Considering new security software? AI and security experts Bartley Richardson and Daniel Rohrer from NVIDIA have advice: Ask a lot of questions.
Considering new security software? AI and security experts Bartley Richardson and Daniel Rohrer from NVIDIA have advice: Ask a lot of questions.
Cybersecurity software is getting more sophisticated these days, thanks to AI and ML capabilities. It’s now possible to automate security measures without direct human intervention. The value in these powerful solutions is real—in stopping breaches, providing highly detailed alerts, and protecting attack surfaces. Still, it pays to be a skeptic.
This interview with NVIDIA experts Bartley Richardson and Daniel Rohrer covers key issues such as AI claims, the hidden costs of deployment, and how to best use the demo. They recommend a series of questions to ask vendors when considering investing in AI-enabled cybersecurity software.
Richardson leads a cross-discipline engineering team for AI infrastructure and cybersecurity, working on ML and Deep Learning techniques and new frameworks for cybersecurity. Rohrer, vice president of software security, has held a variety of technical and leadership roles during his 22 years at NVIDIA.
1. What type of AI is running in your software?
Richardson: A lot of vendors claim they have AI and ML solutions for cybersecurity, but only a small set of them are investing in thoughtful approaches using AI that address the core issue of cybersecurity as a data problem. Vendors can make claims that their solutions can do all kinds of things. But those claims are really only valid if you also have X, Y, and Z in your ecosystem. The conditions on their claims get buried most of the time.
Rohrer: It’s like saying that you can get these great features if you have full ptrace logs that go across your network all day long. Who has that? No one has that. It is cost-prohibitive.
Richardson: Oh sure, we can do amazing things for you. You just need to capture, store, and catalog all of the packets that go across your network. Then devote a lot of very powerful and expensive servers to analyzing those packets, only to then require 100 new cybersecurity experts to interpret those results. Everyone has those resources, right?
But seriously, AI is not magic. It’s math. AI is just another technique. You have to look critically at AI. Ask your vendor, what type of AI is running in their software and where are they running it? Because AI is used for everything, but not everything is AI. Overselling and underdelivering are causing “AI fatigue” in the market. People are getting bombarded with this all the time.
2. What deployment options can you offer?
Rohrer: Many people have hybrid cloud environments and a solution that works in just part of your environment. Certainly for cyber, it’s often deficient. How flexible is their deployment? Can they run in the cloud? On prem? In multiple environments like Linux, Windows, or whatever is needed to protect your data and achieve your goals?
You need the right multicloud. For example, we use Google and Alibaba Cloud and AWS and Azure. Do they have a deployable solution in all those environments, or just one of those environments? And do we need that? Sometimes we don’t need that, sometimes we do. Cybersecurity is one of those use cases where we need logs from everywhere. So understand your solution space and know how flexible your deployment model needs to be to solve your problem. And bake that in.
Cyber is often one of the harder ones to pull off, because we have lots of dynamic ephemeral data. We’re often in many, many complex heterogeneous environments that are data-heavy and IO-heavy. So if you want a worst case scenario, cyber is often it.
Richardson: There could be hidden costs in deployment, too. If you have an environment where the vendor is saying you can get all this AI, but by the way, you have to use our cloud. There’s an associated cost—if you’re not already cloud-native and pushing your data to the cloud—in time, engineering, and money.
Rohrer: Even if you are cloud-native, there’s I/O overhead to push whatever data you have over to them. And all of the sudden, you have a million-dollar project on your hands.
3. What new infrastructure will I need to buy to run your software?
Rohrer: What infrastructure will you need to deploy your model? Do you have what you need, or can you readily purchase it without exorbitant costs? Can you afford it? If it’s an on-prem solution, does the proposal include the additional infrastructure you’re going to need? If it’s cloud-based, does it include all the cloud instances and data ingress/egress fees, or are those all extra?
Richardson: If you’re telling me something is additive, great. If you’re telling me something’s rip and replace, that’s a different proposition.
4. How will you protect my model?
Richardson: People usually ask about data. How are you protecting my data? Is it isolated? Is it secure? Those are good questions to ask. But what happens when a service provider customizes an AI model for me? What are their policies around protecting that fine-tuned model for my environment? How are you protecting my model?
Because if they’re doing anything that’s real with ML or deep learning, the model is just as valuable as the data it’s trained on. It’s possible to back out training and fine-tuning data from a trained model, if you are sufficiently experienced with the techniques.
That means it’s possible for people to access my sensitive information. My data didn’t leak, but this massive embedding space of my neural net leaked, and now it’s possible for someone, with a lot of work, to back out my training data. And not a lot of people are encrypting models. The constant encrypt/decrypt would totally thrash your throughput. There should be policies and procedures in place, ideally ones that can be automatically enforced, that protect these models. Ensure that your vendor is following best practices around implementing the least privileges possible when those models contain embeddings of your data.
5. What can you do with my data?
Rohrer: There are many service providers who are aggregating data and events across customers to improve a model for everyone, which is fine as long as you’re up front about it. But you know, one question to ask is whether your data is being used to improve a model for competitors or everyone else in the market? And make sure that you’re comfortable with that. In some cases that’s fine, if it’s weather data or whatever. Sometimes not so much. Because some of that data and the models you build from it have a real competitive advantage for you.
Richardson: I always come back to companies like Facebook and Twitter. The real value for them is your data. So they can use everyone’s data and training–and that gives them a superior ability and extra value. They’re selling you a service or a product and using your data to improve it.
6. Can I bring my data to the demo?
Rohrer: Preparing for the demo is important, because that’s really where the rubber hits the road for most folks.
Richardson: Yeah, ideally you should have a set of criteria going in. Know what your requirements are. Maybe you have some incident or misconfiguration or problem. Can AI address that? Can we see it run in a customer environment, not just in your sandbox environment?
Rohrer: Bring your problems to the demo.
7. Does your solution require tuning, and if so, how often?
Rohrer: One recommendation is to bring some of your own data to the table. How do I ingest my data? What is the efficacy of problems that I actually have, not the one that the demo team is telling me I should have? And see how it performs with your data. If it doesn’t work with your data unless they tune it, then you know it’s not just buy and deploy. Now it’s a deploy after 3 months, 6 months, maybe 9 months of tuning. Now it’s not just a product purchase. It’s a purchase and integration contract and a support contract and the costs add up before you realize it.
8. How easy is your solution for our engineers to learn and use?
Richardson: A lot of people don’t evaluate the person load. I know that’s hard to do in a trial. But whether it’s cybersecurity or IT or whatever, get your people evaluating that. Get your engineers involved in the process. Ask how will your engineers interact with the new software on a daily basis? We see this a lot, especially in cybersecurity, where you’ve added something to do function X. And in the end, it just creates more cognitive load on your humans that are working with it. It’s generating more noise than they can handle, even if it’s doing it at a pretty low false-positive rate. It’s additive.
Rohrer: Yeah, it’s 99% accurate, but it doubled the number of events your people have to deal with. That didn’t help them.
Richardson: AI is not magic. It’s just math. But it’s framed in the context of magic. Just be willing to look at AI critically. It’s just another technique. It’s not a magic bullet that is going to solve all your problems. We’re not living in the future yet.
About Bartley Richardson

Bartley Richardson is Director of Cybersecurity Engineering at NVIDIA and leads a cross-discipline team researching GPU-accelerated ML and Deep Learning techniques and creating new frameworks for cybersecurity. His interests include NLP and sequence-based methods applied to cyber network datasets and threat detection. Bartley holds a PhD in Computer Science and Engineering working on loosely and unstructured logical query optimization, and a BS in Computer Engineering with a focus on software design and AI.
More from Bartley Richardson:
- Enhancing Zero Trust Security with Data | NVIDIA Technical Blog
- Cybersecurity Framework: An Introduction to NVIDIA Morpheus | NVIDIA Technical Blog
- NVIDIA Launches Morpheus Early Access Program to Enable Advanced Cybersecurity Solution Development | NVIDIA Technical Blog
About Daniel Rohrer

Daniel Rohrer is VP of Software Product Security at NVIDIA. In his 23 years at NVIDIA, he has held a variety of technical and leadership roles. Daniel has taken his integrated knowledge of ‘everything NVIDIA’ to hone security practices through the delivery of advanced technical solutions, reliable processes, and strategic investments to build trustworthy security solutions. He has a MS in Computer Science from the University of North Carolina, Chapel Hill.
More from Daniel Rohrer:
Edge Computing: Considerations for Security Architects | NVIDIA Technical Blog
 Published in Nature Machine Intelligence, a panel of experts shares a vision for the future of biopharma featuring collaboration between ML and drug discovery powered by GPUs.
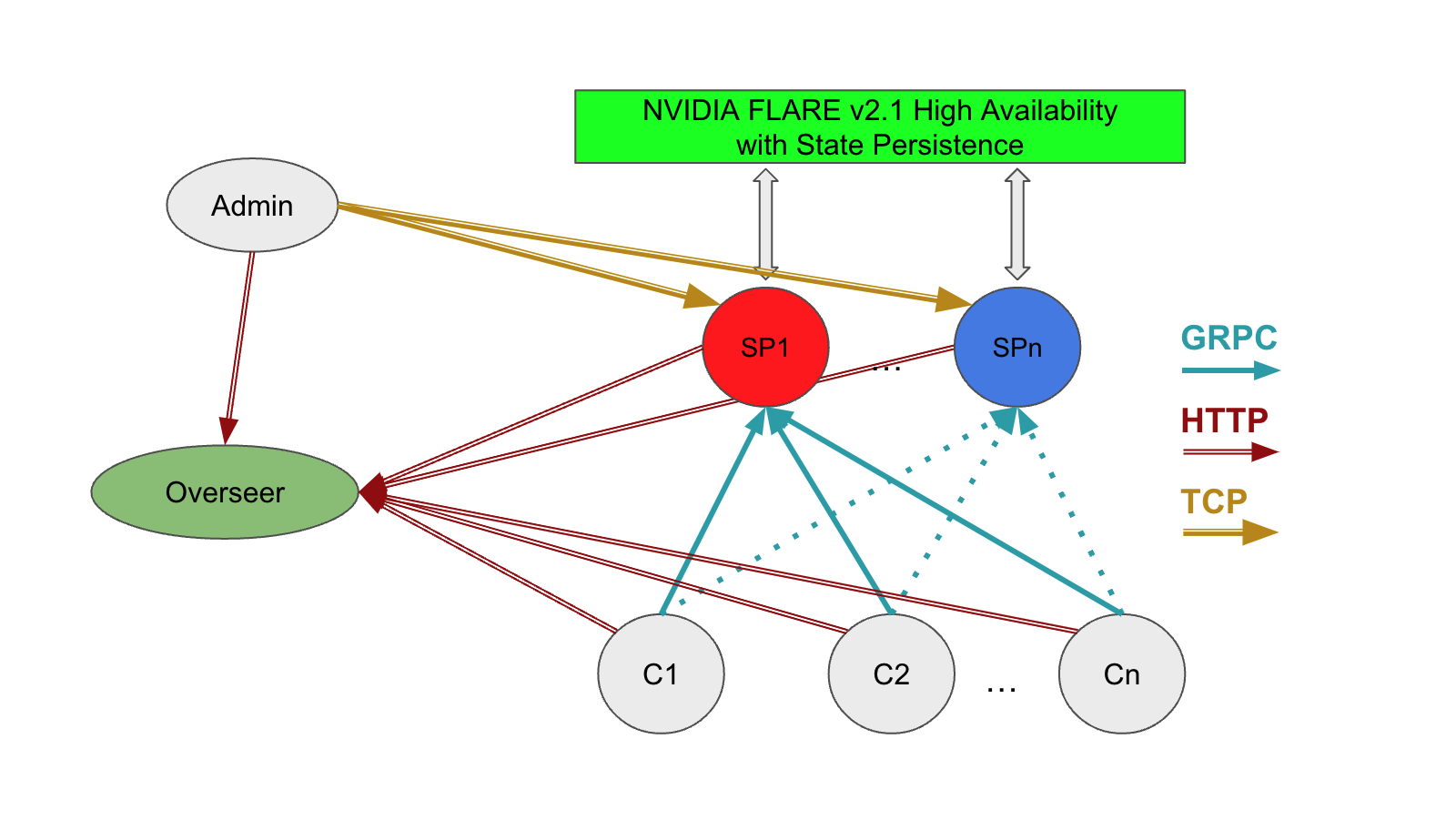
Published in Nature Machine Intelligence, a panel of experts shares a vision for the future of biopharma featuring collaboration between ML and drug discovery powered by GPUs. In this post, I introduce new features of NVIDIA FLARE v2.1 and walk through proof-of-concept and production deployments of the NVIDIA FLARE platform.
In this post, I introduce new features of NVIDIA FLARE v2.1 and walk through proof-of-concept and production deployments of the NVIDIA FLARE platform.
 Learn more about the NVIDIA NVUE object-oriented, schema-driven model of a complete Cumulus Linux system. The API enables you to configure any system element.
Learn more about the NVIDIA NVUE object-oriented, schema-driven model of a complete Cumulus Linux system. The API enables you to configure any system element. 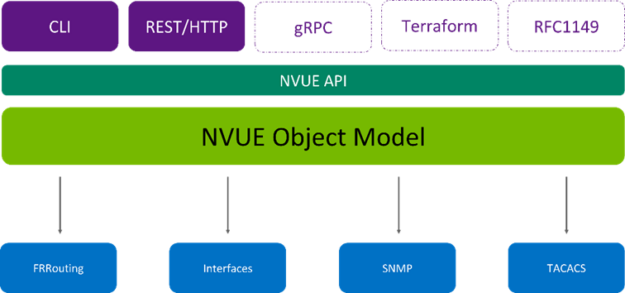
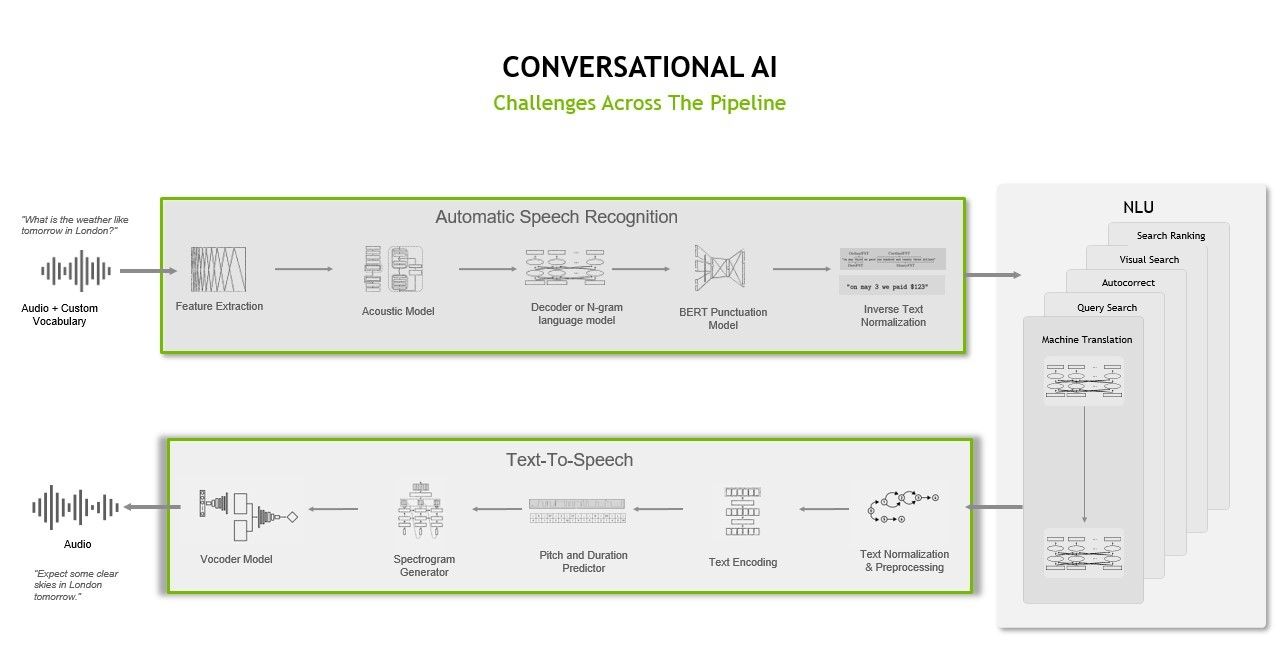
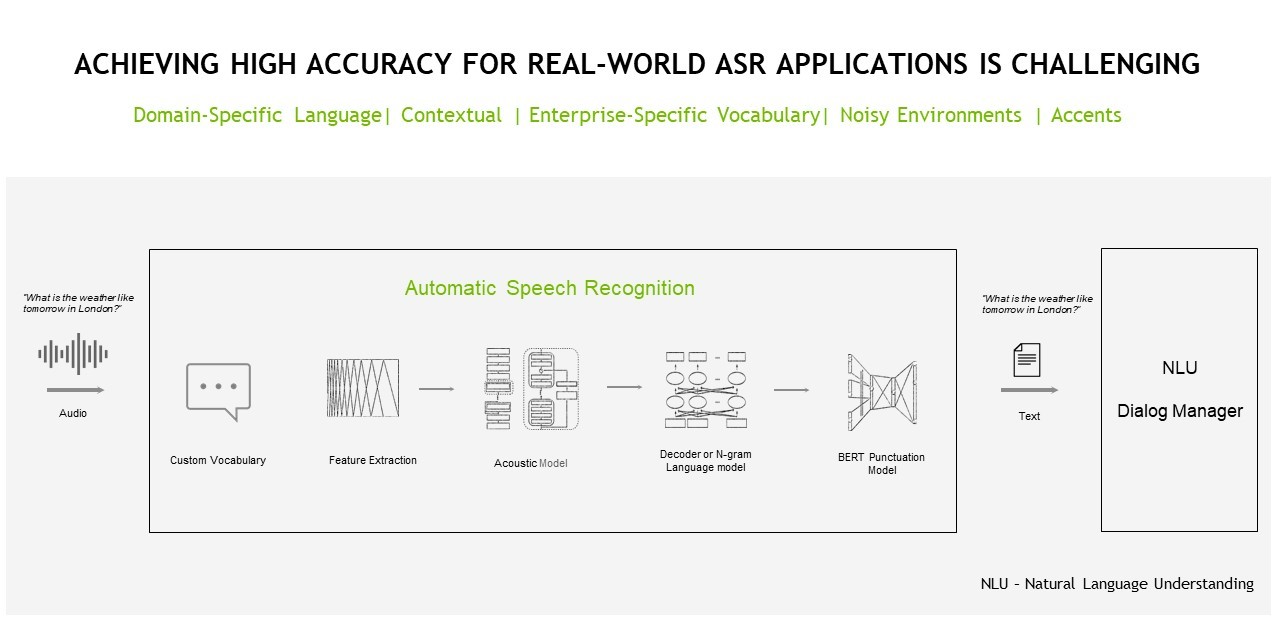
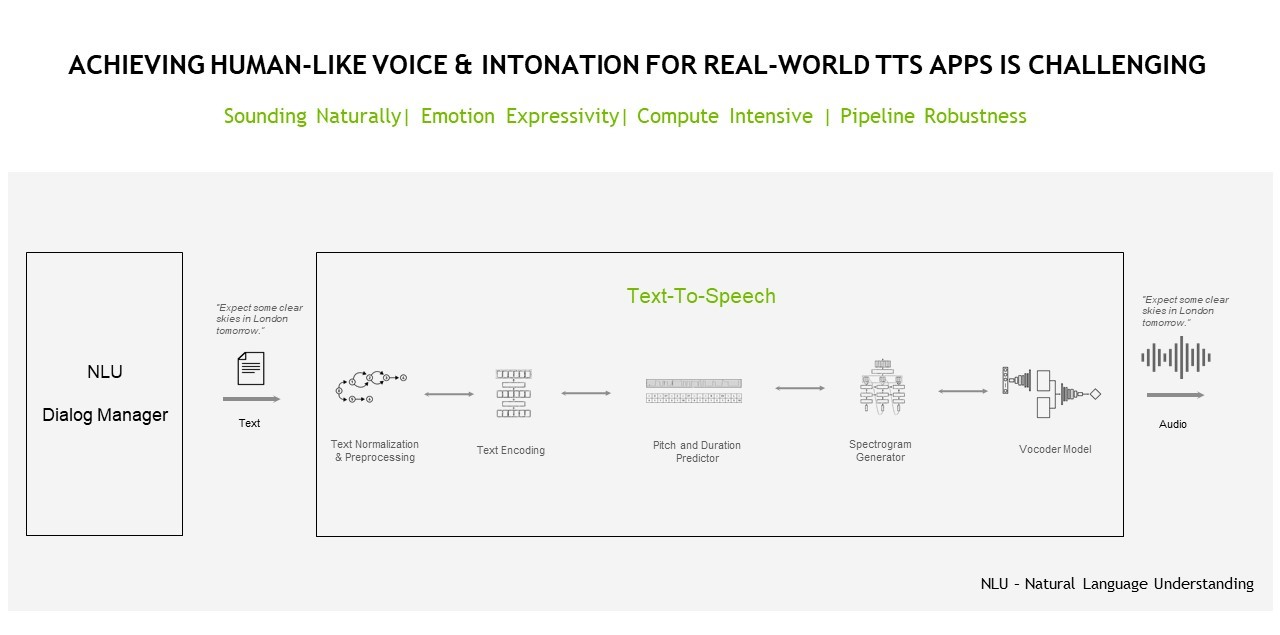
 A simple introduction to speech AI technology, use cases and benefits for practitioners.
A simple introduction to speech AI technology, use cases and benefits for practitioners.