The NVIDIA CloudXR platform will be available on NVIDIA GPU-powered virtual machine instances on Azure.
NVIDIA is raising the bar for XR streaming. Announced today, the NVIDIA CloudXR platform will be available on NVIDIA GPU-powered virtual machine instances on Azure.
NVIDIA CloudXR is built on NVIDIA RTX GPUs to enable streaming of immersive AR, VR or mixed reality experiences from anywhere. By streaming from the cloud, enterprises can easily set up and scale immersive experiences from any location, to any VR or AR device. Companies and customers no longer need to purchase expensive high-performing workstations to experience high-quality, immersive environments.
Delivering High-Fidelity Experiences from the Cloud
NVIDIA partners Innoactive, TechViz, and Vection Technologies are among the first to use CloudXR on Azure instances.
With NVIDIA CloudXR, customers of Vection Technologies can access the Mindesk platform from anywhere, using standalone AR or VR headsets like the HTC Vive Focus. Enterprises can now easily share their 3D CAD, CAM, and BIM environments among colleagues and customers in real time. And since most of the computation happens in the cloud, any business can take advantage of the capabilities of CloudXR without spending money on expensive computational powerhouses.
“One of the greatest obstacles to the adoption of AR and VR was the necessity for a dedicated GPU. And even when that is available, it is not enough for more complex and dynamic content like CAD, CAM, BIM and simulations,” said Gabriele Sorrento, director of Vection Technologies. “NVIDIA CloudXR solves both problems. By decoupling the app from the workstation, CloudXR makes complex AR and VR data available anywhere.”
Vection Technologies plans to ship the Mindesk Suite with NVIDIA CloudXR.
Another early user of CloudXR on Azure is Innoactive, a company that provides a platform to deploy VR training at scale in large organizations. Working with companies such as SAP, Innoactive uses NVIDIA CloudXR and Azure to enhance VR training while keeping content secure and easily accessible from the cloud.
“SAP customers have large and complex CAD models which they want to use in their VR process simulations and training applications,” said Michael Spiess, venture lead for extended reality at SAP. “With CloudXR, we can easily stream those VR simulations with the highest quality visuals to any device — whether it’s an HMD, a tablet, or even a smartphone. Innoactive Portal supports NVIDIA CloudXR and makes all this available with a click of a button. This will help us to offer XR Cloud services to our 200 million business users.”
Users can try CloudXR on Azure today by downloading the Innoactive Portal app, and experience XR streaming from the cloud with their own VR headset.
CloudXR Sets the Stage for Advanced AR and VR
The CloudXR platform includes:
NVIDIA CloudXR SDK, which supports all OpenVR apps and includes broad client support for phones, tablets and head-mounted displays.
NVIDIA RTX Virtual Workstations to provide high quality graphics at the fastest frame rates.
NVIDIA AI SDKs to accelerate performance and increase immersive presence.
With CloudXR running on GPU-powered VM instances on Azure, companies can provide users with high-quality virtual experiences from anywhere in the world.
Availability Coming Soon
NVIDIA CloudXR on Azure will be generally available later this year, with a private beta available soon. Apply now for early access to the SDK, and sign up to get the latest news and updates on upcoming CloudXR releases, including the private beta.
The latest versions of Nsight Systems 2021.2 and, Nsight Compute 2021.1 are now available with new features for GPU profiling and performance optimization.
Today we announced the latest versions of Nsight Systems 2021.2 and, Nsight Compute 2021.1 – now available with new features for GPU profiling and performance optimization.
We also announced the Nsight Visual Studio Code Edition, NVIDIA’s new addition to the series of world class developer tools for CUDA programming and debugging.
Nsight Systems 2021.2
Nsight Systems 2021.2, introduces support for GPU metrics sampling and tracing of CUDA Unified Memory page faults on the CPU and GPU. There’s also support for Reflex SDK, CUDA 11.3, and additional enhancements in network trace, including: NCCL, NVSHMEM, OpenSHMEM, and MPI fortran.
The GPU metrics sampling feature allows you to view and analyze low level utilization details on a timeline. These provide a system wide overview of efficiency for your GPU workloads. They include metrics on IO activity including throughput for PCIe, NVLink, and DRAM. They also show SM utilization, TensorCore activity, instructions issued, warp occupancy and unallocated warps.
This expands Nsight Systems ability to profile system-wide activity and help track GPU workloads and their CPU origins. By providing a deeper understanding of the GPU utilization over multiple processes and contexts; covering the interop of Graphics and Compute workloads including CUDA, OptiX, DirectX and Vulkan ray tracing + rasterization APIs.
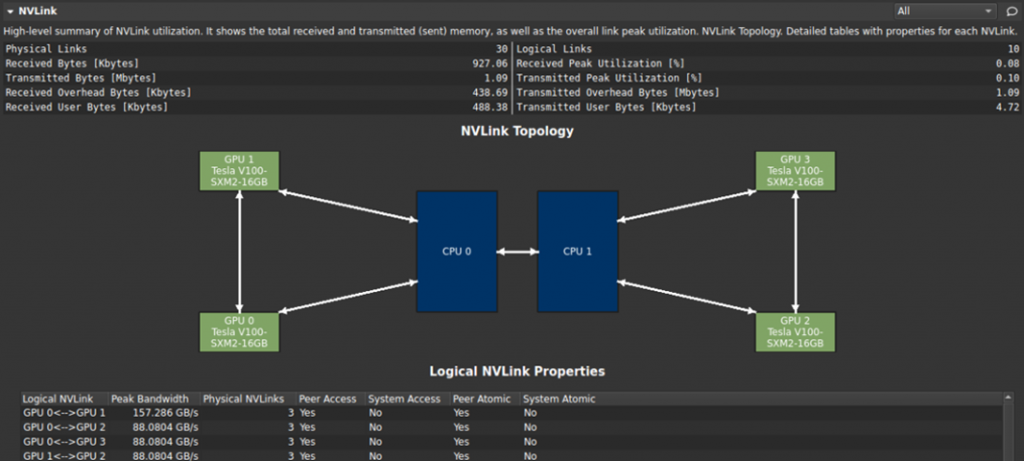
Nsight Compute 2021.1 is available now and adds a new NVLink topology and properties section to help users understand the hardware layout of their platform and how it may be impacting performance.
Figure 2. NVLInk Topology and Properties Section
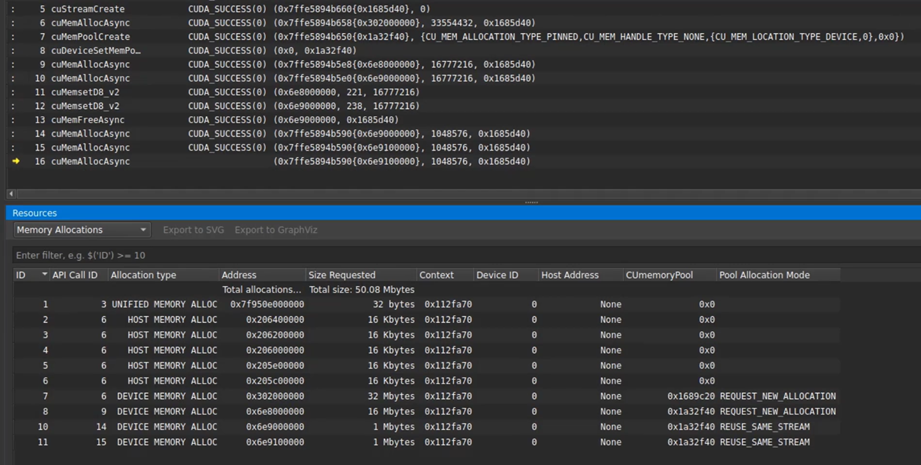
This new version also adds OptiX 7 API stepping, MacOS 11 Big Sur host support, and improved resource tracking capabilities for user objects, stream capture, and asynchronous suballocations.
Figure 3. CUDA asynchronous allocation tracking
These new features give the user increased visibility into the dynamic performance behavior of their workloads and how they are using hardware and software resources.
Nsight Visual Studio Code Edition provides syntax highlighting, CUDA debugging, Problems tab integration for nvcc, and Intellisense features for kernel functions including auto-completion, go to definition, and find all references.
The upcoming NVIDIA CloudXR 2.1 release will deliver support for Apple iOS AR devices, including iPads and iPhones.
The upcoming NVIDIA CloudXR 2.1 release will deliver support for Apple iOS AR devices, including iPads and iPhones.
Built on NVIDIA RTX technology, CloudXR is an advanced streaming technology that delivers VR and AR across 5G and Wi-Fi networks.XR users no longer need to be physically tethered to a high-performance computer to experience rich, immersive environments.
The CloudXR SDK runs on NVIDIA servers located in the cloud, edge or on-premises, delivering the advanced graphics performance needed for wireless virtual, augmented or mixed reality environments.
An early adopter of CloudXR on iOS is Brightline Interactive, a company that provides immersive VR and AR technology solutions to customers. Brightlight Interactive is using CloudXR to enhance immersive experiences and services for clients.
“With the addition of iOS support within CloudXR, we can now deploy content in a platform-agnostic way, enabling us to expand capabilities for delivery and increase our ability to target content for end clients,” said Jason Powers, chief creative technologist at Brightline Interactive. “From a developer perspective, porting apps from Android to iOS, especially for real-time rendered content, can be painstaking work. By utilizing CloudXR, we can quickly and easily add iOS as a target platform for our real-time networked augmented reality experience.”
The key features of CloudXR 2.1 include:
Apple iOS client will be available. This client sample is based on Apple ARKit.
WaveVR client sample is now updated to WaveVR SDK 3.2.0
Android client sample is now using Gradle version 6.1.1
Windows client sample is now using SDL version 2.0.14, as well as has a fix for dependencies on dynamic link libraries
Streaming parameters are optimized for networks with high jitter
Video bitstreams now signal sRGB transfer characteristics in bitstream header
Various minor bug fixes and optimizations
The CloudXR iOS integration will soon be available in NVIDIA Omniverse.
Omniverse is a collaboration and simulation platform that streamlines 3D production pipelines across industries by giving individual users and globally dispersed teams the ability to collaborate between leading industry applications in a shared virtual space in real time. With the newest CloudXR iOS integration, Omniverse users will also be able to stream AR content using their iOS tablets and phones.
Python plays a key role within the science, engineering, data analytics, and deep learning application ecosystem. NVIDIA has long been committed to helping the Python ecosystem leverage the accelerated massively parallel performance of GPUs to deliver standardized libraries, tools, and applications. Today, we’re introducing another step towards simplification of the developer experience with improved Python … Continued
Python plays a key role within the science, engineering, data analytics, and deep learning application ecosystem. NVIDIA has long been committed to helping the Python ecosystem leverage the accelerated massively parallel performance of GPUs to deliver standardized libraries, tools, and applications. Today, we’re introducing another step towards simplification of the developer experience with improved Python code portability and compatibility.
Our goal is to help unify the Python CUDA ecosystem with a single standard set of low-level interfaces, providing full coverage of and access to the CUDA host APIs from Python. We want to provide an ecosystem foundation to allow interoperability among different accelerated libraries. Most importantly, it should be easy for Python developers to use NVIDIA GPUs.
CUDA Python: The long and winding road
To date, access to CUDA and NVIDIA GPUs through Python could only be accomplished by means of third-party software such as Numba, CuPy, Scikit-CUDA, RAPIDS, PyCUDA, PyTorch, or TensorFlow, just to name a few. Each wrote its own interoperability layer between the CUDA API and Python.
By releasing CUDA Python, NVIDIA is enabling these platform providers to focus on their own value-added products and services. NVIDIA also hopes to lower the barrier to entry for other Python developers to use NVIDIA GPUs. The initial release of CUDA Python includes Cython and Python wrappers for the CUDA Driver and runtime APIs.
In future releases, we may offer a Pythonic object model and wrappers for CUDA libraries (cuBLAS, cuFFT, cuDNN, nvJPEG, and so on). Upcoming releases may also be available with source code on GitHub or packaged through PIP and Conda.
CUDA Python workflow
Because Python is an interpreted language, you need a way to compile the device code into PTX and then extract the function to be called at a later point in the application. It’s not important for understanding CUDA Python, but Parallel Thread Execution (PTX) is a low-level virtual machine and instruction set architecture (ISA). You construct your device code in the form of a string and compile it with NVRTC, a runtime compilation library for CUDA C++. Using the NVIDIA Driver API, manually create a CUDA context and all required resources on the GPU, then launch the compiled CUDA C++ code and retrieve the results from the GPU. Now that you have an overview, jump into a commonly used example for parallel programming: SAXPY.
The first thing to do is import the Driver API and NVRTC modules from the CUDA Python package. In this example, you copy data from the host to device. You need NumPy to store data on the host.
import cuda_driver as cuda # Subject to change before release
import nvrtc # Subject to change before release
import numpy as np
Error checking is a fundamental best practice in code development and a code example is provided. For brevity, error checking within the example is omitted. In a future release, this may automatically raise exceptions using a Python object model.
def ASSERT_DRV(err):
if isinstance(err, cuda.CUresult):
if err != cuda.CUresult.CUDA_SUCCESS:
raise RuntimeError("Cuda Error: {}".format(err))
elif isinstance(err, nvrtc.nvrtcResult):
if err != nvrtc.nvrtcResult.NVRTC_SUCCESS:
raise RuntimeError("Nvrtc Error: {}".format(err))
else:
raise RuntimeError("Unknown error type: {}".format(err))
It’s common practice to write CUDA kernels near the top of a translation unit, so write it next. The entire kernel is wrapped in triple quotes to form a string. The string is compiled later using NVRTC. This is the only part of CUDA Python that requires some understanding of CUDA C++. For more information, see An Even Easier Introduction to CUDA.
saxpy = """
extern "C" __global__
void saxpy(float a, float *x, float *y, float *out, size_t n)
{
size_t tid = blockIdx.x * blockDim.x + threadIdx.x;
if (tid
Go ahead and compile the kernel into PTX. Remember that this is executed at runtime using NVRTC. There are three basic steps to NVRTC:
Create a program from the string.
Compile the program.
Extract PTX from the compiled program.
In the following code example, compilation is targeting compute capability 75, or Turing architecture, with FMAD enabled. If compilation fails, use nvrtcGetProgramLog to retrieve a compile log for additional information.
Before you can use the PTX or do any work on the GPU, you must create a CUDA context. CUDA contexts are analogous to host processes for the device. In the following code example, the Driver API is initialized so that the NVIDIA driver and GPU are accessible. Next, a handle for compute device 0 is passed to cuCtxCreate to designate that GPU for context creation. With the context created, you can proceed in compiling the CUDA kernel using NVRTC.
# Initialize CUDA Driver API
err, = cuda.cuInit(0)
# Retrieve handle for device 0
err, cuDevice = cuda.cuDeviceGet(0)
# Create context
err, context = cuda.cuCtxCreate(0, cuDevice)
With a CUDA context created on device 0, load the PTX generated earlier into a module. A module is analogous to dynamically loaded libraries for the device. After loading into the module, extract a specific kernel with cuModuleGetFunction. It is not uncommon for multiple kernels to reside in PTX.
# Load PTX as module data and retrieve function
ptx = np.char.array(ptx)
err, module = cuda.cuModuleLoadData(ptx.ctypes.get_data())
err, kernel = cuda.cuModuleGetFunction(module, b"saxpy")
Next, get all your data prepared and transferred to the GPU. For increased application performance, you can input data on the device to eliminate data transfers. For completeness, this example shows how you would transfer data to and from the device.
NUM_THREADS = 512 # Threads per block
NUM_BLOCKS = 32768 # Blocks per grid
a = np.array([2.0], dtype=np.float32)
n = np.array(NUM_THREADS * NUM_BLOCKS, dtype=np.uint32)
bufferSize = n * a.itemsize
hX = np.random.rand(n).astype(dtype=np.float32)
hY = np.random.rand(n).astype(dtype=np.float32)
hOut = np.zeros(n).astype(dtype=np.float32)
With the input data a, x, and y created for the SAXPY transform device, resources must be allocated to store the data using cuMemAlloc. To allow for more overlap between compute and data movement, use the asynchronous function cuMemcpyHtoDAsync. It returns control to the CPU immediately following command execution.
Python doesn’t have a natural concept of pointers, yet cuMemcpyHtoDAsync expects void*. Therefore, XX.ctypes.get_data retrieves the pointer value associated with XX.
With data prep and resources allocation finished, the kernel is ready to be launched. To pass the location of the data on the device to the kernel execution configuration, you must retrieve the device pointer. In the following code example, int(dXclass) retries the pointer value of dXclass, which is CUdeviceptr, and assigns a memory size to store this value using np.array.
Like cuMemcpyHtoDAsync, cuLaunchKernel expects void** in the argument list. In the earlier code example, it creates void** by grabbing the void* value of each individual argument and placing them into its own contiguous memory.
# The following code example is not intuitive
# Subject to change in a future release
dX = np.array([int(dXclass)], dtype=np.uint64)
dY = np.array([int(dYclass)], dtype=np.uint64)
dOut = np.array([int(dOutclass)], dtype=np.uint64)
args = [a, dX, dY, dOut, n]
args = np.array([arg.ctypes.get_data() for arg in args], dtype=np.uint64)
Now the kernel can be launched:
err, = cuda.cuLaunchKernel(
kernel,
NUM_BLOCKS, # grid x dim
1, # grid y dim
1, # grid z dim
NUM_THREADS, # block x dim
1, # block y dim
1, # block z dim
0, # dynamic shared memory
stream, # stream
args.ctypes.get_data(), # kernel arguments
0, # extra (ignore)
)
err, = cuda.cuMemcpyDtoHAsync(
hOut.ctypes.get_data(), dOutclass, bufferSize, stream
)
err, = cuda.cuStreamSynchronize(stream)
The cuLaunchKernel function takes the compiled module kernel and execution configuration parameters. The device code is launched in the same stream as the data transfers. That ensures that the kernel’s compute is performed only after the data has finished transfer, as all API calls and kernel launches within a stream are serialized. After the call to transfer data back to the host is executed, cuStreamSynchronize is used to halt CPU execution until all operations in the designated stream are finished.
# Assert values are same after running kernel
hZ = a * hX + hY
if not np.allclose(hOut, hZ):
raise ValueError("Error outside tolerance for host-device vectors")
Perform verification of the data to ensure correctness and finish the code with memory clean up.
Performance is a primary driver in targeting GPUs in your application. So, how does the above code compare to its C++ version? Table 1 shows that the results are nearly identical. NVIDIA NSight Systems was used to retrieve kernel performance and CUDA Events was used for application performance.
The following command was used to profile the applications:
nsys profile -s none -t cuda --stats=true
C++
Python
Kernel execution
352µs
352µs
Application execution
1076ms
1080ms
Table 1. Kernel and application performance comparison.
CUDA Python is also compatible with NVIDIA Nsight Compute, which is an interactive kernel profiler for CUDA applications. It allows you to have detailed insights into kernel performance. This is useful when you’re trying to maximize performance (Figure 1).
Figure 1. Screenshot of Nsight Compute CLI output of CUDA Python example.
Get started with CUDA Python
CUDA Python coming soon, along with a detailed description of APIs, installation notes, new features, and examples. For more information, see the following posts:
Carestream Health, a leading maker of medical imaging systems, is investigating the use of NVIDIA Clara AGX — an embedded AI platform for medical devices — in the development of AI-powered features on single-frame and streaming x-ray applications. Startups around the world, too, are adopting Clara AGX for AI solutions in medical imaging, surgery and Read article >
Developing autonomous vehicles with large scale simulation requires an ecosystem of partners and tools that’s just as wide ranging. NVIDIA DRIVE Sim powered by Omniverse addresses AV development challenges with a scalable, diverse and physically accurate simulation platform. With DRIVE Sim, developers can improve productivity and test coverage, accelerating their time to market while minimizing Read article >
Volvo Cars is extending its long-held legacy of safety far into the future. The global automaker announced during the GTC keynote today that it will use NVIDIA DRIVE Orin to power the autonomous driving computer in its next-generation cars. The decision deepens the companies’ collaboration to even more software-defined model lineups, beginning with the next-generation Read article >
SANTA CLARA, Calif., April 12, 2021 — GTC — Volvo, Zoox and SAIC are among the growing ranks of leading transportation companies using the newest NVIDIA DRIVE™ solutions to power their…
Enterprises rely on GPU virtualization to keep their workforces productive, wherever they work. And NVIDIA virtual GPU (vGPU) performance has become essential to powering a wide range of graphics- and compute-intensive workloads from the cloud and data center. Now, designers, engineers and knowledge workers across industries can experience accelerated performance with the NVIDIA A10 and Read article >

 The NVIDIA CloudXR platform will be available on NVIDIA GPU-powered virtual machine instances on Azure.
The NVIDIA CloudXR platform will be available on NVIDIA GPU-powered virtual machine instances on Azure.
 The latest versions of Nsight Systems 2021.2 and, Nsight Compute 2021.1 are now available with new features for GPU profiling and performance optimization.
The latest versions of Nsight Systems 2021.2 and, Nsight Compute 2021.1 are now available with new features for GPU profiling and performance optimization.
 The upcoming NVIDIA CloudXR 2.1 release will deliver support for Apple iOS AR devices, including iPads and iPhones.
The upcoming NVIDIA CloudXR 2.1 release will deliver support for Apple iOS AR devices, including iPads and iPhones. 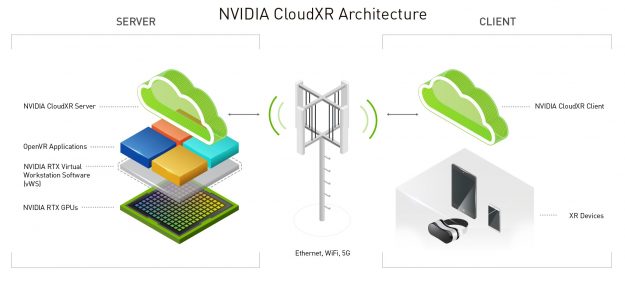
 Python plays a key role within the science, engineering, data analytics, and deep learning application ecosystem. NVIDIA has long been committed to helping the Python ecosystem leverage the accelerated massively parallel performance of GPUs to deliver standardized libraries, tools, and applications. Today, we’re introducing another step towards simplification of the developer experience with improved Python …
Python plays a key role within the science, engineering, data analytics, and deep learning application ecosystem. NVIDIA has long been committed to helping the Python ecosystem leverage the accelerated massively parallel performance of GPUs to deliver standardized libraries, tools, and applications. Today, we’re introducing another step towards simplification of the developer experience with improved Python … 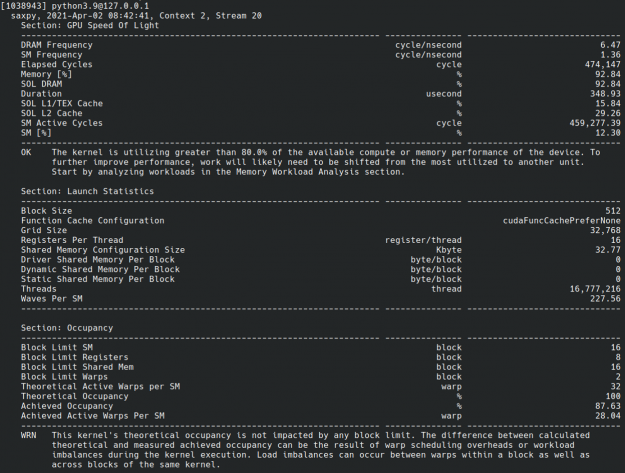
 Catch the latest announcements from NVIDIA CEO Jensen Huang
Catch the latest announcements from NVIDIA CEO Jensen Huang