
NVIDIA today announced a new range of developer frameworks, tools, apps and plugins for NVIDIA Omniverse™, the platform for building and connecting metaverse worlds based on Universal Scene Description (USD).
NVIDIA today announced NVIDIA Omniverse Avatar Cloud Engine (ACE), a suite of cloud-native AI models and services that make it easier to build and customize lifelike virtual assistants and digital humans.
 Learning about new technologies can sometimes be intimidating. The NVIDIA edge computing webinar series aims to present the basics of edge computing so that all…
Learning about new technologies can sometimes be intimidating. The NVIDIA edge computing webinar series aims to present the basics of edge computing so that all…
Learning about new technologies can sometimes be intimidating. The NVIDIA edge computing webinar series aims to present the basics of edge computing so that all attendees can understand the key concepts associated with this technology.
NVIDIA recently hosted the webinar, Edge Computing 201: How to Build an Edge Solution, which explores the components needed to build a production edge AI deployment. During the presentation, attendees were asked various polling questions about their knowledge of edge computing, their biggest challenges, and their approaches to building solutions.
You can see a breakdown of the results from those polling questions below, along with some answers and key resources that will help you along in your edge journey.
What stage are you in on your edge computing journey?
More than half (55%) of the poll respondents said they are still in the learning phase of their edge computing journey. The first two webinars in the series—Edge Computing 101: An Introduction to the Edge and Edge Computing 201: How to Build an Edge Solution—are specifically designed for those who are just starting to learn about edge computing and edge AI.
Another resource for learning the basics of edge computing is Top Considerations for Deploying AI at the Edge. This reference guide includes all the technologies and decision points that need to be considered when building any edge computing deployment.
In addition, 25% of respondents report that they are researching what the right edge computing use cases are for them. By far, the most mature edge computing use case today is computer vision, or vision AI. Since computer vision use cases require high bandwidth and low latency, they are the ideal use case for what edge computing has to offer.
Let’s Build Smarter, Safer Spaces with AI provides a deep dive into computer vision use cases, and walks you through many of the technologies associated with making these use cases successful.
What is your biggest challenge when designing an edge computing solution?
Respondents were more evenly split across several different answers for this polling question. In each subsection below, you can read more about the challenges audience members reported experiencing while getting started with edge computing, along with some resources that can help.
Unsure what components are needed
Although each use case and environment will have unique, specific requirements, almost every edge deployment will include three components:
- An application that can be deployed and managed across multiple environments
- Infrastructure that provides the right compute and networking to enable the desired use case
- Security tools that will protect intellectual property and critical data
Of course, there will be additional considerations, but focusing on these three components provides organizations with what they need to get started with AI at the edge.
Here’s what a typical edge deployment looks like:
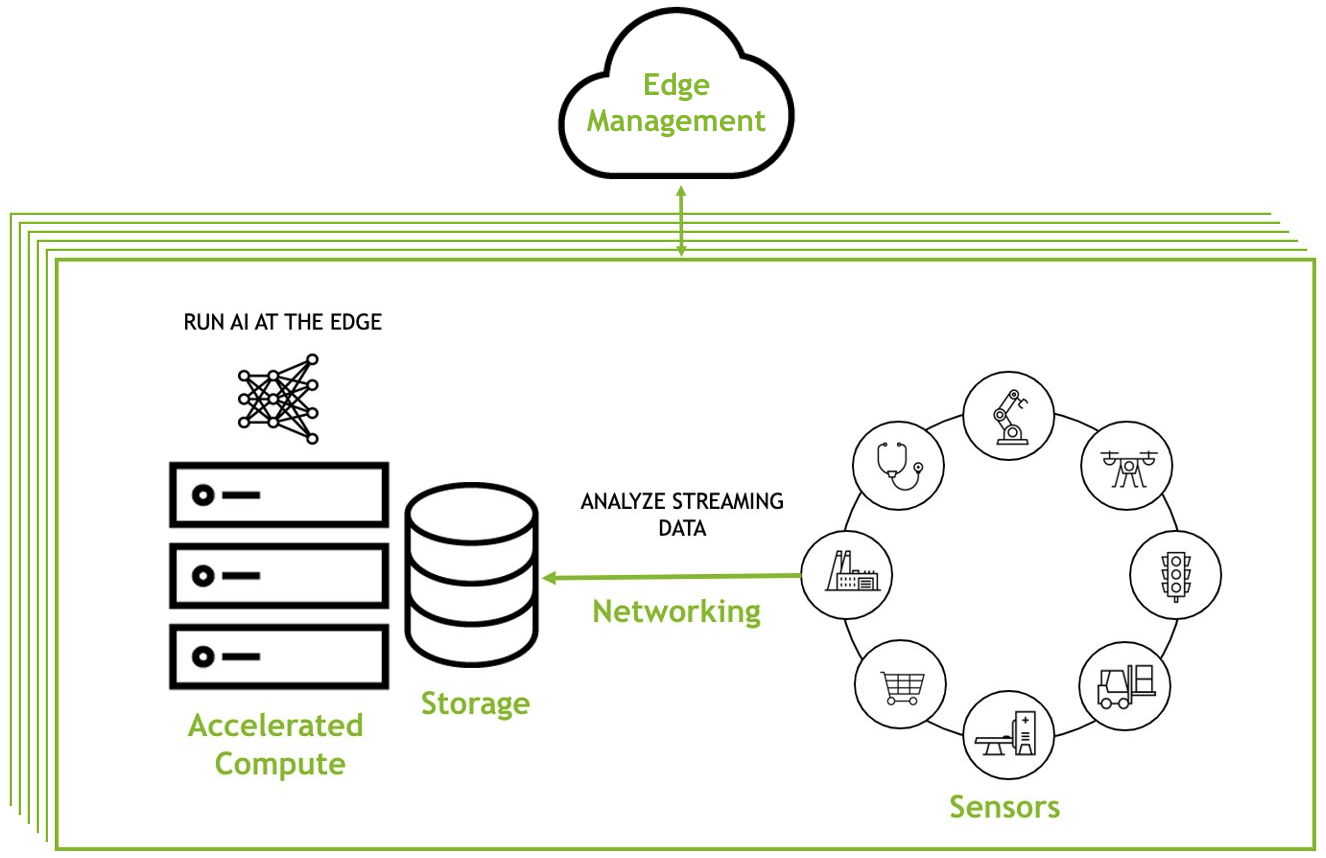
To learn more, see Edge Computing 201: How to Build an Edge Solution. It covers all the considerations for building an edge solution, the needed components, and how to ensure those components work together to create a seamless workflow.
Implementation challenges
Understanding the steps involved in implementing an edge computing solution is a good way to ensure that the first solution built is a comprehensive solution, which will help eliminate future headaches when maintaining or scaling.
This understanding will also help to eliminate unforeseen challenges. The five main steps to implementing any edge AI solution are:
- Identify a use case or challenge to be solved
- Determine what data and application requirements exist
- Evaluate existing edge infrastructure and what pieces must be added
- Test the solution and then roll it out at scale
- Share success with other groups to promote additional use cases
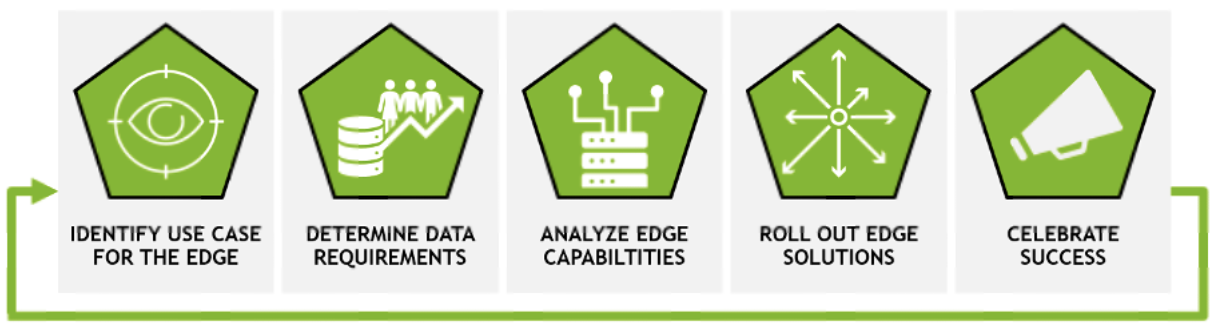
To learn more about how to implement an edge computing solution, see Steps to Get Started With Edge AI, which outlines best practices and pitfalls to avoid along the way.
Scaling across multiple sites
Scaling a solution across multiple (sometimes thousands) of sites is one of the most important, yet challenging tasks associated with edge computing. Some organizations try to manually build solutions to help manage deployments, but find that the resources required to scale these solutions are not sustainable.
Other organizations try to repurpose data center tools to manage their applications at the edge, but to do this requires custom scripts and automation to adapt these solutions for new environments. These customizations become difficult to support as infrastructure footprints increase and new workloads are added.
Kubernetes-based solutions can help deploy, manage, and scale applications across multiple edge locations. These are tools specifically built for edge environments, and can come with enterprise support packages. Examples include Red Hat OpenShift, VMware Tanzu, and NVIDIA Fleet Command.
Fleet Command is purpose-built for AI. It’s turnkey, secure, and can scale to thousands of devices in minutes. Watch the Simplify AI Management at the Edge demo to learn more.
Tuning an application for edge use cases
The most important aspects of an edge computing application are flexibility and performance. Applications need to be able to operate in many different environments, and need to be portable enough that they can be easily managed across distributed locations.
In addition, organizations need applications that they can rely on. Applications need to maintain performance in sometimes extreme locations where network connectivity may be spotty, like an oil rig in the middle of the ocean.
To fulfill both of those requirements, many organizations have turned to cloud-native technology to ensure their applications have the required level of flexibility and performance. By making an application cloud-native, organizations help ensure that the application is ready for edge deployments.
To learn more, see Getting Applications Ready for Cloud-Native.
Justifying the cost of a solution
Justifying the cost of any technology comes down to understanding the cost variables and proving ROI. For an edge computing solution, there are three main cost variables:
- Infrastructure costs
- Application costs
- Management costs
Proving the ROI of a deployment will vary by use case and will be different for each organization. Generally, ROI depends a lot on the value of the AI application deployed at the edge.
Learn more about the costs associated with an edge deployment with Building an Edge Strategy: Cost Factors.
Securing edge environments
Edge computing environments have unique security considerations. That’s because they cannot rely on the castle-and-moat security architecture of a data center. For instance, physical security of data and equipment are factors that must be considered when deploying AI at the edge. Additionally, if there are connections from edge devices back to an organization’s central network, ensuring encrypted traffic between the two devices is essential.
The best approach is to find solutions that offer layered security from cloud-to-edge, providing several security protocols to ensure intellectual property and critical data are always protected.
To learn more about how to secure edge environments, see Edge Computing: Considerations for Security Architects.
Do you plan to deploy containerized applications at the edge?
Cloud-native technology was discussed in the Edge Computing 201 webinar as a way to ensure applications deployed at the edge are flexible and have a reliable level of performance. 54% of respondents reported that they plan on deploying containerized applications at the edge, while 38% said they were unsure.
Organizations need flexible applications at the edge because the edge locations they are deploying to might have varying requirements. For instance, not all grocery stores are the same size. Some bigger grocery stores might have high power requirements with over a dozen cameras deployed, while a smaller grocery store might have extremely limited power requirements with just one or two cameras deployed.
Despite the differences, an organization needs to be able to deploy the same application across both of these environments with confidence that the application can easily adapt.
Cloud-native technology allows for this flexibility, while providing key reliability: applications are re-spun if there are issues, and workloads are migrated if a system fails.
Learn more about how cloud-native technology can be used in edge environments with The Future of Edge AI Is Cloud Native.
Have you considered how you will manage applications and systems at the edge?
When asked if they have considered how they will manage applications and systems at the edge, 52% of respondents reported they are building their own solution, while 24% are buying a solution from a partner. 24% reported they have not considered a management solution.
For AI at the edge, a management solution is a critical tool. The scale and distance of locations makes manually managing all of them very difficult for production deployments. Even managing a small handful of locations becomes more tedious than it needs to be when an application requires an update or new security patch.
The section of this post entitled ‘Scaling across multiple sites’ (above) outlines why manual solutions are difficult to scale. They are often useful for POCs or experimental deployments, but for any production environment, a management tool will save many headaches.
NVIDIA Fleet Command is a managed platform for container orchestration that streamlines provisioning and deployment of systems and AI applications at the edge. It simplifies the management of distributed computing environments with the scale and resiliency of the cloud, turning every site into a secure, intelligent location.
To learn more about how Fleet Command can help manage edge deployments, watch the Simplify AI Management at the Edge demo.
Looking ahead
Edge computing is a new yet proven concept for particular use cases. Understanding the basics of this technology can help many organizations accelerate workloads to drive their bottom line.
While the Edge Computing 101 and Edge Computing 201 webinar sessions focused on designing and building edge solutions, Edge Computing 301: Maintain and Optimizing Deployments dives into what you need for ongoing day-to-day management of edge deployments. Sign up to continue your edge computing learning journey.
 Interested in speech recognition technology? Sign up for the NVIDIA speech AI newsletter. Over the past decade, AI-powered speech recognition systems have…
Interested in speech recognition technology? Sign up for the NVIDIA speech AI newsletter. Over the past decade, AI-powered speech recognition systems have…
Interested in speech recognition technology? Sign up for the NVIDIA speech AI newsletter.
Over the past decade, AI-powered speech recognition systems have slowly become part of our everyday lives, from voice search to virtual assistants in contact centers, cars, hospitals, and restaurants. These speech recognition developments are made possible by deep learning advancements.
Developers across many industries now use automatic speech recognition (ASR) to increase business productivity, application efficiency, and even digital accessibility. Read on to learn more about ASR, how it works, use cases, advancements, and more.
What is automatic speech recognition
Speech recognition technology is capable of converting spoken language (an audio signal) into written text that is often used as a command.
Today’s most advanced software can accurately process varying language dialects and accents. For example, ASR is commonly seen in user-facing applications such as virtual agents, live captioning, and clinical note-taking. Accurate speech transcription is essential for these use cases.
Developers in the speech AI space also use alternative terminologies to describe speech recognition such as ASR, speech-to-text (STT), and voice recognition.
ASR is a critical component of speech AI, which is a suite of technologies designed to help humans converse with computers through voice.
Why natural language processing is used in speech recognition
Developers are often unclear about the role of natural language processing (NLP) models in the ASR pipeline. Aside from being applied in language models, NLP is also used to augment generated transcripts with punctuation and capitalization at the end of the ASR pipeline.
After the transcript is post-processed with NLP, the text is used for downstream language modeling tasks including:
- Sentiment analysis
- Text analytics
- Text summarization
- Question answering
Speech recognition algorithms
Speech recognition algorithms can be implemented in a traditional way using statistical algorithms, or by using deep learning techniques such as neural networks to convert speech into text.
Traditional ASR algorithms
Hidden Markov models (HMM) and dynamic time warping (DTW) are two such examples of traditional statistical techniques for performing speech recognition.
Using a set of transcribed audio samples, an HMM is trained to predict word sequences by varying the model parameters to maximize the likelihood of the observed audio sequence.
DTW is a dynamic programming algorithm that finds the best possible word sequence by calculating the distance between time series: one representing the unknown speech and others representing the known words.
Deep learning ASR algorithms
For the last few years, developers have been interested in deep learning for speech recognition because statistical algorithms are less accurate. In fact, deep learning algorithms work better at understanding dialects, accents, context, and multiple languages, and transcribes accurately even in noisy environments.
Some of the most popular state-of-the-art speech recognition acoustic models are Quartznet, Citrinet, and Conformer. In a typical speech recognition pipeline, you can choose and switch any acoustic model you want based on your use case and performance.
Implementation tools for deep learning models
Several tools are available for developing deep learning speech recognition models and pipelines, including Kaldi, Mozilla DeepSpeech, NVIDIA NeMo, Riva, TAO Toolkit, and services from Google, Amazon, and Microsoft.
Kaldi, DeepSpeech, and NeMo are open-source toolkits that help you build speech recognition models. TAO Toolkit and Riva are closed-source SDKs that help you develop customizable pipelines that can be deployed in production.
Cloud Service Providers like Google, AWS, and Microsoft offer generic services that you can easily plug and play with.
Deep learning speech recognition pipeline
As shown in Figure 1, ASR pipeline consists of the following components: a spectrogram generator that converts raw audio to spectrograms, an acoustic model that takes the spectrograms as input and outputs a matrix of probabilities over characters over time, a decoder (optionally coupled with a language model) that generates possible sentences from the probability matrix, and finally, a punctuation and capitalization model that formats the generated text for easier human consumption.
A typical deep learning pipeline for speech recognition includes:
- Data preprocessing
- Neural acoustic model
- Decoder (optionally coupled with an n-gram language model)
- Punctuation and capitalization model.
Figure 1 shows an example of a deep learning speech recognition pipeline:
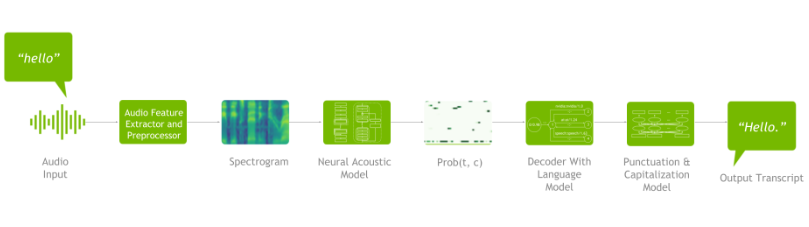
Datasets are essential in any deep learning application. Neural networks function similarly to the human brain. The more data you use to teach the model, the more it learns. The same is true for the speech recognition pipeline.
A few popular speech recognition datasets are LibriSpeech, Fisher English Training Speech, Mozilla Common Voice (MCV), VoxPopuli, 2000 HUB 5 English Evaluation Speech, AN4 (includes recordings of people spelling out addresses and names), and Aishell-1/AIshell-2 Mandarin speech corpus. In addition to your own proprietary datasets, these are some open-source datasets to get started with.
Data processing is the first step. It includes data preprocessing/augmentation techniques such as speed/time/noise/impulse perturbation and time stretch augmentation, Fast Fourier Transformations (FFT) using windowing, and normalization techniques.
For example, in Figure 2 below, the mel spectrogram is generated from a raw audio waveform after applying FFT using the windowing technique.
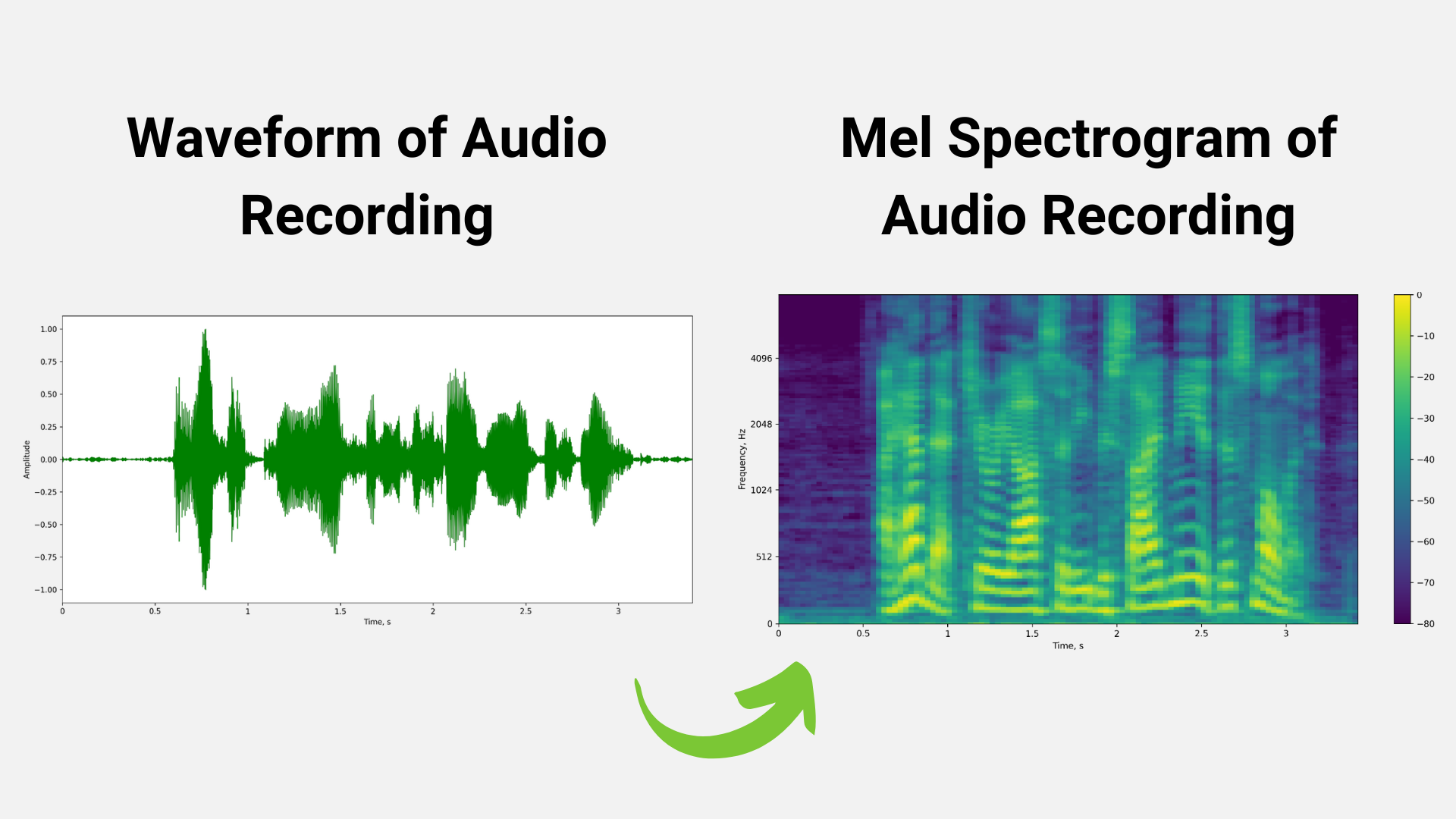
We can also use perturbation techniques to augment the training dataset. Figures 3 and 4 represent techniques like noise perturbation and masking being used to increase the size of the training dataset in order to avoid problems like overfitting.
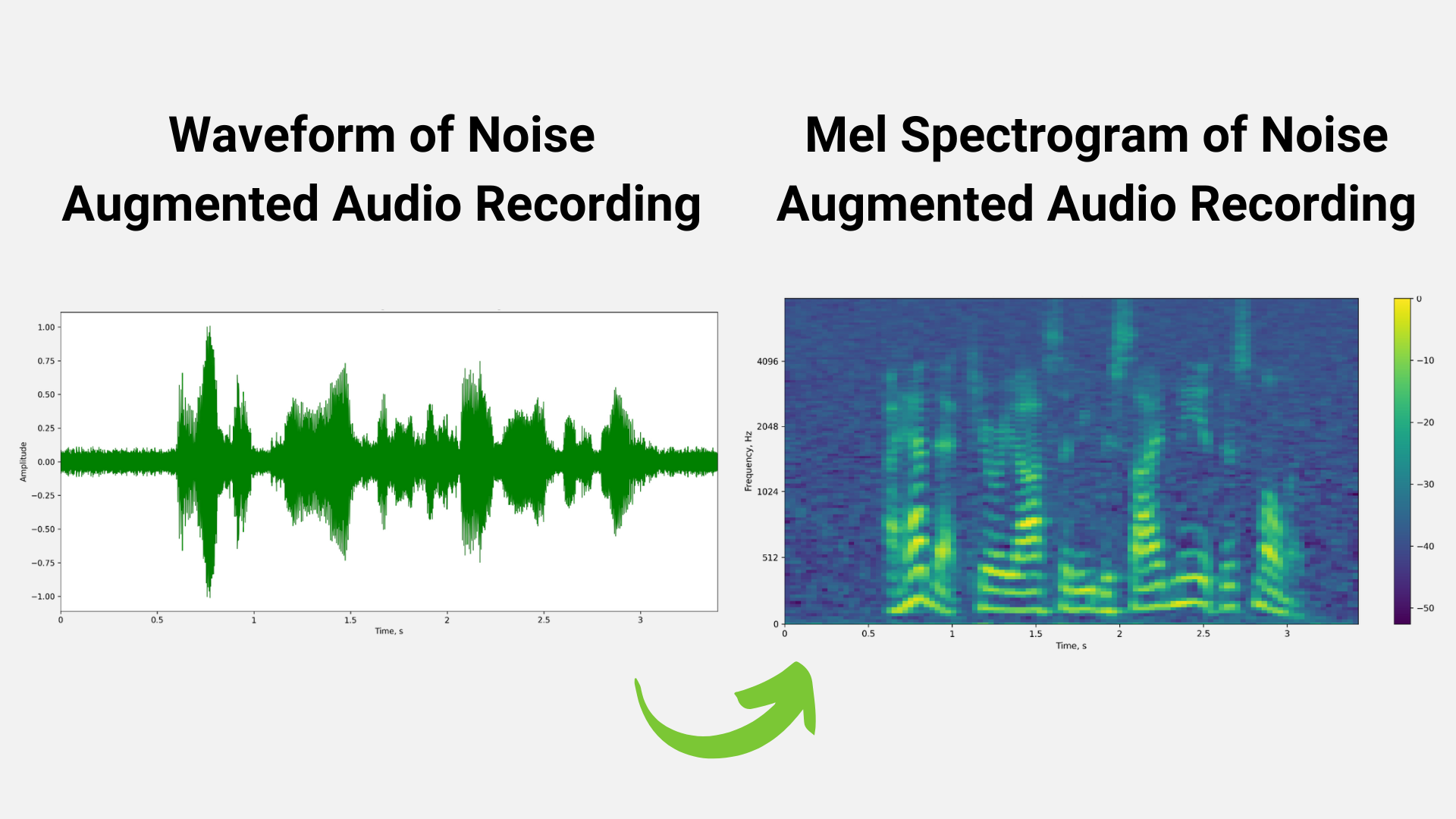
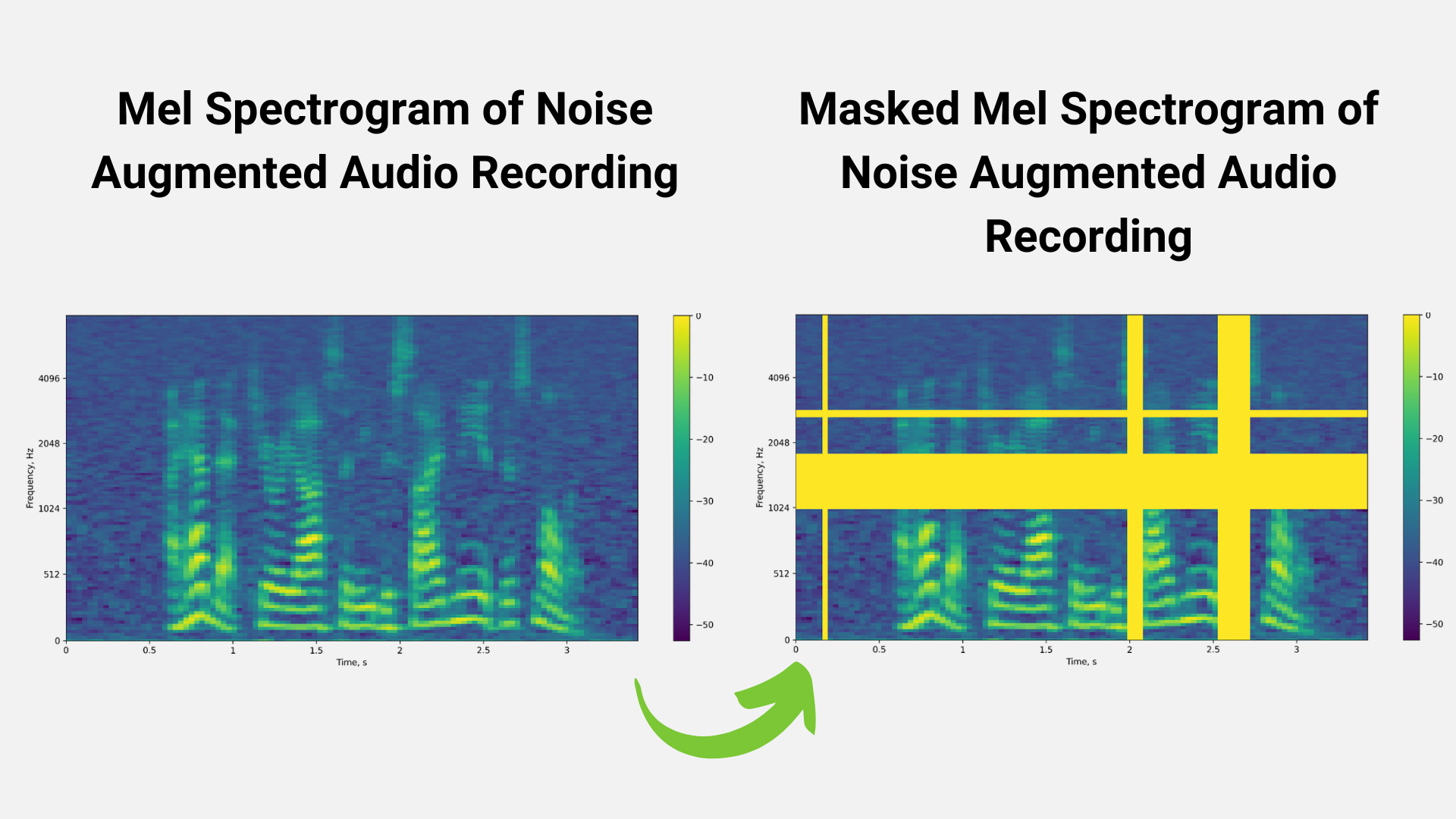
The output of the data preprocessing stage is a spectrogram/mel spectrogram, which is a visual representation of the strength of audio signal over time.
Mel spectrograms are then fed into the next stage: neural acoustic model. QuartzNet, CitriNet, ContextNet, Conformer-CTC, and Conformer-Transducer are examples of cutting-edge neural acoustic models. Multiple ASR models exist for several reasons, such as the need for real-time performance, higher accuracy, memory size, and compute cost for your use case.
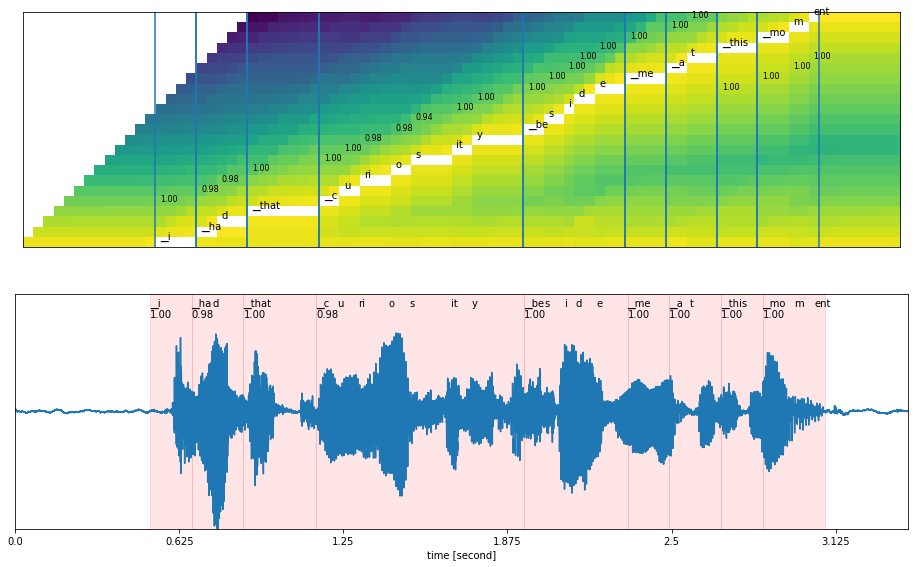
However, Conformer-based models are becoming more popular due to their improved accuracy and ability to comprehend. The acoustic model returns the probability of characters/words at each time stamp.
Figure 5 shows the output of the acoustic model, with time stamps.
The acoustic model’s output is fed into the decoder along with the language model. Decoders include beam search and greedy decoders, and language models include n-gram language, KenLM, and neural scoring. When it comes to the decoder, it helps to generate top words, which are then passed to language models to predict the correct sentence.
In the diagram below, the decoder selects the next best word based on the probability score. Based on the final highest score, the correct word or sentence is selected and sent to the punctuation and capitalization model.
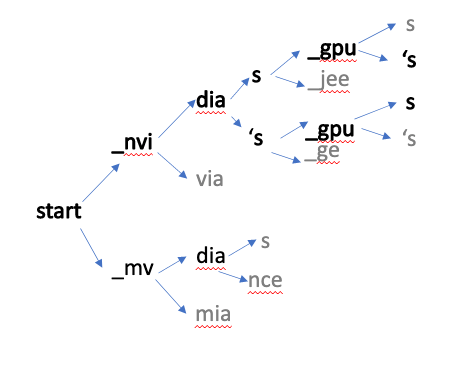
The ASR pipeline generates text with no punctuation or capitalization.
Finally, a punctuation and capitalization model is used to improve the text quality for better readability. Bidirectional Encoder Representations from Transformers (BERT) models are commonly used to generate punctuated text.
Figure 7 illustrates a simple example of a before-and-after punctuation and capitalization model:

Speech recognition industry impact
Speech recognition could help industries such as finance, telecommunications, and Unified Communications as a Service (UCaaS) to improve customer experience, operational efficiency, and return on investment (ROI).
Finance
Speech recognition is applied in the finance industry for applications such as call center agent assist and trade floor transcripts. ASR is used to transcribe conversations between customers and call center agents/trade floor agents. The generated transcriptions can then be analyzed and used to provide real-time recommendations to agents. This adds to an 80% reduction in post-call time.
Furthermore, the generated transcripts are used for downstream tasks, including:
- Sentiment analysis
- Text summarization
- Question answering
- Intent and entity recognition
Telecommunications
Contact centers are critical components of the telecommunications industry. With contact center technology, you can reimagine the telecommunications customer center, and speech recognition helps with that. As previously discussed in the finance call center use case, ASR is used in Telecom contact centers to transcribe conversations between customers and contact center agents in order to analyze them and recommend call center agents in real time. T-Mobile uses ASR for quick customer resolution, for example.
Unified Communications as a Software (UCaaS)
COVID-19 increased demand for Unified Communications as a Service (UCaaS) solutions, and vendors in the space began focusing on the use of speech AI technologies such as ASR to create more engaging meeting experiences.
For example, ASR can be used to generate live captions in video conferencing meetings. Captions generated can then be used for downstream tasks such as meeting summaries and identifying action items in notes.
Future of ASR technology
Speech recognition is not as easy as it sounds. Developing speech recognition is full of challenges, ranging from accuracy to customization for your use case to real-time performance. On the other hand, businesses and academic institutions are racing to overcome some of these challenges and advance the use of speech recognition capabilities.
ASR challenges
Some of the challenges in developing and deploying speech recognition pipelines in production include:
- Lack of tools and SDKs that offer state-of-the-art (SOTA) ASR models makes it difficult for developers to take advantage of the best speech recognition technology.
- Limited customization capabilities that enable developers to fine-tune on domain-specific and context-specific jargon, multiple languages, dialects, and accents in order to have your applications understand and speak like you
- Restricted deployment support; for example, depending on the use case, the software should be capable of being deployed in any cloud, on-prem, edge, and embedded.
- Real-time speech recognition pipelines; for instance, in a call center agent assist use case, we cannot wait several seconds for conversations to be transcribed before using them to empower agents.
ASR advancements
Numerous advancements in speech recognition are occurring on both the research and software development fronts. To begin, research has resulted in the development of several new cutting-edge ASR architectures, E2E speech recognition models, and self-supervised or unsupervised training techniques.
On the software side, there are a few tools that enable quick access to SOTA models, and then there are different sets of tools that enable the deployment of models as services in production.
Key takeaways
Speech recognition continues to grow in adoption due to its advancements in deep learning-based algorithms that have made ASR as accurate as human recognition. Also, breakthroughs like multilingual ASR help companies make their apps available worldwide, and moving algorithms from cloud to on-device saves money, protects privacy, and speeds up inference.
NVIDIA offers Riva, a speech AI SDK, to address several of the challenges discussed above. With Riva, you can quickly access the latest SOTA research models tailored for production purposes. You can customize these models to your domain and use case, deploy on any cloud, on-prem, edge, or embedded, and run them in real-time for engaging natural interactions.
Learn how your organization can benefit from speech recognition skills with the free ebook, Building Speech AI Applications.
![]() Create a project using the NVIDIA Jetson Nano developer kit and submit it by September 30, 2022 for a chance to win a Machine Learning at Home Kit.
Create a project using the NVIDIA Jetson Nano developer kit and submit it by September 30, 2022 for a chance to win a Machine Learning at Home Kit.![]()
Create a project using the NVIDIA Jetson Nano developer kit and submit it by September 30, 2022 for a chance to win a Machine Learning at Home Kit.
 Join us on August 11, 2022 to learn how to design edge deployments for future-proof scale, best practices for optimizing multiple deployments on edge systems,…
Join us on August 11, 2022 to learn how to design edge deployments for future-proof scale, best practices for optimizing multiple deployments on edge systems,…
Join us on August 11, 2022 to learn how to design edge deployments for future-proof scale, best practices for optimizing multiple deployments on edge systems, and tips for remotely repairing systems and applications.
Categories
How to Start a Career in AI
How do I start a career as a deep learning engineer? What are some of the key tools and frameworks used in AI? How do I learn more about ethics in AI? Everyone has questions, but the most common questions in AI always return to this: how do I get involved? Cutting through the hype Read article >
The post How to Start a Career in AI appeared first on NVIDIA Blog.
NVIDIA today announced selected preliminary financial results for the second quarter ended July 31, 2022.
 Imagine driving along a road and an obstacle suddenly appears in your path. How quickly can you react to it? How does your reaction speed change with the time…
Imagine driving along a road and an obstacle suddenly appears in your path. How quickly can you react to it? How does your reaction speed change with the time…
Imagine driving along a road and an obstacle suddenly appears in your path. How quickly can you react to it? How does your reaction speed change with the time of day, the color of the obstacle, and where it appears in your field of view?
The ability to react quickly to visual events is valuable to everyday life. It is also a fundamental skill in fast-paced video games. A recent collaboration between researchers from NVIDIA, NYU, and Princeton—winner of a SIGGRAPH 2022 Technical Paper Award—explores the relationship between image features and the time it takes for an observer to react.
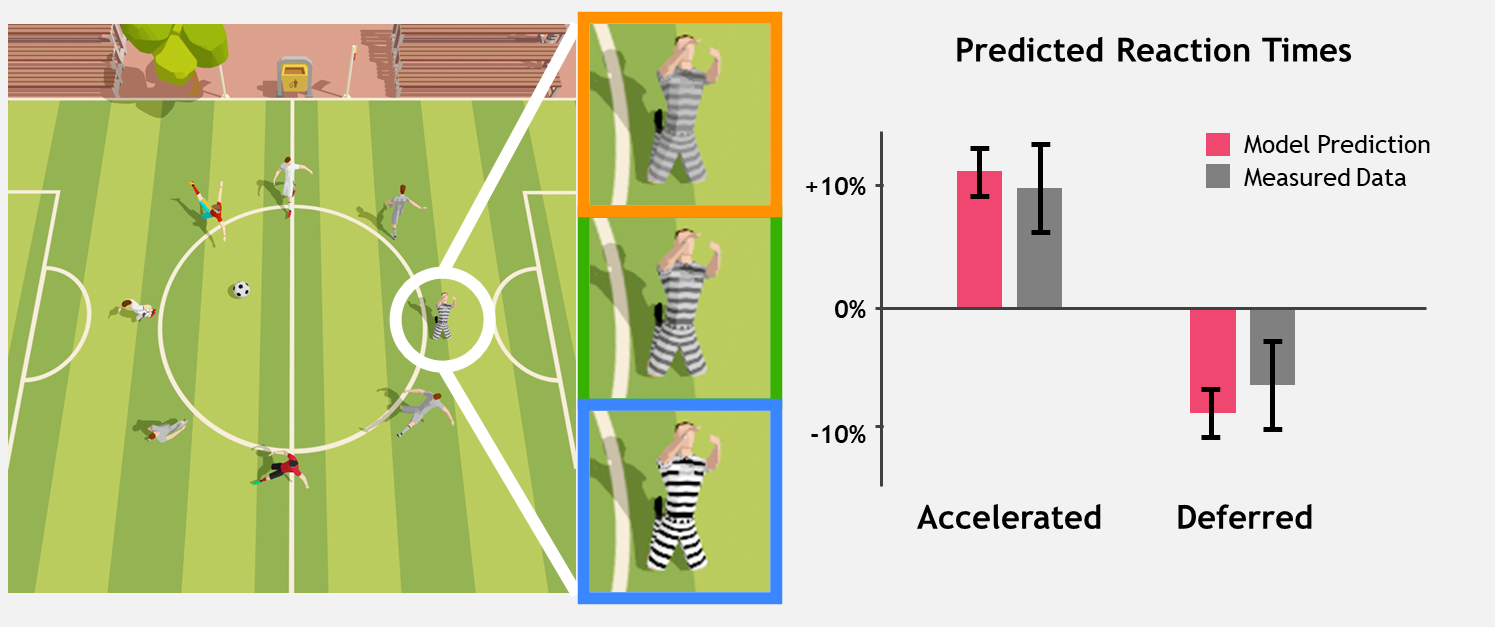
Reaction speed and visual events
With so many recent advances in display technology, human reaction times have become a primary bottleneck in the graphics pipeline. Response times for communicating with remote servers, rendering and displaying images, and collecting and processing mouse or keyboard input are all typically tens of milliseconds or less.
By contrast, the pipeline for human perception is much slower, and can range from 100 to 500 milliseconds depending on the complexity of the visual input. This research aims to simplify and optimize images to reduce our reaction time as much as possible.
Visual contrast and spatial frequency are well-known features that influence low-level vision. Further, human vision is not uniform over the entire field of view. The amount of contrast needed to boost reaction time varies depending on eccentricity, or visual angle (where an object is located relative to center gaze) and spatial frequency (whether an object is a solid color or a complex pattern, for example). Reaction time is a combination of many neural processes, and the proposed model includes all of these factors.
Reaction time measurements are based on the onset latency of voluntary rapid eye movements called saccades. The “reaction time clock” starts ticking as soon as the target appears on the screen. Once the target is identified, a saccade is initiated towards it.
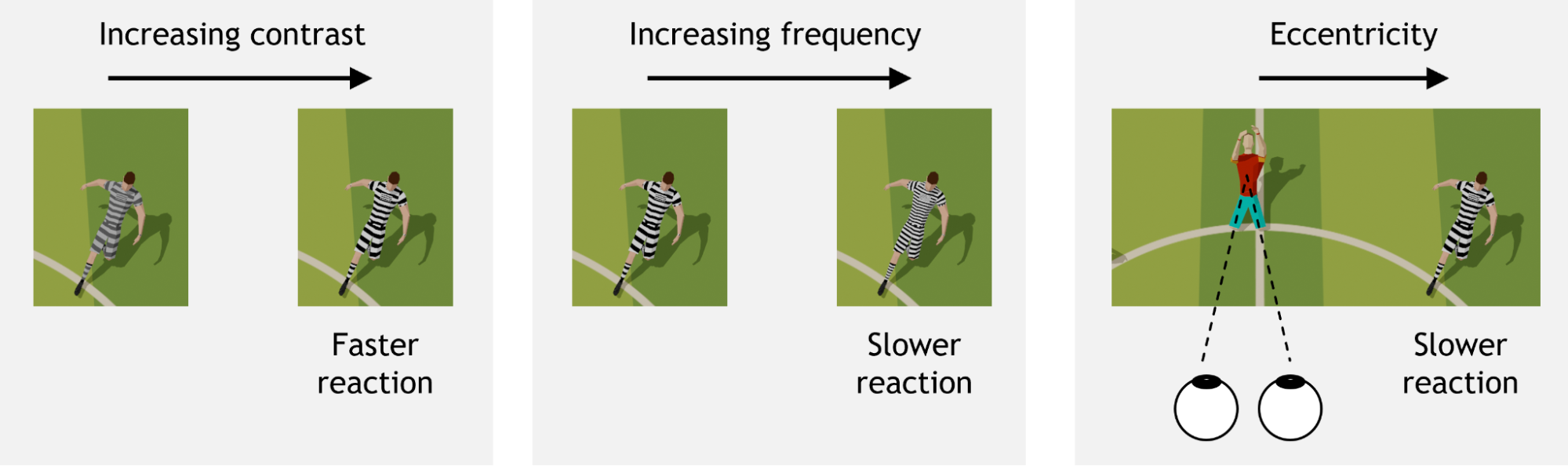
Modeling saccadic reaction
To build a perceptually accurate model for reaction time prediction, researchers conducted a series of experiments with human observers, collecting over 11,000 reaction times for varying image features.
Inspired by how the human brain perceives information and makes decisions, the researchers designed a model for reaction time prediction, accounting for contrast, frequency, and eccentricity, as well as the inherent randomness in human reaction speed.
In this model, a measure of “decision confidence” is accumulated over time, and once enough confidence has been accumulated, a saccade is made. The rate at which confidence accumulates over time is inconsistent, as shown in the video below.
Hence, instead of predicting a single reaction time with full certainty, the model provides a likelihood of exhibiting various reaction times. The average rate of confidence accumulation is influenced by image features and results in a change in the likelihood of reaction times, as shown in the video below.
Two validation experiments confirm that this model can be applied to images that might be seen, including video games and natural photographs.
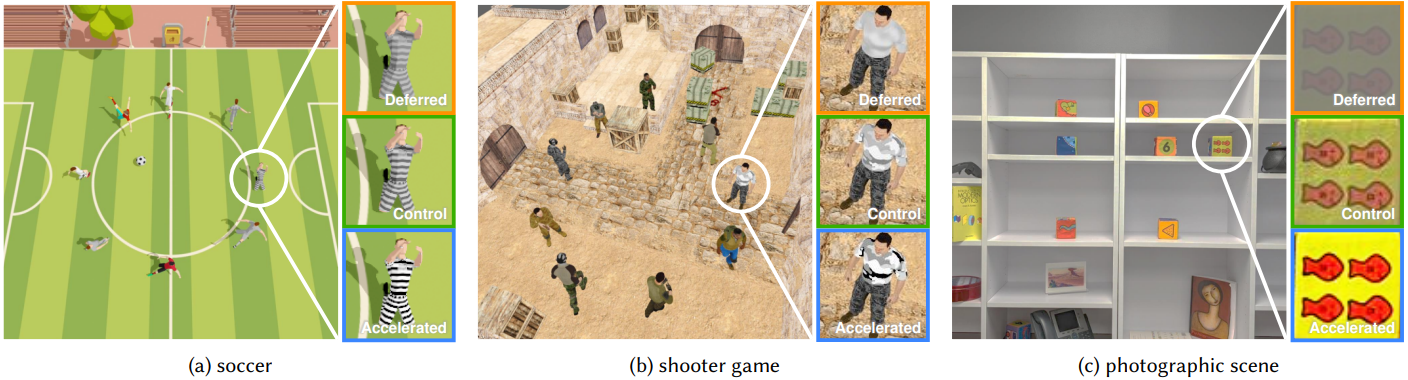
Using reaction time prediction to optimize human performance
Applications for this saccadic reaction time model include, for example, a smart drive-assist system estimating whether a driver can safely react to pedestrians and other vehicles, and turn on appropriate assistance features. Similarly, e-sports game designers can use this model to understand the fairness of their game’s visual design, avoiding bias in competitive outcomes.
Ambitious gamers can also use this model to fine-tune their setup for maximum performance–by choosing an optimal skin for the target 3D object, for example.
In future work, the research team plans to explore how other image features like color and temporal effects influence human reaction time, and how to train humans to increase the speed at which they react to on-screen or real-world events.
For more details, read the paper, Image Features Influence Reaction Time: A Learned Probabilistic Perceptual Model for Saccade Latency. You can also visit the gaze-timing project on GitHub.
The paper’s authors, Budmonde Duinkharjav, Praneeth Chakravarthula, Rachel Brown, Anjul Patney, and Qi Sun will present this work at SIGGRAPH 2022 on August 11 in Vancouver, British Columbia.
") Discover how to detect cyber threats using machine learning and NVIDIA Morpheus, an open-source AI framework.
Discover how to detect cyber threats using machine learning and NVIDIA Morpheus, an open-source AI framework.
Discover how to detect cyber threats using machine learning and NVIDIA Morpheus, an open-source AI framework.