A partial differential equation is “the most powerful tool humanity has ever created,” Cornell University mathematician Steven Strogatz wrote in a 2009 New York Times opinion piece. This quote opened last week’s GTC talk AI4Science: The Convergence of AI and Scientific Computing, presented by Anima Anandkumar, director of machine learning research at NVIDIA and professor Read article >
Atos and NVIDIA today announced the Excellence AI Lab (EXAIL), which brings together scientists and researchers to help advance European computing technologies, education and research.
NVIDIA cuSPARSELt v0.2 now supports ReLu and GeLu activation functions, bias vector, and batched Sparse GEMM.
Today, NVIDIA is announcing the availability of cuSPARSELt, version 0.2.0, which increases performance on activation functions, bias vectors, and Batched Sparse GEMM. This software can be downloaded now free of charge.
NVIDIA cuSPARSELt is a high-performance CUDA library dedicated to general matrix-matrix operations in which at least one operand is a sparse matrix:
In this equation, and refer to in-place operations such as transpose and nontranspose.
The cuSPARSELt APIs provide flexibility in the algorithm/operation selection, epilogue, and matrix characteristics, including memory layout, alignment, and data types.
Enhancements to the low-level interface by adding configuration options, a new error-reporting mechanism, and functions that calculate the size of the decompressed output.
Redesigned Batch APIs
Low-level is targeting advanced users — metadata and chunking must be handled outside of nvCOMP. Perform batch compression/decompression of multiple streams, lightweight, and fully asynchronous.
High-level is provided for ease of use — metadata and chunking is handled internally by nvCOMP. The easiest way to ramp-up and use nvCOMP in applications.
All compressors are available through the updated low-level API (including Cascaded and Bitcomp – new in 2.1).
Performance optimizations for Snappy, LZ4, and GDeflate.
New high-throughput and high-compression-ratio GPU compressors in GDeflate.
nvCOMP is a CUDA library that features generic compression interfaces to enable developers to use high-performance GPU compressors in their applications.
Supported nvCOMP Compression algorithms:
Cascaded: Novel high-throughput compressor ideal for analytical or structured/tabular data.
LZ4: General-purpose no-entropy byte-level compressor well suited for a wide range of datasets.
Snappy: Similar to LZ4, this byte-level compressor is a popular existing format used for tabular data.
GDeflate: Proprietary compressor with entropy encoding and LZ77, high compression ratios on arbitrary data.
Bitcomp: Proprietary compressor designed for floating point data in Scientific Computing applications.
NVIDIA and partners have been working hard to get the NVIDIA Arm HPC Developer Kit units into the hands of developers and enhance the software stack.
In July of 2021, NVIDIA announced the availability of the NVIDIA Arm HPC Developer Kit for preordering, along with the NVIDIA HPC SDK. Since then NVIDIA and its partners have been working hard to get units into the hands of developers, to increase global availability, and enhance the software stack.
Global Availability
The NVIDIA Arm HPC Developer Kit is based on the GIGABYTE G242-P32 2U server. It includes an Arm CPU, two A100 GPUs, two NVIDIA BlueField-2 data processing units (DPUs), and the NVIDIA HPC SDK suite of tools.
This delivers support for both single and multinode configurations. Units are available to order for global delivery through GIGABYTE.
Users Already Running HPC codes
The first units are already being used at sites, including Los Alamos National Laboratory (LANL), the University of Leicester, Oak Ridge National Laboratory (ORNL), and the National Center for High-performance Computing (NCHC) in Taiwan. They have successfully deployed multinode configurations and opened the systems to users to run HPC codes.
Los Alamos National Laboratory
“Los Alamos National Laboratory has a broad set of requirements related to our national security mission spaces. With this as a backdrop, we evaluate, deploy, and integrate many advanced technologies into our ecosystem. The consistent goal of these technologies is to improve our responses to mission requirements.
“As part of our 2023 HPE/NVIDIA system, which will utilize NVIDIA’s Grace Arm-based CPU, Los Alamos has been working with the Arm ecosystem software and hardware. With that in mind, we have already deployed early development test systems where we see good success migrating and developing new codes. One such code, which we are actively codesigning both HW and SW, is an astrophysics code-named Phoebus.” – Steve Poole, Chief Architect at LANL.
University of Leicester
“The University of Leicester, thanks to the contribution of the ExCALIBUR Hardware and Enabling Software Programme and STFC DiRAC HPC facility, has recently completed the deployment of 4x NVIDIA Arm HPC Developer Kit accessible by all UK developers interested in testing, porting, and optimizing strategic UK applications on NVIDIA Ampere Architecture Computing Altra CPU and NVIDIA A100 GPU.
“The UK remains at the forefront of computing thanks to initiatives like ExCALIBUR. The addition of this accelerated Arm-based system opens new opportunities to evaluate the role of accelerators in a fast-growing and diversified Arm HPC ecosystem. We welcome the close partnership of NVIDIA in pushing the ecosystem forward into the next era of accelerated computing.” – Mark Wilkinson, Professor of Theoretical Astrophysics and Director at DiRAC HPC Facility.
Oak Ridge National Laboratory
“Here at ORNL, we are looking forward to working with NVIDIA to explore the deployment of a wide array of applications on the NVIDIA Arm HPC developer kit as performance portability continues to gain prominence in HPC.” – Ross Miller, Systems Integration Programmer in the National Center for Computational Sciences at ORNL.
Software Stack Enhancements
NVIDIA continues to make rapid progress on enhancing the HPC SDK and supporting its full stack of ML tools on Arm. Separate from the HPC SDK, NVIDIA is announcing support for two of the most popular deep learning frameworks: PyTorch and TensorFlow.
The NVIDIA Arm HPC Developer Kit is the first step in enabling an Arm HPC ecosystem with GPU acceleration. NVIDIA is committed to full support for Arm for HPC and AI applications.
Posted by Nal Kalchbrenner and Lasse Espeholt, Google Research
Deep learning has successfully been applied to a wide range of important challenges, such as cancer prevention and increasing accessibility. The application of deep learning models to weather forecasts can be relevant to people on a day-to-day basis, from helping people plan their day to managing food production, transportation systems, or the energy grid. Weather forecasts typically rely on traditional physics-based techniques powered by the world’s largest supercomputers. Such methods are constrained by high computational requirements and are sensitive to approximations of the physical laws on which they are based.
Deep learning offers a new approach to computing forecasts. Rather than incorporating explicit physical laws, deep learning models learn to predict weather patterns directly from observed data and are able to compute predictions faster than physics-based techniques. These approaches also have the potential to increase the frequency, scope, and accuracy of the predicted forecasts.
Illustration of the computation through MetNet-2. As the computation progresses, the network processes an ever larger context from the input and makes a probabilistic forecast of the likely future weather conditions.
To that end, in “Skillful Twelve Hour Precipitation Forecasts Using Large Context Neural Networks”, we push the forecasting boundaries of our neural precipitation model to 12 hour predictions while keeping a spatial resolution of 1 km and a time resolution of 2 minutes. By quadrupling the input context, adopting a richer weather input state, and extending the architecture to capture longer-range spatial dependencies, MetNet-2 substantially improves on the performance of its predecessor, MetNet. Compared to physics-based models, MetNet-2 outperforms the state-of-the-art HREF ensemble model for weather forecasts up to 12 hours ahead.
MetNet-2 Features and Architecture Neural weather models like MetNet-2 map observations of the Earth to the probability of weather events, such as the likelihood of rain over a city in the afternoon, of wind gusts reaching 20 knots, or of a sunny day ahead. End-to-end deep learning has the potential to both streamline and increase quality by directly connecting a system’s inputs and outputs. With this in mind, MetNet-2 aims to minimize both the complexity and the total number of steps involved in creating a forecast.
The inputs to MetNet-2 include the radar and satellite images also used in MetNet. To capture a more comprehensive snapshot of the atmosphere with information such as temperature, humidity, and wind direction — critical for longer forecasts of up to 12 hours — MetNet-2 also uses the pre-processed starting state used in physical models as a proxy for this additional weather information. The radar-based measures of precipitation (MRMS) serve as the ground truth (i.e., what we are trying to predict) that we use in training to optimize MetNet-2’s parameters.
Example ground truth image: Instantaneous precipitation (mm/hr) based on radar (MRMS) capturing a 12 hours-long progression.
MetNet-2’s probabilistic forecasts can be viewed as averaging all possible future weather conditions weighted by how likely they are. Due to its probabilistic nature, MetNet-2 can be likened to physics-based ensemble models, which average some number of future weather conditions predicted by a variety of physics-based models. One notable difference between these two approaches is the duration of the core part of the computation: ensemble models take ~1 hour, whereas MetNet-2 takes ~1 second.
Steps in a MetNet-2 forecast and in a physics-based ensemble.
One of the main challenges that MetNet-2 must overcome to make 12 hour long forecasts is capturing a sufficient amount of spatial context in the input images. For each additional forecast hour we include 64 km of context in every direction at the input. This results in an input context of size 20482 km2 — four times that used in MetNet. In order to process such a large context, MetNet-2 employs model parallelism whereby the model is distributed across 128 cores of a Cloud TPU v3-128. Due to the size of the input context, MetNet-2 replaces the attentional layers of MetNet with computationally more efficient convolutional layers. But standard convolutional layers have local receptive fields that may fail to capture large spatial contexts, so MetNet-2 uses dilated receptive fields, whose size doubles layer after layer, in order to connect points in the input that are far apart one from the other.
Example of input spatial context and target area for MetNet-2.
Results Because MetNet-2’s predictions are probabilistic, the model’s output is naturally compared with the output of similarly probabilistic ensemble or post-processing models. HREF is one such state-of-the-art ensemble model for precipitation in the United States, which aggregates ten predictions from five different models, twice a day. We evaluate the forecasts using established metrics, such as the Continuous Ranked Probability Score, which captures the magnitude of the probabilistic error of a model’s forecasts relative to the ground truth observations. Despite not performing any physics-based calculations, MetNet-2 is able to outperform HREF up to 12 hours into the future for both low and high levels of precipitation.
Continuous Ranked Probability Score (CRPS; lower is better) for MetNet-2 vs HREF aggregated over a large number of test patches randomly located in the Continental United States.
Examples of Forecasts The following figures provide a selection of forecasts from MetNet-2 compared with the physics-based ensemble HREF and the ground truth MRMS.
Probability maps for the cumulative precipitation rate of 1 mm/hr on January 3, 2019 over the Pacific NorthWest. The maps are shown for each hour of lead time from 1 to 12. Left: Ground truth, source MRMS. Center: Probability map as predicted by MetNet-2 . Right: Probability map as predicted by HREF.
Comparison of 0.2 mm/hr precipitation on March 30, 2020 over Denver, Colorado. Left: Ground truth, source MRMS. Center: Probability map as predicted by MetNet-2 . Right: Probability map as predicted by HREF.MetNet-2 is able to predict the onset of the storm (called convective initiation) earlier in the forecast than HREF as well as the storm’s starting location, whereas HREF misses the initiation location, but captures its growth phase well.
Comparison of 2 mm/hr precipitation stemming from Hurricane Isaias, an extreme weather event that occurred on August 4, 2020 over the North East coast of the US. Left: Ground truth, source MRMS. Center: Probability map as predicted by MetNet-2. Right: Probability map as predicted by HREF.
Interpreting What MetNet-2 Learns About Weather Because MetNet-2 does not use hand-crafted physical equations, its performance inspires a natural question: What kind of physical relations about the weather does it learn from the data during training? Using advanced interpretability tools, we further trace the impact of various input features on MetNet-2’s performance at different forecast timelines. Perhaps the most surprising finding is that MetNet-2 appears to emulate the physics described by Quasi-Geostrophic Theory, which is used as an effective approximation of large-scale weather phenomena. MetNet-2 was able to pick up on changes in the atmospheric forces, at the scale of a typical high- or low-pressure system (i.e., the synoptic scale), that bring about favorable conditions for precipitation, a key tenet of the theory.
Conclusion MetNet-2 represents a step toward enabling a new modeling paradigm for weather forecasting that does not rely on hand-coding the physics of weather phenomena, but rather embraces end-to-end learning from observations to weather targets and parallel forecasting on low-precision hardware. Yet many challenges remain on the path to fully achieving this goal, including incorporating more raw data about the atmosphere directly (rather than using the pre-processed starting state from physical models), broadening the set of weather phenomena, increasing the lead time horizon to days and weeks, and widening the geographic coverage beyond the United States.
Acknowledgements Shreya Agrawal, Casper Sønderby, Manoj Kumar, Jonathan Heek, Carla Bromberg, Cenk Gazen, Jason Hickey, Aaron Bell, Marcin Andrychowicz, Amy McGovern, Rob Carver, Stephan Hoyer, Zack Ontiveros, Lak Lakshmanan, David McPeek, Ian Gonzalez, Claudio Martella, Samier Merchant, Fred Zyda, Daniel Furrer and Tom Small.
AI neural network deep potential to combine classical MD simulation with DFT calculation accuracy.
Molecular simulation communities have faced the accuracy-versus-efficiency dilemma in modeling the potential energy surface and interatomic forces for decades. Deep Potential, the artificial neural network force field, solves this problem by combining the speed of classical molecular dynamics (MD) simulation with the accuracy of density functional theory (DFT) calculation.1 This is achieved by using the GPU-optimized package DeePMD-kit, which is a deep learning package for many-body potential energy representation and MD simulation.2
This post provides an end-to-end demonstration of training a neural network potential for the 2D material graphene and using it to drive MD simulation in the open-source platform Large-scale Atomic/Molecular Massively Parallel Simulator (LAMMPS).3 Training data can be obtained either from the Vienna Ab initio Simulation Package (VASP)4, or Quantum ESPRESSO (QE).5
A seamless integration of molecular modeling, machine learning, and high-performance computing (HPC) is demonstrated with the combined efficiency of molecular dynamics with ab initio accuracy — that is entirely driven through a container-based workflow. Using AI techniques to fit the interatomic forces generated by DFT, the accessible time and size scales can be boosted several orders of magnitude with linear scaling.
Deep potential is essentially a combination of machine learning and physical principles, which start a new computing paradigm as shown in Figure 1.
Figure 1. A new computing paradigm composed of molecular modeling, AI, and HPC. (Figure courtesy: Dr. Linfeng Zhang, DP Technology)
The entire workflow is shown in Figure 2. The data generation step is done with VASP and QE. The data preparation, model training, testing, and compression steps are done using DeePMD-kit. The model deployment is in LAMMPS.
Figure 2. Diagram of the DeePMD workflow.
Why Containers?
A container is a portable unit of software that combines the application, and all its dependencies, into a single package that is agnostic to the underlying host OS.
The workflow in this post involves AIMD, DP training, and LAMMPS MD simulation. It is nontrivial and time-consuming to install each software package from source with the correct setup of compiler, MPI, GPU library, and optimization flags.
Containers solve this problem by providing a highly optimized GPU-enabled computing environment for each step, and eliminates the time to install and test software.
The NGC catalog, a hub of GPU-optimized HPC and AI software, carries a whole of HPC and AI containers that can be readily deployed on any GPU system. The HPC and AI containers from the NGC catalog are updated frequently and are tested for reliability and performance — necessary to speed up the time to solution.
These containers are also scanned for Common Vulnerabilities and Exposure (CVEs), ensuring that they are devoid of any open ports and malware. Additionally, the HPC containers support both Docker and Singularity runtimes, and can be deployed on multi-GPU and multinode systems running in the cloud or on-premises.
Training data generation
The first step in the simulation is data generation. We will show you how you can use VASP and Quantum ESPRESSO to run AIMD simulations and generate training datasets for DeePMD. All input files can be downloaded from the GitHub repository using the following command:
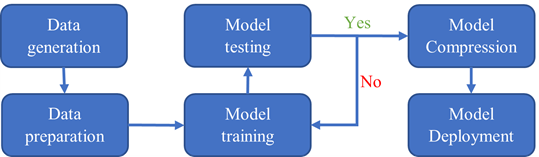
A two-dimensional graphene system with 98-atoms is used as shown in Figure 3.6 To generate the training datasets, 0.5ps NVT AIMD simulation at 300 K is performed. The time step chosen is 0.5fs. The DP model is created using 1000 time steps from a 0.5ps MD trajectory at a fixed temperature.
Due to the short simulation time, the training dataset contains consecutive system snapshots, which are highly correlated. Generally, the training dataset should be sampled from uncorrelated snapshots with various system conditions and configurations. For this example, we used a simplified training data scheme. For production DP training, using DP-GEN is recommended to utilize the concurrent learning scheme to efficiently explore more combinations of conditions.7
The projector-augmented wave pseudopotentials are employed to describe the interactions between the valence electrons and frozen cores. The generalized gradient approximation exchange−correlation functional of Perdew−Burke−Ernzerhof. Only the Γ-point was used for k-space sampling in all systems.
Figure 3. A graphene system composed of 98 carbon atoms is used in AIMD simulation.
Quantum Espresso
The AIMD simulation can also be carried out using Quantum ESPRESSO, available as a container from the NGC Catalog. Quantum ESPRESSO is an integrated suite of open-source computer codes for electronic-structure calculations and materials modeling at the nanoscale based on density-functional theory, plane waves, and pseudopotentials. The same graphene structure is used in the QE calculations. The following command can be used to start the AIMD simulation:
Once the training data is obtained from AIMD simulation, we want to convert its format using dpdata so that it can be used as input to the deep neural network. The dpdata package is a format conversion toolkit between AIMD, classical MD, and DeePMD-kit.
You can use the convenient tool dpdata to convert data directly from the output of first-principles packages to the DeePMD-kit format. For deep potential training, the following information of a physical system has to be provided: atom type, box boundary, coordinate, force, viral, and system energy.
A snapshot, or a frame of the system, contains all these data points for all atoms at one-time step, which can be stored in two formats, that is raw and npy.
The first format raw is plain text with all information in one file, and each line of the file represents a snapshot. Different system information is stored in different files named as box.raw, coord.raw, force.raw, energy.raw, and virial.raw. We recommended you follow these naming conventions when preparing the training files.
This force.raw contains three frames, with each frame having the forces of two atoms, resulting in three lines and six columns. Each line provides all three force components of two atoms in one frame. The first three numbers are the three force components of the first atom, while the next three numbers are the force components of the second atom.
The coordinate file coord.raw is organized similarly. In box.raw, the nine components of the box vectors should be provided on each line. In virial.raw, the nine components of the virial tensor should be provided on each line in the order XX XY XZ YX YY YZ ZX ZY ZZ. The number of lines of all raw files should be identical. We assume that the atom types do not change in all frames. It is provided by type.raw, which has one line with the types of atoms written one by one.
The atom types should be integers. For example, the type.raw of a system that has two atoms with zero and one:
$ cat type.raw
0 1
It is not a requirement to convert the data format to raw, but this process should give a sense on the types of data that can be used as inputs to DeePMD-kit for training.
The easiest way to convert the first-principles results to the training data is to save them as numpy binary data.
For VASP output, we have prepared an outcartodata.py script to process the VASP OUTCAR file. By running the commands:
A folder called deepmd_data is generated and moved to the training directory. It generates five sets 0/set.000, 1/set.000, 2/set.000, 3/set.000, 4/set.000, with each set containing 200 frames. It is not required to take care of the binary data files in each of the set.* directories. The path containing the set.* folder and type.raw file is called a system. If you want to train a nonperiodic system, an empty nopbc file should be placed under the system directory. box.raw is not necessary as it is a nonperiodic system.
We are going to use three of the five sets for training, one for validating, and the remaining one for testing.
Deep Potential model training
The input of the deep potential model is a descriptor vector containing the system information mentioned previously. The neural network contains several hidden layers with a composition of linear and nonlinear transformations. In this post, a three layer-neural network with 25, 50 and 100 neurons in each layer is used. The target value, or the label, for the neural network to learn is the atomic energies. The training process optimizes the weights and the bias vectors by minimizing the loss function.
The training is initiated by the command where input.json contains the training parameters:
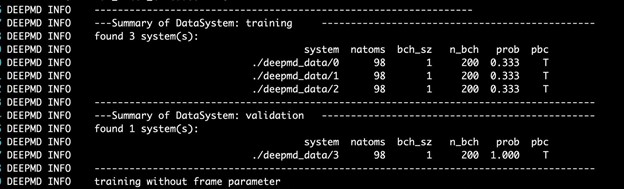
The DeePMD-kit prints detailed information on the training and validation data sets. The data sets are determined by training_data and validation_data as defined in the training section of the input script. The training dataset is composed of three data systems, while the validation data set is composed of one data system. The number of atoms, batch size, number of batches in the system, and the probability of using the system are all shown in Figure 4. The last column presents if the periodic boundary condition is assumed for the system.
Figure 4. Screenshot of the DP training output.
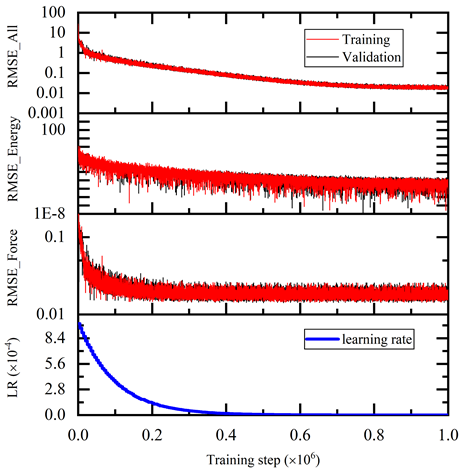
During the training, the error of the model is tested every disp_freq training step with the batch used to train the model and with numb_btch batches from the validating data. The training error and validation error are printed correspondingly in the file disp_file (default is lcurve.out). The batch size can be set in the input script by the key batch_size in the corresponding sections for training and validation data set.
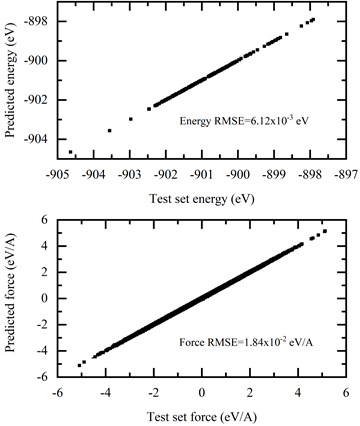
The training error reduces monotonically with training steps as shown in Figure 5. The trained model is tested on the test dataset and compared with the AIMD simulation results. The test command is:
Figure 6. Test of the prediction accuracy of trained DP model with AIMD energies and forces.
Model export and compression
After the model has been trained, a frozen model is generated for inference in MD simulation. The process of saving neural network from a checkpoint is called “freezing” a model:
After the frozen model is generated, the model can be compressed without sacrificing its accuracy; while greatly speeding up the inference performance in MD. Depending on simulation and training setup, model compression can boost performance by 10X, and reduce memory consumption by 20X when running on GPUs.
The frozen model can be compressed using the following command where -i refers to the frozen model and -o points to the output name of the compressed model:
A new pair-style has been implemented in LAMMPS to deploy the trained neural network in prior steps. For users familiar with the LAMMPS workflow, only minimal changes are needed to switch to deep potential. For instance, a traditional LAMMPS input with Tersoff potential has the following setting for potential setup:
pair_style tersoff
pair_coeff * * BNC.tersoff C
To use deep potential, replace previous lines with:
The pair_style command in the input file uses the DeePMD model to describe the atomic interactions in the graphene system.
The graphene-compress.pb file represents the frozen and compressed model for inference.
The graphene system in MD simulation contains 1,560 atoms.
Periodic boundary conditions are applied in the lateral x– and y-directions, and free boundary is applied to the z-direction.
The time step is set as 1 fs.
The system is placed under NVT ensemble at temperature 300 K for relaxation, which is consistent with the AIMD setup.
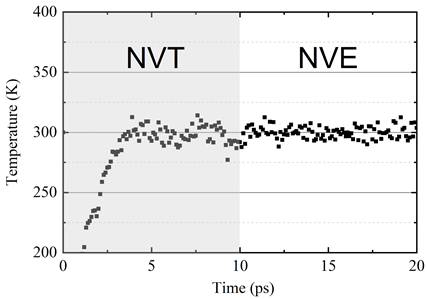
The system configuration after NVT relaxation is shown in Figure 7. It can be observed that the deep potential can describe the atomic structures with small ripples in the cross-plane direction. After 10ps NVT relaxation, the system is placed under NVE ensemble to check system stability.
Figure 7. Atomic configuration of the graphene system after relaxation with deep potential.
The system temperature is shown in Figure 8.
Figure 8. System temperature under NVT and NVE ensembles. The MD system driven by deep potential is very stable after relaxation.
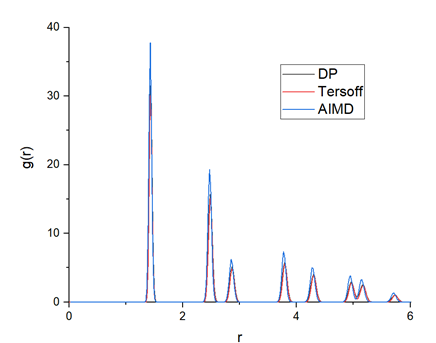
To validate the accuracy of the trained DP model, the calculated radial distribution function (RDF) from AIMD, DP and Tersoff, are plotted in Figure 9. The DP model-generated RDF is very close to that of AIMD, which indicates that the crystalline structure of graphene can be well presented by the DP model.
Figure 9. Radial distribution function calculated by AIMD, DP and Tersoff potential, respectively. It can be observed that the RDF calculated by DP is very close to that of AIMD.
Conclusion
This post demonstrates a simple case study of graphene under given conditions. The DeePMD-kit package streamlines the workflow from AIMD to classical MD with deep potential, providing the following key advantages:
Highly automatic and efficient workflow implemented in the TensorFlow framework.
APIs with popular DFT and MD packages such as VASP, QE, and LAMMPS.
Broad applications in organic molecules, metals, semiconductors, insulators, and more.
Highly efficient code for HPC with MPI and GPU support.
Modularization for easy adoption by other deep learning potential models.
Furthermore, the use of GPU-optimized containers from the NGC catalog simplifies and accelerates the overall workflow by eliminating the steps to install and configure software. To train a comprehensive model for other applications, download the DeepMD Kit Container from the NGC catalog.
Acknowledgements
We thank the helpful discussions with Dr. Chunyi Zhang from Temple University, Dan Han, Dr. Xinyu Wang from Shandong University, and Dr. Linfeng Zhang, Yuzhi Zhang, Jinzhe Zeng, Duo Zhang, and Fengbo Yuan from the DeepModeling community.
References
[1] Jia W, Wang H, Chen M, Lu D, Lin L, Car R, E W and Zhang L 2020 Pushing the limit of molecular dynamics with ab initio accuracy to 100 million atoms with machine learning IEEE Press 5 1-14
[2] Wang H, Zhang L, Han J and E W 2018 DeePMD-kit: A deep learning package for many-body potential energy representation and molecular dynamics Computer Physics Communications 228 178-84
[3] Plimpton S 1995 Fast Parallel Algorithms for Short-Range Molecular Dynamics Journal of Computational Physics 117 1-19
[4] Kresse G and Hafner J 1993 Ab initio molecular dynamics for liquid metals Physical Review B 47 558-61
[5] Giannozzi P, Baroni S, Bonini N, Calandra M, Car R, Cavazzoni C, Ceresoli D, Chiarotti G L, Cococcioni M, Dabo I, Dal Corso A, de Gironcoli S, Fabris S, Fratesi G, Gebauer R, Gerstmann U, Gougoussis C, Kokalj A, Lazzeri M, Martin-Samos L, Marzari N, Mauri F, Mazzarello R, Paolini S, Pasquarello A, Paulatto L, Sbraccia C, Scandolo S, Sclauzero G, Seitsonen A P, Smogunov A, Umari P and Wentzcovitch R M 2009 QUANTUM ESPRESSO: a modular and open-source software project for quantum simulations of materials Journal of Physics: Condensed Matter 21 395502
[6] Humphrey W, Dalke A and Schulten K 1996 VMD: Visual molecular dynamics Journal of Molecular Graphics 14 33-8
[7] Yuzhi Zhang, Haidi Wang, Weijie Chen, Jinzhe Zeng, Linfeng Zhang, Han Wang, and Weinan E, DP-GEN: A concurrent learning platform for the generation of reliable deep learning based potential energy models, Computer Physics Communications, 2020, 107206.
Modern computing workloads — including scientific simulations, visualization, data analytics, and machine learning — are pushing supercomputing centers, cloud providers and enterprises to rethink their computing architecture. The processor or the network or the software optimizations alone can’t address the latest needs of researchers, engineers and data scientists. Instead, the data center is the new Read article >
NVIDIA Clara Holoscan and Clara AGX Developer Kit accelerates development of AI for endoscopy, laparoscopy, and other surgical procedures.
NVIDIA Clara Holoscan provides a scalable medical device computing platform for developers to create AI microservices and deliver insights in real time. The platform optimizes every stage of the data pipeline: from high-bandwidth data streaming and physics-based analysis to accelerated AI inference, and graphic visualizations.
The NVIDIA Clara AGX Developer Kit, which is now available, combines the efficient Arm-based embedded computing of the AGX Xavier SoC with the powerful NVIDIA RTX 6000 GPU and the 100 GbE connectivity of the NVIDIA ConnectX-6 network processor. This brings real-time AI acceleration to the next generation of intelligent, software-defined, embedded medical devices. Developers using the Clara AGX Developer Kit for surgical video applications—such as AI-enhanced endoscopy, laparoscopy, or other minimally invasive procedures—require the minimum possible end-to-end latency in their video processing path. Customers can use the Clara Holoscan SDK v0.1 on the Clara AGX Developer Kit today and on the next-generation developer kit in the second half of 2022.
The demands of surgical video necessitate consistent and reliable low-latency, between the image captured by the endoscope and the image projected on a monitor. This provides surgeons with real-time control of their tools and monitoring of the patient.
In a typical endoscopy system, the image is digitized at the camera sensor in the endoscope, serialized by an FPGA or ASIC and transmitted to a video processor where it is written to an input frame buffer, processed, written to an output frame buffer, and then transmitted serially to the monitor. Each of these steps adds latency to the video pipeline. Developers who wish to add advanced GPU-accelerated AI processing are then faced with additional transmission latency due to the need to write the data from the video capture card to system memory, then transfer it via the CPU and PCIe bus to the GPU.
GPU compute performance is a key component of the NVIDIA Clara Holoscan platform. To optimize GPU-based video processing applications, NVIDIA has partnered with AJA Video Systems to integrate their line of video capture cards with the Clara AGX Developer Kit. AJA provides a wide range of proven, professional video I/O devices. The partnership between NVIDIA and AJA has led to the addition of Clara AGX Developer Kit support in the AJA NTV2 SDK and device drivers as of the NTV2 SDK 16.1 release.
The AJA drivers and SDK now offer GPUDirect support for NVIDIA GPUs. This feature uses remote direct memory access (RDMA) to transfer video data directly from the capture card to GPU memory. This significantly reduces latency and system PCIe bandwidth for GPU video processing applications, as system memory to GPU copies are eliminated from the processing pipeline.
AJA devices now also incorporate RDMA support into the AJA GStreamer plug-in to enable zero-copy GPU buffer integration with the DeepStream SDK. DeepStream applications can now process video data along the entire pipeline, from the initial capture to final display, without leaving GPU memory.
NVIDIA Clara Holoscan SDK v0.1 builds on the features of the previous Clara AGX SDK and adds tools to allow for detailed measurement of video transfer latency between video I/O cards, the CPU, and the GPU. This will enable users to measure latency with various configurations, allowing them to focus on improving bottlenecks and optimizing their workflows for minimum end-to-end latency.
Data transfer latency was measured using the Clara AGX Developer Kit with an AJA capture card using the internal PCIe Gen3 x8 connection. The following tables demonstrate the latency reduction that can be achieved using GPUDirect.
Format
Width
Height
Bytes/pixel
Frames/sec
720p YUV
1280
720
2
60
1080p YUV
1920
1080
2
60
4K UHD YUV
3840
2160
2
60
720p RGBA
1280
720
4
60
1080p RGBA
1920
1080
4
60
4K UHD RGBA
3840
2160
4
60
Table 1. Results of video formats tested
The total time for video data transfer to and from the GPU, as well as time remaining for processing in the GPU, was then measured with and without GPUDirect enabled:
Format
Without GPUDirect
GPUDirect
Transfer time, no processing (ms)
Time remaining for processing (ms)
Transfer time, no processing (ms)
Time remaining for processing (ms)
720p YUV
1.945
14.721
0.956
15.710
1080p YUV
3.865
12.801
1.723
14.943
4K UHD YUV
12.805
3.861
6.256
10.410
720p RGBA
3.451
13.215
1.548
15.118
1080p YUV
6.816
9.850
3.225
13.444
4K UHD RGBA
23.686
-7.020
12.406
4.260
Table 2. Latency (ms) with and without GPUDirect.
Note that GPUDirect cuts transfer time approximately in half by removing the need for writes to system memory. GPUDirect allows for the transfer and processing of 4K UHD RGBA inputs at 60 fps. This can now be transferred under the 16.666 ms frame time, whereas without GPUDirect this format could not be transferred at 60 fps. This allows for uncompressed high-resolution video to be natively alpha-blended with overlays from AI workflows. There is no need for conversion from YUV to RGBA formats, and no compromise in the 60 fps frame rate.
For instructions on how to set up and use an AJA device with the Clara AGX Developer Kit, including RDMA and DeepStream integration, go to Chapter 9 of the Clara HoloClara Holoscan SDK User Guide.
Learn about the NVIDIA Air platform, a fully functional digital twin of a production environment.
Training resources are always a challenge for IT departments. There is a fine line between letting new team members do more without supervision and keeping the lights on by making sure no mistakes are made in the production environment. Leaning towards the latter method and limiting new team members’ access to production deployments may lead to knowledge gaps. How can new team members learn if they never get time on the network?
To close the knowledge gaps, IT teams can leverage a networking digital twin. A digital twin provides a fully functional replica of a production deployment, so each member of the team can learn in a safe and sandboxed environment. A digital twin eliminates the risk of making mistakes that could materially impact the business. Changes can be implemented and validated in a sandbox environment before pushing any changes to production, providing a new level of confidence.
Train with NVIDIA Air
NVIDIA has such an offering with the Air Infrastructure Simulation Platform (Air). The program supports organizations training their staff by leveraging a digital twin approach and providing a full production experience for all team members. With everyone able to contribute (either by training in Air or working directly in production), IT departments can use staff more effectively and boost operational efficiency.
With the use of NVIDIA Air, IT teams give team members their own replica of the production environment on which to learn. No more waiting for hardware resources to be racked and stacked, or balancing limited lab time across multiple users. Staff can use the platform for free, build an exact network digital twin, validate configurations, confirm security policies, and test CI/CD pipelines. In addition to CLI access, the platform provides full software functionality and access to the core system components such as Docker containers and APIs.
This allows less-skilled team members to be an integral part of the network operation, helping them to catch up with the team’s experience, enhance the sense of belonging within the team, and gain confidence to work on production when the time is right.
Get Started
Air is free to use and easy to work with. Build your own digital twin today, and help your team to learn the production environment, practice procedures, and test changes without introducing risk.

 NVIDIA cuSPARSELt v0.2 now supports ReLu and GeLu activation functions, bias vector, and batched Sparse GEMM.
NVIDIA cuSPARSELt v0.2 now supports ReLu and GeLu activation functions, bias vector, and batched Sparse GEMM.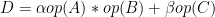
 and
and  refer to in-place operations such as transpose and nontranspose.
refer to in-place operations such as transpose and nontranspose. New nvCOMP v2.1.0 Library with Redesigned Batch API and Performance Optimizations
New nvCOMP v2.1.0 Library with Redesigned Batch API and Performance Optimizations NVIDIA and partners have been working hard to get the NVIDIA Arm HPC Developer Kit units into the hands of developers and enhance the software stack.
NVIDIA and partners have been working hard to get the NVIDIA Arm HPC Developer Kit units into the hands of developers and enhance the software stack.








 AI neural network deep potential to combine classical MD simulation with DFT calculation accuracy.
AI neural network deep potential to combine classical MD simulation with DFT calculation accuracy.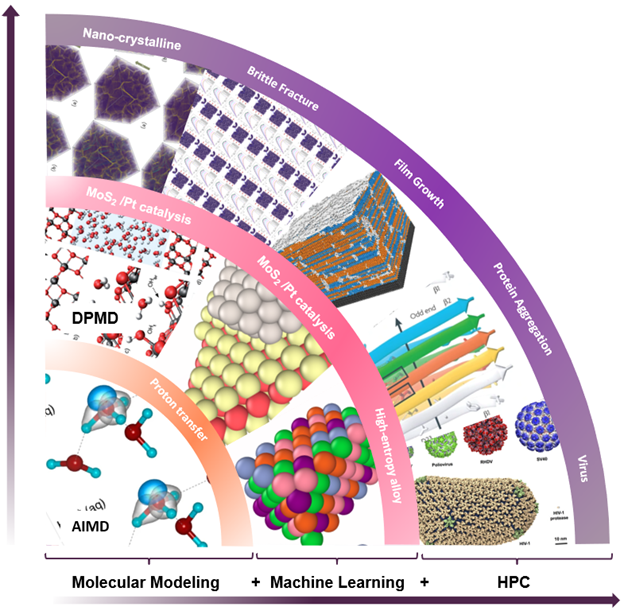

 NVIDIA Clara Holoscan and Clara AGX Developer Kit accelerates development of AI for endoscopy, laparoscopy, and other surgical procedures.
NVIDIA Clara Holoscan and Clara AGX Developer Kit accelerates development of AI for endoscopy, laparoscopy, and other surgical procedures. Learn about the NVIDIA Air platform, a fully functional digital twin of a production environment.
Learn about the NVIDIA Air platform, a fully functional digital twin of a production environment.