
") In collaboration with the United Nations, DLI is offering a new free online course focused on applying deep learning methods to generate accurate flood detection models.
In collaboration with the United Nations, DLI is offering a new free online course focused on applying deep learning methods to generate accurate flood detection models.
 Transformers4Rec makes it easy to use SOTA NLP architectures for sequential and session-based recommendation by leveraging HuggingFace Transformers.
Transformers4Rec makes it easy to use SOTA NLP architectures for sequential and session-based recommendation by leveraging HuggingFace Transformers.
Recommender systems help you discover new products and make informed decisions. Yet, in many recommendation-dependent domains such as e-commerce, news, and streaming media services, users may be untrackable or have rapidly changing tastes depending on their needs at that moment.
Session-based recommendation systems, a sub-area of sequential recommendation, have recently gained popularity because they can recommend items relative to a user’s situation and preferences at any given point in time. Capturing short-term or contextual user preferences towards items is helpful in these domains.

In this post, we introduce the session-based recommendation task, which is supported by Transformers4Rec, a library from the NVIDIA Merlin platform. We then showcase how easy it is to create a session-based recommendation model in a few lines of code using Transformers4Rec and finally conclude with demonstrating an end-to-end session-based recommendation pipeline with NVIDIA Merlin libraries.
Transformers4Rec library features
Released at ACM RecSys’21, the NVIDIA Merlin team designed and open-sourced the NVIDIA Merlin Transformers4Rec library for sequential and session-based recommendation tasks by leveraging state-of-the-art Transformers architectures. The library is extensible by researchers, simple for practitioners, and fast and robust in industrial deployments.
It leverages the SOTA NLP architectures from the Hugging Face (HF) Transformers library, making it possible to quickly experiment with many different Transformer architectures and pretraining approaches in the RecSys domain.
Transformers4Rec also helps data scientists, industry practitioners, and academicians build recommender systems that can leverage the short sequence of past user interactions within the same session and then dynamically suggest the next item that the user may be interested in.

Here are some highlights of the Transformers4Rec library:
- Flexibility and efficiency: Building blocks are modularized and compatible with vanilla PyTorch modules and TF Keras layers. You can create custom architectures, for example, with multiple towers, multiple heads/tasks, and losses. Transformers4Rec supports multiple input features and provides configurable building blocks that can easily be combined for custom architectures.
- Integration with HuggingFace Transformers: Uses cutting-edge NLP research and makes state-of-the-art Transformer architectures available for the RecSys community for sequential and session-based recommendation tasks.
- Support for multiple input features: Transformers4Rec enables the usage of HF Transformers with any type of sequential tabular data.
- Seamless integration with NVTabular for preprocessing and feature engineering.
- Production-ready: Exports trained models to serve on NVIDIA Triton Inference Server in a single pipeline with online features preprocessing and model inference.
Develop your own session-based recommendation model
With only a few lines of code, you can build a session-based model based on a SOTA Transformer architecture. The following example shows how the powerful XLNet Transformer architecture can be used for a next-item prediction task.
As you may notice, the code in building a session-based model with PyTorch and TensorFlow is very similar, with only a couple of differences. The following code example builds an XLNET-based recommendation model with PyTorch and TensorFlow using the Transformers4Rec API:
#from transformers4rec import torch as tr
from transformers4rec import tf as tr
from merlin_standard_lib import Schema
schema = Schema().from_proto_text("schema path>")
max_sequence_length, d_model = 20, 320
# Define input module to process tabular input-features and to prepare masked inputs
input_module = tr.TabularSequenceFeatures.from_schema(
schema,
max_sequence_length=max_sequence_length,
continuous_projection=64,
aggregation="concat",
d_output=d_model,
masking="clm",
)
# Define Next item prediction-task
prediction_task = tr.NextItemPredictionTask(hf_format=True,weight_tying=True)
# Define the config of the XLNet architecture
transformer_config = tr.XLNetConfig.build(
d_model=d_model, n_head=8, n_layer=2,total_seq_length=max_sequence_length
)
# Get the PyT model
model = transformer_config.to_torch_model(input_module, prediction_task)
# Get the TF model
#model = transformer_config.to_tf_model(input_module, prediction_task)
To demonstrate the utility of the library and applicability of Transformer architectures in next-click prediction for user sessions, where sequence lengths are much shorter than those commonly found in NLP, the NVIDIA Merlin team used Transformers4Rec to win two session-based recommendation competitions:
- WSDM WebTour Workshop Challenge 2021 by Booking.com (NVIDIA solution)
- SIGIR eCommerce Workshop Data Challenge 2021 by Coveo (NVIDIA solution)
For more information about the Transformers4Rec library’s flexibility, see Transformers4Rec: A flexible library for Sequential and Session-based recommendation.
Steps for building an end-to-end, session-based recommendation pipeline using NVIDIA Merlin
Figure 3 shows the end-to-end pipeline for a session-based recommendation pipeline using NVIDIA Merlin Transformers4Rec.
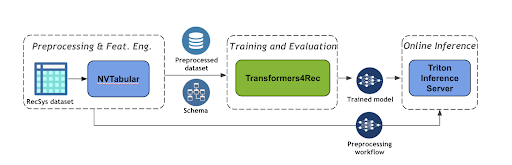
NVTabular is a feature engineering and preprocessing library for tabular data designed to quickly and easily manipulate the terabyte-scale datasets used to train large-scale recommender systems. It provides a high-level abstraction to simplify code and accelerates computation on the GPU using the RAPIDS cuDF library.
NVTabular supports different feature engineering transformations required by deep learning (DL) models such as categorical encoding and numerical feature normalization. It also supports feature engineering and generating sequential features. For more information about the supported features, see here.
In the following code example, you can easily see how to can create an NVTabular preprocessing workflow to group interactions at the session level, sorting the interactions by time. At the end, you obtain a processed dataset where each row represents a user session and corresponding sequential features for that session.
import nvtabular as nvt
# Define Groupby Operator
features = ['session_id', 'item_id', 'timestamp', 'category']
groupby_features = features >> nvt.ops.Groupby(
groupby_cols=["session_id"],
sort_cols=["timestamp"],
aggs={
'item_id': ["list", "count"],
'category': ["list"],
'timestamp': ["first"],
},
name_sep="-")
# create dataset object
dataset = nvt.Dataset(interactions_df)
workflow = nvt.Workflow(groupby_features)
# Apply the preprocessing workflow on the dataset
sessions_gdf = workflow.transform(dataset).compute()
Use Triton Inference Server to simplify the deployment of AI models at scale in production. Triton Inference Server enables you to deploy and serve your model for inference. It supports a number of different machine learning frameworks, such as TensorFlow and PyTorch.
The last step of the machine learning (ML) pipeline is to deploy the ETL workflow and trained model to production for inference. In the production setting, you want to transform the input data as done during training (ETL). For example, you should use the same normalization statistics for continuous features and the same mapping to encode the categories into contiguous IDs before you use the ML/DL model for a prediction.
Fortunately, the NVIDIA Merlin framework has an integrated mechanism to deploy both the preprocessing workflow (modeled with NVTabular) with a PyTorch or TensorFlow model as an ensemble model to NVIDIA Triton Inference. The ensemble model guarantees that the same transformation is applied to the raw inputs.
The following code example showcases how easy it is to create ensemble configuration files using the NVIDIA Merlin Inference API functions, and then serve the model to TIS.
import tritonhttpclient
import nvtabular as nvt
workflow = nvt.Workflow.load("")
from nvtabular.inference.triton import export_tensorflow_ensemble as export_ensemble
#from nvtabular.inference.triton import export_pytorch_ensemble as export_ensemble
export_ensemble(
model,
workflow,
name="ensemble model name>",
model_path="model path>",
label_columns=["label column names>"],
sparse_max=dict or None>
)
tritonhttpclient.InferenceServerClient(url="ip:port>")
triton_client.load_model(model_name="ensemble model name>")
With a few lines of code, you can serve the NVTabular workflow, a trained PyTorch or TensorFlow model, and an ensemble model to NVIDIA Triton Inference Server, in order to execute end-to-end model deployment. Using the NVIDIA Merlin Inference API, you can send a raw dataset as a request (query) to the server and then obtain the prediction results from the server.
In essence, NVIDIA Merlin Inference API creates model pipelines using the NVIDIA Triton ensembling feature. An NVIDIA Triton ensemble represents a pipeline of one or more models and the connection of input and output tensors between those models.
Conclusion
In this post, we introduced you to NVIDIA Merlin Transformers4Rec, a library for sequential and session-based recommendation tasks that seamlessly integrates with NVIDIA NVTabular and NVIDIA Triton Inference Server to build end-to-end ML pipelines for such tasks.
For more information, see the following resources:
- Transformers4Rec GitHub repo
- NVIDIA Merlin org on GitHub
- Transformers4Rec: Bridging the Gap between NLP and Sequential / Session-Based Recommendation (ACM RecSys 2021)
- Transformers with multi-modal features and post-fusion context for e-commerce session-based recommendation (SIGIR eCommerce Workshop Data Challenge 2021)
- GRU4Rec-Recurrent Neural Networks with Top-k Gains for Session-based Recommendations
- BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer
- SasRec: Self-Attentive Sequential Recommendation
Enterprises now have a new option for quickly getting started with NVIDIA AI software: the HPE GreenLake edge-to-cloud platform. The NVIDIA AI Enterprise software suite is an end-to-end, cloud-native suite of AI and data analytics software. It’s optimized to enable any organization to use AI, and doesn’t require deep AI expertise. Fully supported by NVIDIA, Read article >
The post NVIDIA Teams With HPE to Take AI From Edge to Cloud appeared first on NVIDIA Blog.
 Jacques Khisa, community leader at Africa Data School Emerging Chapters Nairobi, shares his experience on getting started in AI in Africa.
Jacques Khisa, community leader at Africa Data School Emerging Chapters Nairobi, shares his experience on getting started in AI in Africa.
In the quest for knowledge in understanding data, I never pictured my passion shifting towards AI. As a matter of fact, AI is all data!
For context, the major hindrance to the implementation of AI projects across the African continent has been the lack of digitized data upon which AI algorithms are built. In my local region of Kenya, for instance, we have struggled to convert data stacked in traditional formats in both public and private data silos, despite a higher penetration of digital products in the past decade compared to neighboring countries.
Ironically, this incentivized my enthusiasm for AI and created the need to help democratize it. As Paulo Coelho said in The Alchemist, “And, when you want something, all the universe conspires in helping you to achieve it.”
NVIDIA Emerging Chapters
With my particular interest in natural language processing, I attended the AI Expo Africa virtual conference to enable me to network with local developers, experts, and researchers in the field of AI.
There, I had a life-changing conversation with the head of Developer Ecosystems and Strategic Partnerships at NVIDIA, Amulya Vishwanath, about the Emerging Chapters program. This is a program that enables local communities in emerging areas to build and scale AI, data science, and graphics projects by providing the following:
- Technological tools
- Educational resources
- Co-marketing opportunities
In Kenya, the academic and entrepreneurial communities are particularly active. Emerging AI hotspots are mostly in academia.
Being a young conversational AI developer, I faced constraints in obtaining compute resources, research papers, and a feasible guide into the immense field of deep learning. I looked for educational opportunities to help other young enthusiasts easily access these resources and practice AI for good in my local community.
Training opportunities
As the NVIDIA DLI Ambassador and Certified DLI Instructor in deep learning and conversational AI at the Africa Data School community, I helped enable members of the Emerging Chapters to have access to training and development opportunities through the NVIDIA Deep Learning Institute (DLI). This includes free passes to select self- or instructor-led courses on AI and data science. Developers receive a NVIDIA DLI certificate upon course completion that highlights their skills, thereby advancing their careers.
Since partnering with NVIDIA, members have had great exposure and high participation in the NVIDIA GTC conference and DLI workshops. I was able to help facilitate these workshops at the Nairobi Garage co-working space, which not only allowed the attendees to get connected to a dynamic community of innovative companies and professionals but also increased our scale and impact.
The training gave participants access to world-class best practices, and knowledge to facilitate their development as AI engineers. Although some students find the content challenging, their enthusiasm is contagious. The content uses real-life case studies and shows the application of different deep learning algorithms on end-to-end applications in startups.
As individuals in my local community make full use of these resources, more talent becomes available, which consequently attracts and increases investments, accelerating growth.
After our in-person workshop, I realized that we needed more talent to educate and inspire. As it was our first workshop, we only provided 20 students with GPU instances and course materials from NVIDIA DLI. There will be many more workshops to come. We are also using free DLI courses that we were granted as part of the Emerging Chapters program to frequent training participants.
Working with the Africa Data School Emerging Chapter community has literally enabled the democratization of AI through the provision of educational resources and development opportunities in my region. Our goal is to create a community of young researchers, developers, AI engineers, and students passionate about NLP and computer vision in fintech, education, and agriculture.
These projects are in line with the Kenya Vision 2030: transforming Kenya into a newly industrializing, middle-income country that provides a high quality of life to all its citizens.
Student feedback from the first workshop
“Deep Learning doesn’t have to be a black box and is a potent tool in the right context with proper constraints. We discussed and implemented the various aspects and techniques fundamental to deep learning at the workshop. The level of discussion and implementation continues to showcase the sheer engineering talent in Kenya and the deep technical talent pool that we are known for across the continent. More efforts such as this will be vital in cementing our position as the Silicon Savannah. We appreciate NVIDIA for providing their state-of-the-art cloud-based GPU compute resources.”
Wilfred Odero
“The AI space is evidently a partnership-intensive space ranging from data collectors, developers, computing resources manufacturers, data regulators, etc. I may not have a clear bird’s-eye view of the scale of what’s happening on the ground, but from where I sit, the continent is taking off in terms of organizing itself toward a structure/ecosystem of some sort that supports the continent’s unanimous AI strategy and AI policy frameworks, with efforts such as the AU-commissioned ‘African stance on Artificial Intelligence’ and a number of big-tech sponsored tech hubs specializing on AI/ML-focused solutions. At the moment, most of the effort is being put into developing ready talent, though all stakeholders need to be ready.”
Rita Grace
“The exciting world of deep learning was introduced with practical examples and by the end of the day we could train models with over 95% accuracy. The training was well planned and our instructor Jacques Khisa explained all the topics in detail. It was a great experience to set up my own AI application development environment and earn a certificate in Fundamentals of Deep Learning. I would like to thank NVIDIA AI Emerging Chapters and Africa Data School for their workshops and commitment to developing future leaders in AI.”
Ibrahim Abdi
Conclusion
Joining the NVIDIA developer program and making Africa Data School a part of the Emerging Chapters community has helped us elevate our technology skills and connect with like-minded local and global professionals.
The NVIDIA Emerging Chapters program is for developer communities. If you are interested in starting a local chapter, apply to the NVIDIA Emerging Chapters pilot program.
For more about developer communities and upcoming educational series webinars, see the NVIDIA Emerging Chapters program page.
 This post covers best practices for using SetStablePowerState on NVIDIA GPUs. To get a high and consistent frame rate in your applications, see all Advanced API Performance tips.
This post covers best practices for using SetStablePowerState on NVIDIA GPUs. To get a high and consistent frame rate in your applications, see all Advanced API Performance tips.
This post covers best practices for using SetStablePowerState on NVIDIA GPUs. To get a high and consistent frame rate in your applications, see all Advanced API Performance tips.
Most modern processors, including GPUs, change processor core and memory clock rates during application execution. These changes can vary performance, introducing errors in measurements and rendering comparisons between runs difficult.
Recommended
- Use the
nvidia-smiutility to set the GPU core and memory clocks before attempting measurements. This command is installed by typical driver installations on Windows and Linux. Installation locations may vary by OS version but should be fairly stable.- Run commands on an administrator console on Windows, or prepend
sudoto the following commands on Linux-like OSs.
- To query supported clock rates
nvidia-smi --query-supported-clocks=timestamp,gpu_name,gpu_uuid,memory,graphics --format=csv
- To set the core and memory clock rates, respectively:
nvidia-smi --lock-gpu-clocks=nvidia-smi --lock-memory-clocks=
- Perform performance capture or other work.
- To reset the core and memory clock rates, respectively:
nvidia-smi --reset-gpu-clocksnvidia-smi --reset-memory-clocks
- For general use during a project, it may be convenient to write a simple script to lock the clocks, launch your application, and after exit, reset the clocks.
- For command-line help, run
nvidia-smi --help. There are shortened versions of the commands listed earlier for your convenience.
- For more information, see NVIDIA System Management Interface.
- Run commands on an administrator console on Windows, or prepend
- Use the DX12 function
SetStablePowerStateto read the GPU’s predetermined stable power clock rate. The stable GPU clock rate may vary by board.- Modify a DX12 sample to invoke
SetStablePowerState. - Execute
nvidia-smi -q -d CLOCK, and record the Graphics clock frequency with theSetStablePowerStatesample running. Use this frequency with the--lock-gpu-clocksoption.
- Modify a DX12 sample to invoke
- Use Nsight Graphics’s GPU Trace activity with the option to lock core and memory clock rates during profiling (Figure 1).
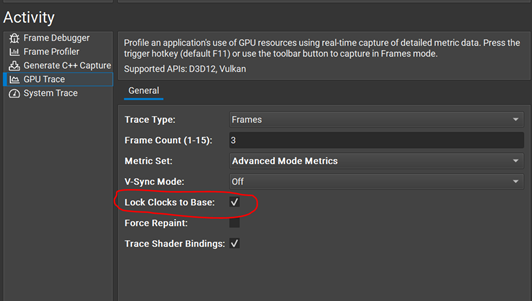
Not recommended
- Don’t lock the GPU core clock using DX12’s
SetStablePowerStatefunction only. This does not lock the memory clock and results are less comparable than achievable withnvidia-smi.
Taiwan has nearly 85,000 kidney dialysis patients — the highest prevalence in the world based on population density. Taipei Veterans General Hospital (TVGH) is working to improve outcomes for these patients with an AI model that predicts heart failure risk in real time during dialysis procedures. Cardiovascular disease is the leading cause of death for Read article >
The post Detect to Protect: Taiwan Hospital Deploys Real-Time AI Risk Prediction for Kidney Patients appeared first on NVIDIA Blog.
Categories
Tensorflow v2.6 CUDA v11.7 not utilising GPU
I am a beginner. I have installed Tensorflow version 2.6.0 and cuda version 11.7. However, tensorflow is not utilizing GPU. When I use tf.config.list_physical_devices(‘GPU’), it gives an empty object. Could anyone help me with this?
submitted by /u/ArunabhB
[visit reddit] [comments]
Hi all,
My question is linked to a question I asked recently: post
I need to loop over individual samples when training due to too large a batch size to hold in memory. I have had good success generating reproducible losses and and accumulated gradients with one of the training loops I am carrying out – and, applied gradients to weights are accurate (plus floating point errors) –
another custom loop I am carrying out on a batch is the mean squared error between a predicted label and the real label. Again, I need to iterate over the batch of samples manually due to a large batch size. To confirm it works, and I get the same losses and gradients, I am comparing my custom loop on a batch of 100 samples so i can compare both methods using ‘GradientTape()’
My code snippet is as follows: for batch training:
with tf.GradientTape() as tape:
value_loss = tf.reduce_mean((return_buffer – critic_model([degree_buffer, graph_adj_buffer, action_vect_buffer])) ** 2)
value_grads = tape.gradient(value_loss, critic_model.trainable_variables)
value_optimizer.apply_gradients(zip(value_grads, critic_model.trainable_variables))
for individual samples:
value_loss_tracking = []total_loss = 0train_vars_val = critic_model_individual.trainable_variablesaccum_gradient_val = [tf.zeros_like(this_var) for this_var in train_vars_val]for adj_ind, degree_ind, action_vect_ind, return_ind in zip(graph_adj_buffer, degree_buffer, action_vect_buffer, return_buffer_):adj_ind = adjacency_normed_tensor(adj_ind)degree_ind = tf.expand_dims(degree_ind, 0)action_vect_ind = tf.expand_dims(action_vect_ind, 0)
with tf.GradientTape() as tape:
ind_value_loss = tf.square(return_ind – critic_model_individual([degree_ind, adj_ind, action_vect_ind]))
value_loss_tracking.append(ind_value_loss)
total_loss += ind_value_lossgradients = tape.gradient(ind_value_loss,train_vars_val)
accum_gradient_val = [(acum_grad + grad) for acum_grad, grad in zip(accum_gradient_val, gradients)]
accum_gradient_vals_final = [this_grad / steps_per_epoch for this_grad in accum_gradient_val]policy_optimizer_ind.apply_gradients(zip(accum_gradient_vals_final, train_vars_val))
mean_loss = tf.reduce_mean(value_loss_tracking)
forgive the lack of indentation, but both loops work fine (in bold is the loss) – however, when I look at the loss in my custom loop relative to the mean squared error in the batch loop, the values are different starting sometimes from one decimal place – and they do not look like floating point errors to me. i.e. 0.43429542 and 0.4318762 – these seem really different to me to be floating point errors – in the other custom loop, i see floating points changing after about 5 decimal places… this is not the case here. sometime i will even see losses like 0.39 compared 0.40 – this seems not right to me. does anybody if this makes sense, or agree that this does not look right? I have tried np.mean and np.square also – I have looked at source code and cannot see exactly how Tensorflow does this under the hood!
any help is appreciated!
submitted by /u/amjass12
[visit reddit] [comments]
Categories
Tensorflow-Lite not recognizing interpreter
This is my code:
#include <iostream> #include <cstdio> #include <iomanip> #include "src/VideoProcessing.h" #include <opencv2/opencv.hpp> #include <opencv2/videoio.hpp> #include <opencv2/highgui.hpp> #include <interpreter.h> #include "tensorflow/lite/interpreter.h" #include "tensorflow/lite/kernels/register.h" #include "tensorflow/lite/model.h" #include "tensorflow/lite/model_builder.h" #include "tensorflow/lite/interpreter_builder.h" #include "tensorflow/lite/optional_debug_tools.h" #include "tensorflow/lite/tools/gen_op_registration.h" typedef cv::Point3_<float> Pixel; void normalize(Pixel &pixel) {...} int main() { ... auto model = tflite::FlatBufferModel::BuildFromFile("/home/me/tensorflow_src/tensorflow/lite/examples/model-verification/pose_landmark_full.tflite"); if(!model){ printf("Failed to mmap modeln"); exit(0); } tflite::ops::builtin::BuiltinOpResolver resolver; std::unique_ptr<tflite::Interpreter> interpreter; ...
The last line std::unique_ptr<tflite::Interpreter> interpreter; is throwing an error, suggesting that interpreter, and associated classes, are undefined. This is the error:
/usr/bin/ld: tensorflow-lite/libtensorflow-lite.a(interpreter.cc.o): in function `tflite::Interpreter::SetProfilerImpl(std::unique_ptr<tflite::Profiler, std::default_delete<tflite::Profiler> >)': interpreter.cc:(.text+0x2a66): undefined reference to `tflite::profiling::RootProfiler::RemoveChildProfilers()' /usr/bin/ld: interpreter.cc:(.text+0x2a75): undefined reference to `tflite::profiling::RootProfiler::AddProfiler(std::unique_ptr<tflite::Profiler, std::default_delete<tflite::Profiler> >&&)' /usr/bin/ld: interpreter.cc:(.text+0x2ab2): undefined reference to `vtable for tflite::profiling::RootProfiler' /usr/bin/ld: interpreter.cc:(.text+0x2b19): undefined reference to `vtable for tflite::profiling::RootProfiler' /usr/bin/ld: tensorflow-lite/libtensorflow-lite.a(interpreter.cc.o): in function `tflite::Interpreter::~Interpreter()': interpreter.cc:(.text+0x307e): undefined reference to `vtable for tflite::profiling::RootProfiler' /usr/bin/ld: tensorflow-lite/libtensorflow-lite.a(interpreter.cc.o): in function `tflite::profiling::RootProfiler::~RootProfiler()': interpreter.cc:(.text._ZN6tflite9profiling12RootProfilerD0Ev[_ZN6tflite9profiling12RootProfilerD5Ev]+0x7): undefined reference to `vtable for tflite::profiling::RootProfiler' /usr/bin/ld: tensorflow-lite/libtensorflow-lite.a(interpreter.cc.o): in function `tflite::profiling::RootProfiler::~RootProfiler()': interpreter.cc:(.text._ZN6tflite9profiling12RootProfilerD2Ev[_ZN6tflite9profiling12RootProfilerD5Ev]+0x7): undefined reference to `vtable for tflite::profiling::RootProfiler' collect2: error: ld returned 1 exit status make[2]: *** [CMakeFiles/model-verification.dir/build.make:247: model-verification] Error 1 make[1]: *** [CMakeFiles/Makefile2:1374: CMakeFiles/model-verification.dir/all] Error 2 make: *** [Makefile:149: all] Error 2
And I only get this error when I use `tflite::interpreter` despite having the correct `interpreter.h` file.
This is how I compile:
cmake ../tensorflow/lite/examples/model-verification/ make ./model-verification
This is my Cmake output:
cmake ../tensorflow/lite/examples/model-verification/ -- Setting build type to Release, for debug builds use'-DCMAKE_BUILD_TYPE=Debug'. CMake Warning at /home/me/tensorflow_src/build/abseil-cpp/CMakeLists.txt:74 (message): A future Abseil release will default ABSL_PROPAGATE_CXX_STD to ON for CMake 3.8 and up. We recommend enabling this option to ensure your project still builds correctly. -- Standard libraries to link to explicitly: none -- The Fortran compiler identification is GNU 11.2.0 -- Could NOT find CLANG_FORMAT: Found unsuitable version "0.0", but required is exact version "9" (found CLANG_FORMAT_EXECUTABLE-NOTFOUND) -- -- Configured Eigen 3.4.90 -- -- Proceeding with version: 2.0.6.v2.0.6 -- CMAKE_CXX_FLAGS: -std=c++0x -Wall -pedantic -Werror -Wextra -Werror=shadow -faligned-new -Werror=implicit-fallthrough=2 -Wunused-result -Werror=unused-result -Wunused-parameter -Werror=unused-parameter -fsigned-char -- Configuring done -- Generating done -- Build files have been written to: /home/onur/tensorflow_src/build
submitted by /u/janissary2016
[visit reddit] [comments]
For a simple TF2 Object detection CNN architecture defined using Keras’s functional API, a batch of data is obtained as:
example, label = next(data_generator(batch_size = 32)) example.keys() # dict_keys(['image']) image = example['image'] image.shape # (32, 144, 144, 3) label.keys() # dict_keys(['class_out', 'box_out']) label['class_out'].shape, label['box_out'].shape # ((32, 9), (32, 2))
The CNN architecture defined using Keras’s functional API is:
input_ = Input(shape = (144, 144, 3), name = 'image') # name - An optional name string for the Input layer. Should be unique in # a model (do not reuse the same name twice). It will be autogenerated if it isn't provided. # Here 'image' is the Python3 dict's key used to map the data to one of the layer in the model. x = input_ # Define a conv block- x = Conv2D(filters = 64, kernel_size = 3, activation = 'relu')(x) x = BatchNormalization()(x) x = MaxPool2D(pool_size = 2)(x) x = Flatten()(x) # flatten the last pooling layer's output volume x = Dense(256, activation='relu')(x) # We are using a data generator which yields dictionaries. Using 'name' argument makes it # possible to map the correct data generator's output to the appropriate layer class_out = Dense(units = 9, activation = 'softmax', name = 'class_out')(x) # classification output box_out = Dense(units = 2, activation = 'linear', name = 'box_out')(x) # regression output # Define the CNN model- model = tf.keras.models.Model(input_, [class_out, box_out]) # since we have 2 outputs, we use a list
I am attempting to define it using Model sub-classing as:
class OD(Model): def __init__(self): super(OD, self).__init__() self.conv1 = Conv2D(filters = 64, kernel_size = 3, activation = None) self.bn = BatchNormalization() self.pool = MaxPool2D(pool_size = 2) self.flatten = Flatten() self.dense = Dense(256, activation = None) self.class_out = Dense(units = 9, activation = None, name = 'class_out') self.box_out = Dense(units = 2, activation = 'linear', name = 'box_out') def call(self, x): x = tf.nn.relu(self.bn(self.conv1(x))) x = self.pool(x) x = self.flatten(x) x = tf.nn.relu(self.dense(x)) x = [tf.nn.softmax(self.class_out(x)), self.box_out(x)] return x A batch of training data is obtained as: example, label = next(data_generator(batch_size = 32)) example.keys() # dict_keys(['image']) image = example['image'] image.shape # (32, 144, 144, 3) label.keys() # dict_keys(['class_out', 'box_out']) label['class_out'].shape, label['box_out'].shape # ((32, 9), (32, 2))
Is my Model sub-classing architecture equivalent to Keras’s functional API?
submitted by /u/grid_world
[visit reddit] [comments]