hi, i tried to load model on cpu with tf.device while inference of 500 images , the cpu usage resches to 100% , inference time is 0.6sec and how do I minimize the inference time and also the utilization of cpu .
Dive deep into the new features and use cases available for networking, security, storage in the latest release of the DOCA software framework.
Today, NVIDIA released the NVIDIA DOCA 1.2 software framework for NVIDIA BlueField DPUs, the world’s most advanced data processing unit (DPU). Designed to enable the NVIDIA BlueField ecosystem and developer community, DOCA is the key to unlocking the potential of the DPU by offering services to offload, accelerate, and isolate infrastructure applications services from the CPU.
DOCA is a software framework that brings together APIs, drivers, libraries, sample code, documentation, services, and prepackaged containers to simplify and speed up application development and deployment on BlueField DPUs on every data center node. Together, DOCA and BlueField create an isolated and secure services domain for networking, security, storage, and infrastructure management that is ideal for enabling a zero-trust strategy.
The DOCA 1.2 release introduces several important features and use cases.
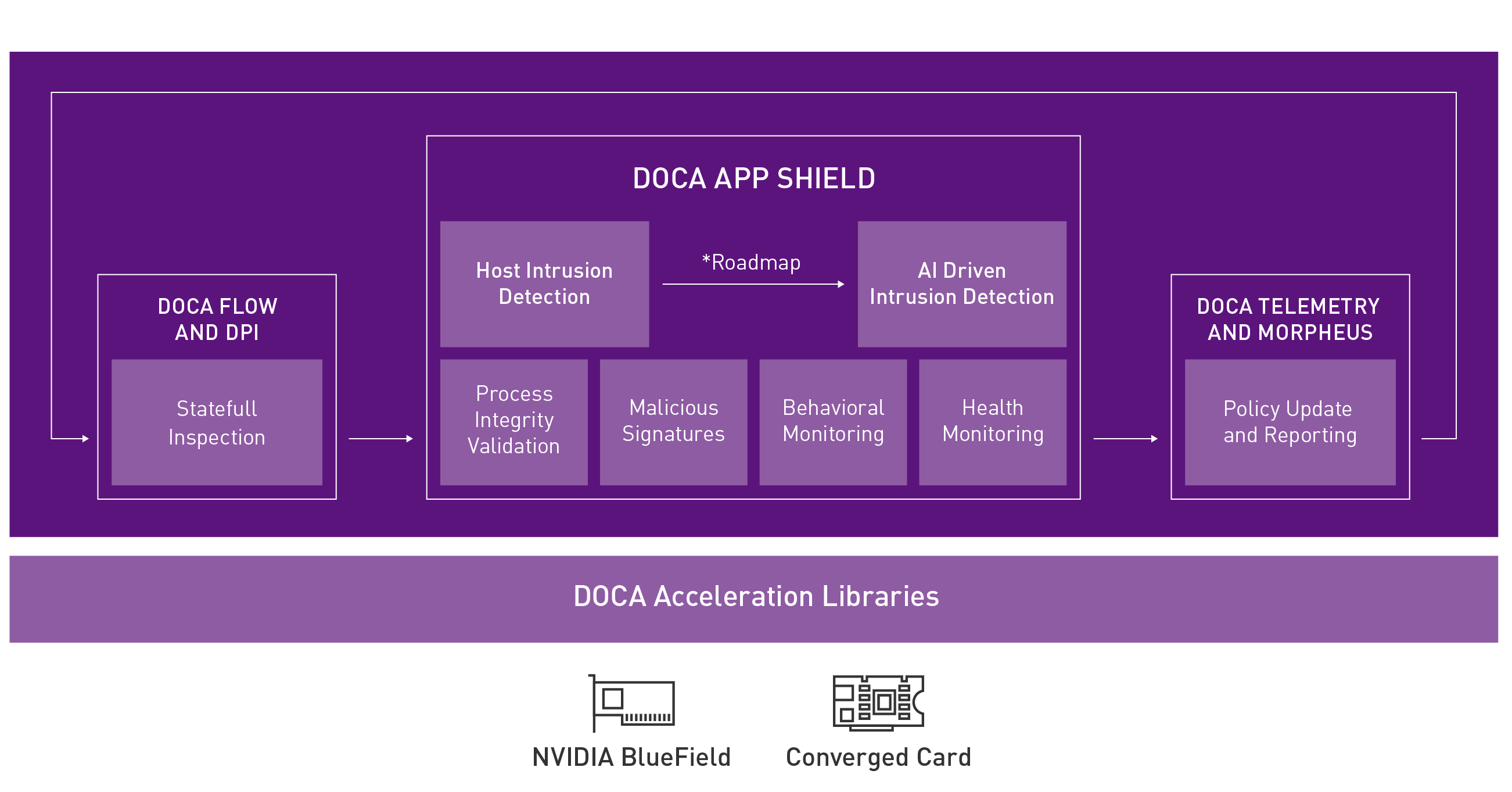
Protect host services with adaptive cloud security
A modern approach to security based on zero trust principles is critical to securing today’s data centers, as resources inside the data center can no longer be trusted automatically. App Shield enables detection of attacks on critical services in a system. In many systems, those critical services are responsible for ensuring the integrity and privacy of the execution of many applications.
Figure 1. Shield your host services with adaptive cloud security
DOCA App Shield provides host monitoring enabling cybersecurity vendors to create accelerated intrusion detection system (IDS) solutions to identify an attack on any physical or virtual machine. It can feed data about application status to security information and event management (SIEM) or extended detection and response (XDR) tools and also enhances forensic investigations.
If a host is compromised, attackers normally exploit the security control mechanism breaches to move laterally across data center networks to other servers and devices. App Shield enables security teams to shield their application processes, continuously validate their integrity, and in turn detect malicious activity.
In the event that an attacker kills the machine security agent’s processes, App Shield can mitigate the attack by isolating the compromised host, preventing the malware from accessing confidential data or spreading to other resources. App Shield is an important advancement in the fight against cybercrime and an effective tool to enable a zero-trust security stance.
BlueField DPUs and the DOCA software framework provide an open foundation for partners and developers to build zero-trust solutions and address the security needs of the modern data center. Together, DOCA and BlueField create an isolated and secure services domain for networking, security, storage, and infrastructure management that is ideal for enabling a zero-trust strategy.
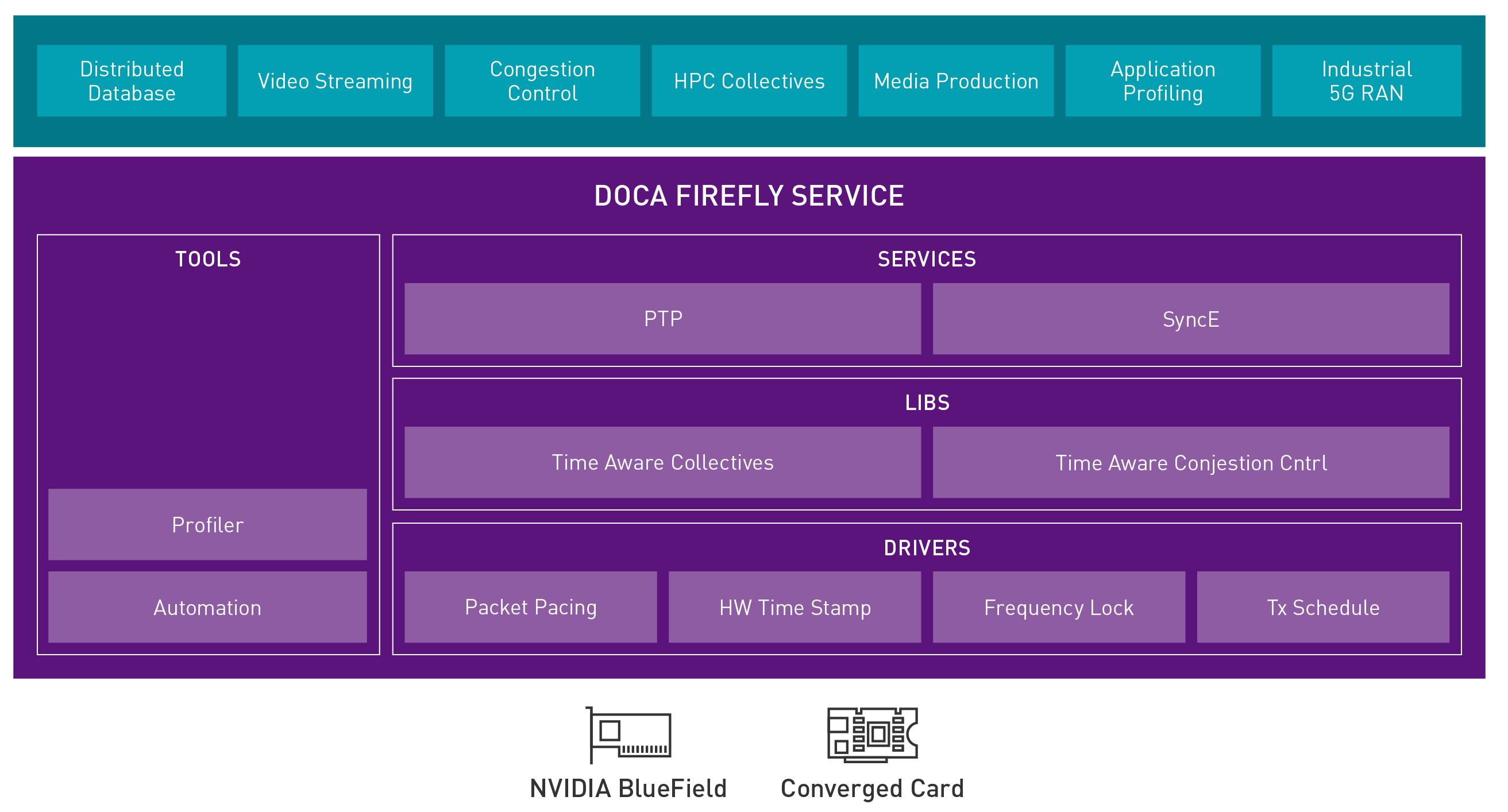
Create time-synchronized data centers
Precision timing is a critical capability to enable and accelerate distributed apps from edge to core. DOCA Firefly is a data center timing service that supports extremely precise time synchronization everywhere. With nanosecond-level clock synchronization, you can enable a new broad range of timing-critical and delay-sensitive applications.
Figure 2. Precision time-synchronized data center service
DOCA Firefly addresses a wide range of use cases, including the following:
High-frequency trading
Distributed databases
Industrial 5G radio access networks (RAN)
Scientific research
High performance computing (HPC)
Omniverse digital twins
Gaming
AR/VR
Autonomous vehicles
Security
It enables data consistency, accurate event ordering, and causality analysis, such as ensuring the correct sequencing of stock market transactions and fair bidding during digital auctions. The hardware engines in the BlueField application-specific integrated circuit (ASIC) are capable of time-stamping data packets at full wire speed with breakthrough nanosecond-level accuracy.
Improving the accuracy of data center timing by orders of magnitude offers many advantages.
With globally synchronized data centers, you can accelerate distributed applications and data analysis including AI, HPC, professional media production, telco virtual network functions, and precise event monitoring. All the servers in the data center—or across data centers—can be harmonized to provide something that is far bigger than any single compute node.
The benefits of improving data center timing accuracy include a reduction in the amount of compute power and network traffic needed to replicate and validate the data. For example, Firefly synchronization delivers a 3x database performance gain to distributed databases.
DOCA HBN beta
The BlueField DPU is a unique solution for network acceleration and policy enforcement within an endpoint host. At the same time, BlueField provides an administrative and software demarcation between the host operating system and functions running on the DPU.
With DOCA host-based networking (HBN), top-of-rack (TOR) network configuration can extend down to the DPU, enabling network administrators to own DPU configuration and management while application management can be handled separately by x86 host administrators. This creates an unparalleled opportunity to reimagine how you can build data center networks.
DOCA 1.2 provides a new driver for HBN called Netlink to DOCA (nl2doca) that accelerates and offloads traditional Linux Netlink messages. nl2doca is provided as an acceleration driver integrated as part of the HBN service container. You can now accelerate host networking for L2 and L3 that relies on DPDK, OVS, or now kernel routing with Netlink.
NVIDIA is adding support for the open-source Free Range Routing (FRR) project, running on the DPU and leveraging this new nl2doca driver. This support enables the DPU to operate exactly like a TOR switch plus additional benefits. FRR on the DPU enables EVPN networks to move directly into the host, providing layer 2 (VLAN) extension and layer 3 (VRF) tenant isolation.
HBN on the DPU can manage and monitor traffic between VMs or containers on the same node. It can also analyze and encrypt or decrypt then analyze traffic to and from the node, both tasks that no ToR switch can perform. You can build your own Amazon VPC-like solution in your private cloud for containerized, virtual machine, and bare metal workloads.
HBN with BlueField DPUs revolutionizes how you build data center networks. It offers the following benefits:
Plug-and-play servers: Leveraging FRR’s BGP unnumbered, servers can be directly connected to the network with no need to coordinate server-to-switch configurations. No need for MLAG, bonding, or NIC teaming.
Open, interoperable multi-tenancy: EVPN enables server-to-server or server-to-switch overlays. This provides multi-tenant solutions for bare metal, closed appliances, or any hypervisor solution, regardless of the underlay networking vendor. EVPN provides distributed overlay configuration, while eliminating the need for costly, proprietary, centralized SDN controllers.
Secure network management: The BlueField DPU provides an isolated environment for network policy configuration and enforcement. There are no software or dependencies on the host.
Enabling advanced HCI and storage networking: BlueField provides a simple method for HCI and storage partners to solve current network challenges for multi-tenant and hybrid cloud solutions, regardless of the hypervisor.
Flexible network offloading: The nl2doca driver provided by HBN enables any netlink capable application to offload and accelerate kernel based networking without the complexities of traditional DPDK libraries.
Simplification of TOR switch requirements: More intelligence is placed on the DPU within the server, reducing the complexity of the TOR switch.
Additional DOCA 1.2 SDK updates:
DOCA FLOW – Firewall (Alpha)
DOCA FLOW – Gateway (Beta)
DOCA FLOW remote APIs
DOCA 1.2 includes enhancements and scale for IPsec and TLS
DLI course: Introduction to DOCA for the BlueField DPU
In addition, NVIDIA is introducing a Deep Learning Institute (DLI) course: Introduction to DOCA for the BlueField DPU. The main objective of this course is to provide students, including developers, researchers, and system administrators, with an introduction to DOCA and BlueField DPUs. This enables students to successfully work with DOCA to create accelerated applications and services powered by BlueField DPUs.
Try DOCA today
You can experience DOCA today with the DOCA software, which includes DOCA SDK and runtime accelerated libraries for networking, storage, and security. The libraries help you program your data center infrastructure running on the DPU.
The DOCA Early Access program is open now for applications. To receive news and updates about DOCA or to become an early access member/partner, register on the DOCA Early Access page.
For more information, see the following resources:
Researchers create a neural network that automatically detects tectonic fault deformation, crucial to understanding and possibly predicting earthquake behavior.
Researchers at Los Alamos National Laboratory in New Mexico are working toward earthquake detection with a new machine learning algorithm capable of global monitoring. The study uses Interferometric Synthetic Aperture Radar (InSAR) satellite data to detect slow-slip earthquakes. The work will help scientists gain a deeper understanding of the interplay between slow and fast earthquakes, which could be key to making future predictions of quake events.
“Applying machine learning to InSAR data gives us a new way to understand the physics behind tectonic faults and earthquakes,” Bertrand Rouet-Leduc, a geophysicist in Los Alamos’ Geophysics group said in a press release. “That’s crucial to understanding the full spectrum of earthquake behavior.”
Discovered a couple of decades ago, slow earthquakes remain a bit of a mystery. They occur at the boundary between plates and can last from days to months without detection due to their slow and quiet nature.
They typically happen in areas where faults are locked due to frictional resistance, and scientists believe they may precede major fast quakes. Japan’s 9.0 magnitude earthquake in 2011, which also caused a tsunami and the Fukushima nuclear disaster, followed two slow earthquakes along the Japan Trench.
Scientists can track earthquake behavior with InSAR satellite data. The radar waves have the benefit of penetrating clouds and also work effectively at night, making it possible to track ground deformation continuously. Comparing radar images over time, researchers can detect ground surface movement.
But these movements are small, and existing approaches limit ground deformation measurements to a few centimeters. Ongoing monitoring of global fault systems also creates massive data streams that are too much to interpret manually.
The researchers created deep learning models addressing both of these limitations. The team trained convolutional neural networks on several million time series of synthetic InSAR data to detect automatically and extract ground deformation.
Using cuDNN-accelerated TensorFlow deep learning framework distributed over multiple NVIDIA GPUs, the new methodology operates without prior knowledge of a fault’s location or slip behavior.
Figure 1. Application to real data shows the North Anatolian Fault 2013 slow earthquake.
To test their approach, they applied the algorithm to a time series built from images of the North Anatolian fault in Turkey. As a major plate boundary fault, the area has ruptured several times in the past century.
With a finer temporal resolution, the algorithm identified previously undetected slippage events, showing that slow earthquakes happen much more often than expected. It also spotted movement as small as two millimeters, something experts would have overlooked due to the subtlety.
“The use of deep learning unlocks the detection on faults of deformation events an order of magnitude smaller than previously achieved manually. Observing many more slow slip events may, in turn, unveil their interaction with regular, dynamic earthquakes, including the potential nucleation of earthquakes with slow deformation,” Rouet-Leduc said.
The team is currently working on a follow-up study, testing a model on the San Andreas Fault that extends roughly 750 miles through California. According to Rouet-Leduc, the model will soon be available on GitHub.
Supply chain shortages are impacting many industries, with semiconductors feeling the crunch in particular. With networking digital twins, you don’t have to wait on the hardware. Get started with infrastructure simulation in NVIDIA Air to stage deployments, test out tools, and enable hardware-free training.
What do Ethernet switches, sports cars, household appliances, and toilet paper have in common? If you read this blog’s title and have lived through the past year and a half, you probably know the answer. These are all products whose availability has been impacted by the materials shortages due to the global pandemic.
In some instances, the supply issues are more of an inconvenience–waiting a few extra months to get that new Corvette won’t be the end of the world. For other products (think toilet paper or a replacement freezer), the supply crunch was and is a big deal.
It is easy to see the impact on consumers, but enterprises feel the pain of long lead times too. Consider Ethernet switches: Ethernet switches build the networking fabric that ties together the data center. Ethernet switch shortages mean more than “rack A is unable to talk to rack B.” They mean decreased aggregate throughput, and increased load on existing infrastructure, leading to more downtime and unplanned outages; that is, significant adverse impacts to business outcomes.
That all sounds bad, but there is no need to panic. NVIDIA can help you mitigate these challenges and transform your operations with a data center digital twin from NVIDIA Air.
So, what is a digital twin, and how is it related to the data center? A digital twin is a software-simulated replica of a real-world thing, system, or process. It constantly reacts and updates any changes to the status of its physical sibling and is always on. A data center digital twin applies the digital twin concept to data center infrastructure. To model the data center itself as a data center and not just a bunch of disparate pizza boxes, it is imperative that the data center digital twin fully simulates the network.
NVIDIA Air is unmatched in providing that capability. The modeling tool in Air enables you to create logical instances of every switch and cable, connecting to logical server instances. In addition to modeling the hardware, NVIDIA Air spins up fully functional virtual appliances with pre-built and fully functional network and server OS images. This is the key ingredient to the digital twin–with an appliance model, the simulation is application-granular.
Benefits
NVIDIA Air enables data center digital twins, but how does that solve supply chain issues? Focusing on those benefits tied to hardware, in particular, it enables:
Hardware-free POCs: Want exposure to the Cumulus Linux or SONiC NOSes? Ordinarily, you would have to acquire the gear to try out the functionality. With NVIDIA Air, you have access to Cumulus VX and SONiC VX–the virtual appliances mentioned above. Because Cumulus and SONiC are built from the ground up on standards-based technologies, you get the full experience without the hardware.
Staging production deployments: Already decided on NVIDIA Ethernet switches? There is no reason to sit on your hands until the pallet of switches arrives. With a digital twin, you can completely map out your data center fabric. You can test your deployment and provisioning scripts and know that they will work seamlessly after the systems have been racked, stacked, and cabled. This can reduce your bring-up time up to 95%.
Testing out new network and application tools: Need to roll out a new networking tool on your Spectrum Ethernet switches? Typically, you would need a prototype pre-production environment. With a digital twin, you deploy the application to the digital twin, validate the impact on your network with NetQ, tweak some settings if necessary, and make deployment to production worry-free.
Hardware-free training: Your organization has decided to bring on someone new to join your networking infrastructure team. They are eager to learn, but there is no hardware set aside for training purposes. Without a digital twin, you and the trainee would be stuck waiting on a new switch order or reading a long and tedious user manual. With the digital twin, you have an always-on sandbox, perfect for skill-building and exploration.
One caveat: data center digital twins will not expedite the date that the RTX 3090 comes back in stock at your favorite retailer, but they will help with the crunch around your networking procurement.
Digital Twins with NVIDIA Air
The best part – if you are curious to learn more, you can do so right now. NVIDIA Air brings the public cloud experience to on-premises networking, making it simple and quick to jump right in. Navigate to NVIDIA Air in your browser and get started immediately.
Hello! I’m a long time developer but new to AI-based image processing. The end goal is to process images from cameras and alert when deer (and eventually other wildlife) is detected.
The first step is finding a decent model that can (say) detect deer vs. birds vs. other animals, then running that somewhere. The default The CameraTraps model here allows detecting “animal” vs. “person” vs. “vehicle”:
Would I need to train it further to differentiate between types of animals, or am I missing something with the default model? Or a more general question, how can you see what a frozen model is set up to detect? (I just learned what a frozen model was yesterday)
Appreciate any pointers or if there’s another sub that would be more suited to getting this project setup, happy to post there instead 🙂
Explore NVIDIA Metropolis partners showcasing new technologies to improve city mobility at the ITS America 2021.
The Intelligent Transportation Society (ITS) of America annual conference brings together a community of intelligent transportation professionals to network, educate others about emerging technologies, and demonstrate innovative products driving the future of efficient and safe transportation.
As cities and DOT teams struggle with constrained roadway infrastructure and the need to build safer roads, events like this offer solutions and reveal a peek into the future. The NVIDIA Metropolis video analytics platform is increasingly being used by cities, DOTs, tollways, and developers to help measure, automate, and vastly improve the efficiency and safety of roadways around the world.
The following NVIDIA Metropolis partners are participating at ITS-America and showcasing how they help cities improve livability and safety.
Miovision: Arguably one of the first in building superhuman levels of computer vision into intersections, Miovison will explain how their technology is transforming traffic intersections, giving cities and towns more effective tools to manage traffic congestion, improving traffic safety, and reducing the impact of traffic on greenhouse gas emissions. Check out Miovision at booth #1619.
NoTraffic: NoTraffic’s real-time, plug-and-play autonomous traffic management platform uses AI and cloud computing to reinvent how cities run their transport networks. The NoTraffic platform is an end-to-end hardware and software solution installed at intersections, transforming roadways to optimize traffic flows and reduce accidents. Check out NoTraffic at booth #1001.
Ouster: Cities are using Ouster digital lidar solutions capable of capturing the environment in minute detail and detecting vehicles, vulnerable road users, and traffic incidents in real time to improve safety and traffic efficiency. Ouster lidar’s 3D spatial awareness and 24/7 performance combine the high-resolution imagery of cameras with the all-weather reliability of radar. Check out Ouster and a live demo at booth #2012.
Parsons: Parsons is a leading technology firm driving the future of smart infrastructure. Parsons develops advanced traffic management systems that cities use to improve safety, mobility, and livability. Check out Parsons at booth #1818.
Velodyne Lidar: Velodyne’s lidar-based Intelligent Infrastructure Solution (IIS) is a complete end-to-end Smart City solution. IIS creates a real-time 3D map of roads and intersections, providing precise traffic and pedestrian safety analytics, road user classification, and smart signal actuation. The solution is deployed in the US, Canada and across EMEA and APAC. Learn more about Velodyne’s on-the-ground deployments at their panel talk.
Register for ITS America, happening December 7-10 in Charlotte, NC.
Learn about the latest updates to NVIDIA TAO, an AI-model-adaptation framework, and NVIDIA TAO toolkit, a CLI and Jupyter notebook-based version of TAO.
All AI applications are powered by models. Models can help spot defects in parts, detect the early onset of disease, translate languages, and much more. But building custom models for a specific use requires mountains of data and an army of data scientists.
NVIDIA TAO, an AI-model-adaptation framework, simplifies and accelerates the creation of AI models. By fine-tuning state-of-the-art, pretrained models, you can create custom, production-ready computer vision and conversational AI models. This can be done in hours rather than months, eliminating the need for large training data or AI expertise.
The latest version of the TAO toolkit is now available for download. The TAO toolkit, a CLI and Jupyter notebook-based version of TAO, brings together several new capabilities to help you speed up your model creation process.
Increased utilization of GPUs for faster, more efficient training.
We are also taking TAO to the next level and making it a lot easier to create custom, production-ready models. A graphical user interface version of TAO is currently under development that epitomizes a zero-code model development solution. This creates the ability to train, adapt, and optimize computer vision and conversational AI models without writing a single line of code.
Early access is slated for early 2022. Sign up today!
Build an action recognition app with pretrained models, the TAO Toolkit, and DeepStream without large training data sets or deep AI expertise.
As humans, we are constantly on the move and performing several actions such as walking, running, and sitting every single day. These actions are a natural extension of our daily lives. Building applications that capture these specific actions can be extremely valuable in the field of sports for analytics, in healthcare for patient safety, in retail for a better shopping experience, and more.
However, building and deploying AI applications that can understand the temporal information of human action is challenging and time-consuming, requiring large amounts of training and deep AI expertise.
In this post, we show how you can fast-track your AI application development by taking a pretrained action recognition model, fine-tuning it with custom data and classes with the NVIDIA TAO Toolkit and deploying it for inference through NVIDIA DeepStream with no AI expertise whatsoever.
Figure 1. End-to-end workflow starting with a pretrained model, fine-tuning with the TAO Toolkit, and deploying it with DeepStream
Action recognition model
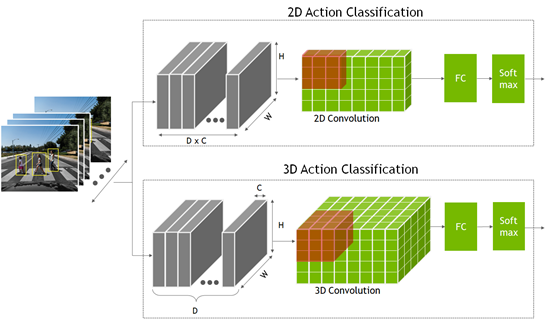
To recognize an action, the network must look at not just a single static frame but several consecutive frames. This provides the temporal context to understand the action. This is the extra temporal dimension compared to a classification or object detection model, where the network only looks at a single static frame.
These models are created using a 2D convolution neural network, where the dimensions are width, height, and number of channels. The 2D action recognition model is like the other 2D computer vision model, but the channel dimension now also contains the temporal information.
In the 2D action recognition model, you multiply the temporal frames D with the channel count C to form the channel dimension input.
For the 3D model, a new dimension, D, is added that represents the temporal information.
The output from both the 2D and 3D convolution networks goes into a fully connected layer, followed by a Softmax layer to predict the action.
Figure 2. Action recognition 2D and 3D convolution network
A pretrained model is one that has been trained on representative datasets and fine-tuned with weights and biases. The action recognition model, available from the NGC catalog, has been trained on five common classes:
Walking
Running
Pushing
Riding a bike
Falling
This is a sample model. More importantly, this model can then be easily retrained with custom data in a fraction of the time and data that it takes to train from scratch.
The pretrained model was trained on a few hundred short video clips from the HMDB51 dataset. For the five classes that the model is trained on, the 2D model achieved accuracy of 83% and the 3D model achieved an accuracy of 86%. Furthermore, the following table shows the expected performance on various GPUs, if you choose to deploy the model as-is.
Inference Performance (FPS)
2DResNet18
3DResNet18
Nano
30
0.6
NVIDIA Xavier NX
250
5
NVIDIA AGX Xavier
490
33
NVIDIA A30
5,809
356
NVIDIA A100
10,457
640
Table 1. Expected inference performance by model
For this experiment, you fine-tune the model with three new classes that consist of simple actions such as pushups, sit-ups, and pull-ups. You use the subset of HMDB51 dataset, which contains 51 different actions.
Prerequisites
Before you start, you must have the following resources for training and deploying:
In this section, you use the TAO Toolkit to fine-tune the model with the new classes.
The TAO Toolkit uses transfer learning, where it uses the learned features from an existing neural network model and applies it to a new one. A CLI and Jupyter notebook–based solution of the NVIDIA TAO framework, the TAO Toolkit abstracts away the AI/DL framework complexity, enabling you to create custom and production-ready models for your use case without any AI expertise.
You can either provide simple directives in the CLI window or use the turnkey Jupyter notebook for training and fine-tuning. You use the action recognition notebook from NGC to train your custom three-class model.
Download the version 1.3 of the TAO Toolkit Computer Vision Sample Workflows and unzip the package. In the /action_recognition_net directory, find the Jupyter notebook (actionrecognitionnet.ipynb) for action recognition training, and the /specs directory, which contains all the spec files for training, evaluation, and model export. You configure these spec files for training.
Start the Jupyter notebook and open the action_recognition_net/actionrecognitionnet.ipynb file:
All the training steps are run inside the Jupyter notebook. After you have started the notebook, run the Set up env variables and map drives and Install TAO launcher steps provided in the notebook.
Step 2: Download the dataset and pretrained model
After you have installed TAO, the next step is to download and prepare the dataset for training. The Jupyter notebook provides the steps to download and preprocess the HMDB51 dataset. If you have your own custom dataset, you can use it in step 2.1.
For this post, you use three classes from the HMDB51 dataset. Modify a few lines to add the push-up, pull-up, and sit-up classes.
$ wget -P $HOST_DATA_DIR http://serre-lab.clps.brown.edu/wp-content/uploads/2013/10/hmdb51_org.rar
$ mkdir -p $HOST_DATA_DIR/videos && unrar x $HOST_DATA_DIR/hmdb51_org.rar $HOST_DATA_DIR/videos
$ mkdir -p $HOST_DATA_DIR/raw_data
$ unrar x $HOST_DATA_DIR/videos/pushup.rar $HOST_DATA_DIR/raw_data
$ unrar x $HOST_DATA_DIR/videos/pullup.rar $HOST_DATA_DIR/raw_data
$ unrar x $HOST_DATA_DIR/videos/situp.rar $HOST_DATA_DIR/raw_data
The video files for each class are stored in their respective directory under $HOST_DATA_DIR/raw_data. These are encoded video files and must be uncompressed to frames to train the model. A script has been provided to help you prepare the data for training.
Download the helper scripts and install the dependency:
$ cd tao_recipes/tao_action_recognition/data_generation/
$ ./preprocess_HMDB_RGB.sh $HOST_DATA_DIR/raw_data $HOST_DATA_DIR/processed_data
The output for each class is shown in the following code example. f cnt: 82 means that this video clip was uncompressed to 82 frames. This action is performed for all the videos in the directory. Depending on the number of classes and size of the dataset and video clips, this process can take some time.
Preprocess pullup
f cnt: 82.0
f cnt: 82.0
f cnt: 82.0
f cnt: 71.0
...
The format of the processed data looks something like the following code example. If you are training on your own data, make sure that your dataset also follows this directory format.
$HOST_DATA_DIR/processed_data/
|-->
|-->
The next step is to split the data into a training and validation set. The HMDB51 dataset provides a split file for each class, so just download that and divide the dataset into 70% training and 30% validation.
Use the helper script split_dataset.py to split the data. This only works with the split file provided with the HMDB dataset. If you are using your own dataset, then this wouldn’t apply.
$ cd tao_recipes/tao_action_recognition/data_generation/
$ python3 ./split_dataset.py $HOST_DATA_DIR/processed_data $HOST_DATA_DIR/splits/testTrainMulti_7030_splits $HOST_DATA_DIR/train $HOST_DATA_DIR/test
Data used for training is under $HOST_DATA_DIR/train and data for test and validation is under $HOST_DATA_DIR/test.
After preparing the dataset, download the pretrained model from NGC. Follow the steps in 2.1 of the Jupyter notebook.
$ ngc registry model download-version "nvidia/tao/actionrecognitionnet:trainable_v1.0" --dest $HOST_RESULTS_DIR/pretrained
Step 3: Configure training parameters
The training parameters are provided in the spec YAML file. In the /specs directory, find all the spec files for training, fine-tuning, evaluation, inference, and export. For training, you use train_rgb_3d_finetune.yaml.
For this experiment, we show you a few hyperparameters that you can modify. For more information about all the different parameters, see ActionRecognitionNet.
You can also overwrite any of the parameters during runtime. Most of the parameters are kept as default. The few that you are changing are highlighted in the following code block.
## Model Configuration
model_config:
model_type: rgb
input_type: "3d"
backbone: resnet18
rgb_seq_length: 32 ## Change from 3 to 32 frame sequence
rgb_pretrained_num_classes: 5
sample_strategy: consecutive
sample_rate: 1
# Training Hyperparameter configuration
train_config:
optim:
lr: 0.001
momentum: 0.9
weight_decay: 0.0001
lr_scheduler: MultiStep
lr_steps: [5, 15, 25]
lr_decay: 0.1
epochs: 20 ## Number of Epochs to train
checkpoint_interval: 1 ## Saves model checkpoint interval
## Dataset configuration
dataset_config:
train_dataset_dir: /data/train ## Modify to use your train dataset
val_dataset_dir: /data/test ## Modify to use your test dataset
## Label maps for new classes. Modify this for your custom classes
label_map:
pushup: 0
pullup: 1
situp: 2
For training, follow step 4 in the Jupyter notebook. Set your environment variables.
The TAO Toolkit task to train action recognition is called action_recognition. To train, use the tao action_recognition train command. Specify the training spec file and provide the output directory and pretrained model. Alternatively, you can also set the pretrained model in the model_config specs.
Depending on your GPU, sequence length or epochs, this can take anywhere from minutes to hours. Because you are saving every epoch, you see as many model checkpoints as the number of epochs.
The model checkpoints are saved as ar_model_epoch=-val_loss=.tlt. Pick the last epoch for model evaluation and export but you can use any that has the lowest validation loss.
Step 5: Evaluate the trained model
There are two different sampling strategies to evaluate the trained model on video clips:
Center mode: Picks up the middle frames of a sequence to do inference. For example, if the model requires 32 frames as input and a video clip has 128 frames, then you choose the frames from index 48 to index 79 to do the inference.
Conv mode: Convolutionally sample 10 sequences out of a single video and do inference. The results are averaged.
For evaluation, use the evaluation spec file (evaluate_rgb.yaml) provided in the /specs directory. This is like the training config. Modify the dataset_config parameter to use the three classes that you are training for.
dataset_config:
## Label maps for new classes. Modify this for your custom classes
label_map:
pushup: 0
pullup: 1
situp: 2
Evaluate using the tao action_recognition evaluate command. For video_eval_mode, you can choose between center mode or conv mode, as explained earlier. Use the last saved model checkpoint from the training run.
This was evaluated on a 90-video dataset, which had clips of all three actions. The overall accuracy is about 82%, which is decent for the size of the dataset. The larger the dataset, the better the model can generalize. You can try to test with your own clips for accuracy.
Step 6: Export for DeepStream deployment
The last step is exporting the model for deployment. To export, run the tao action_recognition export command. You must provide the export specs file, which is included in the /specs directory as export_rgb.yaml. Modify the dataset_config value in the export_rgb.yaml to use the three classes that you trained for. This is like dataset_config in evaluate_rgb.yaml.
$ tao action_recognition export
-e $SPECS_DIR/export_rgb.yaml
-k $KEY
model=$RESULTS_DIR/rgb_3d_ptm/ar_model_epoch=-val_loss=.tlt
/export/rgb_resnet18_3.etlt
Congratulations, you have successfully trained a custom 3D action recognition model. Now, deploy this model using DeepStream.
Deploying with DeepStream
In this section, we show how you can deploy the fine-tuned model using NVIDIA DeepStream.
The DeepStream SDK helps you quickly build efficient, high-performance video AI applications. DeepStream applications can run on edge devices powered by NVIDIA Jetson, on-premises servers, or in the cloud.
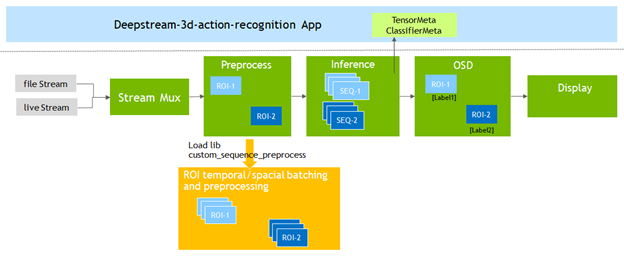
To support action recognition models, DeepStream 6.0 adds the Gst-nvdspreprocess plug-in. This plug-in loads a custom library (custom_sequence_preprocess.so) to perform temporal sequence catching and region of interest (ROI) partial batching and then forward the batched tensor buffers to the downstream inference plug-in.
You modify the deepstream-3d-action-recognition application included in the DeepStream SDK to test the model that you fine-tuned with TAO.
Figure 4. 3D action recognition application pipeline
The sample application runs inference on four video files simultaneously and presents the results with a 2×2 tiled display.
Run the standard application first before you do your modifications. First, start the DeepStream 6.0 development container:
For more information about the DeepStream containers available from NVIDIA, see the NGC catalog.
From within the container, navigate to the 3D action recognition application directory and download and install the standard 3D and 2D models from NGC.
Before modifying the application, familiarize yourself with the key configuration parameters of the preprocessor plug-in required to run the application.
From the /app/sample_apps/deepstream-3d-action-recognition folder, open the config_preprocess_3d_custom.txt file and review the preprocessor configuration for the 3D model.
Line 13 defines the 5-dimension input shape required by the 3D model:
network-input-shape = 4;3;32;224;224
For this application, you are using four inputs each with one ROI:
Your batch number is 4 (# of inputs * # of ROIs per input).
Your input is RGB so the number of channels is 3.
The sequence length is 32 and the input resolution is 224×224 (HxW).
Line 18 tells the preprocessor library that you are using a CUSTOM sequence:
network-input-order = 2
Lines 51 and 52 define how the frames are passed to the inference engine:
stride=1 subsample=0
A subsample value of 0 means that you pass on the frames sequentially (Frame 1, Frame 2, …) to the inference step.
A stride value of 1 means that there is a difference of a single frame between the sequences. For example:
Sequence A: Frame 1, 2, 3, 4, …
Sequence B: Frame 2, 3, 4, 5, …
Finally, lines 55 – 60 define the number of inputs and ROIs:
For more information about all the application and preprocessor parameters, see the Action Recognition section of the DeepStream documentation.
Running the new model
You are now ready to modify your application configuration and test the exercise action recognition model.
Because you’re using a Docker image, the best way to transfer files between the host filesystem and the container is to use the -v mount flag when starting the container to set up a shareable location. For example, use -v /home:/home to mount the host’s /home directory to the /home directory of the container.
Copy the new model, label file, and text video into the /app/sample_apps/deepstream-3d-action-recognition folder.
# back up the original labels file
$ cp ./labels.txt ./labels_bk.txt
$ cp /home/labels.txt ./
$ cp /home/Exercise_demo.mp4 ./
$ cp /home/rgb_resnet18_3d_exercises.etlt ./
Open deepstream_action_recognition_config.txt and change line 30 to point to the exercise test video.
Open config_infer_primary_3d_action.txt and change the model used for inference on line 63 and the batch size on line 68 from 4 to 1 because you are going from four inputs to a single input:
Finally, open config_preprocess_3d_custom.txt. Change the network-input-shape value to reflect the single input and configuration of the exercise recognition model on line 35:
network-input-shape= 1;3;3;224;224
Modify the source settings on lines 77 – 82 for a single input and ROI:
The action recognition sample application gives you the flexibility to change the input source, number of inputs, and model used without having to modify the application source code.
To review how the application was implemented, see the source code for the application, as well as the custom sequence library used by the preprocessor plug-in, in the /sources/apps/sample_apps/deepstream-3d-action-recognition folder.
Summary
In this post, we showed you an end-to-end workflow of fine-tuning and deploying an action recognition model using the TAO Toolkit and DeepStream, respectively. Both the TAO Toolkit and DeepStream are solutions that abstract away the AI framework complexity, enabling you to build and deploy AI applications in production without the need for any AI expertise.
Get started with your action recognition model by downloading the model from the NGC catalog.
For more information, see the following resources:
Learn about TensorRT 8.2 and the new TensorRT framework integrations, which accelerate inference in PyTorch and TensorFlow with just one line of code.
Today NVIDIA released TensorRT 8.2, with optimizations for billion parameter NLU models. These include T5 and GPT-2, used for translation and text generation, making it possible to run NLU apps in real time.
TensorRT is a high-performance deep learning inference optimizer and runtime that delivers low latency, high-throughput inference for AI applications. TensorRT is used across several industries including healthcare, automotive, manufacturing, internet/telecom services, financial services, and energy.
PyTorch and TensorFlow are the most popular deep learning frameworks having millions of users. The new TensorRT framework integrations now provide a simple API in PyTorch and TensorFlow with powerful FP16 and INT8 optimizations to accelerate inference by up to 6x.
Highlights include
TensorRT 8.2: Optimizations for T5 and GPT-2 run real-time translation and summarization with 21x faster performance compared to CPUs.
TensorRT 8.2: Simple Python API for developers using Windows.
Torch-TensorRT: Integration for PyTorch delivers up to 6x performance vs in-framework inference on GPUs with just one line of code.
TensorFlow-TensorRT: Integration of TensorFlow with TensorRT delivers up to 6x faster performance compared to in-framework inference on GPUs with one line of code.
Resources
Torch-TensorRT is available today in the PyTorch Container from the NGC catalog.
TensorFlow-TensorRT is available today in the TensorFlow Container from the NGC catalog.

 Researchers create a neural network that automatically detects tectonic fault deformation, crucial to understanding and possibly predicting earthquake behavior.
Researchers create a neural network that automatically detects tectonic fault deformation, crucial to understanding and possibly predicting earthquake behavior.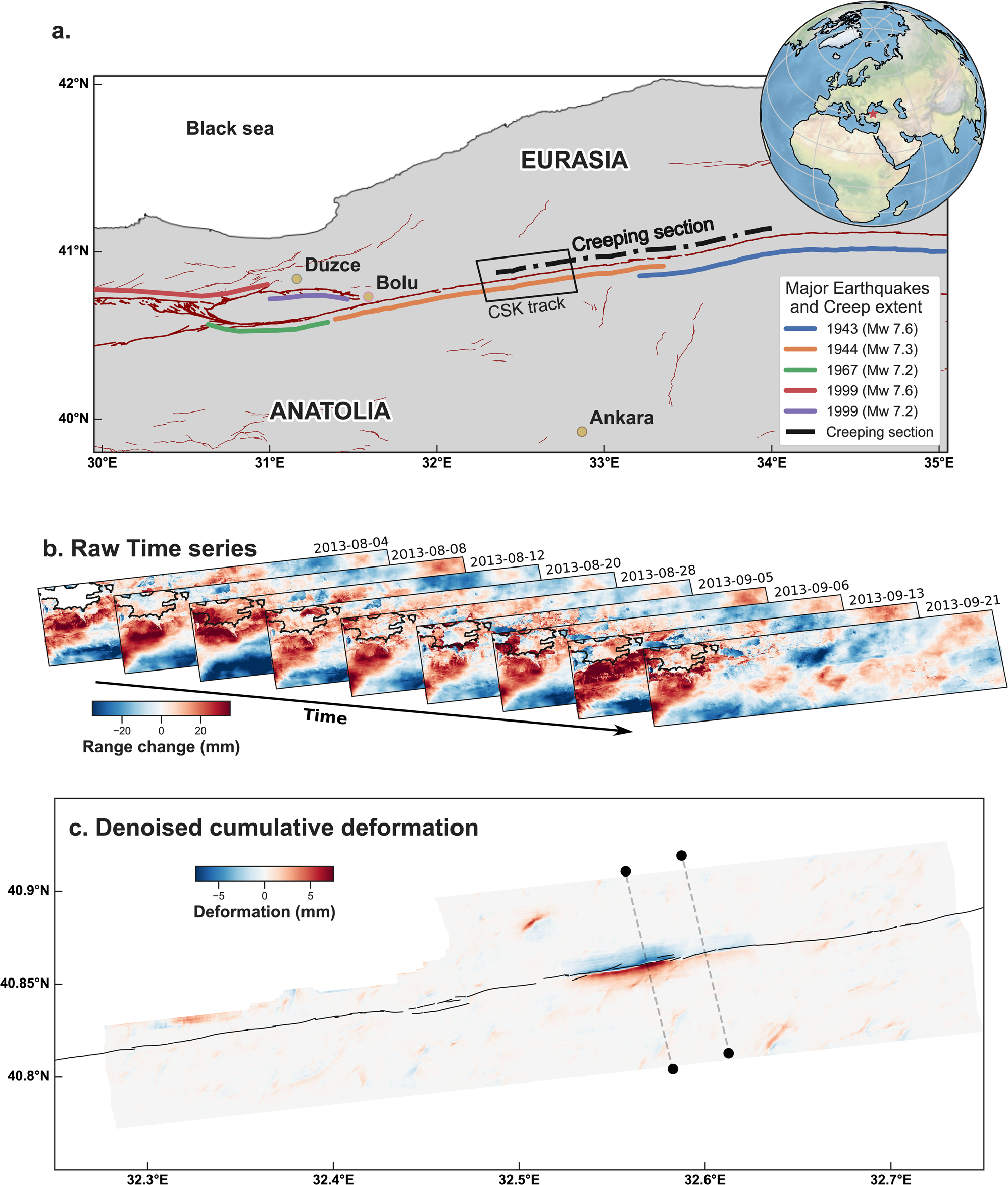
 Supply chain shortages are impacting many industries, with semiconductors feeling the crunch in particular. With networking digital twins, you don’t have to wait on the hardware. Get started with infrastructure simulation in NVIDIA Air to stage deployments, test out tools, and enable hardware-free training.
Supply chain shortages are impacting many industries, with semiconductors feeling the crunch in particular. With networking digital twins, you don’t have to wait on the hardware. Get started with infrastructure simulation in NVIDIA Air to stage deployments, test out tools, and enable hardware-free training.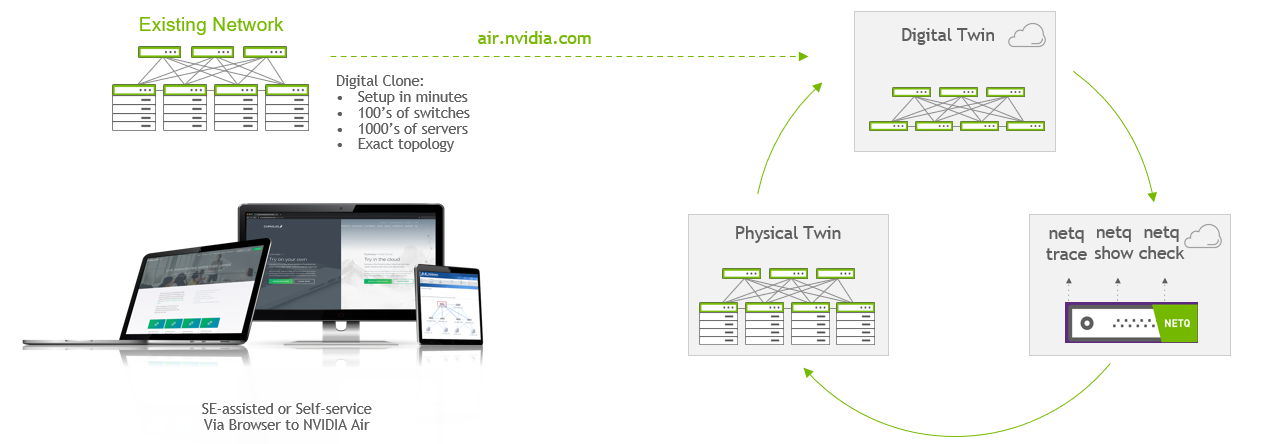



 Explore NVIDIA Metropolis partners showcasing new technologies to improve city mobility at the ITS America 2021.
Explore NVIDIA Metropolis partners showcasing new technologies to improve city mobility at the ITS America 2021.
 Learn about the latest updates to NVIDIA TAO, an AI-model-adaptation framework, and NVIDIA TAO toolkit, a CLI and Jupyter notebook-based version of TAO.
Learn about the latest updates to NVIDIA TAO, an AI-model-adaptation framework, and NVIDIA TAO toolkit, a CLI and Jupyter notebook-based version of TAO. Build an action recognition app with pretrained models, the TAO Toolkit, and DeepStream without large training data sets or deep AI expertise.
Build an action recognition app with pretrained models, the TAO Toolkit, and DeepStream without large training data sets or deep AI expertise.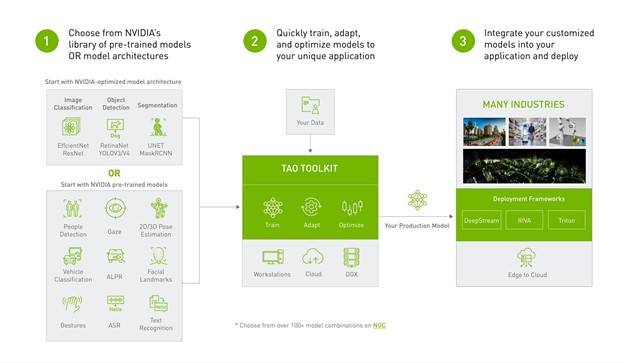


 Learn about TensorRT 8.2 and the new TensorRT framework integrations, which accelerate inference in PyTorch and TensorFlow with just one line of code.
Learn about TensorRT 8.2 and the new TensorRT framework integrations, which accelerate inference in PyTorch and TensorFlow with just one line of code.