The NVIDIA Network Operator includes an RDMA Shared Device Plug-In and OFED Driver.
The NVIDIA Network Operator includes an RDMA Shared Device Plug-In and OFED Driver.
The NVIDIA GPU Operator has NVIDIA GPU Monitoring, NVIDIA Container Runtime, NVIDIA Driver, and NVIDIA Kubernetes Device Plug-In.
When deployed together, they automatically enable the GPU Direct RDMA Driver.
The NVIDIA EGX Operators are part of the NVIDIA EGX stack which contain Kubernetes, Container engine and Linux Distribution. They run bare metal virtualization.
This is the second post in a two part series.
The first post described how to integrate the NVIDIA GPU and Network Operators using preinstalled drivers.
This post describes the following tasks:
- Clean up preinstalled driver integrations
- Installing the Network Operator with a custom driver container
- Installing the GPU Operator with a custom driver container
NVIDIA Driver integration
The preinstalled driver integration method is suitable for edge deployments requiring signed drivers for secure and measured boot. Use the driver container method when the edge node has an immutable operating system. Driver containers are also appropriate when not all edge nodes have accelerators.
Clean up preinstalled driver integration
First, uninstall the previous configuration and reboot to clear the preinstalled drivers.
- Delete the test pods and network attachment.
$ kubectl delete pod roce-shared-pod
pod "roce-shared-pod" deleted
$ kubectl delete macvlannetwork roce-shared-macvlan-network
macvlannetwork.mellanox.com "roce-shared-macvlan-network" deleted
- Uninstall the Network Operator Helm chart.
$ helm delete -n network-operator network-operator
release "network-operator" uninstalled
3. Uninstall MOFED to remove the preinstalled drivers and libraries.
$ rmmod nvidia_peermem
$ /etc/init.d/openibd stop
Unloading HCA driver: [ OK ]
$ cd ~/MLNX_OFED_LINUX-5.4-1.0.3.0-rhel7.9-x86_64
$ ./uninstall.sh
4. Remove the GPU test pod.
$ kubectl delete pod cuda-vectoradd
pod "cuda-vectoradd" deleted
5. Uninstall the NVIDIA Linux driver.
$ ./NVIDIA-Linux-x86_64-470.57.02.run --uninstall
6. Remove GPU Operator.
$ helm uninstall gpu-operator-1634173044
7. Reboot.
$ sudo shutdown -r now
Install the Network Operator with a custom driver container
This section describes the steps for installing the Network Operator with a custom driver container.
The driver build script executed in the container image needs access to kernel development and packages for the target kernel. In this example the kernel development packages are provided through an Apache web server.
Once the container is built, upload it to a repository the Network Operator Helm chart can access from the host.
The GPU Operator will use the same web server to build the custom GPU Operator driver container in the next section.
- Install the Apache web server and start it.
$ sudo firewall-cmd --state
not running
$ sudo yum install createrepo yum-utils httpd -y
$ systemctl start httpd.service && systemctl enable httpd.service && systemctl status httpd.service
● httpd.service - The Apache HTTP Server
Loaded: loaded (/usr/lib/systemd/system/httpd.service; enabled; vendor preset: disabled)
Active: active (running) since Wed 2021-10-20 18:10:43 EDT; 4h 45min ago
...
- Create a mirror of the upstream CentOS 7 Base package repository. It could take ten minutes or more to download all the CentOS Base packages to the web server. Note that the custom package repository requires 500 GB free space on the /var partition.
$ cd /var/www/html
$ mkdir -p repos/centos/7/x86_64/os
$ reposync -p /var/www/html/repos/centos/7/x86_64/os/ --repo=base --download-metadata -m
3. Copy the Linux kernel source files into the Base packages directory on the web server. This example assumes the custom kernel was compiled as an RPM using rpmbuild.
$ cd repos/centos/7/x86_64/os
$ sudo cp ~/rpmbuild/RPMS/x86_64/*.rpm .
The Network Operator requires the following files:
- kernel-headers-${KERNEL_VERSION}
- kernel-devel-${KERNEL_VERSION}
Ensure the presence of these additional files for the GPU Operator:
- gcc-${GCC_VERSION}
- elfutils-libelf.x86_64
- elfutils-libelf-devel.x86_64
$ for i in $(rpm -q kernel-headers kernel-devel elfutils-libelf elfutils-libelf-devel gcc | grep -v "not installed"); do ls $i*; done
kernel-headers-3.10.0-1160.42.2.el7.custom.x86_64.rpm
kernel-devel-3.10.0-1160.42.2.el7.custom.x86_64.rpm
elfutils-libelf-0.176-5.el7.x86_64.rpm
elfutils-libelf-devel-0.176-5.el7.x86_64.rpm
gcc-4.8.5-44.el7.x86_64.rpm
4. Browse to the web repository to make sure it is accessible via HTTP.
$ elinks http://localhost/repos/centos/7/x86_64/os --dump
Index of /repos/centos/7/x86_64/os
[1][ICO] [2]Name [3]Last modified [4]Size [5]Description
--------------------------------------------------------------------------
[6][PARENTDIR] [7]Parent Directory -
[8][DIR] [9]base/ 2021-10-21 22:55 -
[10][DIR] [11]extras/ 2021-10-02 00:29 -
--------------------------------------------------------------------------
References
Visible links
2. http://localhost/repos/centos/7/x86_64/os/?C=N;O=D
3. http://localhost/repos/centos/7/x86_64/os/?C=M;O=A
4. http://localhost/repos/centos/7/x86_64/os/?C=S;O=A
5. http://localhost/repos/centos/7/x86_64/os/?C=D;O=A
7. http://localhost/repos/centos/7/x86_64/
9. http://localhost/repos/centos/7/x86_64/os/base/
11. http://localhost/repos/centos/7/x86_64/os/extras/
5. MOFED driver container images are built from source code in the mellanox/ofed-docker repository on Github. Clone the ofed-docker repository.
$ git clone https://github.com/Mellanox/ofed-docker.git
$ cd ofed-docker/
6. Make a build directory for the custom driver container.
$ mkdir centos
$ cd centos/
7. Create a Dockerfile that installs the MOFED dependencies and source archive into a CentOS 7.9 base image. Specify the MOFED and CentOS versions.
$ sudo cat
8. Modify the RHEL entrypoint.sh script included in the ofed-docker repository to install the custom kernel source packages from the web server. Specify the path to the base/Packages directory on the web server in the _install_prerequsities() function.
In this example 10.150.168.20 is the web server IP address created earlier in the section.
$ cp ../rhel/entrypoint.sh .
$ cat entrypoint.sh
...
# Install the kernel modules header/builtin/order files and generate the kernel version string.
_install_prerequisites() {
echo "Installing dependencies"
yum -y --releasever=7 install createrepo elfutils-libelf-devel kernel-rpm-macros numactl-libs initscripts grubby linux-firmware libtool
echo "Installing Linux kernel headers..."
rpm -ivh http://10.150.168.20/repos/centos/7/x86_64/os/base/Packages/kernel-3.10.0-1160.45.1.el7.custom.x86_64.rpm
rpm -ivh http://10.150.168.20/repos/centos/7/x86_64/os/base/Packages/kernel-devel-3.10.0-1160.45.1.el7.custom.x86_64.rpm
rpm -ivh http://10.150.168.20/repos/centos/7/x86_64/os/base/Packages/kernel-headers-3.10.0-1160.45.1.el7.custom.x86_64.rpm
# Prevent depmod from giving a WARNING about missing files
touch /lib/modules/${KVER}/modules.order
touch /lib/modules/${KVER}/modules.builtin
depmod ${KVER}
...
9. The OFED driver container mounts a directory from the host file system for sharing driver files. Create the directory.
$ mkdir -p /run/mellanox/drivers
10. Upload the new CentOS driver image to a registry. This example uses an NGC private registry. Login to the registry.
$ sudo yum install -y podman
$ sudo podman login nvcr.io
Username: $oauthtoken
Password: *****************************************
Login Succeeded!
11. Use Podman to build the driver container image and push it to the registry.
$ sudo podman build --no-cache --tag nvcr.io/nv-ngc5g/mofed-5.4-1.0.3.0:centos7-amd64 .
12. Tag the image and push it to the registry.
$ sudo podman images nvcr.io | grep mofed
nvcr.io/nv-ngc5g/mofed-5.4-1.0.3.0 centos7-amd64 d61e555bddda 2 minutes ago 1.13 GB
13. Override the values.yaml file included in the NVIDIA Network Operator Helm chart to install the custom driver image. Specify the image name, repository, and version for the custom driver container.
$ cat
14. Install the NVIDIA Network Operator with the new values.yaml.
$ helm install -f ./roce_shared_values_driver.yaml -n network-operator --create-namespace --wait network-operator mellanox/network-operator
15. View the pods deployed by the Network Operator. The MOFED pod should be in status Running. This is the custom driver container. Note that it may take several minutes to compile the drivers before starting the pod.
$ kubectl -n nvidia-network-operator-resources get pods
NAME READY STATUS RESTARTS AGE
cni-plugins-ds-zr9kf 1/1 Running 0 10m
kube-multus-ds-w57rz 1/1 Running 0 10m
mofed-centos7-ds-cbs74 1/1 Running 0 10m
rdma-shared-dp-ds-ch8m2 1/1 Running 0 2m27s
whereabouts-z947f 1/1 Running 0 10m
16. Verify that the MOFED drivers are loaded on the host.
$ lsmod | egrep '^ib|^mlx|^rdma'
rdma_ucm 27022 0
rdma_cm 65212 1 rdma_ucm
ib_ipoib 124872 0
ib_cm 53085 2 rdma_cm,ib_ipoib
ib_umad 27744 0
mlx5_ib 384793 0
mlx5_core 1360822 1 mlx5_ib
ib_uverbs 132833 2 mlx5_ib,rdma_ucm
ib_core 357959 8 rdma_cm,ib_cm,iw_cm,mlx5_ib,ib_umad,ib_uverbs,rdma_ucm,ib_ipoib
mlx_compat 55063 11 rdma_cm,ib_cm,iw_cm,auxiliary,mlx5_ib,ib_core,ib_umad,ib_uverbs,mlx5_core,rdma_ucm,ib_ipoib
mlxfw 22321 1 mlx5_core
17. The root filesystem of the driver container should be bind mounted to the /run/mellanox/drivers directory on the host.
$ ls /run/mellanox/drivers
anaconda-post.log bin boot dev etc home host lib lib64 media mnt opt proc root run sbin srv sys tmp usr var
Install the GPU Operator with a custom driver container
This section describes the steps for installing the GPU Operator with a custom driver container.
Like the Network Operator, the driver build script executed by the GPU Operator container needs access to development packages for the target kernel.
This example uses the same web server that delivered development packages to the Network Operator in the previous section.
Once the container is built, upload it to a repository the GPU Operator Helm chart can access from the host. Like the Network Operator example, the GPU Operator also uses the private registry on NGC.
- Build a custom driver container.
$ cd ~
$ git clone https://gitlab.com/nvidia/container-images/driver.git
$ cd driver/centos7
2. Update the CentOS Dockerfile to use driver version 470.74. Comment out unused arguments.
$ grep ARG Dockerfile
ARG BASE_URL=http://us.download.nvidia.com/XFree86/Linux-x86_64
#ARG BASE_URL=https://us.download.nvidia.com/tesla
ARG DRIVER_VERSION=470.74
ARG DRIVER_TYPE=passthrough
ARG VGPU_LICENSE_SERVER_TYPE=FNE
ARG PUBLIC_KEY=''
#ARG PUBLIC_KEY=empty
ARG PRIVATE_KEY
3. Build the GPU driver container image and push it to NGC.
$ sudo podman build --no-cache --tag nvcr.io/nv-ngc5g/driver:470.74-centos7 .
4. View the GPU driver container image.
$ podman images nvcr.io | grep 470
nvcr.io/nv-ngc5g/driver 470.74-centos7 630f0f8e77f5 2 minutes ago 1.28 GB
5. Verify that the following files are available in the custom repository created for the Network Operator installation:
- elfutils-libelf.x86_64
- elfutils-libelf-devel.x86_64
- kernel-headers-${KERNEL_VERSION}
- kernel-devel-${KERNEL_VERSION}
- gcc-${GCC_VERSION}
These files are needed to compile the driver for the custom kernel image.
$ cd /var/www/html/repos/centos/7/x86_64/os/base/Packages/
$ for i in $(rpm -q kernel-headers kernel-devel elfutils-libelf elfutils-libelf-devel gcc | grep -v "not installed"); do ls $i*; done
kernel-headers-3.10.0-1160.45.1.el7.custom.x86_64.rpm
kernel-devel-3.10.0-1160.45.1.el7.custom.x86_64.rpm
elfutils-libelf-0.176-5.el7.x86_64.rpm
elfutils-libelf-devel-0.176-5.el7.x86_64.rpm
gcc-4.8.5-44.el7.x86_64.rpm
6. Unlike the Network Operator, the GPU Operator uses a custom Yum repository configuration file. Create a Yum repo file referencing the custom mirror repository.
$ cd /var/www/html/repos
$ cat
7. The GPU Operator uses a Kubernetes ConfigMap to configure the custom repository. The ConfigMap must be available in the gpu-operator-resources namespace. Create the namespace and the ConfigMap.
$ kubectl create ns gpu-operator-resources
$ kubectl create configmap repo-config -n gpu-operator-resources --from-file=/var/www/html/repos/custom-repo.repo
configmap/repo-config created
$ kubectl describe cm -n gpu-operator-resources repo-config
Name: repo-config
Namespace: gpu-operator-resources
Labels:
Annotations:
Data
====
custom-repo.repo:
----
[base]
name=CentOS Linux $releasever - Base
baseurl=http://10.150.168.20/repos/centos/$releasever/$basearch/os/base/
gpgcheck=0
enabled=1
8. Install the GPU Operator Helm chart. Specify the custom repository location, the custom driver version, and the custom driver image name and location.
$ helm install nvidia/gpu-operator --generate-name --set driver.repoConfig.configMapName=repo-config --set driver.repoConfig.destinationDir=/etc/yum.repos.d --set driver.image=driver --set driver.repository=nvcr.io/nv-ngc5g --set-string driver.version="470.74" --set toolkit.version=1.7.1-centos7 --set operator.defaultRuntime=crio
9. View the deployed pods.
$ kubectl get pods -n gpu-operator-resources
NAME READY STATUS RESTARTS AGE
gpu-feature-discovery-r6kq6 1/1 Running 0 3m33s
nvidia-container-toolkit-daemonset-62pbj 1/1 Running 0 3m33s
nvidia-cuda-validator-ljd5l 0/1 Completed 0 119s
nvidia-dcgm-9nsfx 1/1 Running 0 3m33s
nvidia-dcgm-exporter-zm82v 1/1 Running 0 3m33s
nvidia-device-plugin-daemonset-bp66r 1/1 Running 0 3m33s
nvidia-device-plugin-validator-8pbmv 0/1 Completed 0 108s
nvidia-driver-daemonset-4tx24 1/1 Running 0 3m33s
nvidia-mig-manager-kvcgc 1/1 Running 0 3m32s
nvidia-operator-validator-g9xz5 1/1 Running 0 3m33s
10. Verify the driver is loaded.
$ lsmod | grep nvidia
nvidia_modeset 1195268 0
nvidia_uvm 995356 0
nvidia 35237551 114 nvidia_modeset,nvidia_uvm
drm 456166 5 ast,ttm,drm_kms_helper,nvidia
11. Run nvidia-smi from the driver daemonset pod.
Defaulted container "nvidia-driver-ctr" out of: nvidia-driver-ctr, k8s-driver-manager (init)
Thu Oct 28 02:37:50 2021
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 470.74 Driver Version: 470.74 CUDA Version: 11.4 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA A100-PCI... On | 00000000:23:00.0 Off | 0 |
| N/A 25C P0 32W / 250W | 0MiB / 40536MiB | 0% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
| 1 NVIDIA A100-PCI... On | 00000000:E6:00.0 Off | 0 |
| N/A 27C P0 32W / 250W | 0MiB / 40536MiB | 0% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
The NVIDIA peer memory driver that enables GPUDirect RDMA is not built automatically.
Repeat this process to build a custom nvidia-peermem driver container.
This additional step is needed for any Linux operating system that the nvidia-peermem installer in GPU Operator does not yet support.
The future with NVIDIA Accelerators
NVIDIA accelerators help future-proof an edge AI investment against the exponential growth of sensor data. NVIDIA operators are cloud native software that streamline accelerator deployment and management on Kubernetes. The operators support popular Kubernetes platforms out of the box and can be customized to support alternative platforms.
Recently, NVIDIA announced converged accelerators that combine DPU and GPU capability onto a single PCI device. The converged accelerators are ideal for edge AI applications with demanding compute and network performance requirements. The NVIDIA operators are being enhanced to facilitate converged accelerator deployment on Kubernetes.
Both the NVIDIA GPU Operator and Network Operator are open source software projects published under the Apache 2.0 license. NVIDIA welcomes upstream participation for both projects.
Register for GTC 2021 session, Exploring Cloud-native Edge AI, to learn more about accelerating edge AI with NVIDIA GPUs and SmartNICs.



 Learn how AI-enabled video analytics is helping companies and employees work smarter and safer.
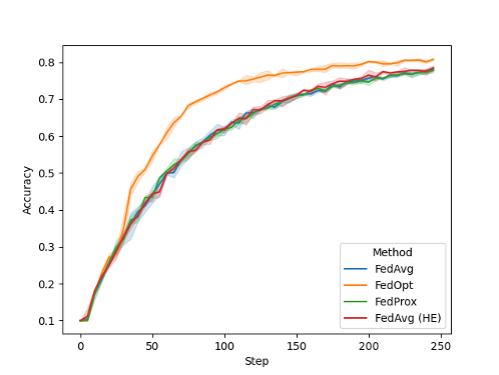
Learn how AI-enabled video analytics is helping companies and employees work smarter and safer. ") NVIDIA FLARE v2.0 is an open-source federated learning SDK that is making it easier for data scientists to collaborate to develop more generalizable robust AI models by just sharing model weights rather than private data.
NVIDIA FLARE v2.0 is an open-source federated learning SDK that is making it easier for data scientists to collaborate to develop more generalizable robust AI models by just sharing model weights rather than private data.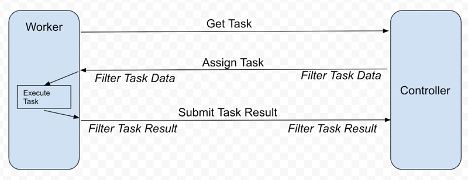
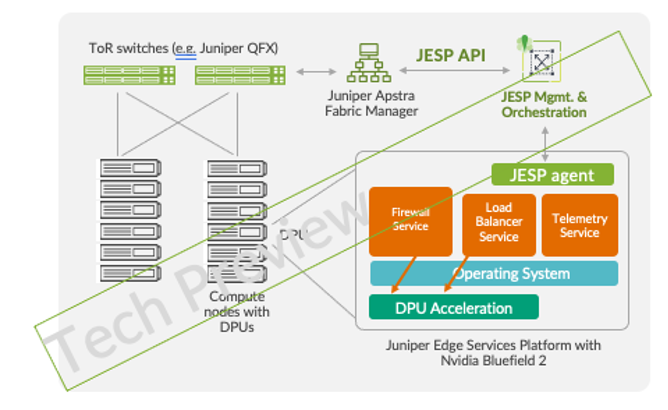
 Learn how these Industry leaders have started to integrate their solutions using the DPU/DOCA architecture as key partners showcase these solutions at the recent NVIDIA GTC.
Learn how these Industry leaders have started to integrate their solutions using the DPU/DOCA architecture as key partners showcase these solutions at the recent NVIDIA GTC.