy to collect data and improve the policy. In particular, given the current model under training, the compiler consults the model for inline / no-inline decision making during the inlining stage. After the compilation finishes, it produces a log of the sequential decision process (state, action, reward). The log is then passed to the trainer to update the model. This process repeats until we obtain a satisfactory model.
Compiler behavior during training. The compiler compiles the source code foo.cpp to an object file foo.o with a sequence of optimization passes, one of which is the inline pass.
The trained policy is then embedded into the compiler to provide inline / no-inline decisions during compilation. Unlike the training scenario, the policy does not produce a log. The TensorFlow model is embedded with XLA AOT, which converts the model into executable code. This avoids TensorFlow runtime dependency and overhead, minimizing the extra time and memory cost introduced by ML model inference at compilation time.
Compiler behavior in production.
We trained the inlining-for-size policy on a large internal software package containing 30k modules. The trained policy is generalizable when applied to compile other software and achieves a 3% ~ 7% size reduction. In addition to the generalizability across software, generalizability across time is also important — both the software and compiler are under active development so the trained policy needs to retain good performance for a reasonable time. We evaluated the model’s performance on the same set of software three months later and found only slight degradation.
Inlining-for-size policy size reduction percentages. The x-axis presents different software and the y-axis represents the percentage size reduction. “Training” is the software on which the model was trained and “Infra[1|2|3]” are different internal software packages.
The MLGO inlining-for-size training has been deployed on Fuchsia — a general purpose open source operating system designed to power a diverse ecosystem of hardware and software, where binary size is critical. Here, MLGO showed a 6.3% size reduction for C++ translation units.
Register-Allocation (for performance) As a general framework, we used MLGO to improve the register allocation pass, which improves the code performance in LLVM. Register Allocation solves the problem of assigning physical registers to live ranges (i.e., variables).
As the code executes, different live ranges are completed at different times, freeing up registers for use by subsequent processing stages. In the example below, each “add” and “multiply” instruction requires all operands and the result to be in physical registers. The live range x is allocated to the green register and is completed before either live ranges in the blue or yellow registers. After x is completed, the green register becomes available and is assigned to live range t.
Register allocation example.
When it’s time to allocate live range q, there are no available registers, so the register allocation pass must decide which (if any) live range can be “evicted” from its register to make room for q. This is referred to as the “live range eviction” problem, and is the decision for which we train the model to replace original heuristics. In this particular example, it evicts z from the yellow register, and assigns it to q and the first half of z.
We now consider the unassigned second half of live range z. We have a conflict again, and this time the live range t is evicted and split, and the first half of t and the final part of z end up using the green register. The middle part of z corresponds to the instruction q = t * y, where z is not being used, so it is not assigned to any register and its value is stored in the stack from the yellow register, which later gets reloaded to the green register. The same happens to t. This adds extra load/store instructions to the code and degrades performance. The goal of the register allocation algorithm is to reduce such inefficiencies as much as possible. This is used as the reward to guide RL policy training.
Similar to the inlining-for-size policy, the register allocation (regalloc-for-performance) policy is trained on a large Google internal software package, and is generalizable across different software, with 0.3% ~1.5% improvements in queries per second (QPS) on a set of internal large-scale datacenter applications. The QPS improvement has persisted for months after its deployment, showing the model’s generalizability across the time horizon.
Conclusion and Future Work We propose MLGO, a framework for integrating ML techniques systematically in an industrial compiler, LLVM. MLGO is a general framework that can be expanded to be: 1) deeper, e.g., adding more features, and applying better RL algorithms; and 2) broader, by applying it to more optimization heuristics beyond inlining and regalloc. We are enthusiastic about the possibilities MLGO can bring to the compiler optimization domain and look forward to its further adoption and to future contributions from the research community.
Try it Yourself Check out the open-sourced end-to-end data collection and training solution on github and a demo that uses policy gradient to train an inlining-for-size policy.
Acknowledgements We’d like to thank MLGO’s contributors and collaborators Eugene Brevdo, Jacob Hegna, Gaurav Jain, David Li, Zinan Lin, Kshiteej Mahajan, Jack Morris, Girish Mururu, Jin Xin Ng, Robert Ormandi, Easwaran Raman, Ondrej Sykora, Maruf Zaber, Weiye Zhao. We would also like to thank Petr Hosek, Yuqian Li, Roland McGrath, Haowei Wu for trusting us and deploying MLGO in Fuchsia as MLGO’s very first customer; thank David Blaikie, Eric Christopher, Brooks Moses, Jordan Rupprecht for helping to deploy MLGO in Google internal large-scale datacenter applications; and thank Ed Chi, Tipp Moseley for their leadership support.
Learn how developers used pretrained machine learning models and the Jetson Nano 2GB to create Mariola, a robot that can mimic human actions, from arm and head movements to making faces.
They say “imitation is the sincerest form of flattery.” Well, in the case of a robotics project by Polish-based developer Tomasz Tomanek, imitation—or mimicry—is the goal of his robot named Mariola.
In this latest Jetson Project of the Month, Tomanek has developed a funky little robot using pretrained machine learning models to make human-robot interactions come to life. The main controller for this robot is the Jetson Nano 2GB.
The use of PoseNet models make it possible for Mariola to recognize the posture and movements of a person, and then use those models to make the robot mimic or replicate those human actions. As Tomanek notes, “the use of the Jetson Nano makes it quite simple and straightforward to achieve this goal.”
An overview about Mariola is available in this YouTube video from the developer:
Video 1. Mariola with Jetson Nano
As you can see, Mariola is able to drive on wheels, move its arms, turn its head, and make faces. Separate Arduino controllers embedded in each section of the robot’s body enable those actions. Separate controllers for servo motors control the movement of the arms and head. The robot has four mecanum wheels so that it can move omnidirectionally.
Mariola’s facial expressions use a separate microcontroller built from NeoPixel LEDs, a set of two for each eye and a set of eight for the mouth. Daisy-chained together, they are driven by a separate Arduino nano board that manages color changes and the appearance of blinking eyes.
According to Tomanek, one key idea of the Mariola build was to make each subsystem a separate unit and let them communicate through an internal bus. There is a UART/BT receiver Arduino nano, and its role is to get the command from the user and decode to which subcontroller it needs to go and send it through CAN BUS.
Each subcontroller gets its commands from CAN BUS and creates the corresponding action for the wheels, the servos (hands and head moves), or the face (NeoPixels).
Tomanek notes in the NVIDIA Developer Forum that the Jetson Nano at the back of the robot is the brain running a customized Python script with the resnet18-body that returns the planar coordinates of a person’s joints when it detects them. Those coordinates are recalculated through an IK model to get the servo’s positions, and the results are sent to the master Arduino through UART. The Arduinos do the rest of the movement.
Currently, Mariola will detect and then mimic the movement of one person at a time. If no one is visible to the robot, or if more than one person is detected, no action occurs.
Why did Tomanek choose a Jetson Nano for this project? As he notes, “the potential power of the pretrained model available for the Jetson, along with the affordability [of the Jetson Nano], brought me to use the 2GB version to learn and see how it works.”
“This is a work in progress and learning project for me,” Tomanek notes. While there is no stated goal to Mariola, he sees it as an opportunity to experiment and learn what can be achieved by using this technology. “The best outcome so far is that with those behaviors driven by the machine learning model, there is a certain kind of autonomy for this small robot.”
When people interact with Mariola for the first time, Tomanek says “it always generates smiles. This is a very interesting aspect of human-robot interactions.” It’s easy to see why that would happen. Just watch Mariola in action–we dare you not to smile:
Video 2. Robotic project demo with Arduino and Jetson Nano
The Mariola project continues in active development, and is modified and updated on a regular basis. As Tomanek concludes in his overview video,“We’ll see what the future will bring.”
More details about the project are available in this GitHub repository.
Learn how you can prepost process your NVIDIA Modulus simulations using the Modulus Omniverse extension.
NVIDIA Modulus is a physics-machine learning platform that blends the power of physics with data to build high-fidelity, parameterized AI surrogate models that serve as digital twins to simulate with near real-time latency.
This cutting-edge framework is expanding its interactive simulation capabilities by integrating with the NVIDIA Omniverse (OV) platform for real-time virtual-world simulation and full-design fidelity visualization.
Previously, you would need to set up the visualization pipeline, a key component of simulation and analysis workflows, on your own. Now, you can use the built-in pipeline in Omniverse for common output scenarios such as visualizing streamlines and iso-surfaces for the outputs of the Modulus-trained AI model. Another key feature is being able to visualize and analyze the high-fidelity simulation output in near real time as you vary design parameters.
The three key advantages of adding the Modulus-OV extension:
This built-in visualization pipeline supports a small number of commonly used modalities such as streamlines, Scalar field slice, and Flow.
There is a near real-time simulation output for making design parameter changes and visualizing it on screen.
The rich ecosystem in Omniverse is now compatible for you to integrate with other extensions such as CAD tools, visualization tools for an end-to-end design, and simulation workflows.
The Modulus extension is available with Omniverse Create. After you install Omniverse Create on a supported OS using Omniverse Launcher, install the Modulus extension. Then go into the extension window and search for ‘Modulus’. This will bring up the core extension to install and enable the Modulus extension.
Figure 1: Enabling the Modulus extension in Omniverse Create
For this preview release, Modulus extension is supported only on the Linux platform and the GPU Memory requirements for running both Omniverse Create and Modulus can be quite high. For existing scenarios, we have observed minimum GPU requirements of an NVIDIA RTX 3090 or higher.
Visualizing an interactive simulation
Simulation scenarios are prepackaged examples that help users get familiar with the capabilities of the extension.
For now, the following preconfigured scenarios are available to experiment with: modulus_scenario_fpga
Load this scenario extension by searching for its name in the extension manager (in the following, we will use modulus_scenario_fpga). Install and enable the extension. If you do this for the first time, this process can take a few minutes for the pretrained model to be downloaded and installed on your machine.
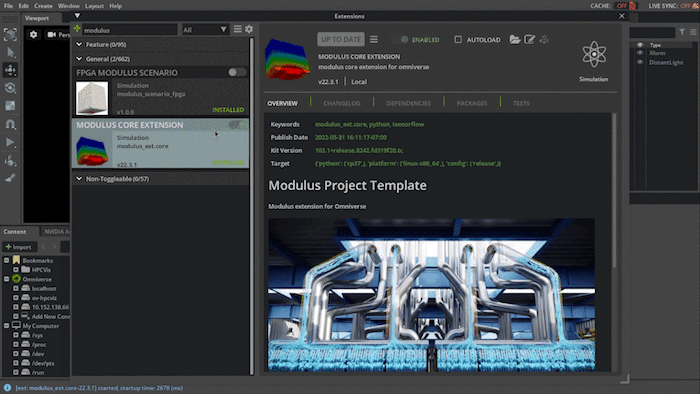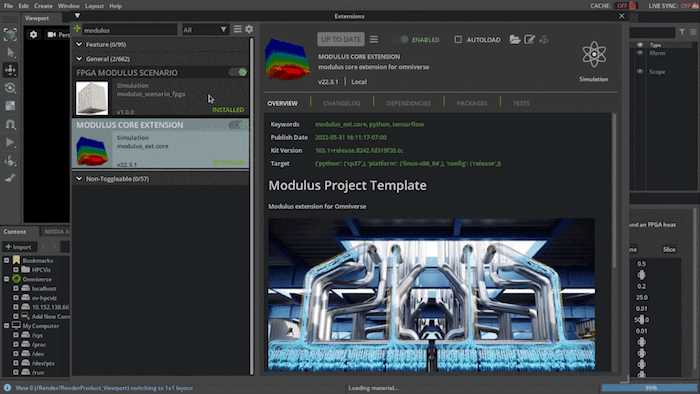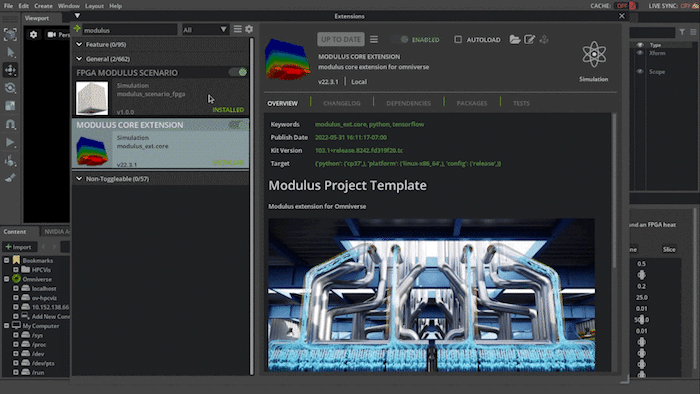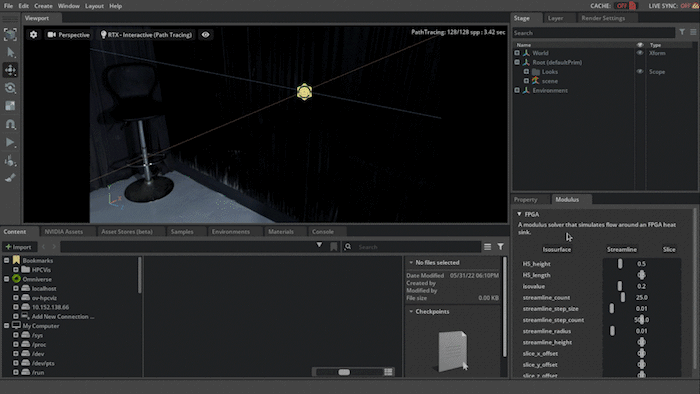
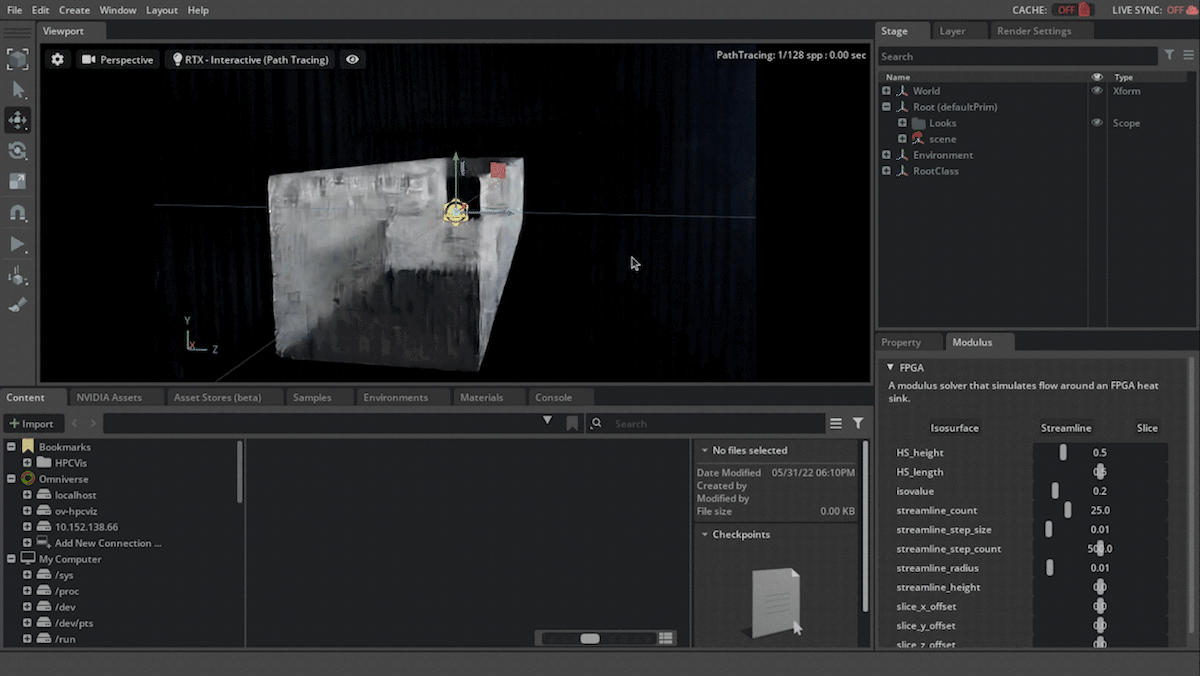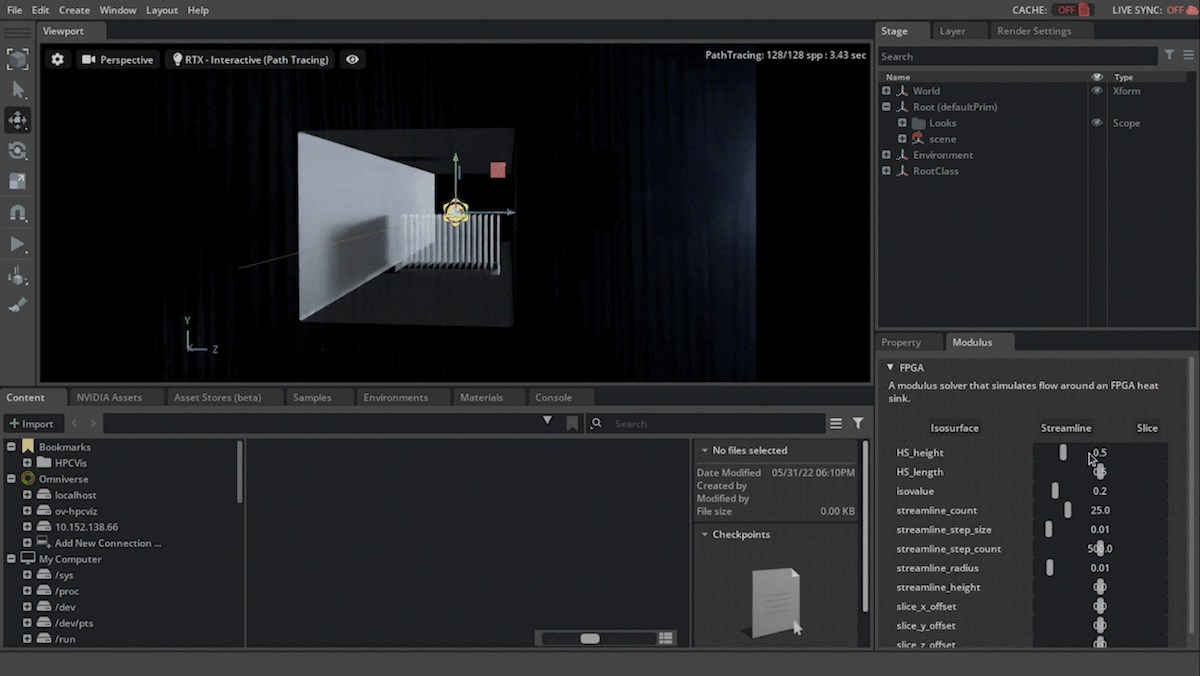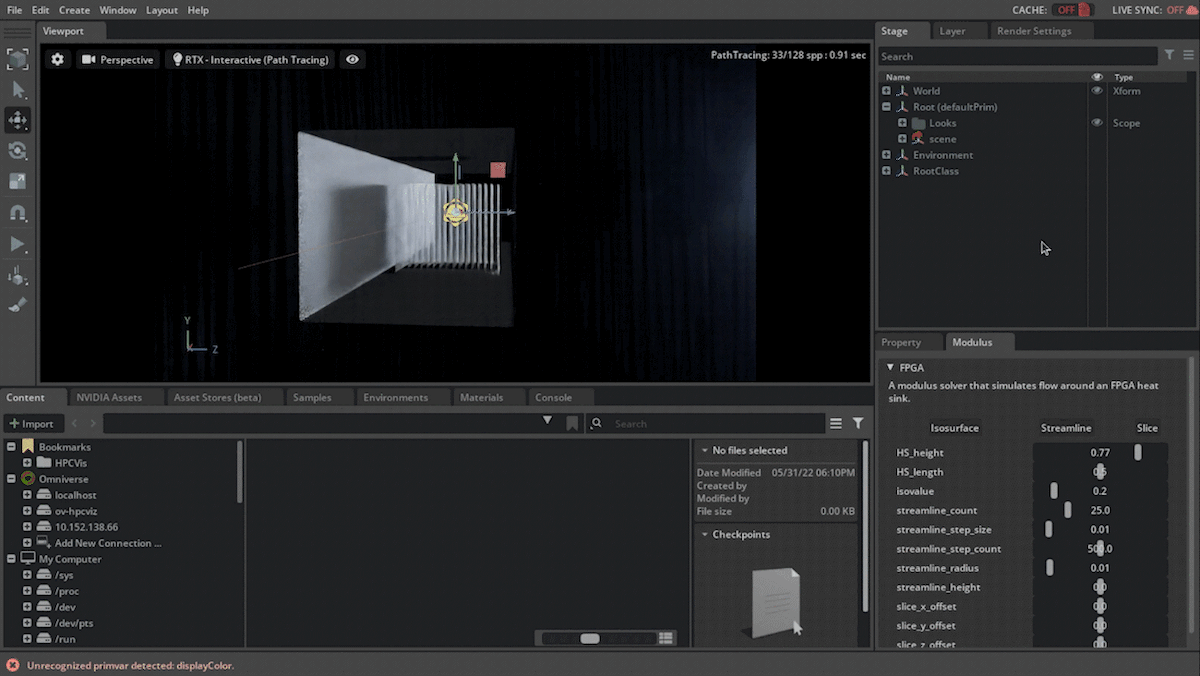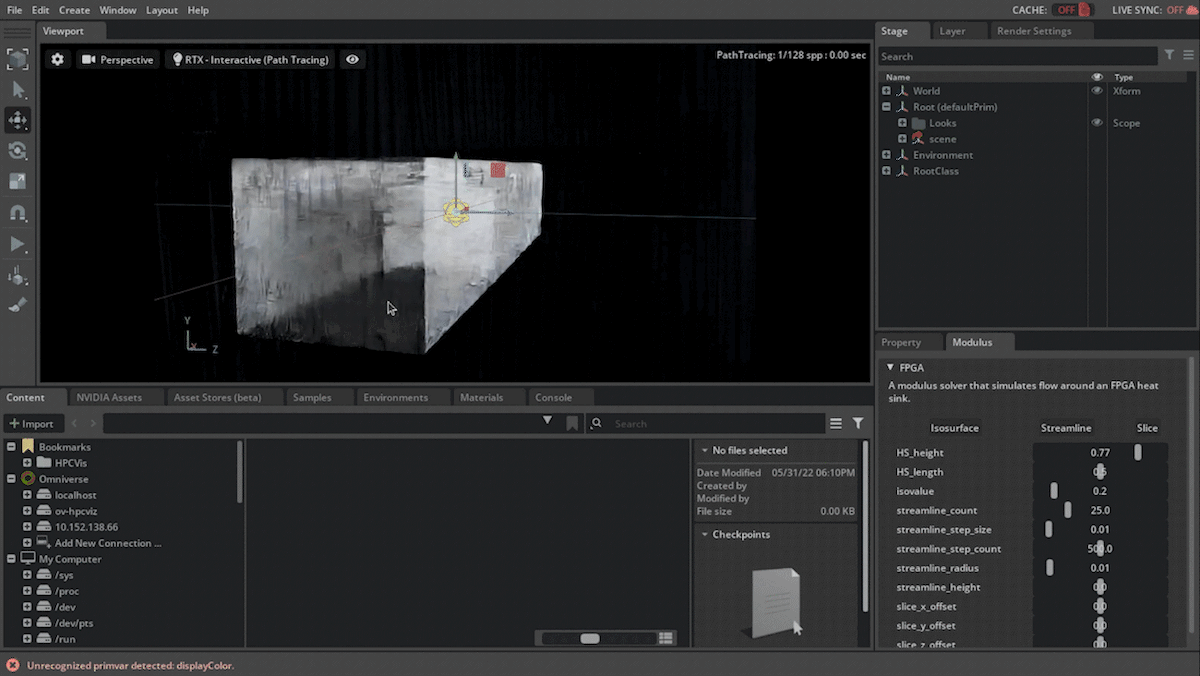
This scenario is based on the parameterized 3D heat sink example in Modulus, which, with the OV extension enabled you can visualize the airflow through the field-programmable gate array (FPGA) geometry.
In this scenario, the Modulus-trained parameterized neural network model is simulating airflow paths. The inference output data being used is the velocity magnitude, which is the airspeed at a given point defined on a volumetric surface. By putting a surface at a fairly low speed you can see where the airflow is slowing down, which would be the boundary, and as it hits the cooling fins shown in Figure 2.
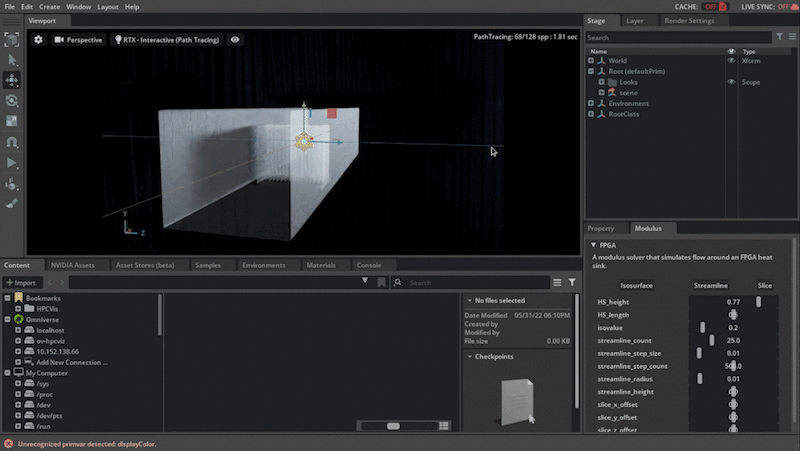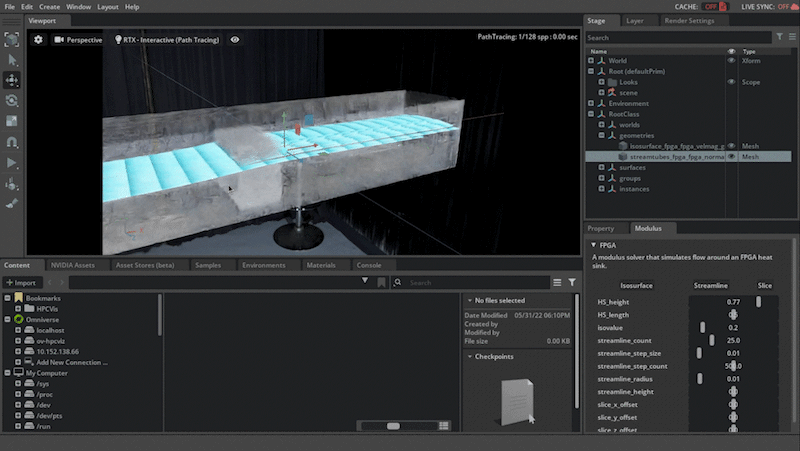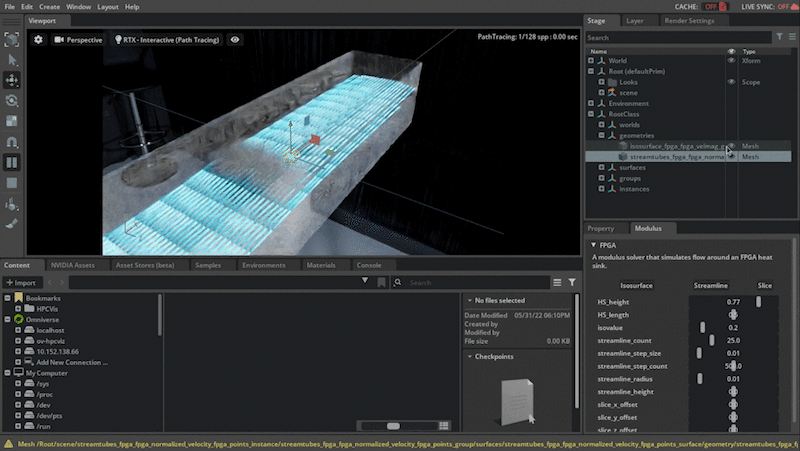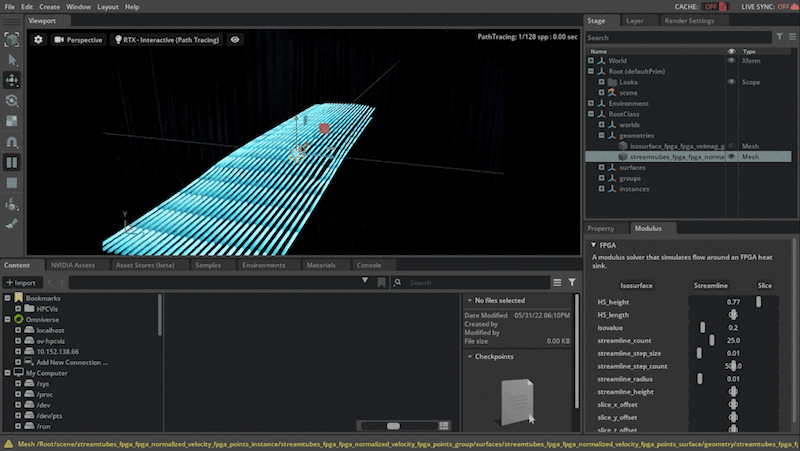
You can also analyze the airflow by using streamlines, which are computed by adding advecting particles through the airflow. You can also play with the texture of the airflow for a better understanding of the airflow.
Figure 2. Visualizing and interactively modifying the simulation scenario
A set of common visualization modes is available with this release of the extension. Each mode will populate the stage that is currently open in Omniverse Create with visualization geometry, which will be updated as you change parameters.
Isosurface: Create an isosurface of the velocity magnitude.
Streamlines: Create a set of streamlines.
Slices: Add three axis-aligned slices of the velocity magnitude.
In addition, you can also vary the visualization parameters using knobs in the extension user interface. The model is not reevaluated when visualization parameters are modified. To learn about which parameters can be adjusted please refer to the OV integration documentation.
Figure 3. Changing visualization parameters and seeing the results interactively in the extension user interface
Another game-changing aspect of Modulus and Physics-ML is the ability to train a model on a parameterized space that can be used to infer a design space defined by a set of design parameters. Users can expose this within the scenario as various parameters knobs, that can be changed to infer and visualize the new simulation output in near real time. When you change these design parameters, the model is reevaluated to infer the new geometry and the output is visualized.
Figure 4. Changing design parameters like height, length, etc. of the fins of the heat sink
Learn more
To learn more about the extension and this example, please refer to the Discord Live session where we talk more about Modulus, its capabilities, and the Modulus OV extension.
NVIDIA is partnering with IronYun to leverage the capabilities of edge AI to help make the world a smarter, safer, more efficient place.
Nearly every organization is enticed by the ability to use cameras to understand their businesses better. Approximately 1 billion video cameras—the ultimate Internet of Things (IoT) sensors—are being used to help people around the world live better and safer.
But, there is a clear barrier to success. Putting the valuable data collected by these cameras to use requires significant human effort. The time-consuming process of manually reviewing massive amounts of footage is arduous and costly. Moreover, after the review is complete, much of the footage is either thrown out or stowed away in the cloud and never used again.
This leads to vast amounts of valuable data never being used to its full potential.
Luckily, thanks to advancements in AI and edge computing, organizations can now layer AI analytics directly onto their existing camera infrastructures to expand the value of video footage captured. By adding intelligence to the equation, organizations can transform physical environments into safer, smarter spaces with AI-powered video analytics systems.
Edge AI in action
This change is already helping companies in many industries improve customer experiences, enhance safety, drive accountability, and deliver operational efficiency. The possibilities for expanding these smart spaces and reaping even greater benefits are vast.
In the retail space, an AI-powered smart store can elevate the consumer shopping experience by using heat maps to improve customer traffic flow, accurately forecast product demand, and optimize supply chain logistics. Ultimately, these smart stores could completely transform retail as we know it and use cameras to create “just walk out” shopping experiences, with no cash registers required.
At electrical substations, intelligent video analytics is streamlining asset inspection and ensuring site safety and security. AI-powered analysis of real-time video streaming provides continuous monitoring of substation perimeters. This can be used to prevent unauthorized access, ensure technicians and engineers follow health and safety protocols, and detect dangerous environmental conditions like smoke and fire.
Creating a smart space
At the forefront of this smart space revolution is the AI vision company and NVIDIA Metropolis partner IronYun. The IronYun AI platform, Vaidio, is helping retailers, banks, NFL stadiums, factories, and more fuel their existing cameras with the power of AI.
NVIDIA and IronYun are working to leverage the capabilities of edge AI and help make the world a smarter, safer, more efficient place.
A smart space is more than simply a physical location equipped with cameras. To be truly smart, these spaces must take collected data to generate critical insights that create superior experiences.
According to IronYun, most organizations today use cameras to improve safety in their operations. The IronYun Vaidio platform extends beyond basic security applications and supports dozens of advanced AI-powered video analytics capabilities specific to each customer. From video search to heat map creation and detection for PPE, IronYun is helping organizations across all industries take their business to the next level with AI through a single platform.
How does this look in the real world? An NFL stadium that hosts 65,000 fans at every game uses Vaidio in interesting ways. The customer first approached IronYun in hopes of improving safety and security operations at the stadium. Once they saw Vaidio analytics in action, they realized they could leverage the same advanced platform to monitor and alert security of smoke, fire, falls, and fights, as well as detect crowd patterns.
IronYun CEO, Paul Sun says, “The tedious task of combing through hours of video footage can take days or weeks to complete. Using Vaidio’s AI video analytics, that same forensic video search can be done in seconds.”
Powering smart spaces across the world
Edge AI is the technology that is making smart spaces possible for organizations to mobilize data being produced at the edge.
The edge is simply a location, named for the way AI computation is done near or at the edge of a network rather than centrally in a cloud computing facility or private data center. Without the low latency and speed provided by the edge, many security and data gathering applications would not be effective or possible.
Sun says, “When you are talking about use cases to ensure safety like weapons detection or smoke and fire detection, instantaneous processing at the edge can accelerate alert and response times, especially relative to camera-based alternatives.”
Building the future
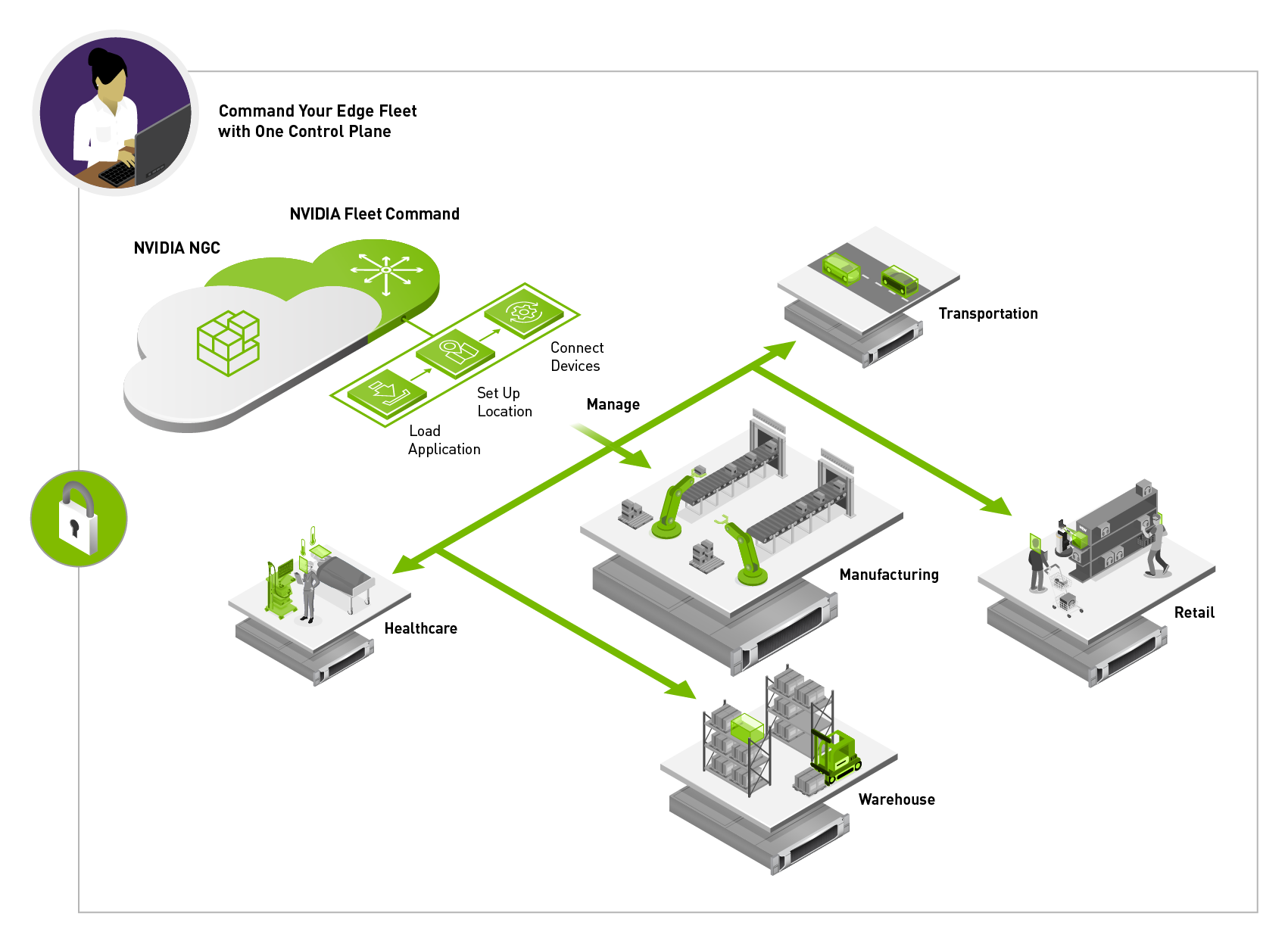
With the powerful capabilities of NVIDIA Metropolis, NVIDIA Fleet Command, and NVIDIA Certified-Systems IronYun applies AI analytics to help make the world safer and smarter,
The NVIDIA Metropolis platform offers IronYun the development tools and services to reduce the time and cost of developing their vision AI deployments. This is a key factor in their ability to bring multiple new and accurate AI-powered video analytics to the Vaidio platform every year.
Figure 1. With NVIDIA Fleet command IT admins can remotely manage edge systems across distributed edge sites
Fleet Command eliminates the need for IT teams to be on call 24/7 when a system experiences a bug or issue. Instead, they can troubleshoot and manage emergencies from the comfort of their office.
The Fleet Command dashboard sits in the cloud and provides administrators a control plane to deploy applications, alerts and analytics. It also provides provisioning and monitoring capabilities, user management control, and other features needed for day-to-day management of the lifecycle of an AI application.
The dashboard also has a private registry where organizations can securely store their own custom application or a partner application, such as IronYun’s Vaidio platform for deployment at any location.
“With NVIDIA Fleet Command, we are able to scale our vision applications from one or two cameras in a POC, to thousands of cameras in a production deployment. By simplifying the management of edge environments, and improving video analytics accuracy at scale, our customer environments indeed become safer and smarter,” says Sun.

 Learn how NVIDIA researchers use AI to design better arithmetic circuits that power our AI chips.
Learn how NVIDIA researchers use AI to design better arithmetic circuits that power our AI chips. 







 Learn how developers used pretrained machine learning models and the Jetson Nano 2GB to create Mariola, a robot that can mimic human actions, from arm and head movements to making faces.
Learn how developers used pretrained machine learning models and the Jetson Nano 2GB to create Mariola, a robot that can mimic human actions, from arm and head movements to making faces. Learn how you can prepost process your NVIDIA Modulus simulations using the Modulus Omniverse extension.
Learn how you can prepost process your NVIDIA Modulus simulations using the Modulus Omniverse extension.
 NVIDIA is partnering with IronYun to leverage the capabilities of edge AI to help make the world a smarter, safer, more efficient place.
NVIDIA is partnering with IronYun to leverage the capabilities of edge AI to help make the world a smarter, safer, more efficient place.