
|
submitted by /u/pgaleone [visit reddit] [comments] |

 DataBloom
DataBloom
|
|
submitted by /u/pgaleone [visit reddit] [comments] |
Hi everyone, probably this is a silly question but I will appreciate if someone takes the time to answer it please.
I’m trying to build a custom loss function, and for now as a dummy I’m just trying to build a MSE function and compare it with the in-built MSE.
My code is just an autoencoder that receives 2D images with a batch size of 128, so when verify y_true I obtain a tensor like this: [128, 256, 256] where the 128 is batch size and the other two are the dimensions.
So, when I was looking for the MSE custom loss and compared it with the in-built one, I realised that they’re doing something like this:
diff = math_ops.squared_difference(y_pred, y_true) loss = K.mean(diff, axis=-1) loss = loss/10
Then I get a vector as a loss function as this: [128,256], so my question is: is this right? shouldn’t loss be an scalar value instead of a vector?, should I use the whole 3D tensor instead of only 2 components in the 2nd line?
I’m kinda lost and since I don’t understand this I cannot move forward on my project.
submitted by /u/DaSpaceman245
[visit reddit] [comments]
Hi, I am working on a classification task for audio data with a custom dataset. i am trying to use the leaf audio github on my own dataset, which runs on the speech commands tfds dataset. i created my own tfds dataset for my custom data, following the exact same setup as the speech commands data. however, i am running into an issue as the dataset is stored in the PrefetchDataset format, and I do not know how to access the data for model.fit . i have researched ways to fix this error and the solutions have not worked, so i was wondering if anyone would be able to help me
submitted by /u/Kunnanada
[visit reddit] [comments]
 Learn industry insights and best practice when implementing data science and AI at the edge.
Learn industry insights and best practice when implementing data science and AI at the edge.
Whether your organization is new to data science or has a mature strategy in place, many come to a similar realization: Most data does not originate at the core.
Scientists often want access to amounts of data that are unreasonable to securely stream to the data center in real time. Whether the distance is 10 miles or thousands of miles, the bounds of traditional IT infrastructure are simply not designed to stretch outside of fixed campuses.
This has led organizations to realize that no data science strategy is complete without an edge strategy.
Read on to learn industry insights on the benefits of coupling data science and edge computing, the challenges faced, solutions to these challenges, and register to view a demo of an edge architecture blueprint.
Edge computing is a style of IT architecture that is typically employed to create systems that are tolerant of geographically distributed data sources and high latency and low-bandwidth interconnects.
Due to restrictions imposed by the operating environment, computing systems designed in this way are typically identifiable by compromises on computational speed and high availability.
Today, there are three types of edge architectures that are commonly being used by organizations: streaming data, edge preprocessing, and autonomous systems.
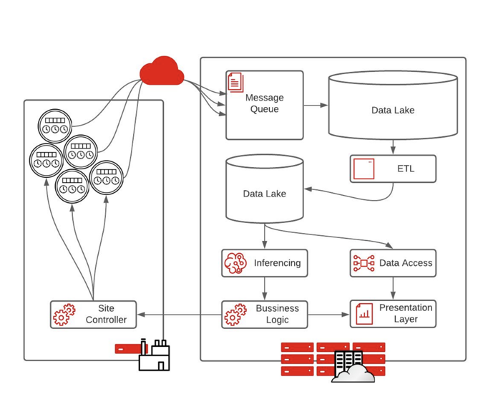
Today, streaming data, the “classical big data” architecture, is the most popular prototypical architecture for organizations that are just starting to implement an edge strategy. This architecture starts with IoT devices, usually sensors, placed anywhere from a factory floor, hospital, or retail store. The data is then sent through the cloud to an IT system.
As data processing abilities increase, the classic big data architecture can be a hindrance because of the level of infrastructure required and the large quantity of data that needs to move from the edge to core.
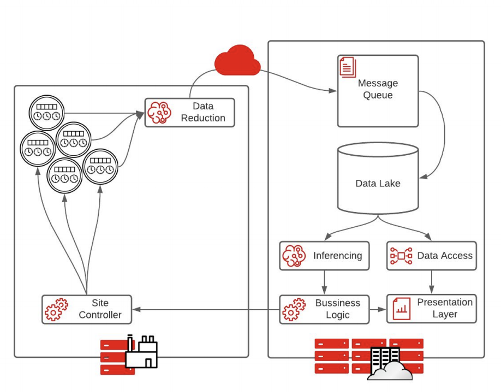
The edge preprocessing model is the most common architecture for organizations transitioning to the edge.
Instead of sensor data feeding directly into a pipeline running in the data center, data is fed into an intelligent data reduction application. This is usually an intelligent machine-learning algorithm that decides what data is important and needs to be sent back to the data center.
Extraction, transformation, and loading (ETL) processes are less important in these architectures because data reduction has already occurred at the edge. Therefore, there is no need for two data lakes, and inference can happen more quickly. The result is faster execution on business logic.
This is a good stepping stone for creating fully autonomous systems, allowing for an unlimited amount of data compression.
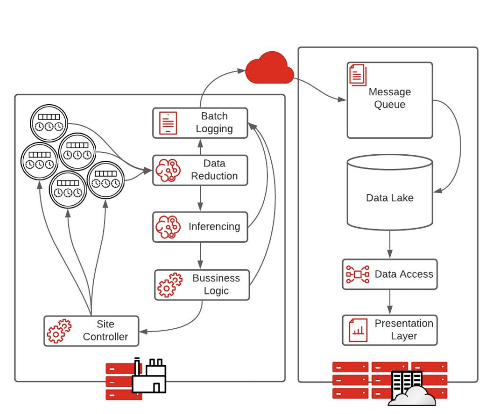
Fully autonomous systems are characterized by sensors collecting data at the edge to make rapid decisions with low latency. With no time to send data back to a data center or cloud to make a proper decision, processing happens at the edge and actions are taken automatically.
With this architecture, every step of the pipeline is sent to a logging mechanism to record the decisions made at the edge. The batch logging will send messages to the cloud or core data center to allow for analytics and system adjustments on the decisions made.
Building an intelligent edge solution is not just about pushing a container to tens or thousands of sites. While it may seem like a trivial task, your organization’s success relies heavily on the infrastructure that you put in place, not just the data science.
There are many complexities that need to be taken into consideration when building an intelligent edge solution such as scale, interoperability, and consistency.
Suggested technologies to build intelligent solutions are:
As organizations look to meet their business needs and enable data science to drive innovation, your options should not be limited to your architecture. Implementing an edge architecture will help you future-proof your platform against new use cases and technologies.
While it is helpful to understand where your architecture stands among different stages of edge implementation, it is often best to view a live demonstration.
For more information, view our webinar, “Data Scientists on the Loose: Lessons Learned while Enabling the Intelligent Edge” for best practice regarding how to implement a Kubernetes system at the edge and the capabilities it can give your organization.
Or, learn more about edge computing and data science.
 Researchers from the University of Illinois at Urbana-Champaign developed GPU-accelerated software to simulate a 2-billion-atom cell that metabolizes and grows like a living cell.
Researchers from the University of Illinois at Urbana-Champaign developed GPU-accelerated software to simulate a 2-billion-atom cell that metabolizes and grows like a living cell.
 This post shows how NLP in Text is converted into vectors to be compatible with ML and other algorithms.
This post shows how NLP in Text is converted into vectors to be compatible with ML and other algorithms.
This article will discuss how to prepare text through vectorization, hashing, tokenization, and other techniques, to be compatible with machine learning (ML) and other numerical algorithms. I’ll explain and demonstrate the process.
Natural Language Processing (NLP) applies Machine Learning (ML) and other techniques to language. However, machine learning and other techniques typically work on the numerical arrays called vectors representing each instance (sometimes called an observation, entity, instance, or row) in the data set. We call the collection of all these arrays a matrix; each row in the matrix represents an instance. Looking at the matrix by its columns, each column represents a feature (or attribute).
So far, this language may seem rather abstract if one isn’t used to mathematical language. However, when dealing with tabular data, data professionals have already been exposed to this type of data structure with spreadsheet programs and relational databases.
After all, spreadsheets are matrices when one considers rows as instances and columns as features. For example, consider a dataset containing past and present employees, where each row (or instance) has columns (or features) representing that employee’s age, tenure, salary, seniority level, and so on.
The first problem one has to solve for NLP is to convert our collection of text instances into a matrix form where each row is a numerical representation of a text instance — a vector. But, in order to get started with NLP, there are several terms that are useful to know. Let’s introduce them.
In NLP, a single instance is called a document, while a corpus refers to a collection of instances. Depending on the problem at hand, a document may be as simple as a short phrase or name or as complex as an entire book.
One has to make a choice about how to decompose our documents into smaller parts, a process referred to as tokenizing our document. It follows that this process produces tokens. Tokens are the units of meaning the algorithm can consider. The set of all tokens seen in the entire corpus is called the vocabulary.
A common choice of tokens is to simply take words; in this case, a document is represented as a bag of words (BoW). More precisely, the BoW model scans the entire corpus for the vocabulary at a word level, meaning that the vocabulary is the set of all the words seen in the corpus. Then, for each document, the algorithm counts the number of occurrences of each word in the corpus.
Most words in the corpus will not appear for most documents, so there will be many zero counts for many tokens in a particular document. Conceptually, that’s essentially it, but an important practical consideration to ensure that the columns align in the same way for each row when we form the vectors from these counts. In other words, for any two rows, it’s essential that given any index k, the kth elements of each row represent the same word.
Before getting into the details of how to assure that rows align, let’s have a quick look at an example done by hand. We’ll see that for a short example it’s fairly easy to ensure this alignment as a human. Still, eventually, we’ll have to consider the hashing part of the algorithm to be thorough enough to implement — I’ll cover this after going over the more intuitive part.
Suppose our corpus is the following four sentences1:
“This is the first document.”
“This document is the second document.”
“And this is the third one.”
“Is this the first document?“
Let’s apply some preprocessing to remove case and punctuation:
“this is the first document”
“this document is the second document”
“and this is the third one”
“is this the first document”
Let’s tokenize the preprocessed documents by designating each word as a token:
“this”, “is”, “the”, “first”, “document”
“this”, “document”, “is”, “the”, “second”, “document”
“and”, “this”, “is”, “the”, “third”, “one”
“is”, “this”, “the”, “first”, “document”
Scanning through the corpus and getting each unique word, we can form our vocabulary:
“this”, “is”, “the”, “first”, “document”, “second”, “and”, “third”, “one”
Let’s count the number of occurrences of each word in each document.
“this”: 1, “is”: 1, “the”: 1, “first”: 1, “document”: 1, “second”: 0, “and”: 0, “third”: 0, “one”: 0
“this”:1, “is”: 1, “the”: 1, “first”: 0, “document”: 2, “second”: 1, “and”: 0, “third”: 0, “one”: 0
“this”: 1, “is”: 1, “the”: 1, “first”: 0, “document”: 0, “second”: 0, “and”: 1, “third”: 1, “one”: 1
“this”: 1, “is”: 1, “the”: 1, “first”: 1, “document”: 1, “second”: 0, “and”: 0, “third”: 0, “one”: 0
Let’s collect this into a table.
| This | is | the | first | document | second | and | third | one |
| 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 |
| 1 | 1 | 1 | 0 | 2 | 1 | 0 | 0 | 0 |
| 1 | 1 | 1 | 0 | 0 | 0 | 1 | 1 | 1 |
| 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 |
If we ignore the header, this is the matrix we were looking for.
It is worth noting that permuting the row of this matrix and any other design matrix (a matrix representing instances as rows and features as columns) does not change its meaning. The same is true for column permutations. Depending on how we map a token to a column index, we’ll get a different ordering of the columns, but no meaningful change in the representation.
This process of mapping tokens to indexes such that no two tokens map to the same index is called hashing2. A specific implementation is called a hash, hashing function, or hash function.
While doing vectorization by hand, we implicitly created a hash function. Assuming a 0-indexing system, we assigned our first index, 0, to the first word we had not seen. Then we incremented the index and repeated the process. Our hash function mapped “this” to the 0-indexed column, “is” to the 1-indexed column and “the” to the 3-indexed columns. A vocabulary-based hash function has certain advantages and disadvantages.
Using the vocabulary as a hash function allows us to invert the hash. This means that given the index of a feature (or column), we can determine the corresponding token. One useful consequence is that once we have trained a model, we can see how certain tokens (words, phrases, characters, prefixes, suffixes, or other word parts) contribute to the model and its predictions. We can therefore interpret, explain, troubleshoot, or fine-tune our model by looking at how it uses tokens to make predictions. We can also inspect important tokens to discern whether their inclusion introduces inappropriate bias to the model.
Let’s consider the artifacts produced by some machine learning models. For example, if we use a Logistic Regression model, we can interpret the coefficient associated with each feature as its effects on the model’s prediction. Random forest models yield feature importances, which tell us how often decision trees in the random forest use each feature to make decisions. Likewise, a Naive Bayes model produces the probability that a feature is non-zero for a specified class.
The power of vocabulary-based vectorization lies in understanding which token each feature represents. So, instead, with a Logistic Regression model, we can see how strongly each token affects the prediction. With Random forests, we get feature importance associated with each token, which tells us how often the decision trees in the random forest make decisions using each token. With naive Bayes, we can extract the probability of a certain token appearing in documents of each class.
If we see that seemingly irrelevant or inappropriately biased tokens are suspiciously influential in the prediction, we can remove them from our vocabulary. If we observe that certain tokens have a negligible effect on our prediction, we can remove them from our vocabulary to get a smaller, more efficient and more concise model.
There are a few disadvantages with vocabulary-based hashing, the relatively large amount of memory used both in training and prediction and the bottlenecks it causes in distributed training.
One downside to vocabulary-based hashing is that the algorithm must store the vocabulary. With large corpuses, more documents usually result in more words, which results in more tokens. Longer documents can cause an increase in the size of the vocabulary as well.
On a single thread, it’s possible to write the algorithm to create the vocabulary and hashes the tokens in a single pass. However, effectively parallelizing the algorithm that makes one pass is impractical as each thread has to wait for every other thread to check if a word has been added to the vocabulary (which is stored in common memory). Without storing the vocabulary in common memory, each thread’s vocabulary would result in a different hashing and there would be no way to collect them into a single correctly aligned matrix.
A better way to parallelize the vectorization algorithm is to form the vocabulary in a first pass, then put the vocabulary in common memory and finally, hash in parallel. This approach, however, doesn’t take full advantage of the benefits of parallelization. Additionally, as mentioned earlier, the vocabulary can become large very quickly, especially for large corpuses containing large documents.
Fortunately, there is an alternative way of hashing tokens: hash each instance with a non-cryptographic mathematical hash function. This type of hash function uses a combination of arithmetic, modular arithmetic, and algebra to map objects (represented by their bits) to a known range of integers or(bits). Since the range is known, the maximum value determines how many columns are in the matrix. Generally, the range is quite large, but for most rows, most columns will be 0. Therefore, with a sparse representation, the memory required to store the matrix will be minimal, and algorithms can efficiently handle sparse matrix-based operations.
Further, since there is no vocabulary, vectorization with a mathematical hash function doesn’t require any storage overhead for the vocabulary. The absence of a vocabulary means there are no constraints to parallelization and the corpus can therefore be divided between any number of processes, permitting each part to be independently vectorized. Once each process finishes vectorizing its share of the corpuses, the resulting matrices can be stacked to form the final matrix. This parallelization, which is enabled by the use of a mathematical hash function, can dramatically speed up the training pipeline by removing bottlenecks.
Although the use of mathematical hash functions can reduce the time taken to produce feature vectors, it does come at a cost, namely the loss of interpretability and explainability. Because it is impossible to map back from a feature’s index to the corresponding tokens efficiently when using a hash function, we can’t determine which token corresponds to which feature. So we lose this information and therefore interpretability and explainability.
In this article, we’ve seen the basic algorithm that computers use to convert text into vectors. We’ve resolved the mystery of how algorithms that require numerical inputs can be made to work with textual inputs.
Textual data sets are often very large, so we need to be conscious of speed. Therefore, we’ve considered some improvements that allow us to perform vectorization in parallel. We also considered some tradeoffs between interpretability, speed and memory usage.
By applying machine learning to these vectors, we open up the field of NLP (Natural Language Processing). In addition, vectorization also allows us to apply similarity metrics to text, enabling full-text search and improved fuzzy matching applications.
1This example comes from the SciKit-learn documentation: sklearn.feature_extraction.text.CountVectorizer
2In general, a hash function can map two entities to the same index. This is called a collision and should be an extremely rare occurrence for a hash function. Collisions are undesirable.
 NVIDIA Omniverse for virtual world building brought design collaboration and digital twins to center stage in 2021.
NVIDIA Omniverse for virtual world building brought design collaboration and digital twins to center stage in 2021.
2021 was a landmark year for NVIDIA Omniverse, the multi-GPU enabled open platform for 3D design collaboration and real-time simulation. The platform became generally available to millions of creators, developers, and enterprise leaders looking to enhance 3D workflows and develop physically accurate digital twins.
Recognized by TIME Magazine as a Best Invention, NVIDIA Omniverse is laying the foundation for robust virtual world creation and opening new paths to market for developers around the world.
With the growth of the platform last year came major new updates and releases for NVIDIA Omniverse Apps including Omniverse Create, Omniverse View, Omniverse Audio2Face, Omniverse Machinima, Omniverse Kaolin, and Omniverse XR Remote.
Powerful new features and frameworks include:
Over 100,000 individual creators, designers, engineers, and students downloaded the NVIDIA Omniverse platform in 2021, while numerous leading companies explored NVIDIA Omniverse Enterprise to unite their teams, tools, and assets in a shared virtual space.
Some of the incredible work from the community, partners, customers, and senior NVIDIA Omniverse designers and engineers made in Omniverse are listed below.
At GTC in Spring of 2021, BMW Group debuted how they are using NVIDIA Omniverse Enterprise to create a digital twin of their automotive factory to reduce planning times and improve flexibility and precision.
One of the #CreateYourRetroverse contest winners, Yenifer, used Omniverse Create, Adobe Substance Painter, Autodesk Maya, and ZBrush to design this nostalgic scene.

The creator behind the popular YouTube channel, JSFILMZ, Jae Solina is using NVIDIA Omniverse Audio2Face to save time and money on virtual production. “With Omniverse, I don’t have to wait a full week to render a 30-second animation,” Solina said. “The rendering speed in Omniverse is superb and saves me a lot of time, which is important when balancing my filmmaking, noncreative work, and family.”
Cartoon Network animator Benny Sokomba Dazhi, Benny Dee, uses the Reallusion iClone Omniverse Connector to streamline his 3D workflow. “The main challenges I faced when trying to meet deadlines were long render times and difficulties with software compatibility, but using an Omniverse Connector for Reallusion’s iClone app has been game-changing for my workflow,” he said.
At SIGGRAPH, NVIDIA premiered a documentary highlighting the creative minds and revolutionary technologies behind the GTC 2021 keynote, detailing how Omniverse was used to create a virtual version of NVIDIA’s CEO Jensen Huang.
NVIDIA launched a new self-paced Deep Learning Institute training course, Getting Started with Universal Scene Description for Collaborative 3D Workflows, that familiarizes users with Universal Scene Description. The inaugural NVIDIA Omniverse Developer Day was also introduced at GTC in November, providing developers access to technical and business-focused sessions for building, extending, and connecting tools and platforms to the growing Omniverse ecosystem.
To learn more about NVIDIA Omniverse highlights from 2021, and to get an insider’s look at the 2022 product roadmap:
Every living cell contains its own bustling microcosm, with thousands of components responsible for energy production, protein building, gene transcription and more. Scientists at the University of Illinois at Urbana-Champaign have built a 3D simulation that replicates these physical and chemical characteristics at a particle scale — creating a fully dynamic model that mimics the Read article >
The post NVIDIA GPUs Enable Simulation of a Living Cell appeared first on The Official NVIDIA Blog.
So for example, let’s just say there is some unknown function of x, y=f(x). Now I can train the model with x and y and it would predict y when given x. But i don’t want exactly y, instead i want will y be greater than x or not? So the output should be 1 if it greater 0 if equal or lesser. How can I do this? So my data has 3 parameters: x, y, e(1 or 0). I need to train my model by giving out x and y and results as e. But then when I want predict i have to give x and y. Right? I want to give only x and get output 0 or 1. I could just train it with x as input and y as results and predict y from x and check them by myself but that is useless since I don’t want to know y it is just going to be waste of computational power.
submitted by /u/ash_hashtag
[visit reddit] [comments]
Greetings, I am running a text classification task that tries to classify a text as belonging to one (and only one) of 25 classes.
I’ve used two accuracy metrics: tf.keras.metrics.Accuracy(), which was set as the default on the code I’m reusing, and tf.keras.metrics.CategoricalAccuracy(), as it seemed more appropriate.
CategoricalAccuracy is reporting a fairly good result of around 0.90, but the other Accuracy is reporting only 0.17. What exactly are the differences between these two, and am I doing something wrong?
submitted by /u/Portugal_Stronk
[visit reddit] [comments]