Machine learning (ML) has become prominent in information technology, which has led some to raise concerns about the associated rise in the costs of computation, primarily the carbon footprint, i.e., total greenhouse gas emissions. While these assertions rightfully elevated the discussion around carbon emissions in ML, they also highlight the need for accurate data to assess true carbon footprint, which can help identify strategies to mitigate carbon emission in ML.
In “The Carbon Footprint of Machine Learning Training Will Plateau, Then Shrink”, accepted for publication in IEEE Computer, we focus on operational carbon emissions — i.e., the energy cost of operating ML hardware, including data center overheads — from training of natural language processing (NLP) models and investigate best practices that could reduce the carbon footprint. We demonstrate four key practices that reduce the carbon (and energy) footprint of ML workloads by large margins, which we have employed to help keep ML under 15% of Google’s total energy use.
The 4Ms: Best Practices to Reduce Energy and Carbon Footprints
We identified four best practices that reduce energy and carbon emissions significantly — we call these the “4Ms” — all of which are being used at Google today and are available to anyone using Google Cloud services.
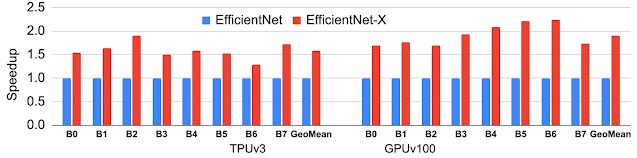
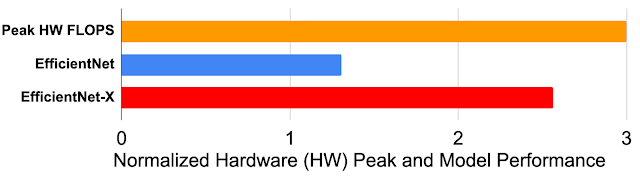
- Model. Selecting efficient ML model architectures, such as sparse models, can advance ML quality while reducing computation by 3x–10x.
- Machine. Using processors and systems optimized for ML training, versus general-purpose processors, can improve performance and energy efficiency by 2x–5x.
- Mechanization. Computing in the Cloud rather than on premise reduces energy usage and therefore emissions by 1.4x–2x. Cloud-based data centers are new, custom-designed warehouses equipped for energy efficiency for 50,000 servers, resulting in very good power usage effectiveness (PUE). On-premise data centers are often older and smaller and thus cannot amortize the cost of new energy-efficient cooling and power distribution systems.
- Map Optimization. Moreover, the cloud lets customers pick the location with the cleanest energy, further reducing the gross carbon footprint by 5x–10x. While one might worry that map optimization could lead to the greenest locations quickly reaching maximum capacity, user demand for efficient data centers will result in continued advancement in green data center design and deployment.
These four practices together can reduce energy by 100x and emissions by 1000x.
Note that Google matches 100% of its operational energy use with renewable energy sources. Conventional carbon offsets are usually retrospective up to a year after the carbon emissions and can be purchased anywhere on the same continent. Google has committed to decarbonizing all energy consumption so that by 2030, it will operate on 100% carbon-free energy, 24 hours a day on the same grid where the energy is consumed. Some Google data centers already operate on 90% carbon-free energy; the overall average was 61% carbon-free energy in 2019 and 67% in 2020.
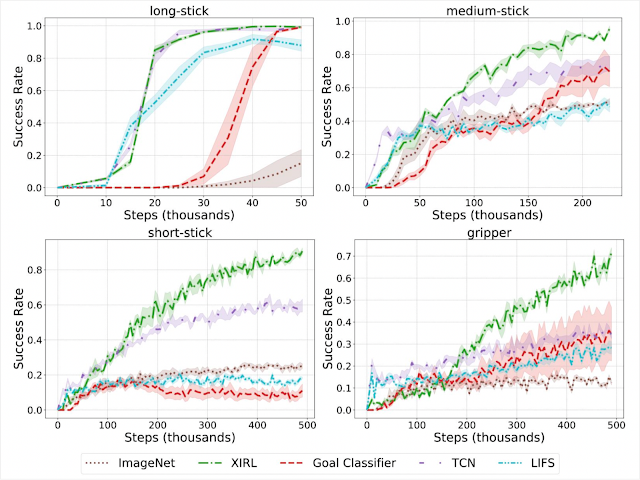
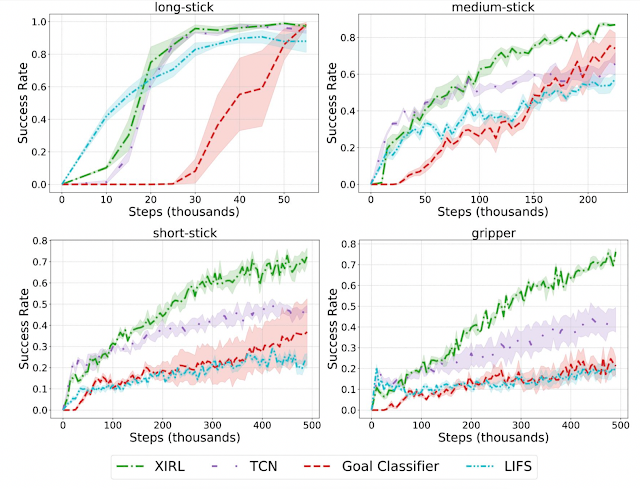
Below, we illustrate the impact of improving the 4Ms in practice. Other studies examined training the Transformer model on an Nvidia P100 GPU in an average data center and energy mix consistent with the worldwide average. The recently introduced Primer model reduces the computation needed to achieve the same accuracy by 4x. Using newer-generation ML hardware, like TPUv4, provides an additional 14x improvement over the P100, or 57x overall. Efficient cloud data centers gain 1.4x over the average data center, resulting in a total energy reduction of 83x. In addition, using a data center with a low-carbon energy source can reduce the carbon footprint another 9x, resulting in a 747x total reduction in carbon footprint over four years.
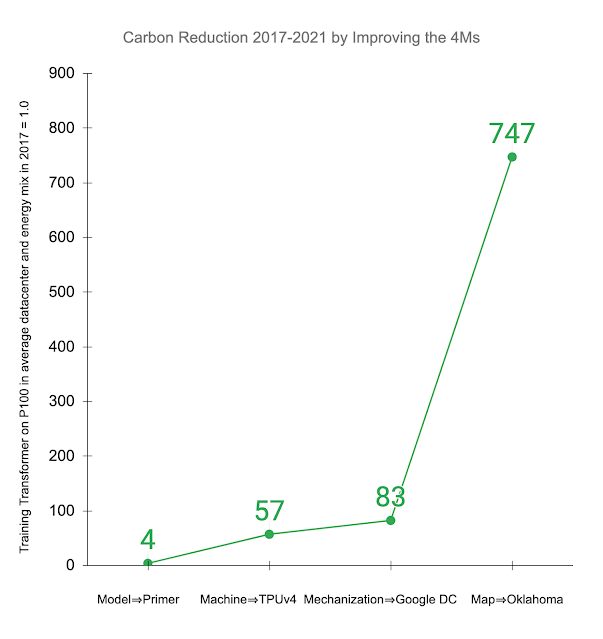 |
| Reduction in gross carbon dioxide equivalent emissions (CO2e) from applying the 4M best practices to the Transformer model trained on P100 GPUs in an average data center in 2017, as done in other studies. Displayed values are the cumulative improvement successively addressing each of the 4Ms: updating the model to Primer; upgrading the ML accelerator to TPUv4; using a Google data center with better PUE than average; and training in a Google Oklahoma data center that uses very clean energy. |
Overall Energy Consumption for ML
Google’s total energy usage increases annually, which is not surprising considering increased use of its services. ML workloads have grown rapidly, as has the computation per training run, but paying attention to the 4Ms — optimized models, ML-specific hardware, efficient data centers — has largely compensated for this increased load. Our data shows that ML training and inference are only 10%–15% of Google’s total energy use for each of the last three years, each year split ⅗ for inference and ⅖ for training.
Prior Emission Estimates
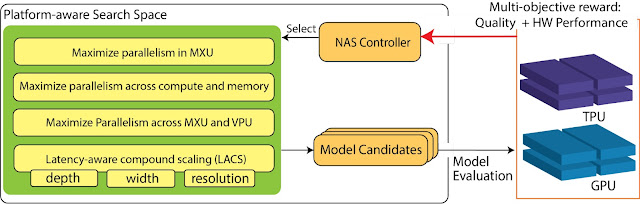
Google uses neural architecture search (NAS) to find better ML models. NAS is typically performed once per problem domain/search space combination, and the resulting model can then be reused for thousands of applications — e.g., the Evolved Transformer model found by NAS is open sourced for all to use. As the optimized model found by NAS is often more efficient, the one time cost of NAS is typically more than offset by emission reductions from subsequent use.
A study from the University of Massachusetts (UMass) estimated carbon emissions for the Evolved Transformer NAS.
- Without ready access to Google hardware or data centers, the study extrapolated from the available P100 GPUs instead of TPUv2s, and assumed US average data center efficiency instead of highly efficient hyperscale data centers. These assumptions increased the estimate by 5x over the energy used by the actual NAS computation that was performed in Google’s data center.
- In order to accurately estimate the emissions for NAS, it’s important to understand the subtleties of how they work. NAS systems use a much smaller proxy task to search for the most efficient models to save time, and then scale up the found models to full size. The UMass study assumed that the search repeated full size model training thousands of times, resulting in emission estimates that are another 18.7x too high.
The overshoot for the NAS was 88x: 5x for energy-efficient hardware in Google data centers and 18.7x for computation using proxies. The actual CO2e for the one-time search were 3,223 kg versus 284,019 kg, 88x less than the published estimate.
Unfortunately, some subsequent papers misinterpreted the NAS estimate as the training cost for the model it discovered, yet emissions for this particular NAS are ~1300x larger than for training the model. These papers estimated that training the Evolved Transformer model takes two million GPU hours, costs millions of dollars, and that its carbon emissions are equivalent to five times the lifetime emissions of a car. In reality, training the Evolved Transformer model on the task examined by the UMass researchers and following the 4M best practices takes 120 TPUv2 hours, costs $40, and emits only 2.4 kg (0.00004 car lifetimes), 120,000x less. This gap is nearly as large as if one overestimated the CO2e to manufacture a car by 100x and then used that number as the CO2e for driving a car.
Outlook
Climate change is important, so we must get the numbers right to ensure that we focus on solving the biggest challenges. Within information technology, we believe these are much more likely the lifecycle costs — i.e., emission estimates that include the embedded carbon emitted from manufacturing all components involved, from chips to data center buildings — of manufacturing computing equipment of all types and sizes1 rather than the operational cost of ML training.
Expect more good news if everyone improves the 4Ms. While these numbers may currently vary across companies, these simple measures can be followed across the industry:
- Data center providers should publish data center efficiency and the cleanliness of the energy supply per location so that customers can understand and reduce their energy consumption and carbon footprint.
- ML practitioners should train models using the best processors in the greenest data centers, which today are often in the Cloud.
- ML researchers should continue to develop more efficient ML models, for example, by leveraging sparsity or by integrating retrieval to shrink the model. They should also publish energy consumption and carbon footprint, both to foster competition beyond model quality and to ensure accurate accounting of their work, which is difficult to do accurately post-hoc.
If the 4Ms become widely recognized, we predict a virtuous circle that will bend the curve so that the global carbon footprint of ML training is actually shrinking, not increasing.
Acknowledgements
Let me thank my co-authors who stayed with this long and winding investigation into a topic that was new to most of us: Jeff Dean, Joseph Gonzalez, Urs Hölzle, Quoc Le, Chen Liang, Lluis-Miquel Munguia, Daniel Rothchild, David So, and Maud Texier. We also had a great deal of help from others along the way for an earlier study that eventually led to this version of the paper. Emma Strubell made several suggestions for the prior paper, including the recommendation to examine the recent giant NLP models. Christopher Berner, Ilya Sutskever, OpenAI, and Microsoft shared information about GPT-3. Dmitry Lepikhin and Zongwei Zhou did a great deal of work to measure the performance and power of GPUs and TPUs in Google data centers. Hallie Cramer, Anna Escuer, Elke Michlmayr, Kelli Wright, and Nick Zakrasek helped with the data and policies for energy and CO2e emissions at Google.
1Worldwide IT manufacturing for 2021 included 1700M cell phones, 340M PCs, and 12M data center servers. ↩