The new Amazon EC2 G5g instances feature the AWS Graviton2 processors and NVIDIA T4G Tensor Core GPUs, to power rich android game streaming for mobile devices.
Today at AWS re:Invent 2021, AWS announced the general availability of Amazon EC2 G5g instances—bringing the first NVIDIA GPU-accelerated Arm-based instance to the AWS cloud. The new EC2 G5g instance features AWS Graviton2 processors, based on the 64-bit Arm Neoverse cores, and NVIDIA T4G Tensor Core GPUs, enhanced for graphics-intensive applications.
This powerful combination creates an optimal development environment for Android game content. It also brings a richer Android gaming experience to be streamed to a diverse set of mobile devices anywhere.
Unlocking enhanced Android game streaming for mobile devices
EC2 G5g instances enable game developers to support and optimize games for high-quality streaming on a wide range of mobile devices. You can develop Android games natively on Arm-based Graviton2 processors, accelerate graphics rendering and encoding with NVIDIA T4G GPUs, and stream games to mobile devices eliminating the need for emulation software and cross-compilation.
This brings together breakthrough graphics performance powered by NVIDIA RTX technology, the price performance of AWS Graviton2 processors, and the elastic scaling of the AWS cloud for Android-in-the-Cloud gaming services.
A number of customers are already building cloud game development and gaming platforms on AWS, and are up and running on the new G5g instance.
Initially a simple, fast, developer’s favorite Android emulator, Genymotion has evolved into a full-fledged Android platform, available across multiple channels both in the cloud and on your desktop. NVIDIA has worked closely with Genymobile to accelerate its platform on the G5g instances, improving the performance and density of its solution in the cloud.
now.gg offers a mobile cloud gaming platform that enables game developers to publish games directly to the cloud. By leveraging the power of the new G5g instances, now.gg enables gamers to access and stream high-performance games on mobile devices anywhere without lag or compromising on gaming experience
The company has launched its Anbox Cloud Appliance, a small-scale version of Canonical’s Anbox Cloud, built for rapid prototyping of Android-in-the-Cloud solutions on the new G5g instance. Additionally, AWS Marketplace makes Anbox Cloud readily available with access to a more extensive set of instance types, including support for Arm CPUs and NVIDIA GPUs. Developers can upload their Android apps, configure and virtualize Android devices, and stream graphical output in real time to any web or mobile client. This development environment allows you to unleash your creativity to invent new user experiences.
Accelerating Arm-based HPC and AI
In addition to being a great gaming and game development platform, AWS’ new G5g instance also brings the NVIDIA Arm HPC SDK to cloud computing. With support for the NVIDIA T4G GPU and the Arm-based Graviton CPU, the NVIDIA Arm HPC SDK provides the tools you need to build NVIDIA GPU-accelerated HPC applications in the cloud.
EC2 G5g instances can also be used to build and deploy high-performance, cost-effective AI-powered applications at scale. Developers can use the NVIDIA Deep Learning Amazon Machine Image on AWS Marketplace. This comes preconfigured with all the necessary NVIDIA drivers, libraries, and dependencies to run Arm-enabled software from the NVIDIA NGC catalog.
Learn more about the G5g instances and get started.
NVIDIA Clara medical AI models can now run natively on MD.ai in the cloud, enabling collaborative model validation and rapid annotation projects using modern web browsers.
Medical imaging AI models built with NVIDIA Clara can now run natively on MD.ai in the cloud, which enables collaborative model validation and rapid annotation projects using modern web browsers. These NVIDIA Clara models are free to use in any MD.ai project for collaborative research, such as for organ or tumor segmentation.
AI solutions have been shown to help streamline radiology and enterprise imaging workflows. However, the process to create, share, test, and scale computer vision models is not as streamlined for all modalities, conditions, and findings. Several critical components are needed to create robust models and support the most diverse acquisition devices and patient populations. These critical components can include the ability to create ground truth for unannotated imaging studies and the ability to collaborate worldwide to assess the use of models with validation data.
MD.ai’s real-time collaborative annotation platform and the NVIDIA Clara deep learning training framework are helping to create more robust model building and collaboration.
In this post, we walk through the basics of the Clara Train MMAR and the steps necessary to prepare it for use with MD.ai. In just a few steps, you can deploy any of these pretrained models on MD.ai for seamless web-based evaluation and collaboration. After they’re deployed on MD.ai, these models can be used in any existing or new MD.ai projects.
Figure 1. Workflow needed to train and validate an AI model.
NVIDIA Clara Train
The Clara Train training framework is an application package built on the Python-based NVIDIA Clara Train SDK. This framework is designed to enable rapid implementation of deep learning solutions in medical imaging based on optimized, ready-to-use, pretrained medical imaging models built in-house by NVIDIA researchers.
The Clara Training framework uses a standard structure for models, the Medical Model Archive (MMAR), which contains the pretrained model as well as scripts that define end-to-end development workflows for training, fine-tuning, validation, and inference.
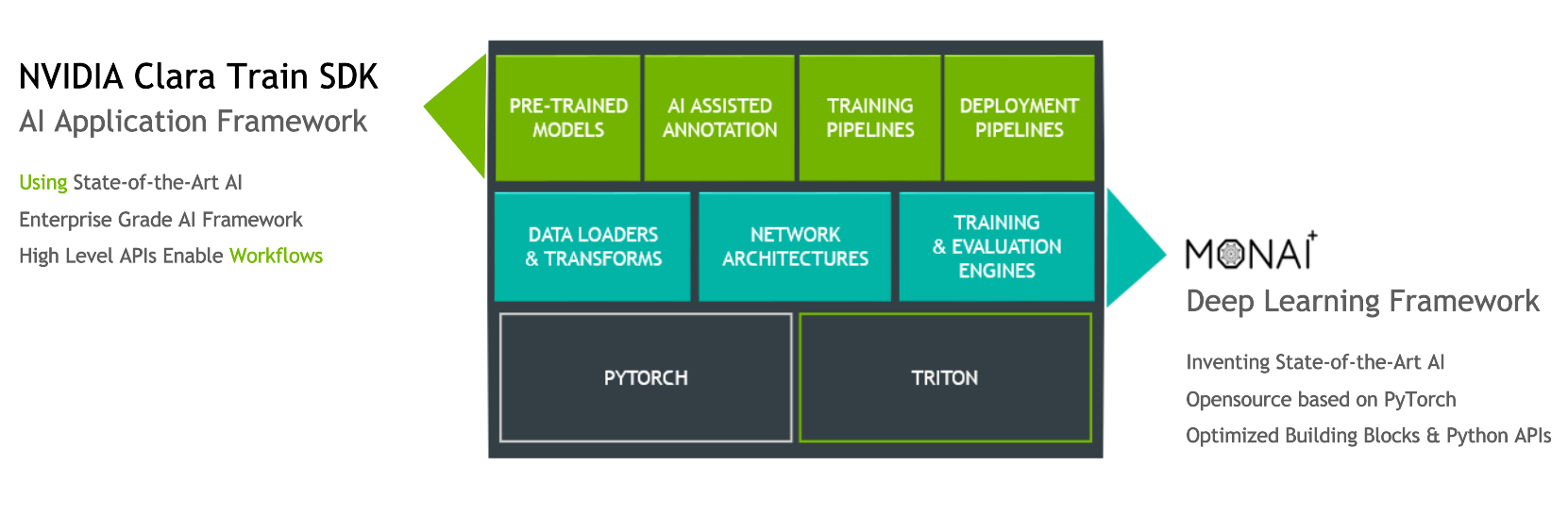
Figure 2. Clara Train SDK and MONAI Deep Learning Framework high-level architecture.
The Clara Train v4.0+ SDK uses a component-based architecture built on the open source, PyTorch-based framework MONAI(Medical Open Network for AI). MONAI provides domain-optimized foundational capabilities in healthcare imaging that can be used to build training workflows in a native PyTorch paradigm. The Clara Train SDK uses these foundational components such as optimized data loaders, transforms, loss functions, optimizers, and metrics to implement end-to-end training workflows packaged as MMARs.
MD.ai
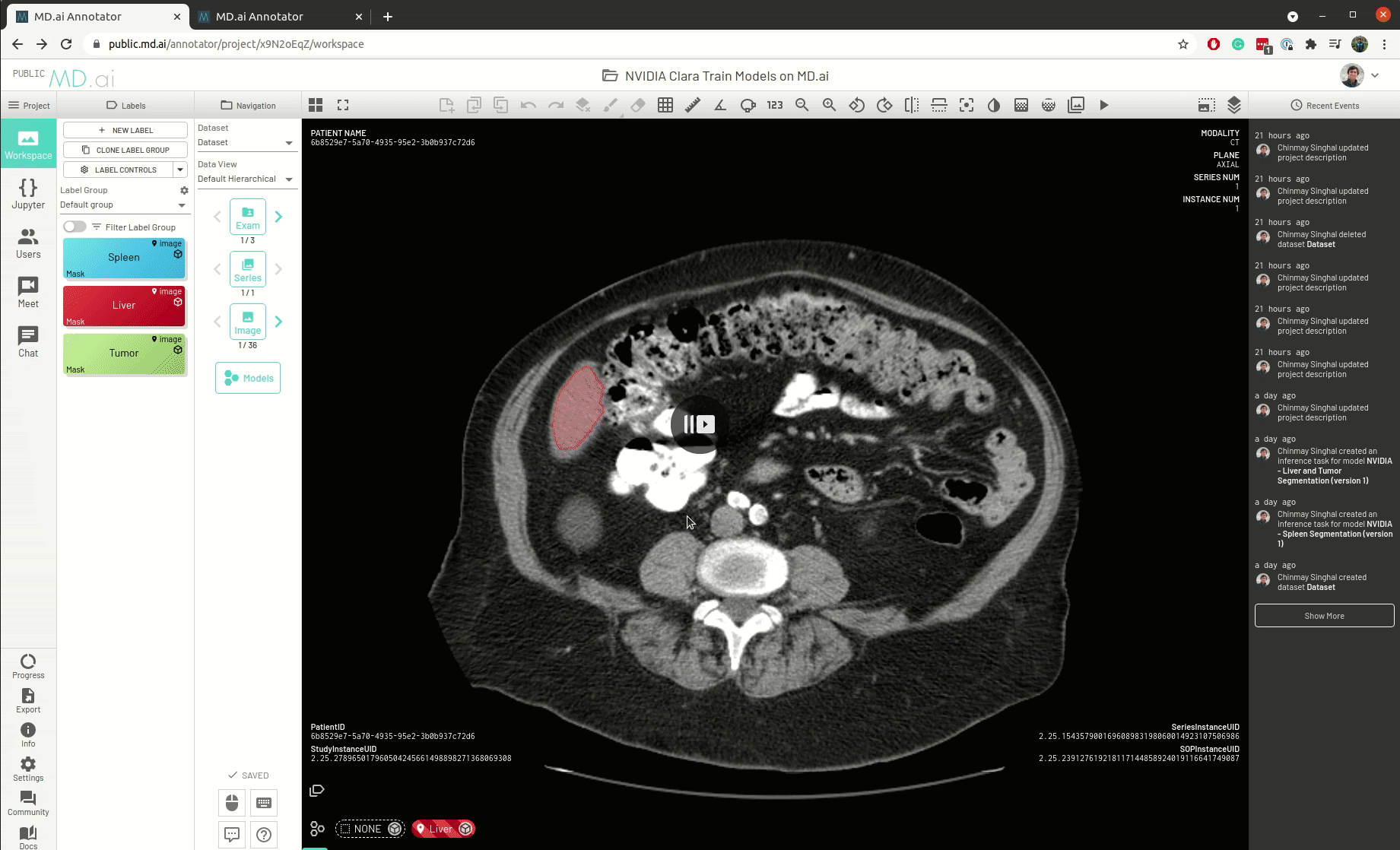
MD.ai provides a web-based and cloud native annotation platform that enables real-time collaboration among teams of clinicians and researchers, with shared workspaces. You can also load multiple deep learning models for real-time evaluation.
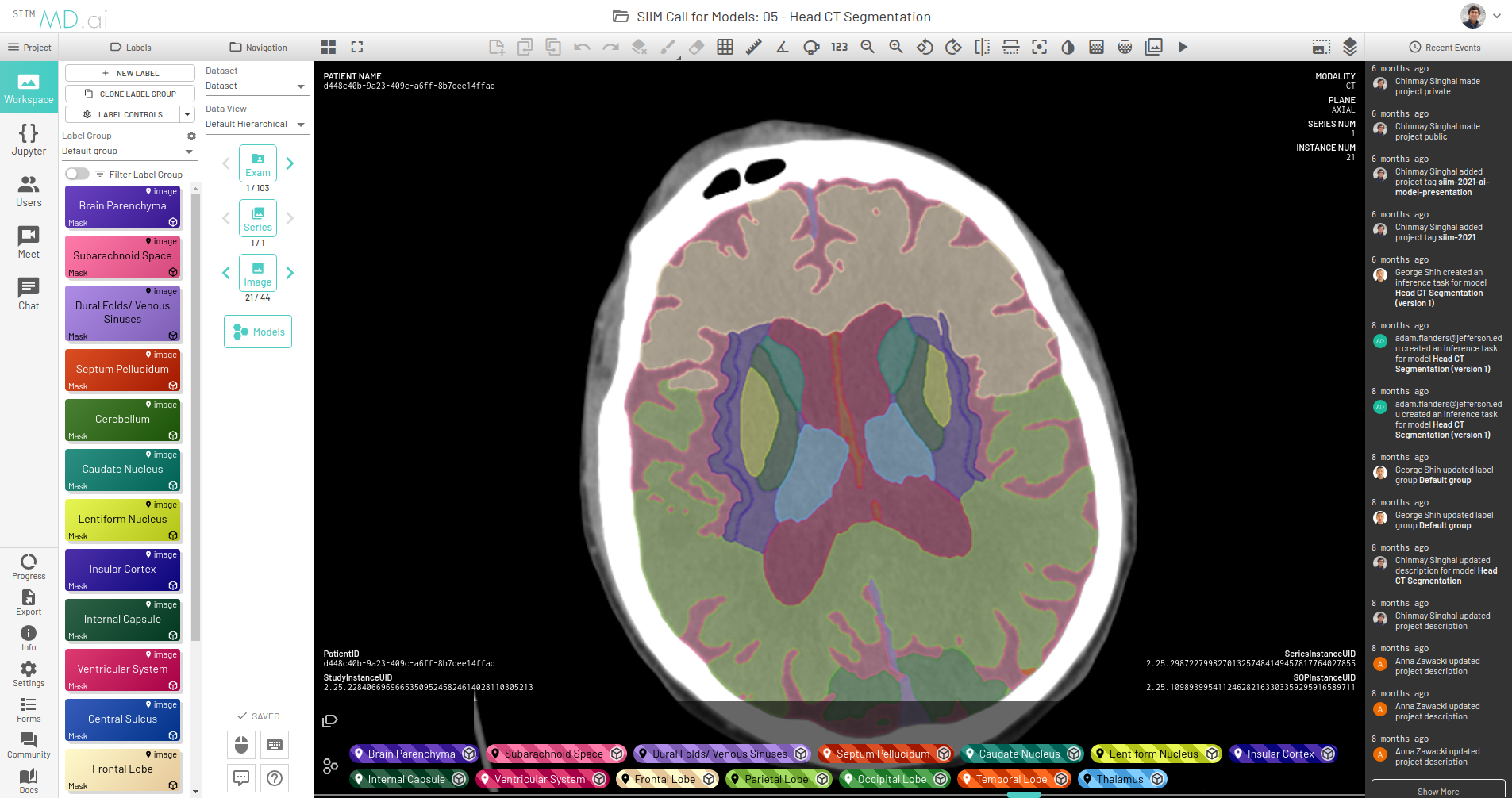
The platform provides an easy and seamless interface for dataset construction and AI project creation. It gives users a wide suite of tools for annotating data and building machine-learning algorithms to accelerate the application of AI in medicine, with a particular focus on medical imaging.
Figure 3. MD.ai user interface showing a brain segmentation.
Coupling this capability with the ability to quickly deploy Clara Train model MMARs on the MD.ai platform gives you an end-to-end workflow that spans rapid model development, model training, fine-tuning, inference, and rapid evaluation and visualization. This end-to-end capability streamlines the process of taking a model from research and development to production.
Solution overview
The starting point for Clara Train is the NGC Clara Train Collection. Here, you find the Clara Train SDK container, a collection of freely available, pretrained models, and a collection of Jupyter notebooks that walk through the main concepts of the SDK. All the Clara Train models share the MMAR format mentioned earlier.
The Clara Train MMAR defines a standard structure for storing the files required for defining the model development workflow, as well the files produced when executing the model for validation and inference. This structure is defined as follows:
ROOT
config
config_train.json
config_finetune.json
config_inference.json
config_validation.json
config_validation_ckpt.json
environment.json
commands
set_env.sh
train.sh train with single GPU
train_multi_gpu.sh train with 2 GPUs
finetune.sh transfer learning with CKPT
infer.sh inference with TS model
validate.sh validate with TS model
validate_ckpt.sh validate with CKPT
validate_multi_gpu.sh validate with TS model on 2 GPUs
validate_multi_gpu_ckpt.sh validate with CKPT on 2 GPUs
export.sh export CKPT to TS model
resources
log.config
...
docs
license.txt
Readme.md
...
models
model.pt
model.ts
final_model.pt
eval
all evaluation outputs: segmentation / classification results
metrics reports, etc.
All pretrained models provided for use with Clara Train, as well as custom models developed with the Clara Train framework, use this structure. To prepare an MMAR for use with MD.ai, we assume a pretrained model and focus on a couple key components for deployment.
The first component is the environment.json file that defines the common parameters for the model, including dataset paths and model checkpoints. For example, the environment.json file from the Clara Train spleen segmentation task defines the following parameters:
When preparing the model for integration with MD.ai, make sure that the MMAR contains the trained MMAR_CKPT and MMAR_TORCHSCRIPT in the MMAR’s models/ directory. These are generated by executing the bundled train.sh and export.sh, respectively.
The train.sh script executes model training, which requires DATA_ROOT and DATASET_JSON for the input dataset and generates the MMAR_CKPT.
The infer.sh script serializes this checkpoint into the MMAR_TORCHSCRIPT used for inference.
With a pretrained model, both the checkpoint and TorchScript are provided, and you can focus on the inference pipeline. Inference is executed using the MMAR’s infer.sh script:
This script runs inference on the validation subset, defined in config_validation.json, of the full dataset defined in environment.json. If reference test data is provided along with the MMAR, the paths to this data must be defined. When you integrate the MMAR, MD.ai handles the dataset directly, and these values are overridden as part of the integration.
To deploy your own pretrained AI models on MD.ai for inference, you must already have an existing project or create a new project on the platform. The project also must contain the dataset on which to test your model. For more information, see Set Up Project.
Next, to deploy your AI model, the inference code must be transformed into a specific format that is compatible with the platform. The following files are the bare minimum for a successful deployment:
For NVIDIA Clara models, we have further streamlined this for you and there is no need to write these files from scratch. We provide skeleton codes for each different category of deep learning models supported by the NGC catalog: classification, segmentation, and so on. You can download the model-specific skeleton code, make a few adjustments that are outlined later in this post, and then upload the models on MD.ai for inference.
Inference steps
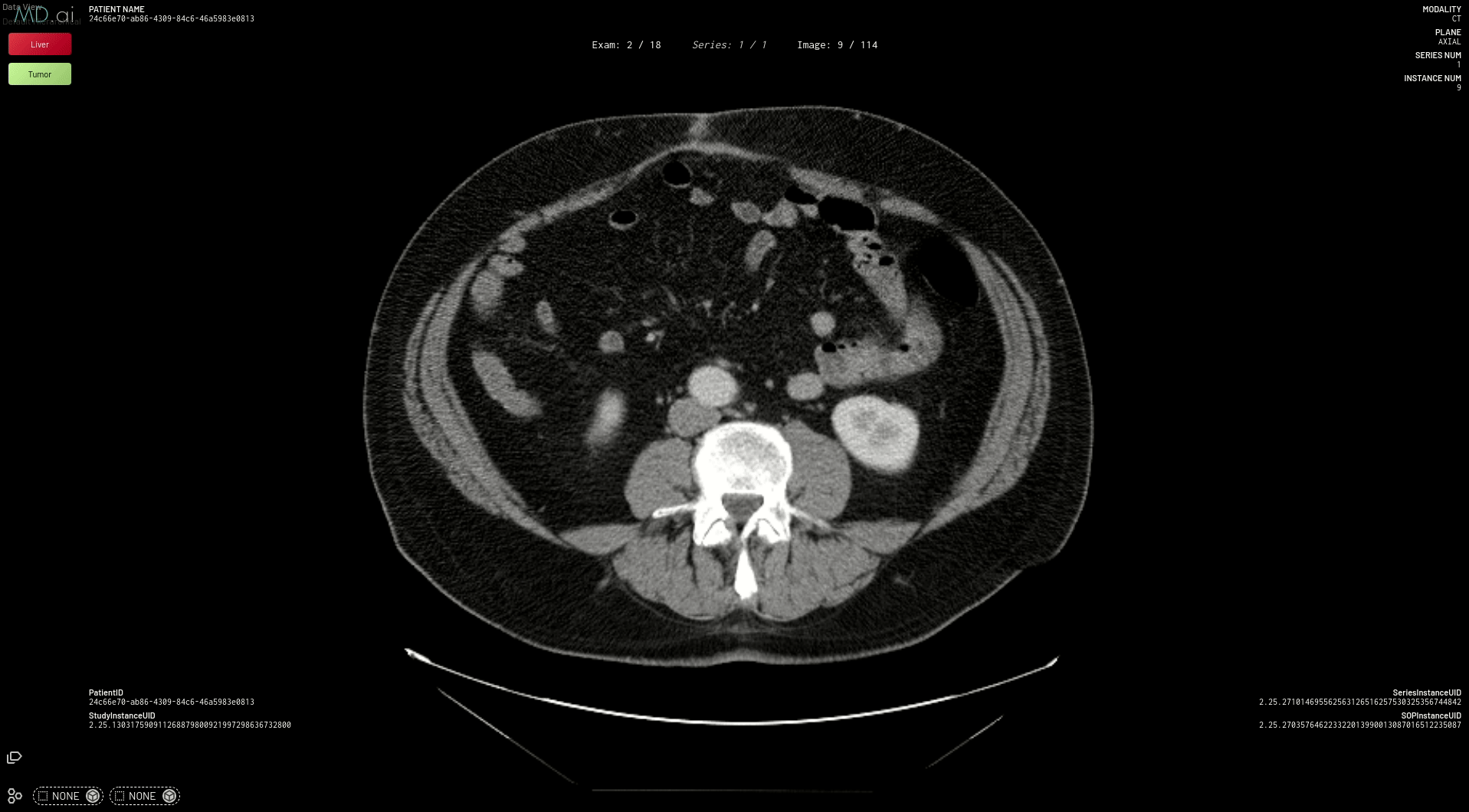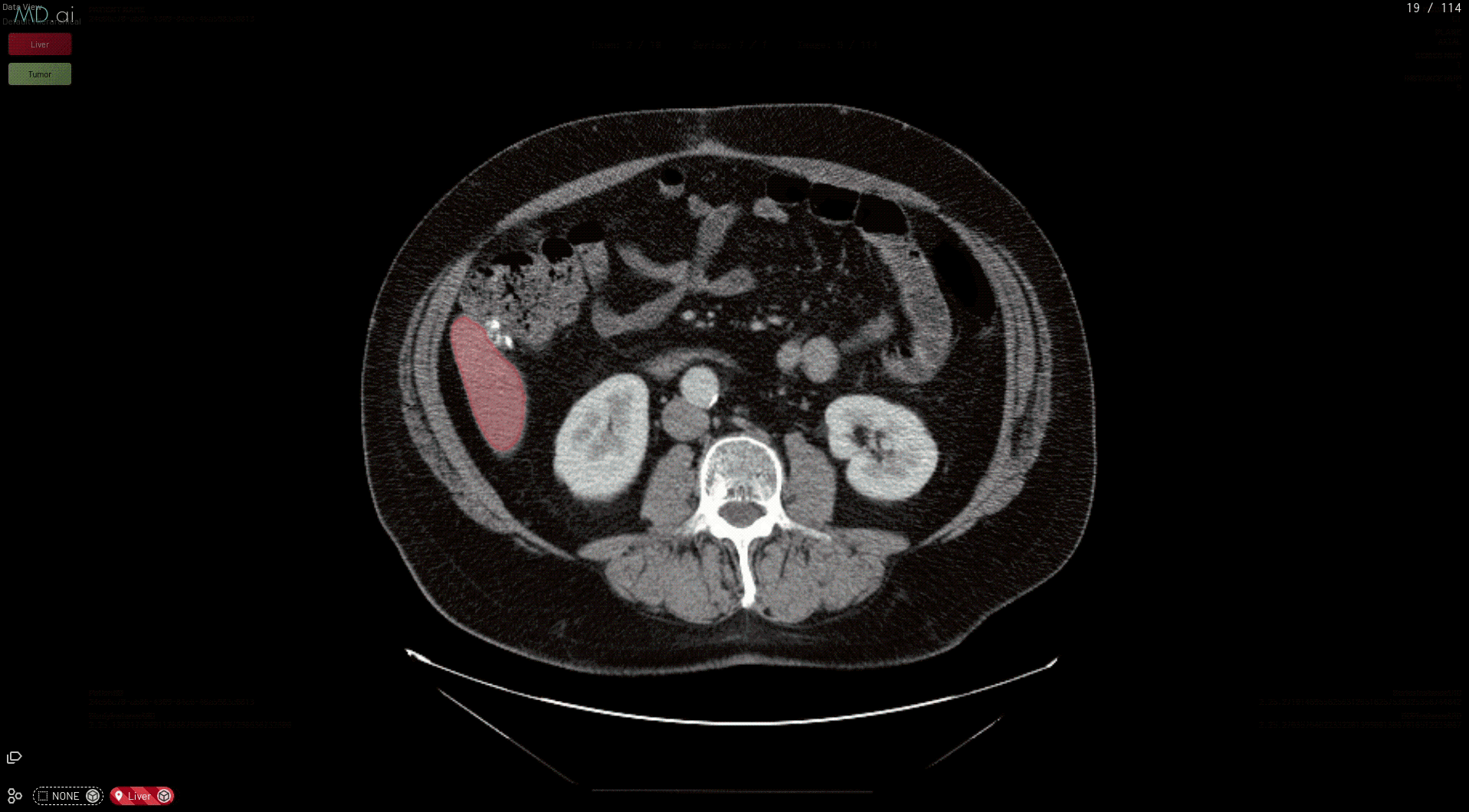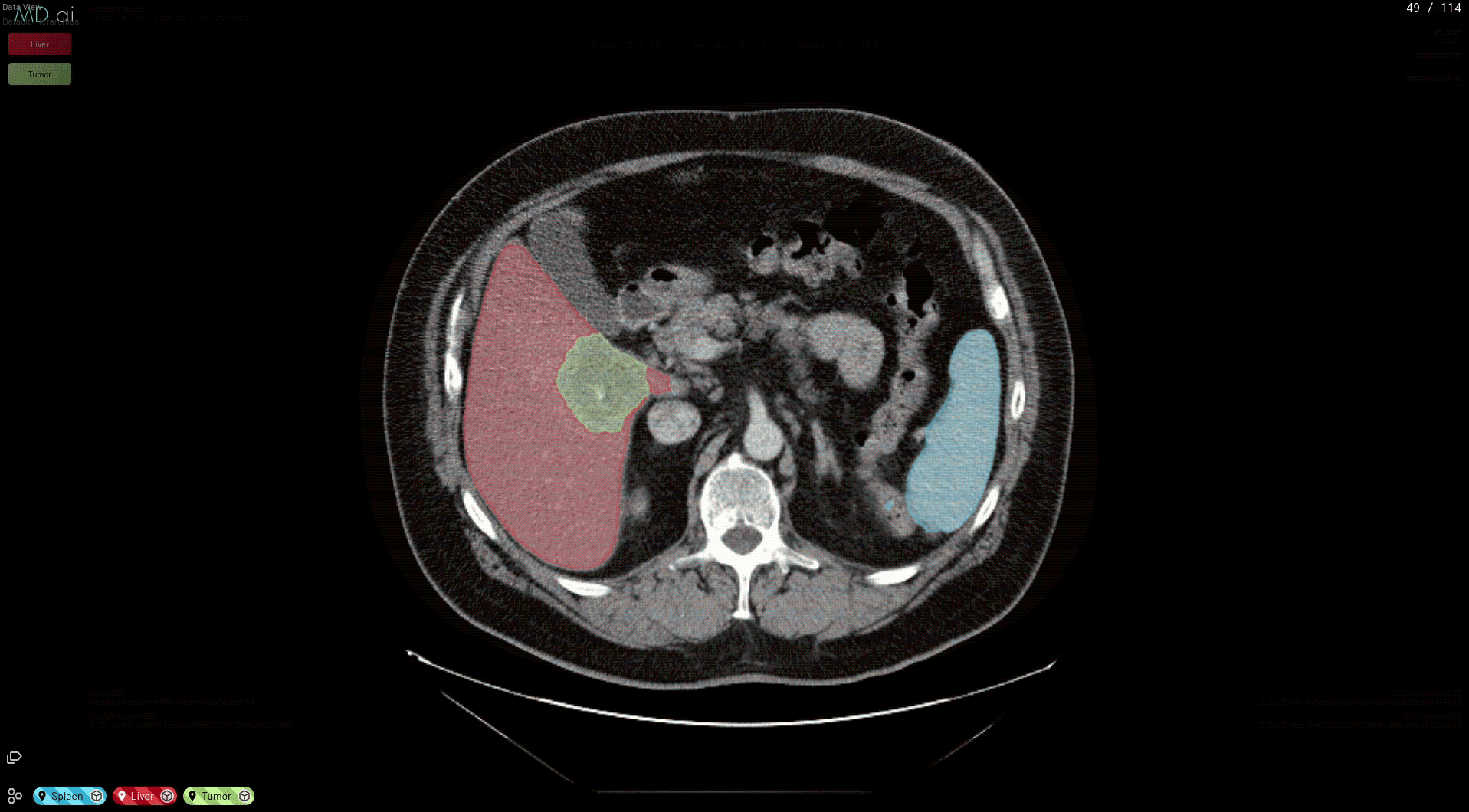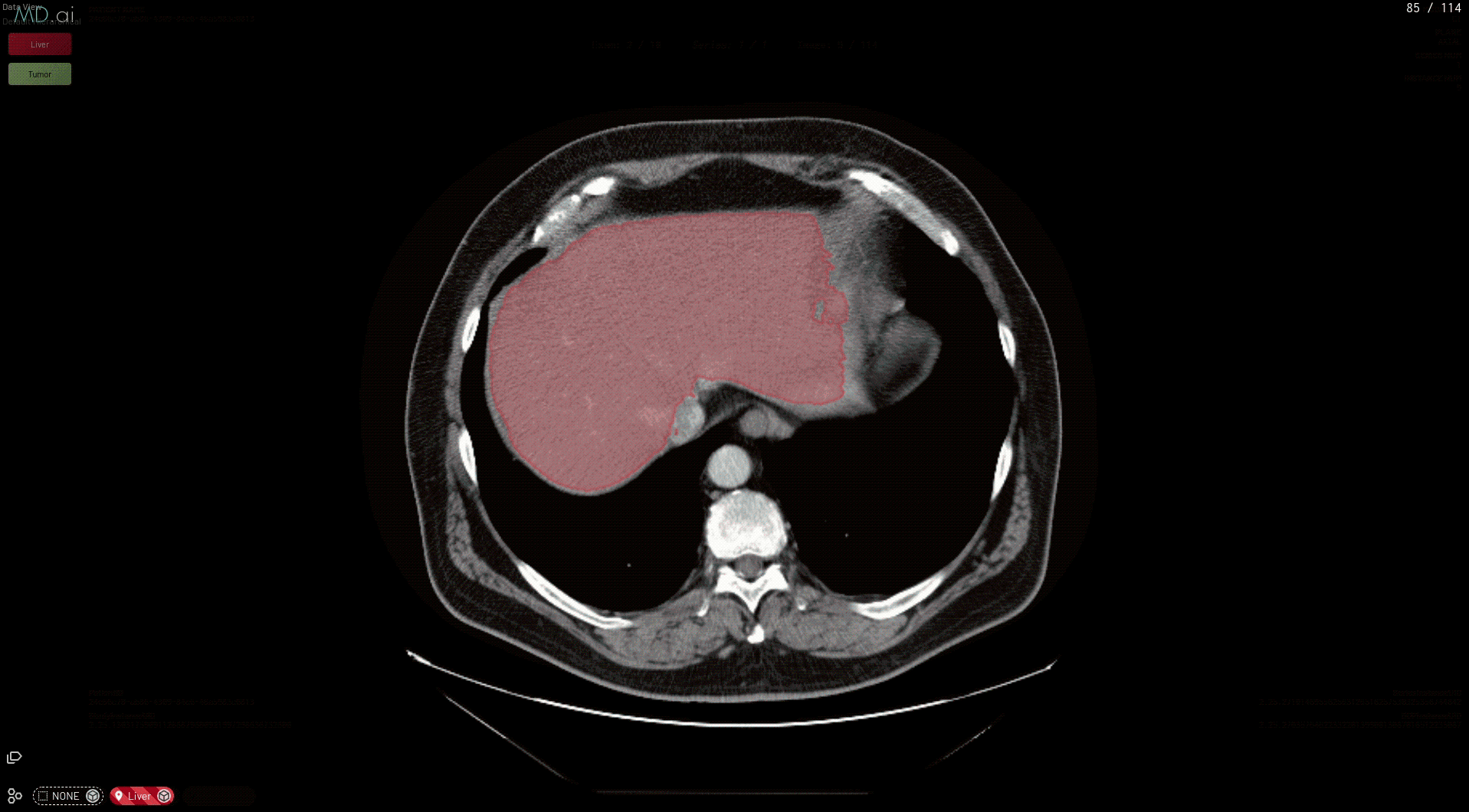
After you have an MMAR prepared, here’s how to use it directly for running the model on MD.ai. This post walks you through an example segmentation model that’s already deployed on the platform: the skeleton code for running segmentation models on MD.ai, which is actually the code for a CT spleen segmentation model from NVIDIA.
root_folder—Replace this key value with the name of your downloaded MMAR folder, such as clara_pt_liver_and_tumor_ct_segmentation_1for the liver and tumor example.
out_classes—Replace this value with the number of output classes for your model, such as 3 in this case (background: 0, liver: 1, and tumor: 2).
data_list_key—Replace with the key name mentioned in the data_list_key attribute of your MMAR’s config/config_inference.json file, such as testing.
In the /mdai folder, make the following changes:
In the config.yaml file, change the clara_version key to the appropriate version used by your model (for example, 3.1.01 or 4.0).
In requirements.txt, add any additional dependencies required, more than those provided by the NVIDIA Clara base image and those already present in the file.
This prepares your model for deployment on MD.ai. Both the spleen and liver tumor segmentation models have been deployed on the MD.ai platform and are available for evaluation.
When the code is ready, it must be wrapped in a zip file so that it can be uploaded on MD.ai for inference. For more information, see Deploying models.
Your model is now ready to be tried within MD.ai on any dataset of your choice!
Figure 4. Segmentation example on MD.ai
The best part is that all models need only be deployed one time on the MD.ai platform. As soon as an NVIDIA Clara model is deployed on MD.ai, it can be used in any MD.ai project by using the model cloning feature. Here’s an example of cloning the NVIDIA Liver Segmentation model into a new MD.ai project by just copying the value:
Figure 5. Model cloning workflow on MD.ai.
Future features
We are working towards streamlining the integration to minimize the steps required to deploy the MMAR, with plans to eliminate all code modification, so that deployment is as easy as just clicking a button.
MD.ai plans to predeploy all the models available on NGC so that you can use them directly by cloning from our public projects, saving you from the process of deploying MMARs on your own. We are also going to create NVIDIA Clara Starter Packs so that you can easily get started with selected models preattached to your project.
Another important plan is to add support for training AI models on MD.ai. When we have that, you can effectively use the NVIDIA AI-assisted annotation product on the platform to help users annotate much faster and much easier, rather than starting from scratch.
Summary
In this post, we highlighted key components of each platform and the steps necessary to quickly deploy a medical imaging model built with NVIDIA Clara on MD.ai.
The NVIDIA Clara developer kit, NVIDIA Clara Holoscan, and us4us front end help build AI models on streaming data for ultrasounds, to remove artifacts like aliasing.
At RSNA 2021, there are dedicated tracks on ultrasound imaging, which is a cost-effective way to see what is going on inside a patient’s body without exposure to radiation or the need for injections and surgeries.
Ultrasound imaging is typically done by trained sonographers and needs special expertise to interpret. The probe is a small transducer to both transmit sound waves into the body and record the waves that echo back. It is placed on the skin and as it moves, waves bounce off your blood cells, organs, and other body parts, and then back to the device. A computer then takes all the sound waves and turns them into moving images that you visualize on a screen.
The LITMUS group (Laboratory on Innovative Technology in Medical Ultrasound) at the University of Waterloo, Canada is working on making ultrasound color doppler imaging (CDI) easier to visualize. They used the NVIDIA Clara Holoscan platform, including the NVIDIA Clara AGX Developer Kit and the NVIDIA Clara Holoscan SDK, along with frontend us4us, to remove aliasing artifacts and increase the frame rate 12-fold- from 2 fps to 30 fps.
Clara Holoscan is an AI platform that includes strong deep learning compute ability that can run a model at high frame rates. The Clara Holoscan SDK is designed to facilitate the creation of AI pipelines for the processing of real-time streaming medical data for ultrasound, video, and other imaging applications.
The Clara AGX Developer Kit combines the power of an NVIDIA RTX 6000 GPU controlled by an NVIDIA AGX Xavier SoC, with external connectivity provided by two PCIe Gen4 x 8 slots, and a NVIDIA ConnectX-6 SmartNIC with a 100 GbE port.
Figure 1. Overview of the aliasing-resistant CDI pipeline on the Clara AGX Developer Kit and us4us frontend.
Color Doppler imaging
Color Doppler imaging (CDI) is a non-invasive way to see blood flow in arteries and veins. It is used to identify a blockage, blood clot, or narrowing of the arteries that can lead to deadly clinical outcomes such as a stroke or heart attack. These blockages can occur in a variety of arteries in the body and significantly alter the properties of blood flow. The flow alterations can be captured by CDI and used in the identification and monitoring of diseased conditions. CDI can also be used for detecting aneurysms, where swollen artery walls can also impact blood flow.
Figure 2 shows a typical CDI sequence obtained from a carotid artery model where flow comes in from the left side of the image, then branches out into the upper and lower branches. Flow speed in the artery is shown in shades of blue or red, depending on its direction relative to the probe. The surrounding grayscale image shows the tissue structure. The CDI sequence also shows how blood flow dynamics can change throughout the cardiac cycle, which is typically less than a second long.
Figure 2. Typical CDI sequence on an artery bifurcation model.
Aliasing problems in CDI
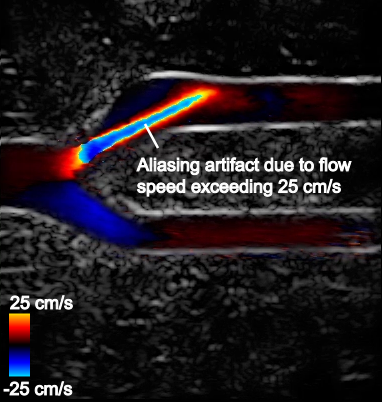
One recurring issue in CDI is the presence of so-called aliasing artifacts that hinder the visualization of blood flow. Aliasing artifacts occur when blood flow exceeds the maximum flow speed measurable by the CDI system.
For example, Figure 3 shows that flow in the upper branch is fastand exceeds the maximum measurable flow speed on the color scale (25 cm/s). The color chosen for this region is therefore picked from the opposite end of the color scale and incorrectly indicates that flow is going in the opposite direction. The maximum measurable speed stems from underlying system limitations and imaging considerations.
Aliasing is most problematic in tortuous vasculature such as bifurcations and in conditions where a wide range of multidirectional velocities are encountered. CDI in such conditions can become difficult to interpret.
Figure 3. CDI sequence on an artery bifurcation model with aliasing artifacts
Novel deep learning–based solution
The LITMUS group devised a new deep learning–based solution to address these aliasing artifacts in CDI for the femoral artery bifurcation. The femoral artery bifurcation in the thigh was chosen due to its diverse flow properties, including a wide range of flow speeds and multidirectional flow. The artery can be a site of blockage in conditions of peripheral artery disease and would be susceptible to aliasing in the bifurcation, even in healthy conditions.
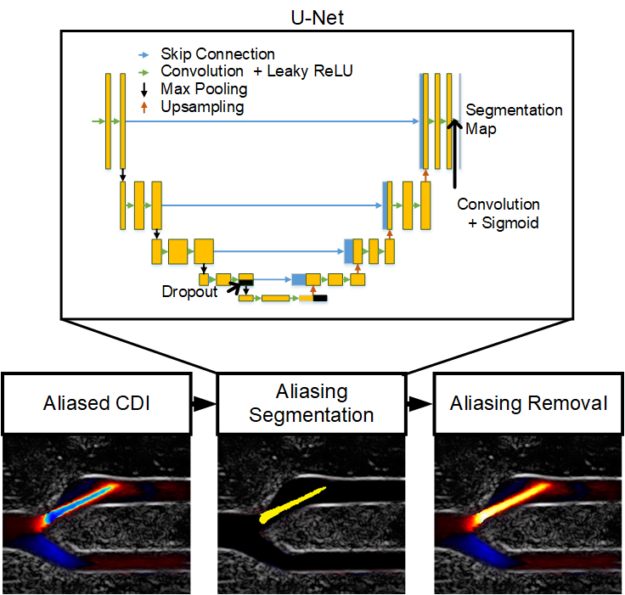
Figure 4. Overview of the CDI aliasing removal pipeline
To address aliasing artifacts in CDI, the LITMUS group devised a two-step process:
Aliasing artifacts in CDI are segmented using a convolutional neural network (CNN) model.
The segmented aliasing artifacts are subsequently removed by an adaptive technique.
For the aliasing segmentation, a U-Net CNN was trained to detect aliasing artifacts using several relevant ultrasound features that are often computed in typical CDI pipelines and can contain features that are relevant for aliasing detection. The network was trained on 1,136 frames obtained from three real femoral artery bifurcation acquisitions using a us4us ultrasound frontend. The aliasing artifacts in CDI were manually labelled for training and validation. The model definition and training were done in TensorFlow.
The segmentation maps were then leveraged by an adaptive phase unwrapping algorithm that reverses the aliasing artifact according to flow continuity criteria so that a smooth aliasing-free flow profile is achieved. The framework was then evaluated on a new acquisition from an unseen femoral artery bifurcation acquisition, where it was shown to deal with multidirectional and excessive aliasing.
The framework was computationally demanding, requiring more than 500 ms per frame for simple de-aliasing, and even slower for excessive aliasing cases.
Clara Holoscan for real-time de-aliasing in bedside applications
CDI is widely expected to be a point-of-care modality that can be used to gain quick and immediate insights into blood flow conditions in patients. Offline processing would disrupt this utility of CDI, so it is important that the aliasing removal framework be run in real time.
NVIDIA and the LITMUS group collaborated to accelerate the de-aliasing framework to achieve real-time performance that would be suitable in a bedside application, using the NVIDIA Clara Holoscan SDK and the NVIDIA Clara AGX Developer kit.
Raw sensor data is continuously copied to the NVIDIA RTX 6000 GPU in the Clara AGX developer kit where custom CUDA-built kernels perform the necessary processing for image formation. The pretrained U-Net TensorFlow model was implemented using the Tensor RT API and the adaptive phase unwrapping algorithm was accelerated using the CUDA-NPP library. Further CUDA and OpenGL functions were used for display. The result was a complete raw-sensor-data-to-de-aliased-CDI package that was run on the Clara AGX Developer Kit with demonstrated real-time performance.
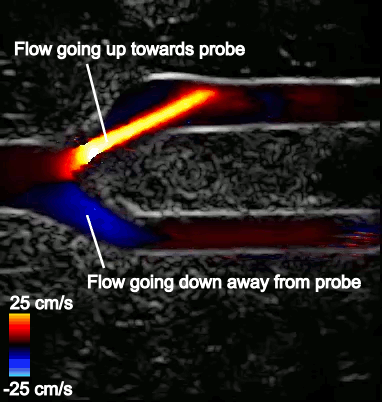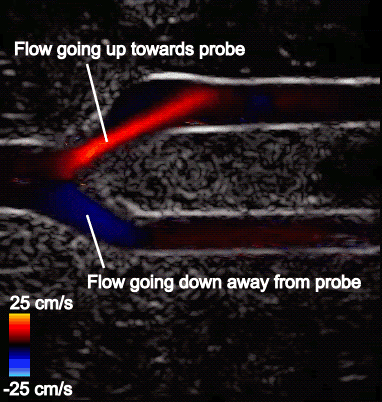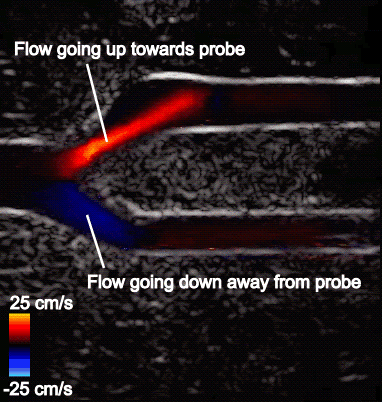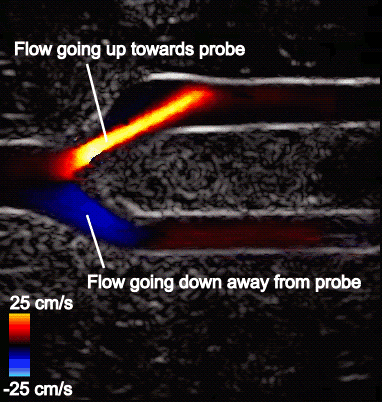
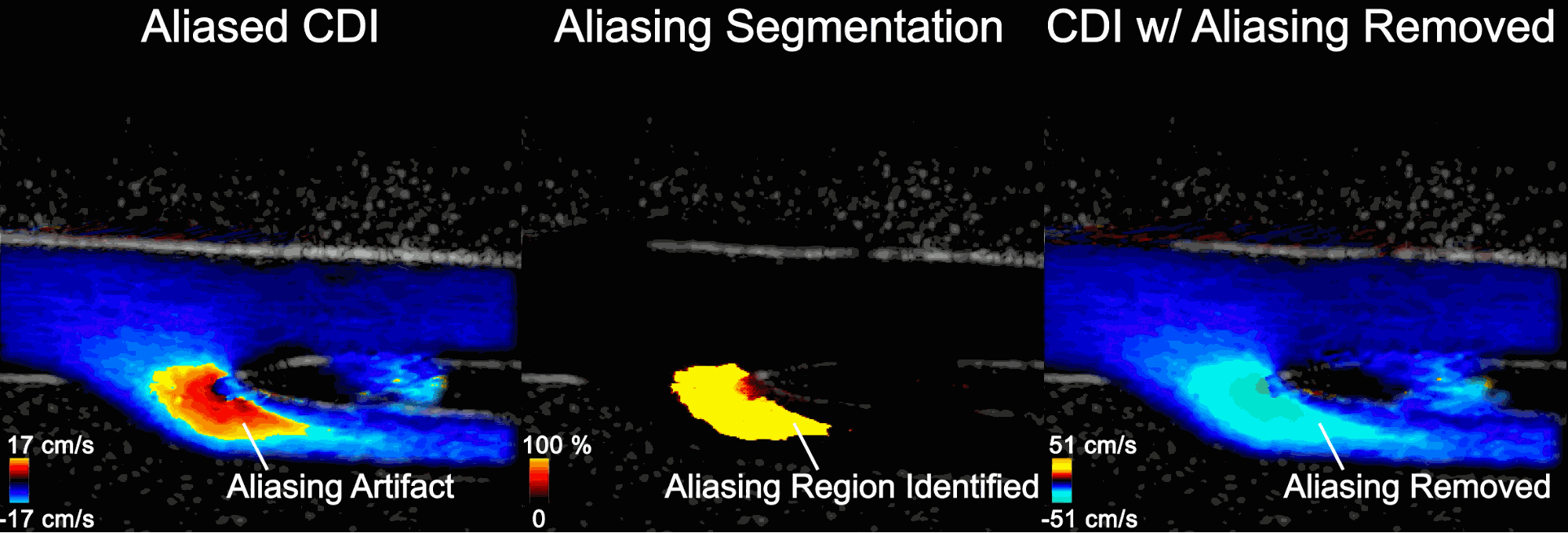
Figure 5 shows the aliasing resistant CDI framework in action on the Clara AGX developer kit, processing raw sensor data from a femoral bifurcation model to aliasing resistant CDI in live mode. The raw data was acquired using the us4us frontend, which gives researchers access to all the fundamental signals as they arrive from the probe:
Figure 5. Screen capture of the aliasing-resistant CDI platform on the Clara AGX Developer kit
Left: The aliased CDI sequence is obtained using a conventional processing pipeline. At systole (peak of the cardiac cycle, frozen frame), flow is moving away from the probe and should all be blue. In the bottom branch, however, the flow speed in the direction of the probe exceeds the maximum measurable and therefore appears as a red/orange shaded region that incorrectly suggests flow is going up.
Middle: Aliasing segmentation is obtained by the integrated U-Net model during the live imaging session. You can see how the aliasing artifact in the systolic frame is correctly captured on-site.
Right: The CDI sequence has the aliasing removed. The maximum measurable speed is increased and the visualization of blood flow is made more intuitive.
The processing time of the de-aliasing module was improved to 30 fps, a 12x improvement from the previous 2-2.5 fps. In building up to this, CuPy was used to prototype and get quick GPU acceleration, giving an intermediate ~15 fps.
Conclusion
The LITMUS group’s workflow showed how the NVIDIA Clara AGX Developer Kit and the NVIDIA Clara Holoscan SDK can resolve aliasing artifacts in CDI, in real time. Removing aliasing makes image visualization and interpretation easier by removing the ambiguity about the blood flow direction. This makes the most impact in tortuous vasculature where flow direction can be difficult to guess by the sonographer.
For more information, see the following resources:
This post features winners from the NVIDIA sponsored contest with Make: where makers submit their best robotics projects with a galactic theme.
Earlier this year, NVIDIA sponsored a contest with Make: Magazine, asking makers to submit their best AI-enabled droid projects with a galactic theme. Below are the two droid contest winners.
Figure 1. R2D2 robot. Courtesy of John Ferguson.
Autonomous 3D Printed R2-D2
During the Covid lockdown, John Ferguson looked for a fun project to build with his 11-year-old son. Using a 3D printer, John took on the massive task of creating every inch of his robot. About 40 kg of filament and 10 months of printing later, he had himself the body of an R2 unit. This hands-on project required sanding, prepping each piece, filling, painting, and tuning for a truly movie-grade finish.
A few components of the R2-D2 robot include Sabertooth Motor controllers, Sony cameras, two scooter motors, Arduino, NVIDIA Jetson Nano, a Muse EEG brainwave reader for an active periscope mechanism, and it is controlled with an Xbox 360 wireless controller. This project is a way for the Ferguson family to learn about AI, integrating NVIDIA Jetson Nano to activate R2’s vision-enabled object recognition capabilities and speech recognition.
“This is the first time we’ve done a project using object recognition and it’s a thrill. It really feels like the future is here! To teach children this capability and show them the interactivity—you really get stunned silence as a reaction,” said Ferguson.
Figure 2. 3D printed droid parts, banana for scale. Courtesy of John Ferguson.
When asked why John decided to implement the NVIDIA Jetson Nano into his project, he said that the plastic body of the R2 is heavy, so having a lightweight component is preferable. It’s also a premium option for object recognition using AI, easily integrated with Python apps, and a good system for a young person to learn with.
Figure 3. John’s son constructing droid. Courtesy of John Ferguson.
Their goal is to attend in-person events and have R2 autonomously strolling at their side using ROS2, identify other Star Wars characters accurately, and vocally respond just like the real thing. John and his son are building the body from scratch, training the recognition model using their own annotated image library, and optimizing the models.
“I’m not a developer. We’ve learned everything from videos and tutorials. We had the time and the passion, and that’s got us to where we are through experimenting and persistence,” Ferguson said.
At the heart of the R2-D2 project, John hopes to showcase the robot to local schools, outline his journey so that it’s replicable, and talk about the personal growth that comes with building something from scratch and having fun with robotics.
“I want to encourage young people to enjoy developing technology,” said Ferguson.
Figure 4. RoboJango holding an NVIDIA Jetson Nano Developer Kit. Courtesy of Jim Nason.
Next up, we have Jim Nason’s impressive Mandalorian-inspired droid named RoboJango.
This droid is packed with features that any Star Wars fanatic would be psyched to see. To name a few, this droid has HD vision for eyes, acoustic sensors, dual lidar to promote autonomy, heat sensors, off-roading ATV capabilities, and a powerful winch for getting out of sticky situations. Similar to the R2-D2 robot, the RoboJango incorporates 3D printed parts mounted onto a wood frame and steel core.
RoboJango is surprisingly personable. It uses human-like movements and conversational AI skills, giving people in the room casual greetings, flexing its “muscles”, and spitting jokes. The RoboJango recognizes Jim’s family members, their pets, and harnesses object recognition capabilities by self-organizing to a DNN. This is done with several Arduinos, a battery matrix, customized software framework, and NVIDIA Jetson Nano as its brain.
The coolest thing about RoboJango is the maker, Jim Nason. With a 30-year professional history in programming, he started building this robot because his son asked for a 3D printer and wanted to build an android with the materials.
Figure 5. Space cowboy, RoboJango posing with its NVIDIA Jetsons. Courtesy of Jim Nason.
Three years ago, Jim started by just building a finger, then an arm, eventually leading to an AI-enabled robot. RoboJango also has functional anthropomorphic eyes, with a wire-based circulatory system based on a virtual representation of a human.
Talking with Jim, you get the sense that he really understands the mantra of being a maker, which is to dream, learn, and innovate:
“I’m teaching him how to play the ukulele and drums. Just need to work on the movements,” Nason said.
Figure 6. Jim Nason, winner of Make: contest.
He also built a best friend for RoboJango, its very own robot dog.
Now, Jim wants to give back to the community and teach kids all about STEAM with his wacky and whimsical robotics projects. Since March of this year, Jim has taught over 1,500 virtual students across the United States and was awarded a 2021 Impact Award for his outstanding contributions to the classroom. On summer weekends, Jim hosted community builds in Long Beach where anyone could walk in and learn about robotics.
“RoboJango was created to drive funding for Long Island robotics apprentices. We want to teach to all communities and allow kids to have a ball,” said Nason
Learn more about Jim’s robotics course here, and follow his adventures on Instagram.
Thank you to our friends at Make: for hosting this contest.
Carol Song is opening a door for researchers to advance science on Anvil, Purdue University’s new AI-ready supercomputer, an opportunity she couldn’t have imagined as a teenager in China. “I grew up in a tumultuous time when, unless you had unusual circumstances, the only option for high school grads was to work alongside farmers or Read article >
NVIDIA is making it easier than ever for researchers to harness federated learning by open-sourcing NVIDIA FLARE, a software development kit that helps distributed parties collaborate to develop more generalizable AI models. Federated learning is a privacy-preserving technique that’s particularly beneficial in cases where data is sparse, confidential or lacks diversity. But it’s also useful Read article >
Whether facilitating cancer screenings, cutting down on false positives, or improving tumor identification and treatment planning, AI is a powerful agent for healthcare innovation and acceleration. Yet, despite its promise, integrating AI into actual solutions can challenge many IT organizations. The Netherlands Cancer Institute (NKI), one of the world’s top-rated cancer research and treatment centers, Read article >
Project MONAI continues to expand its end-to-end workflow with new releases and a new component called MONAI Deploy Inference Service.
Project MONAI continues to expand its end-to-end workflow with new releases and a new subproject called MONAI Deploy Inference Service.
Project MONAI is releasing three new updates to existing frameworks, MONAI v0.8, MONAI Label v0.3, and MONAI Deploy App SDK v0.2. It’s also expanding its MONAI Deploy subsystem with the MONAI Deploy Inference Service (MIS), a server that runs MONAI Application Packages (MAPs) in a Kubernetes Cluster as cloud-native microservices.
MIS helps expand the end-to-end capabilities of MONAI by integrating with a container orchestration system like Kubernetes. By using the Kubernetes framework, developers can quickly start testing their models. This allows moving the execution from local development to staging environments.
More information:
MONAI Core v0.8
MONAI Core v0.8 focuses on expanding its learning capabilities by both adding Self-Supervised and Multi-Instance learning support.
Also included is a new state-of-the-art differential search framework called DiNTS that helps accelerate Neural Architecture Search (NAS) for large-scale 3D image sets like those found in medical imaging.
Highlights include:
Multi-instance learning with examples for the MSD dataset.
Visualization of transforms and notebook with approaches for 3D image transform augmentation.
Self-supervised learning with pretraining pipeline-leveraging vision transformer tutorials, highlighting training with unlabeled data and adaptation for downstream tasks.
DiNTS AutoML with examples using MSD tasks.
Get started with the new features using the included Jupyter Notebooks:
MONAI Label v0.3 focuses on including multilabel segmentation support with DynUNet and UNETR networks as the base architecture options. It also focuses on enhanced performance with multi-GPU training support to improve scalability and usability improvements that make active learning easier to use.
Highlights include:
Multi-Label Segmentation Support
Multi-GPU Training
Active Learning UX Changes
MONAI Deploy
MONAI Deploy App SDK v0.2
MONAI Deploy App SDK v0.2 continues to expand its base operators, including support for additional DICOM operations.
Highlights include:
Operator for DICOM Series Selection.
Operator for exporting DICOM Structured Reports SOP for classification results.
MONAI Deploy Inference Service v0.1
MONAI Deploy Inference Service v0.1 is the first component of the MONAI Deploy Application Server that continues to expand on the end-to-end workflow of MONAI. It includes the ability to deploy MONAI Application Packages (MAPs) created by MONAI Deploy App SDK into a Kubernetes cluster.
Highlights include:
Register a MAP in the Helm Charts of MIS.
Upload inputs through a REST API request and make them available to the MAP container.
Provision resources for the MAP container.
Provide outputs of the MAP container to the client who made the request.
Check out the new MONAI Deploy tutorials that walk you through creating a MAP using App SDK, deploying the MIS Service, and pushing your MAP to MIS to be run as a cloud-native microservice.
You can find more in-depth information about each release under their respective projects in the Project MONAI GitHub.
NVIDIA cuTENSOR, version 1.4, library supports 64-dimensional tensors, distributed multi-GPU tensor operations, and improves tensor contraction performance models.
Today, NVIDIA is announcing the availability of cuTENSOR, version 1.4, which supports up to 64-dimensional tensors, distributed multi-GPU tensor operations, and helps improve tensor contraction performance models. This software can be downloaded now free of charge.

 The new Amazon EC2 G5g instances feature the AWS Graviton2 processors and NVIDIA T4G Tensor Core GPUs, to power rich android game streaming for mobile devices.
The new Amazon EC2 G5g instances feature the AWS Graviton2 processors and NVIDIA T4G Tensor Core GPUs, to power rich android game streaming for mobile devices. NVIDIA Clara medical AI models can now run natively on MD.ai in the cloud, enabling collaborative model validation and rapid annotation projects using modern web browsers.
NVIDIA Clara medical AI models can now run natively on MD.ai in the cloud, enabling collaborative model validation and rapid annotation projects using modern web browsers.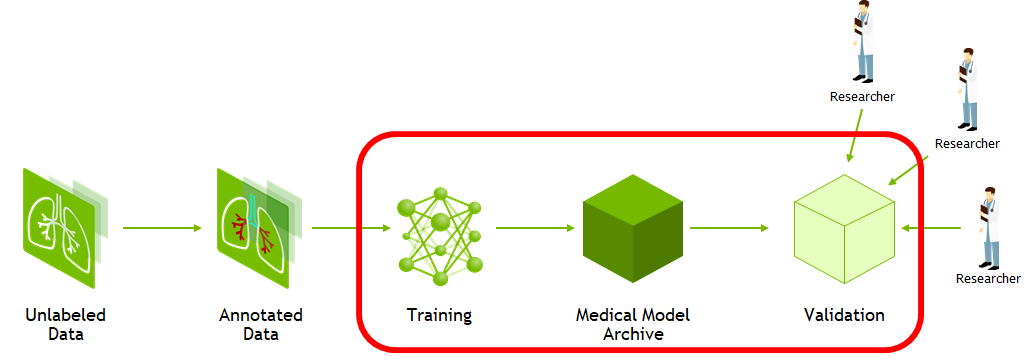
 The NVIDIA Clara developer kit, NVIDIA Clara Holoscan, and us4us front end help build AI models on streaming data for ultrasounds, to remove artifacts like aliasing.
The NVIDIA Clara developer kit, NVIDIA Clara Holoscan, and us4us front end help build AI models on streaming data for ultrasounds, to remove artifacts like aliasing.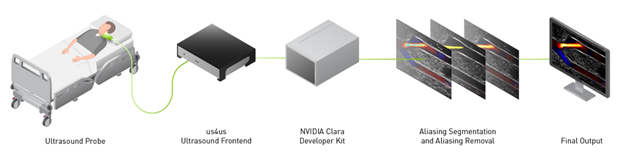
 This post features winners from the NVIDIA sponsored contest with Make: where makers submit their best robotics projects with a galactic theme.
This post features winners from the NVIDIA sponsored contest with Make: where makers submit their best robotics projects with a galactic theme.





 Project MONAI continues to expand its end-to-end workflow with new releases and a new component called MONAI Deploy Inference Service.
Project MONAI continues to expand its end-to-end workflow with new releases and a new component called MONAI Deploy Inference Service. NVIDIA cuTENSOR, version 1.4, library supports 64-dimensional tensors, distributed multi-GPU tensor operations, and improves tensor contraction performance models.
NVIDIA cuTENSOR, version 1.4, library supports 64-dimensional tensors, distributed multi-GPU tensor operations, and improves tensor contraction performance models.