
Jiusheng Chen’s team just got accelerated. They’re delivering personalized ads to users of Microsoft Bing with 7x throughput at reduced cost, thanks to NVIDIA Triton Inference Server running on NVIDIA A100 Tensor Core GPUs. It’s an amazing achievement for the principal software engineering manager and his crew. Tuning a Complex System Bing’s ad service uses Read article >
 The NVIDIA Jetson Orin Nano and Jetson AGX Orin Developer Kits are now available at a discount for qualified students, educators, and researchers.Since its…
The NVIDIA Jetson Orin Nano and Jetson AGX Orin Developer Kits are now available at a discount for qualified students, educators, and researchers.Since its…
The NVIDIA Jetson Orin Nano and Jetson AGX Orin Developer Kits are now available at a discount for qualified students, educators, and researchers.Since its initial release almost 10 years ago, the NVIDIA Jetson platform has set the global standard for embedded computing and edge AI. These high-performance, low-power modules and developer kits for deep learning and computer vision give developers a small yet powerful platform to bring their robotics and edge AI vision to life. It’s the perfect tool for learning and teaching AI.
With 80x the performance over the original Jetson Nano, the Jetson Orin Nano Developer Kit enables you to run any kind of modern AI models, including transformer and advanced robotics models. It also has 5.4x the CUDA compute, 6.6x the CPU performance, and 50x the performance per watt compared to the Nano.
The NVIDIA Jetson AGX Orin Developer Kit and all Jetson Orin modules share one SoC architecture. This enables the developer kit to emulate any of the modules and makes it easy for you to start developing your next product. Compact size, lots of connectors, and up to 275 TOPS of AI performance make this developer kit perfect for prototyping advanced AI-powered robots and other edge AI devices.
The following videos show how easy it is to get started with the Jetson Orin Developer Kits.
Students making the most of Jetson developer kits
When you’ve got a Jetson-powered developer kit, imagine the possibilities for your next edge AI application.
For example, a group of mathematics, computer science, and biology researchers from the University of Marburg in Germany devised a way to quickly identify 80 species of birds and monitor local biodiversity based solely on the sounds those birds make. They used audio recordings captured with portable devices connected to the NVIDIA Jetson Nano Developer Kit.

Last fall, students from Southern Methodist University in Dallas, built what they called a baby supercomputer using 16 NVIDIA Jetson Nano modules, four power supplies, more than 60 handmade wires, a network switch, and some cooling fans. Compared to a normal-sized supercomputer, which can be huge, this mini supercomputer fits neatly on a desk, enabling students to easily use it and learn hands-on.

Special student and educator pricing for Jetson Orin Developer Kits
If you are affiliated with an educational institution, you may be eligible for a discount on Jetson Orin Developer Kits. You must have a valid accredited university or education-related email address. You will then be provided with a one-time use code to order the Jetson Orin Nano Developer Kit or the Jetson AGX Orin Developer Kit. At this time, there is a limit of one of each kit per person.
Qualified students and educators can get the Jetson Orin Nano Developer Kit for $399 (USD) and the Jetson AGX Orin Developer Kit for $1,699 (USD). For more information, see Jetson for Education (login required). Requests for multiple units will be evaluated on a case-by-case basis.
The Ultimate School Supply: NVIDIA Jetson Nano

Don’t need all the power and performance from Jetson Orin? The NVIDIA Jetson Nano Developer Kit is the perfect companion for the upcoming back-to-school season. Powered by NVIDIA GPU-accelerated computing, the Jetson Nano brings your ideas to life, whether you’re a student, educator, or DIY enthusiast. From building intelligent robots to developing groundbreaking AI applications, the possibilities are endless.
The Jetson Nano Developer Kit is available for $149 (USD).
Need help getting started?
Want to learn more about how you can use the Jetson Nano Developer Kit? Consider signing up for a free course from the NVIDIA Deep Learning Institute: Getting Started with AI on Jetson Nano. You may also want to look at the two Jetson AI certification programs available. For more inspiration, see the Jetson Community Projects page. Be sure to share your hard work in the Jetson forums so other developers can learn from your successes.
 AI is transforming industries, automating processes, and opening new opportunities for innovation in the rapidly evolving technological landscape. As more…
AI is transforming industries, automating processes, and opening new opportunities for innovation in the rapidly evolving technological landscape. As more…
AI is transforming industries, automating processes, and opening new opportunities for innovation in the rapidly evolving technological landscape. As more businesses recognize the value of incorporating AI into their operations, they face the challenge of implementing these technologies efficiently, effectively, and reliably.
Enter NVIDIA AI Enterprise, a comprehensive software suite designed to help organizations implement enterprise-ready AI, machine learning (ML), and data analytics at scale with security, reliability, API stability, and enterprise-grade support.
What is NVIDIA AI Enterprise?
Deploying AI solutions can be complex, requiring specialized hardware and software, as well as expert knowledge to develop and maintain these systems. NVIDIA AI Enterprise addresses these challenges by providing a complete ecosystem of tools, libraries, frameworks, and support services tailored for enterprise environments.
With GPU-accelerated computing capabilities, NVIDIA AI Enterprise enables enterprises to run AI workloads more efficiently, cost effectively, and at scale. NVIDIA AI Enterprise is built on top of the NVIDIA CUDA-X AI software stack, providing high-performance GPU-accelerated computing capabilities.
The suite includes:
- VMI: A preconfigured virtual machine image that includes the necessary drivers and software to support GPU-accelerated AI workloads in the major clouds.
- AI frameworks: Software that can run in a VMI (such as PyTorch, TensorFlow, RAPIDS, NVIDIA Triton with TensorRT and ONNX support, and more) that serves as the basis for AI development and deployment.
- Pretrained models: Models that can be used as-is, or fine-tuned on enterprise-relevant data.
- AI workflows: Prepackaged reference examples that illustrate how AI frameworks and pretrained models can be leveraged to build AI solutions to solve common business problems. These workflows provide guidance around fine-tuning pretrained models and AI model creation to build on NVIDIA frameworks. The pipelines to create applications are highlighted, as well as opinions on how to deploy customized applications and integrate them with various components typically found in enterprise environments, such as software for orchestration and management, storage, security, and networking. Available AI workflows include:
- Intelligent virtual assistant: Engaging around-the-clock contact center assistance for lower operational costs.
- Audio transcription: World-class, accurate transcripts based on GPU-optimized models.
- Digital fingerprinting threat detection: Cybersecurity threat detection and alert prioritization to identify and act faster.
- Next item prediction: Personalized product recommendations for increased customer engagement and retention.
- Route optimization: Vehicle and robot routing optimization to reduce travel times and fuel costs.
Supported software with release branches
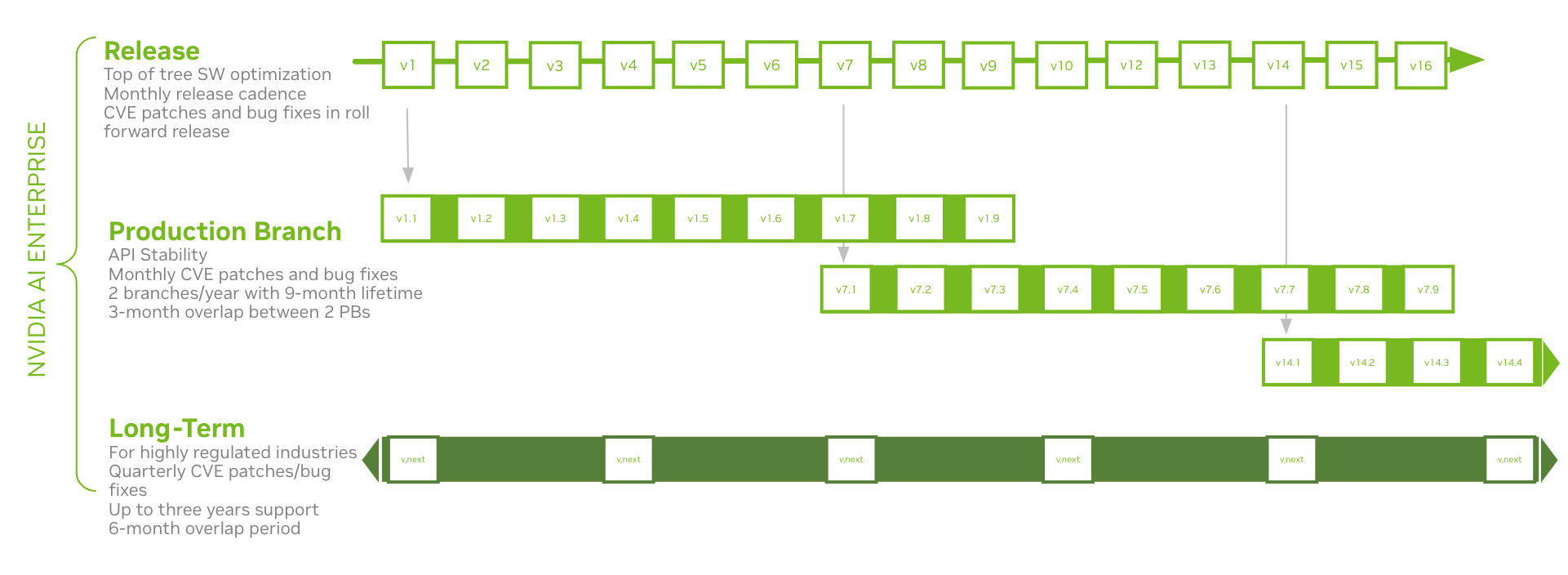
One of the main benefits of using the software available in NVIDIA AI Enterprise is that it is supported by NVIDIA with security and stability as guiding principles. NVIDIA AI Enterprise includes three release branches to cater to varying requirements across industries and use cases:
- Latest Release Branch: Geared towards those needing top-of-the-tree software optimizations, this branch will have a monthly release cadence, ensuring users have access to the latest features and improvements. CVE patches, along with bug fixes, will also be included in roll-forward releases.
- Production Release Branch: Designed for environments that prioritize API stability, this branch will receive monthly CVE patches and bug fixes, with two new branches introduced each year, each having a 9-month lifespan. To ensure seamless transitions and support, there will be a 3-month overlap period between two consecutive production branches. Production branches will be available in the second half of 2023.
- Long-Term Release Branch: Tailored for highly regulated industries where long-term support is paramount, this branch will receive quarterly CVE patches and bug fixes and offers up to 3 years of support for a particular release. Complementing this long-term stability is a 6-month overlap period to ensure smooth transitions between versions, thus providing the longevity and consistency needed for these highly regulated industries.
How to use NVIDIA AI Enterprise with Microsoft Azure Machine Learning
Microsoft Azure Machine Learning is a platform for AI development in the cloud and on premises, including a service for training, experimentation, deploying, and monitoring models, as well as designing and constructing prompt flows for large language models. An open platform, Azure Machine Learning supports all popular machine learning frameworks and toolkits, including those from NVIDIA AI Enterprise.
This collaboration optimizes the experience of running NVIDIA AI software by integrating it with the Azure Machine Learning training and inference platform. Users no longer need to spend time setting up training environments, installing packages, writing training code, logging training metrics, and deploying models. With this integration, users will be able to leverage the power of NVIDIA enterprise-ready software, complementing Azure Machine Learning’s high performance and secure infrastructure, to build production-ready AI workflows.
To get started today, follow these steps:
1. Sign in to Microsoft Azure and launch Azure Machine Learning Studio.
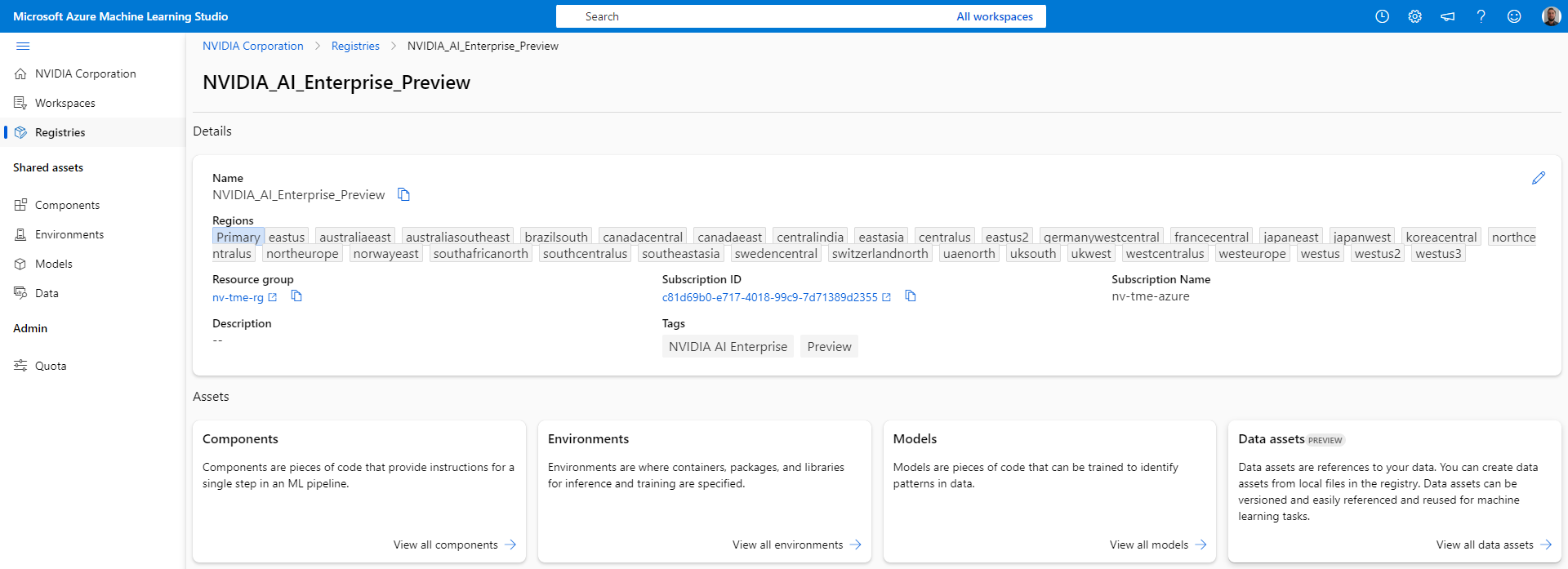
2. View and access all prebuilt NVIDIA AI Enterprise Components, Environments, and Models from the NVIDIA AI Enterprise Preview Registry (Figure 2).
3. Use these assets from within a workspace to create ML pipelines within the designer through simple drag and drop (Figure 3).
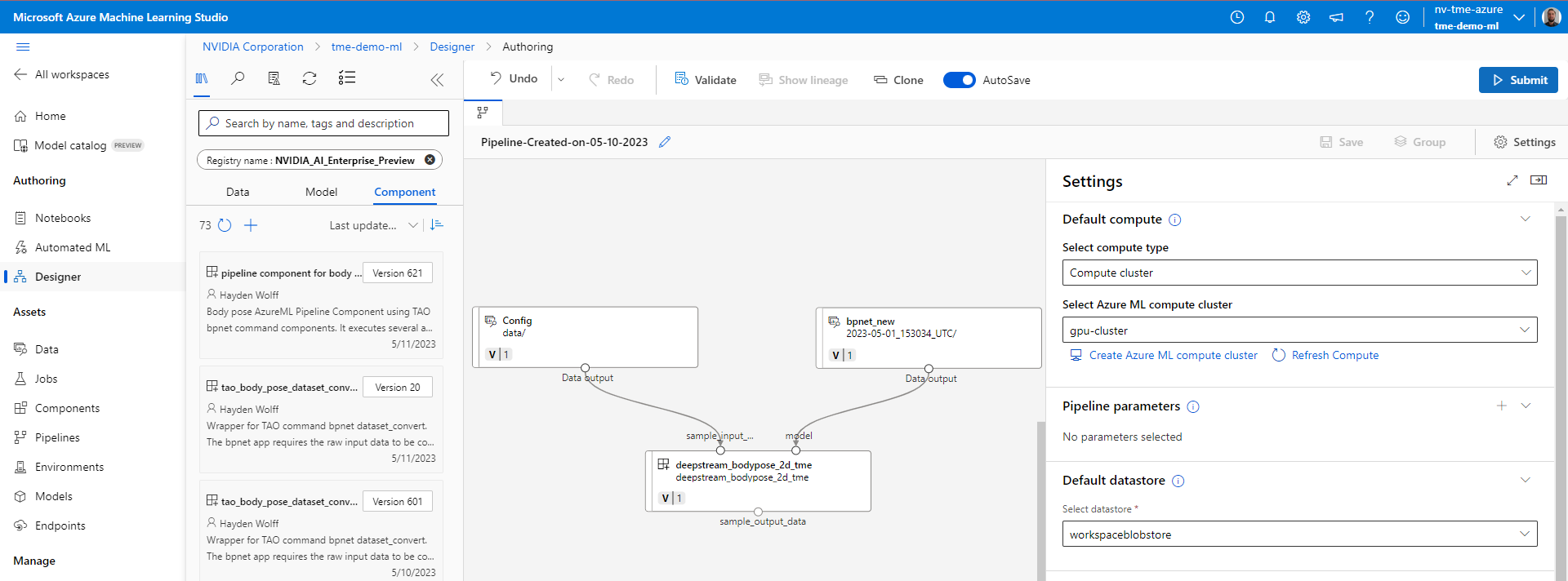
Find NVIDIA AI Enterprise sample assets in the Azure Machine Learning registry. Visit NVIDIA_AI_Enterprise_AzureML on GitHub to find code for the preview assets.
Use case: Body pose estimation
Using the various elements within the NVIDIA AI Enterprise Preview Registry is easy. This example showcases a computer vision task that uses NVIDIA DeepStream for body pose estimation. NVIDIA TAO Toolkit provides the basis for the body pose model and the ability to refine it with new data.
Figure 4 shows a video analytics pipeline example running the NVIDIA DeepStream sample app for body pose estimation. It runs on a GPU cluster and can be easily adapted to leverage updated models and videos, unlocking the power of the Azure Machine Learning platform.
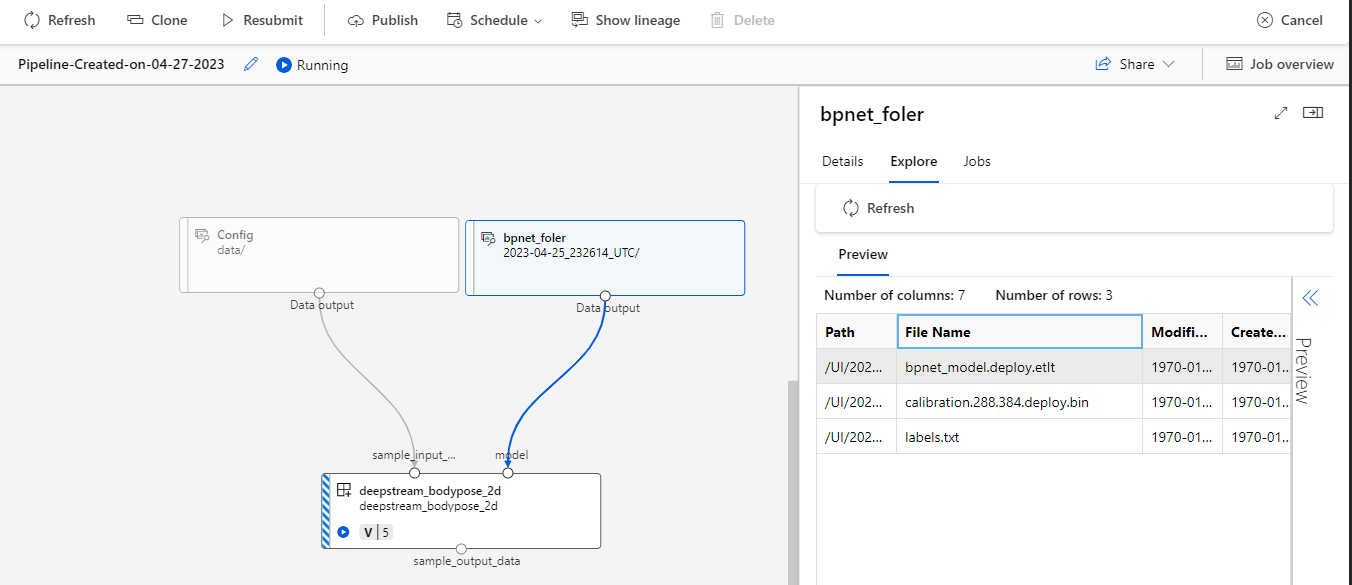
The example includes two URI-based data assets created for storing the inputs for the DeepStream sample app command component. The data assets leverage a pretrained model, which is readily available in the NVIDIA AI Enterprise Registry. They also include additional calibration and label information.
The DeepStream body pose command component is configured to use Microsoft Azure blob storage. This component monitors the input directory for any new video files that require inference. When a video file appears, the component picks it up and performs body pose inference. The outputted video includes bounding boxes and tracking lines and is stored in an output directory.
Additional samples available within the registry include:
- bodyposenet
- citysemsegformer
- dashcamnet
- emotionnet
- fpenet
- gazenet
- gesturenet
- lprnet
- peoplenet
- peoplenet_transformer
- peoplesemsegnet
- reidentificationnet
- retail_object_detection
- retail_object_recognition
- trafficcamnet
Each of these samples can be improved with a TAO Toolkit-based training pipeline, which performs transfer learning. The model output changes to fit a specific use case. You can find TAO Toolkit computer vision sample workflows on NGC.
Get started with NVIDIA AI Enterprise on Azure Machine Learning
NVIDIA AI Enterprise and Azure Machine Learning together create a powerful combination of GPU-accelerated computing and a comprehensive cloud-based machine learning platform, enabling businesses to develop and deploy AI models more efficiently. This synergy enables enterprises to harness the flexibility of cloud resources while leveraging the performance advantages of NVIDIA GPUs and software.
To get started with NVIDIA AI Enterprise on Azure Machine Learning, sign up for a Tech Preview. This will give you access to all of the prebuilt Components, Environments, and Models from the NVIDIA AI Enterprise Preview Registry on Azure Machine Learning.
Automatic speech recognition (ASR) is a well-established technology that is widely adopted for various applications such as conference calls, streamed video transcription and voice commands. While the challenges for this technology are centered around noisy audio inputs, the visual stream in multimodal videos (e.g., TV, online edited videos) can provide strong cues for improving the robustness of ASR systems — this is called audiovisual ASR (AV-ASR).
Although lip motion can provide strong signals for speech recognition and is the most common area of focus for AV-ASR, the mouth is often not directly visible in videos in the wild (e.g., due to egocentric viewpoints, face coverings, and low resolution) and therefore, a new emerging area of research is unconstrained AV-ASR (e.g., AVATAR), which investigates the contribution of entire visual frames, and not just the mouth region.
Building audiovisual datasets for training AV-ASR models, however, is challenging. Datasets such as How2 and VisSpeech have been created from instructional videos online, but they are small in size. In contrast, the models themselves are typically large and consist of both visual and audio encoders, and so they tend to overfit on these small datasets. Nonetheless, there have been a number of recently released large-scale audio-only models that are heavily optimized via large-scale training on massive audio-only data obtained from audio books, such as LibriLight and LibriSpeech. These models contain billions of parameters, are readily available, and show strong generalization across domains.
With the above challenges in mind, in “AVFormer: Injecting Vision into Frozen Speech Models for Zero-Shot AV-ASR”, we present a simple method for augmenting existing large-scale audio-only models with visual information, at the same time performing lightweight domain adaptation. AVFormer injects visual embeddings into a frozen ASR model (similar to how Flamingo injects visual information into large language models for vision-text tasks) using lightweight trainable adaptors that can be trained on a small amount of weakly labeled video data with minimum additional training time and parameters. We also introduce a simple curriculum scheme during training, which we show is crucial to enable the model to jointly process audio and visual information effectively. The resulting AVFormer model achieves state-of-the-art zero-shot performance on three different AV-ASR benchmarks (How2, VisSpeech and Ego4D), while also crucially preserving decent performance on traditional audio-only speech recognition benchmarks (i.e., LibriSpeech).
 |
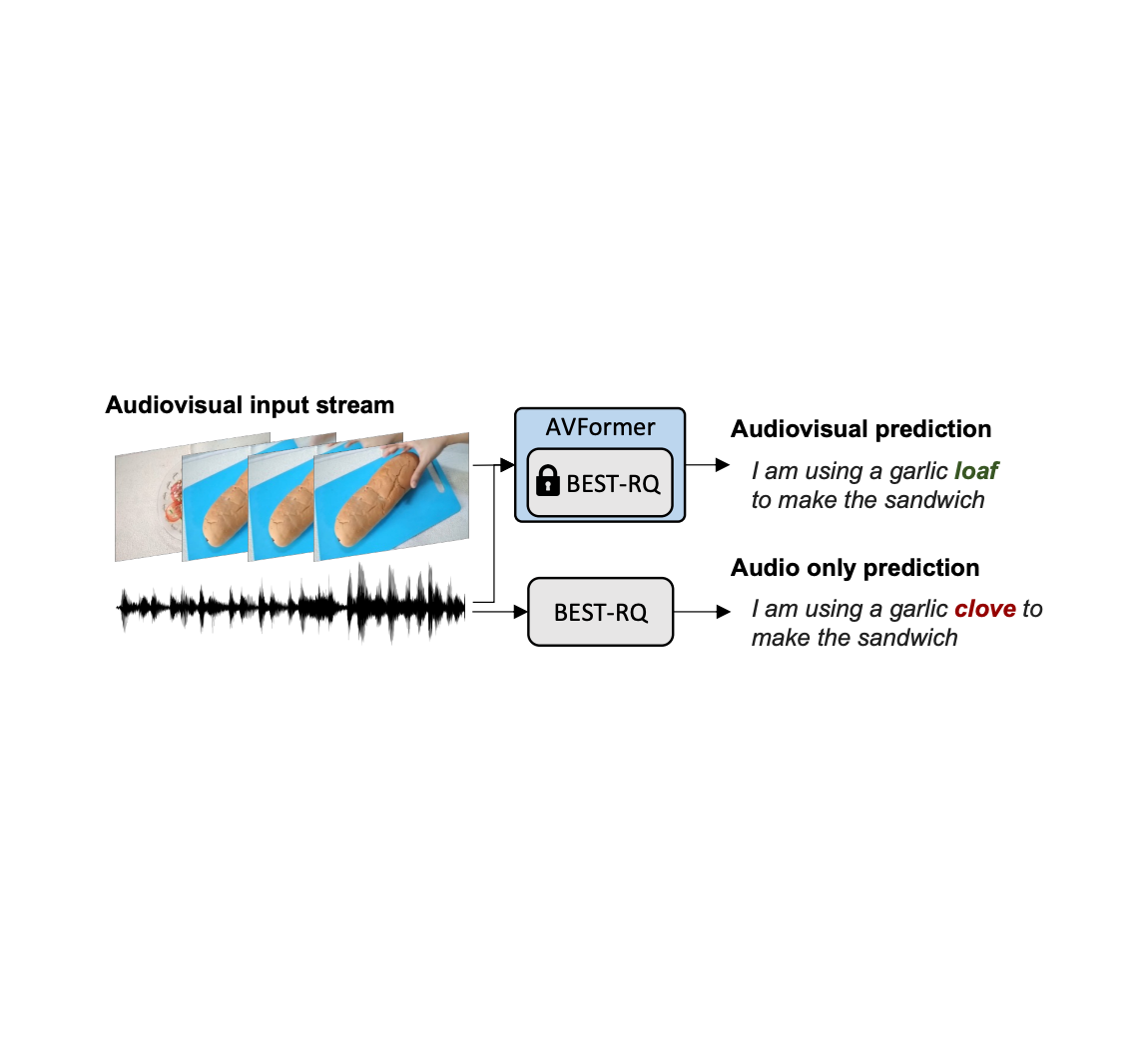
| Unconstrained audiovisual speech recognition. We inject vision into a frozen speech model (BEST-RQ, in grey) for zero-shot audiovisual ASR via lightweight modules to create a parameter- and data-efficient model called AVFormer (blue). The visual context can provide helpful clues for robust speech recognition especially when the audio signal is noisy (the visual loaf of bread helps correct the audio-only mistake “clove” to “loaf” in the generated transcript). |
Injecting vision using lightweight modules
Our goal is to add visual understanding capabilities to an existing audio-only ASR model while maintaining its generalization performance to various domains (both AV and audio-only domains).
To achieve this, we augment an existing state-of-the-art ASR model (Best-RQ) with the following two components: (i) linear visual projector and (ii) lightweight adapters. The former projects visual features in the audio token embedding space. This process allows the model to properly connect separately pre-trained visual feature and audio input token representations. The latter then minimally modifies the model to add understanding of multimodal inputs from videos. We then train these additional modules on unlabeled web videos from the HowTo100M dataset, along with the outputs of an ASR model as pseudo ground truth, while keeping the rest of the Best-RQ model frozen. Such lightweight modules enable data-efficiency and strong generalization of performance.
We evaluated our extended model on AV-ASR benchmarks in a zero-shot setting, where the model is never trained on a manually annotated AV-ASR dataset.
Curriculum learning for vision injection
After the initial evaluation, we discovered empirically that with a naïve single round of joint training, the model struggles to learn both the adapters and the visual projectors in one go. To mitigate this issue, we introduced a two-phase curriculum learning strategy that decouples these two factors — domain adaptation and visual feature integration — and trains the network in a sequential manner. In the first phase, the adapter parameters are optimized without feeding visual tokens at all. Once the adapters are trained, we add the visual tokens and train the visual projection layers alone in the second phase while the trained adapters are kept frozen.
The first stage focuses on audio domain adaptation. By the second phase, the adapters are completely frozen and the visual projector must simply learn to generate visual prompts that project the visual tokens into the audio space. In this way, our curriculum learning strategy allows the model to incorporate visual inputs as well as adapt to new audio domains in AV-ASR benchmarks. We apply each phase just once, as an iterative application of alternating phases leads to performance degradation.
 |
| Overall architecture and training procedure for AVFormer. The architecture consists of a frozen Conformer encoder-decoder model, and a frozen CLIP encoder (frozen layers shown in gray with a lock symbol), in conjunction with two lightweight trainable modules – (i) visual projection layer (orange) and bottleneck adapters (blue) to enable multimodal domain adaptation. We propose a two-phase curriculum learning strategy: the adapters (blue) are first trained without any visual tokens, after which the visual projection layer (orange) is tuned while all the other parts are kept frozen. |
The plots below show that without curriculum learning, our AV-ASR model is worse than the audio-only baseline across all datasets, with the gap increasing as more visual tokens are added. In contrast, when the proposed two-phase curriculum is applied, our AV-ASR model performs significantly better than the baseline audio-only model.
 |
| Effects of curriculum learning. Red and blue lines are for audiovisual models and are shown on 3 datasets in the zero-shot setting (lower WER % is better). Using the curriculum helps on all 3 datasets (for How2 (a) and Ego4D (c) it is crucial for outperforming audio-only performance). Performance improves up until 4 visual tokens, at which point it saturates. |
Results in zero-shot AV-ASR
We compare AVFormer to BEST-RQ, the audio version of our model, and AVATAR, the state of the art in AV-ASR, for zero-shot performance on the three AV-ASR benchmarks: How2, VisSpeech and Ego4D. AVFormer outperforms AVATAR and BEST-RQ on all, even outperforming both AVATAR and BEST-RQ when they are trained on LibriSpeech and the full set of HowTo100M. This is notable because for BEST-RQ, this involves training 600M parameters, while AVFormer only trains 4M parameters and therefore requires only a small fraction of the training dataset (5% of HowTo100M). Moreover, we also evaluate performance on LibriSpeech, which is audio-only, and AVFormer outperforms both baselines.
.png) |
| Comparison to state-of-the-art methods for zero-shot performance across different AV-ASR datasets. We also show performances on LibriSpeech which is audio-only. Results are reported as WER % (lower is better). AVATAR and BEST-RQ are finetuned end-to-end (all parameters) on HowTo100M whereas AVFormer works effectively even with 5% of the dataset thanks to the small set of finetuned parameters. |
Conclusion
We introduce AVFormer, a lightweight method for adapting existing, frozen state-of-the-art ASR models for AV-ASR. Our approach is practical and efficient, and achieves impressive zero-shot performance. As ASR models get larger and larger, tuning the entire parameter set of pre-trained models becomes impractical (even more so for different domains). Our method seamlessly allows both domain transfer and visual input mixing in the same, parameter efficient model.
Acknowledgements
This research was conducted by Paul Hongsuck Seo, Arsha Nagrani and Cordelia Schmid.
 When you see a context-relevant advertisement on a web page, it’s most likely content served by a Taboola data pipeline. As the leading content recommendation…
When you see a context-relevant advertisement on a web page, it’s most likely content served by a Taboola data pipeline. As the leading content recommendation…
When you see a context-relevant advertisement on a web page, it’s most likely content served by a Taboola data pipeline. As the leading content recommendation company in the world, a big challenge for Taboola was the frequent need to scale Apache Spark CPU cluster capacity to address the constantly growing compute and storage requirements.
Data center capacity and hardware costs are always under pressure.
What caused the scaling challenges? Taboola uses a complex data pipeline stretching from user browsers or mobile devices through multiple data centers. Complex deep learning algorithms, databases, infrastructure services (such as Apache Kafka), and thousands of servers are deployed to serve the best-fitting ads to users around the world.
This post describes Taboola’s motivation to move to RAPIDS Accelerator for Apache Spark to optimize processing costs, along with insights on the migration process, challenges, and lessons learned to date.
Challenges of feeding a compute-hungry pipeline
To plan solutions, you must fully understand the magnitude of the problem. When serving ad content, Taboola builds a unique pageview that identifies each user and their interaction with the system. The pageview, a large, wide data structure, is built within a massive CPU cluster using data collected across worldwide data centers. The structure contains over 1500 distinct columns amounting to >1 TB of hourly data, all processed in our Apache Spark CPU cluster.
Many distinct analyzers and SQL queries process incoming pageviews at a rate of 1 TB of raw data per hour and catchup runs at 2, 6, 12, and 48 hours. New analyzers are constantly being created that increase the load on the Apache Spark cluster. There is a growing need for more compute power.
Our main task was to make the complex compute-hungry pipeline more scalable while being cost-effective. To address this challenge, Taboola embarked on an effort to migrate thousands of CPU cores to GPUs, to help us cope with the increasing data load to be processed.
One tool we considered to accelerate Taboola’s Apache Spark environments was the RAPIDS Accelerator on GPUs. As such, it was a natural decision to attempt greater scalability on GPUs as opposed to CPUs.
Key considerations
First, we defined what we needed for testing to successfully migrate thousands of CPU cores to leverage GPU acceleration:
- Real-life dataset
- Hardware specifications
- Minimum X factor
- Complex query testing
Real-life dataset
We used real production data from Cyber Monday to test and benchmark a large dataset. The data is 1.5 TB of ZSTD-compressed Parquet files per hour. It has over 1500 columns of all native types including arrays, structures, and nested structures with arrays.
Hardware specifications
For hardware, we started with the following resources:
- A 72 CPU core Intel server with three A30 GPUs
- A 900-GB local SSD drive, for Apache Spark to store its intermediate files
- 380 GB RAM
- A 10-Gb/s NIC card
Minimum X factor
The primary question when migrating a project from the CPU to the GPU is usually, “What’s the X factor?” For a real-world cluster with multiple GPUs, the question is, “How many GPUs do I need for sustaining a load manageable by X CPU cores?” The answer is your X factor.
We set a minimum bar of an X factor of 3 for the GPU solution to be considered successful in terms of cost. This factor helps guarantee our migration efforts will pay off.
Complex query testing
We picked 15 queries from production across multiple R&D departments to resemble as many of the hundreds of queries as are in production.
The queries are mostly complex including many SQL operations:
- Aggregations
- Sorts
- Lateral view explode
- Distribute by
- Window functions
- UDFS
Figure 1 shows an example query.
Table 1 shows you Taboola’s factors.
| Analyzer name | Avg CPU production time | Avg GPU time | GPU factor |
| AdvertiserDimensionByRequest | 586.41 | 31.91 | 18.38 |
| ExperiementAnalysisPage | 3021.6 | 102.92 | 29.36 |
| ExperiementAnalysisPlacement | 680.84 | 47.12 | 14.45 |
| ExperimentAnalysisRequestBase | 6605.44 | 362.68 | 18.21 |
| ExperimentAnalysisSession | 207.87 | 23.01 | 9.03 |
| MediaDatatrendsBase | 222.94 | 9.8 | 22.75 |
| PerformanceMeasurements | 397.17 | 86.22 | 4.61 |
| PublisherPerformance | 965.63 | 108.95 | 8.86 |
| RBoxABTest | 63.04 | 2.4 | 23.88 |
| RevenueByHostHourly | 487.44 | 95.03 | 5.13 |
| SlaUnitAvailableFillRate | 1199.93 | 152.38 | 7.87 |
| SupplyDataTrends | 529.92 | 45.28 | 11.7 |
CPU-to-GPU migration goals
We began with a single server (as described earlier) capable of scaling to a multi-GPU and multi-server cluster. The cluster would be managed by Kubernetes, as opposed to the current Mesos cluster. Mesos was going to become obsolete and NVIDIA environments support Kubernetes.
Any changes in the software and hardware environment would have to be oblivious to Taboola’s code. Queries run on GPUs should execute with the exact results as CPUs. The team was aware of this challenge, as production stability was a critical goal.
Lastly, we wanted the GPU to outperform the CPUs by a minimum factor of 3. We benchmarked several GPUs including NVIDIA P100, NVIDIA V100, NVIDIA A100, and NVIDIA A30. We learned that the A30 GPU gave us the best price-performance fit.
First experiment with RAPIDS Accelerator
We ran SQL queries using RAPIDS Accelerator with somewhat disappointing results. Some of the less complex queries, mostly with lateral view explode, gave a 3x to 5x factor over the CPU. Some showed much lower factors, while other queries crashed.
After asking questions in the RAPIDS GitHub repo, we tried relevant Apache Spark and RAPIDS Accelerator parameters and began seeing better results:
sql.files.maxPartitionBytes: The CPU uses a default value of 128 MB. This is too low for the GPU. We are using 1–2 GB.sql.shuffle.partitions: We found the 200 default to be sufficient in most cases.rapids.sql.concurrentGpuTasks: Determines the number of tasks that can be run concurrently on the GPU. A minimum of at least two tasks appears to be best.
Tuning these parameters helped the queries run more smoothly and perform better in some cases. The NVIDIA Accelerated Spark Analysis tool can automatically generate tuning recommendations.
Challenge #1 – Parquet parsing overhead
We experienced bottlenecks on some of the less performant SQL queries, with most of them wasting time parsing Parquet footer data on the CPU. The Parquet data has more than 1500 columns. It was apparent that regular Java code for parsing the footer was not adequate for such a large footer.
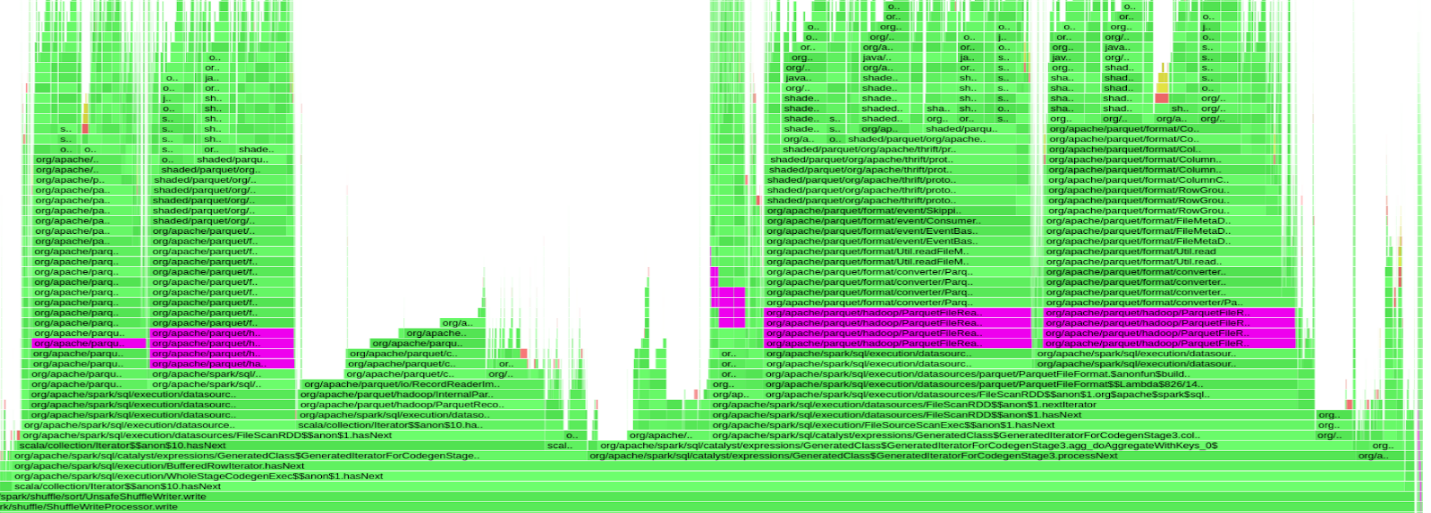
Figure 2 shows a small section of NVIDIA profiler output for a 9-second Apache Spark task where the GPU was mostly idle (only working for 330 ms).

Figure 3 shows a flame graph of a query suffering from this behavior. The purple bars indicate time spent inside the org.apache.parquet.hadoop.ParquetFileReader class. Almost 50% of the query time was spent on parsing Parquet’s footer while the GPU was idle.
As such, we set off to test an alternative solution. When parsing the footer, Parquet code would iterate over footer metadata serially for each row group. We adjusted Parquet parameters to decrease the number of row groups in each file. This gave us about 10–15% improvement. We found this improvement to be insufficient.
Each time metadata was read, all 1500 columns of metadata were read and parsed serially, even after only asking for 50-100 columns per query. We wanted to index footer metadata such that instead of reading the entire 1500 data columns serially, we’d just access it directly. We managed to make this happen by changing the Parquet-mr public code in C++ and Java. Although we got nice performance results, this was too cumbersome and complex.
Fortunately, the NVIDIA RAPIDS team had a much better idea. The solution was optimal Parquet file parsing. They replaced the Java code with Arrow’s C++ implementation. We now have the rapids.sql.format.parquet.reader.footer.type set to NATIVE by default for our GPU implementation. The bottleneck was solved and there were no longer queries with the GPU idle because of footer parsing overheads on the CPU.
Challenge #2 – Network bottleneck
A weak network card caused the next bottleneck. While the 10-Gb/s Ethernet card sustained the CPU load, it failed to do so for the GPU load.
The solution was an optimal network card for GPU loads. Replacing the 10-Gb/s Ethernet card with a 25-Gb/s card removed this bottleneck.
Challenge #3 – Disk I/O bottleneck
Even after removing the two bottlenecks, queries still ran slow. On the Apache Spark user interface, we saw a clear indication as to what was happening.
| Metric | Min | 25th percentile | Median | 75th percentile | Max |
| Duration | 0.4 s | 0.6 s | 0.8 s | 1 s | 1.2 min |
| GC Time | 0.0 ms | 0.0 ms | 0.0 ms | 90.0 ms | 0.5 s |
| Shuffle Read Size/Records | 21.4 MB/1000 | 22.3 MB/1000 | 22.5 MB/1000 | 22.7 MB/1000 | 27.3 MB/1000 |
| Shuffle Write Size/Records | 17.5 MB/1000 | 17.9 MB/1000 | 18 MB/1000 | 18.1 MB/1000 | 18.1 MB/1000 |
| Scheduler Delay | 3.0 ms | 5.0 ms | 5.0 ms | 7.0 ms | 3 s |
| Peak Execution Memory | 64 MB | 64 MB | 64 MB | 64 MB | 64 MB |
| Shuffle Write Time | 9.0 ms | 13.0 ms | 18.0 ms | 21.0 ms | 59 s |
In Table 2, in the Max column, the task’s duration is 1.2 minutes, while Shuffle Write Time took 58 seconds. A lot of time was wasted doing shuffle work while the GPU was idle.
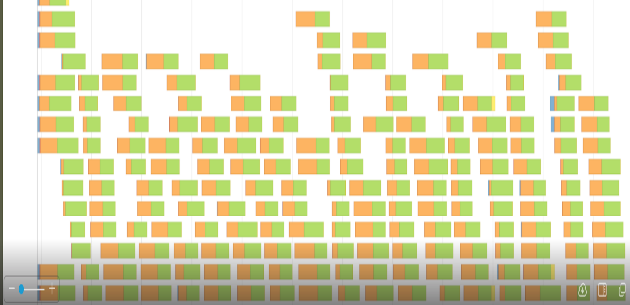
Figures 4 and 5 show the appropriate event timeline graph. The orange part represents shuffle times, read or write. The green parts are compute time. We were wasting a lot of time reading or writing shuffle files.
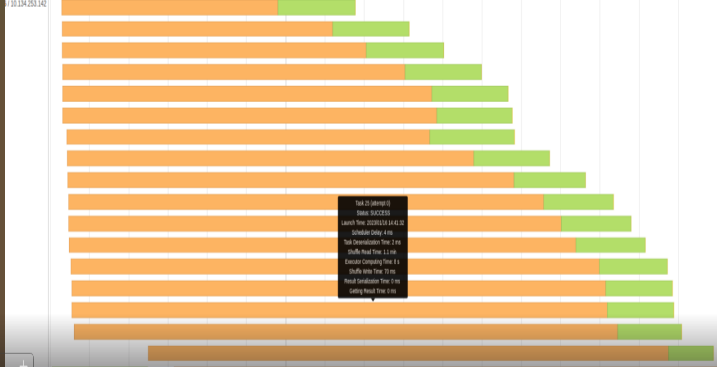
Our shuffle files can get up to 500 GB and greater in some queries. We obviously can’t keep this huge amount of data in the server’s RAM, so shuffle files are stored in the local SSD drive.
After a quick investigation with our teams, we figured out that the SSD drive was configured to use RAID-1. Each temporary shuffle file was saved twice to the disk. This wasted a lot of time and switching to RAID-0 somewhat improved the situation.
The GPU put more pressure on the SSD drive than the CPU such that we had to replace the SSD with an NVMe drive. The solution was to switch to a 6-TB NVMe drive. We removed one of the GPUs to create a slot for the NVMe drive. Afterward, we had no shuffle read or write performance issues. We also learned that one NVMe drive could sustain the workload of two A30 GPUs.
Moving to Kubernetes
Because our Mesos cluster would become obsolete, the move to Kubernetes from a standalone POC machine was imperative. This involved a lot of configuration work, and other minor work. Still, it was straightforward to implement.
The basic idea is that the Apache Spark driver would sit on a non-GPU machine and each K8s Pod would be associated with a single GPU. For more information, see Getting Started with RAPIDS and Kubernetes.
The following code example shows some of the major relevant Kubernetes configurations.
spring:
profiles:
include: spark_k8s_extra_files
spark:
driver:
sparkConnector:
sparkOpts:
spark.kubernetes.container.image.pullPolicy: Always
spark.kubernetes.authenticate.serviceAccountName: spark
spark.kubernetes.executor.deleteOnTermination: true
spark.deploy.mode: client
spark.executorEnv.preLoadMemoryLibraryName: "/usr/libjemalloc.so"
spark.executorEnv.xmxPercentage: 80
spark.kubernetes.memoryOverheadFactor: 0.1
spark.mesos.fetcherCache.enable: false
spark.executor.extraJavaOptions:
-XX:-UsePerfData
-XX:-OmitStackTraceInFastThrow
-verbose:gc
-XX:+UseParallelGC
-XX:+UseParallelOldGC
-XX:+PrintFlagsFinal
-Dmapreduce.fileoutputcommitter.algorithm.version=2
-XX:NativeMemoryTracking=detail
spark.plugins: "com.nvidia.spark.SQLPlugin"
spark.kubernetes.executor.podTemplateFile: /conf/k8GPUPodTemplateProduction.yml
spark.executor.resource.gpu.vendor: "nvidia.com"
spark.executor.resource.gpu.discoveryScript: /conf/getGpusResources.sh
spark.executor.resource.gpu.amount: 1
# GPU task configuration
spark.rapids.sql.variableFloatAgg.enabled: "true"
spark.rapids.sql.castFloatToDecimal.enabled: "true"
spark.rapids.sql.rowBasedUDF.enabled: "true"
spark.rapids.sql.format.parquet.reader.footer.type: "NATIVE"
spark.rapids.sql.explain: "all" # For debug.
# Most common
spark.rapids.sql.concurrentGpuTasks: 4
spark.sql.files.maxPartitionBytes: "2048m"
spark.rapids.sql.batchSizeBytes: "1g"
spark.sql.shuffle.partitions: 200
How many GPUs to accelerate?
If the goal is to use GPUs to accelerate workloads more cost-effectively than CPUs, we first had to understand how fast GPUs were. We set up a test system with two A30 GPUs and streamed production data to it in parallel with our large CPU core production environment.
Figure 6 shows two of our heaviest queries running on the production CPU cluster and also on the server with two A30 GPUs.
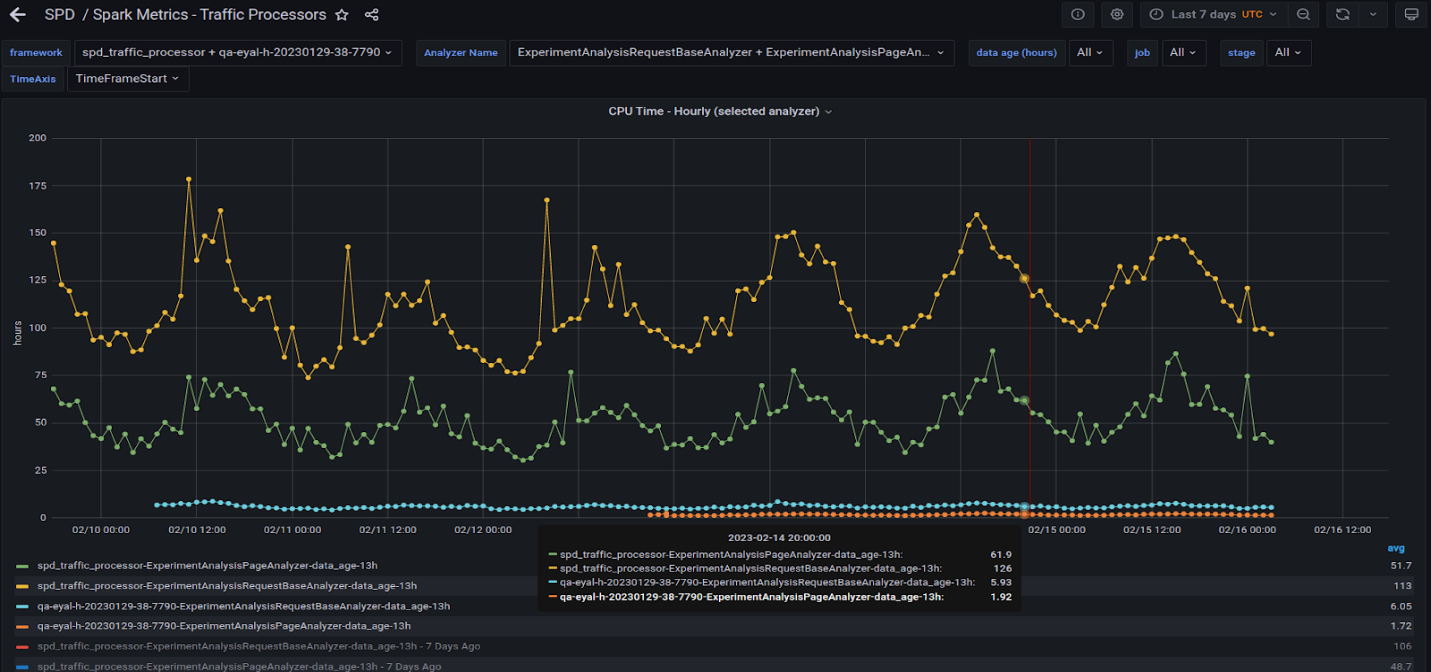
The yellow and green lines denote the hourly total time across all task numbers of the two queries running on the CPU cluster. The blue and orange lines denote the same queries running on the GPU server. GPU factors are 20x and higher.
Figure 7 shows the two queries running on the GPU shown in Figure 6. Observe that they behave similarly to the CPU in that peaks and valleys roughly align at different times of the day.
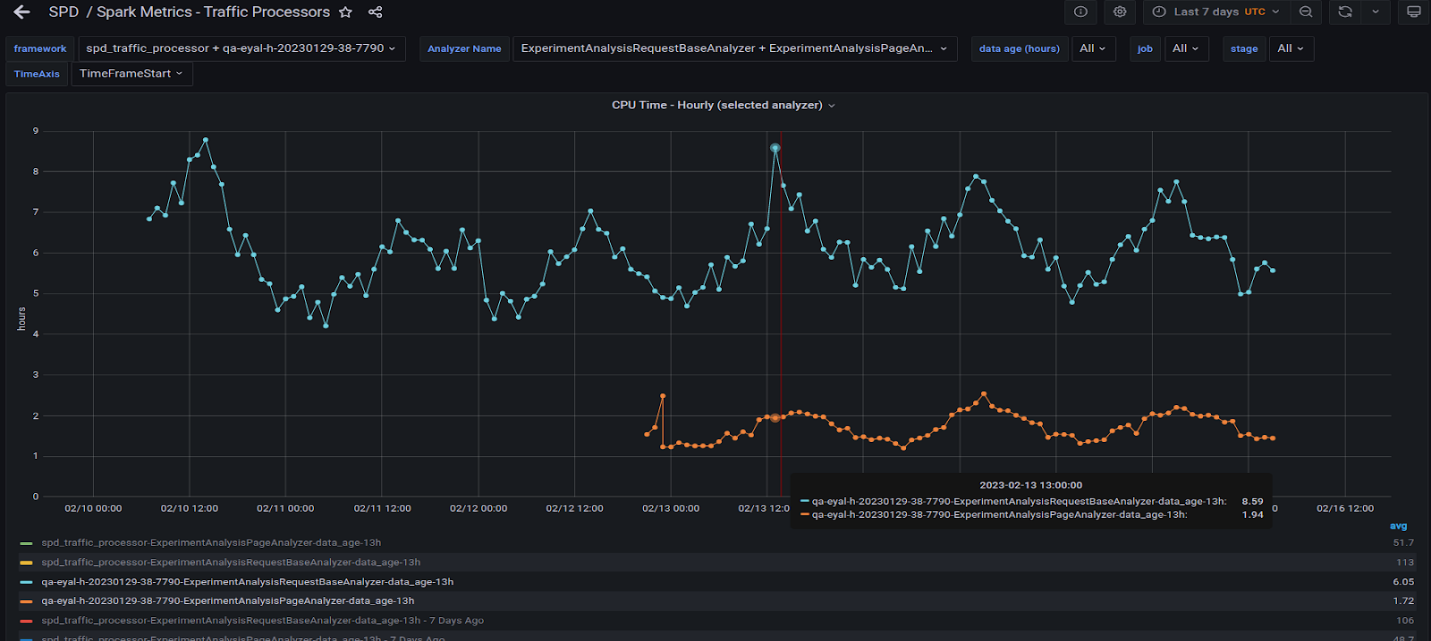
Figure 8 is interesting in that it shows the factor of all the queries that we migrated to the GPU and their counterparts on the CPU. The GPU run is missing the biggest query, which we are still working on migrating to the GPU. It will likely add 200 hours per day to the GPU total time.
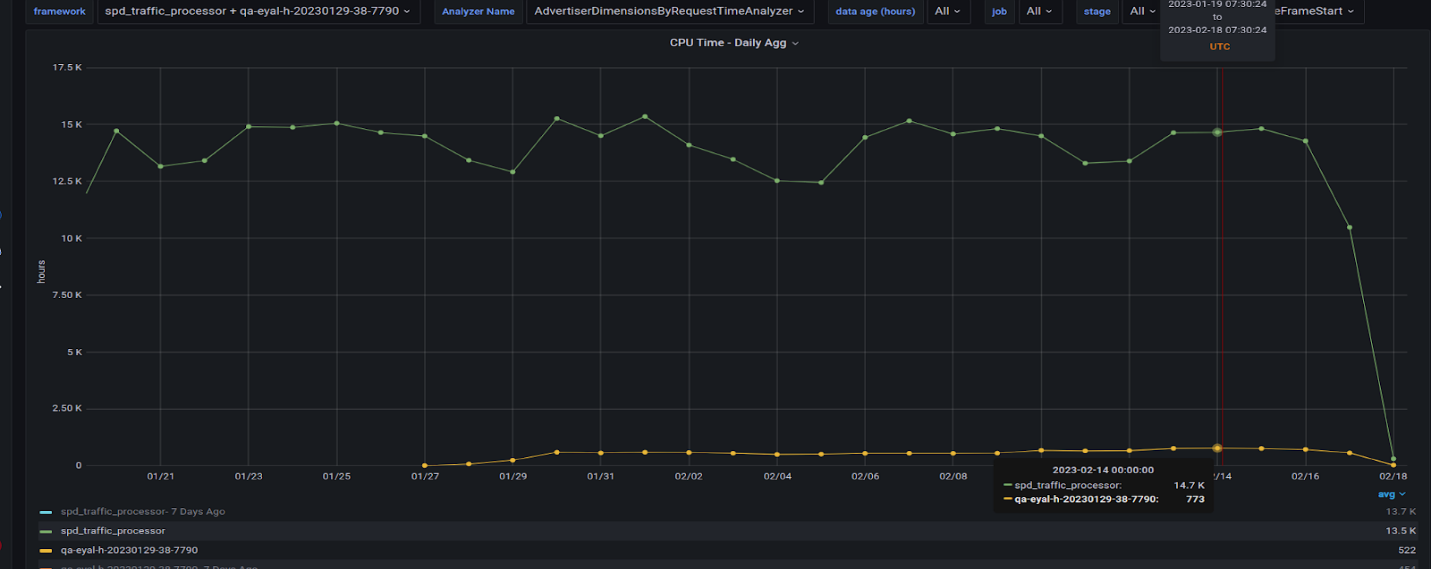
Lessons learned
Looking ahead to our next migration steps, Taboola would like to move queries from other R&D departments to the GPU, resulting in a greater number of GPUs in production. This means that QA must monitor the system more closely while in production.
Getting acquainted with RAPIDS Accelerator for Apache Spark was an amazing “joy ride” effort. From handling Parquet files to pushing GPUs to their limit, we became better equipped at handling a large data pipeline along with managing data center capacity and hardware costs. Identifying and coping with hardware limitations with this method proved to be rewarding.
Here are Taboola’s top takeaways for those considering CPU-to-GPU migration:
- Tuning parameters in complex environments that have multiple variables is never straightforward. Automate this task to whatever degree possible. It’s probably a good idea to use the NVIDIA Accelerated Spark Analysis tool to help address this challenge, as it can easily suggest optimized parameters.
- Look beyond CPUs and GPUs for solutions to bottlenecks. No amount of GPU horsepower can resolve issues that are fundamentally network, disk, bandwidth, or configuration and parsing related.
- Multiple GPUs do not hinder performance, but GPUs are so powerful that you may have good performance with fewer GPUs than originally thought. It’s best to test for this to lower costs.
- We achieved our 20x factor through RAPIDS Accelerator and NVIDIA GPUs. The biggest lesson learned was that we needed to better understand what was happening in our existing environment before benefiting from GPU acceleration. One A30 GPU sustained the same production load for some workloads as the ~200-CPU core test cluster.
For more information about achieving performance multiples over Apache Spark CPU-based environments, see GPU-Accelerated Apache Spark.
Acknowledgments
Our huge effort was more successful with the support, assistance, and patience of two great groups of people. At Taboola: Andrey Gourine, Gilad Zamoscinski, Igor Berman, Keren Corsia, Lior Chaga, and Michael Taranov. On the NVIDIA RAPIDS team: Alessandro Bellina, Hao Zhu, Karthikeyan Rajendran, Robert Evans, and Sameer Raheja.
 A new model generates 3D reconstructions using neural networks, turns 2D video clips into detailed 3D structures — generating lifelike virtual replicas of…
A new model generates 3D reconstructions using neural networks, turns 2D video clips into detailed 3D structures — generating lifelike virtual replicas of…
A new model generates 3D reconstructions using neural networks, turns 2D video clips into detailed 3D structures — generating lifelike virtual replicas of buildings, sculptures and other real-world objects.
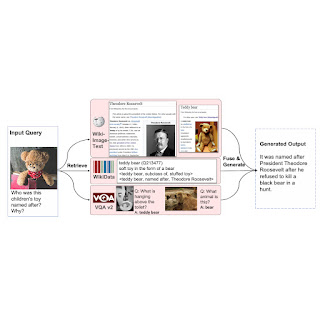
Large-scale models, such as T5, GPT-3, PaLM, Flamingo and PaLI, have demonstrated the ability to store substantial amounts of knowledge when scaled to tens of billions of parameters and trained on large text and image datasets. These models achieve state-of-the-art results on downstream tasks, such as image captioning, visual question answering and open vocabulary recognition. Despite such achievements, these models require a massive volume of data for training and end up with a tremendous number of parameters (billions in many cases), resulting in significant computational requirements. Moreover, the data used to train these models can become outdated, requiring re-training every time the world’s knowledge is updated. For example, a model trained just two years ago might yield outdated information about the current president of the United States.
In the fields of natural language processing (RETRO, REALM) and computer vision (KAT), researchers have attempted to address these challenges using retrieval-augmented models. Typically, these models use a backbone that is able to process a single modality at a time, e.g., only text or only images, to encode and retrieve information from a knowledge corpus. However, these retrieval-augmented models are unable to leverage all available modalities in a query and knowledge corpora, and may not find the information that is most helpful for generating the model’s output.
To address these issues, in “REVEAL: Retrieval-Augmented Visual-Language Pre-Training with Multi-Source Multimodal Knowledge Memory”, to appear at CVPR 2023, we introduce a visual-language model that learns to utilize a multi-source multi-modal “memory” to answer knowledge-intensive queries. REVEAL employs neural representation learning to encode and convert diverse knowledge sources into a memory structure consisting of key-value pairs. The keys serve as indices for the memory items, while the corresponding values store pertinent information about those items. During training, REVEAL learns the key embeddings, value tokens, and the ability to retrieve information from this memory to address knowledge-intensive queries. This approach allows the model parameters to focus on reasoning about the query, rather than being dedicated to memorization.
 |
| We augment a visual-language model with the ability to retrieve multiple knowledge entries from a diverse set of knowledge sources, which helps generation. |
Memory construction from multimodal knowledge corpora
Our approach is similar to REALM in that we precompute key and value embeddings of knowledge items from different sources and index them in a unified knowledge memory, where each knowledge item is encoded into a key-value pair. Each key is a d-dimensional embedding vector, while each value is a sequence of token embeddings representing the knowledge item in more detail. In contrast to previous work, REVEAL leverages a diverse set of multimodal knowledge corpora, including the WikiData knowledge graph, Wikipedia passages and images, web image-text pairs and visual question answering data. Each knowledge item could be text, an image, a combination of both (e.g., pages in Wikipedia) or a relationship or attribute from a knowledge graph (e.g., Barack Obama is 6’ 2” tall). During training, we continuously re-compute the memory key and value embeddings as the model parameters get updated. We update the memory asynchronously at every thousand training steps.
Scaling memory using compression
A naïve solution for encoding a memory value is to keep the whole sequence of tokens for each knowledge item. Then, the model could fuse the input query and the top-k retrieved memory values by concatenating all their tokens together and feeding them into a transformer encoder-decoder pipeline. This approach has two issues: (1) storing hundreds of millions of knowledge items in memory is impractical if each memory value consists of hundreds of tokens and (2) the transformer encoder has a quadratic complexity with respect to the total number of tokens times k for self-attention. Therefore, we propose to use the Perceiver architecture to encode and compress knowledge items. The Perceiver model uses a transformer decoder to compress the full token sequence into an arbitrary length. This lets us retrieve top-k memory entries for k as large as a hundred.
The following figure illustrates the procedure of constructing the memory key-value pairs. Each knowledge item is processed through a multi-modal visual-language encoder, resulting in a sequence of image and text tokens. The key head then transforms these tokens into a compact embedding vector. The value head (perceiver) condenses these tokens into fewer ones, retaining the pertinent information about the knowledge item within them.
 |
| We encode the knowledge entries from different corpora into unified key and value embedding pairs, where the keys are used to index the memory and values contain information about the entries. |
Large-scale pre-training on image-text pairs
To train the REVEAL model, we begin with the large-scale corpus, collected from the public Web with three billion image alt-text caption pairs, introduced in LiT. Since the dataset is noisy, we add a filter to remove data points with captions shorter than 50 characters, which yields roughly 1.3 billion image caption pairs. We then take these pairs, combined with the text generation objective used in SimVLM, to train REVEAL. Given an image-text example, we randomly sample a prefix containing the first few tokens of the text. We feed the text prefix and image to the model as input with the objective of generating the rest of the text as output. The training goal is to condition the prefix and autoregressively generate the remaining text sequence.
To train all components of the REVEAL model end-to-end, we need to warm start the model to a good state (setting initial values to model parameters). Otherwise, if we were to start with random weights (cold-start), the retriever would often return irrelevant memory items that would never generate useful training signals. To avoid this cold-start problem, we construct an initial retrieval dataset with pseudo–ground-truth knowledge to give the pre-training a reasonable head start.
We create a modified version of the WIT dataset for this purpose. Each image-caption pair in WIT also comes with a corresponding Wikipedia passage (words surrounding the text). We put together the surrounding passage with the query image and use it as the pseudo ground-truth knowledge that corresponds to the input query. The passage provides rich information about the image and caption, which is useful for initializing the model.
To prevent the model from relying on low-level image features for retrieval, we apply random data augmentation to the input query image. Given this modified dataset that contains pseudo-retrieval ground-truth, we train the query and memory key embeddings to warm start the model.
REVEAL workflow
The overall workflow of REVEAL consists of four primary steps. First, REVEAL encodes a multimodal input into a sequence of token embeddings along with a condensed query embedding. Then, the model translates each multi-source knowledge entry into unified pairs of key and value embeddings, with the key being utilized for memory indexing and the value encompassing the entire information about the entry. Next, REVEAL retrieves the top-k most related knowledge pieces from multiple knowledge sources, returns the pre-processed value embeddings stored in memory, and re-encodes the values. Finally, REVEAL fuses the top-k knowledge pieces through an attentive knowledge fusion layer by injecting the retrieval score (dot product between query and key embeddings) as a prior during attention calculation. This structure is instrumental in enabling the memory, encoder, retriever and the generator to be concurrently trained in an end-to-end fashion.
 |
| Overall workflow of REVEAL. |
Results
We evaluate REVEAL on knowledge-based visual question answering tasks using OK-VQA and A-OKVQA datasets. We fine-tune our pre-trained model on the VQA tasks using the same generative objective where the model takes in an image-question pair as input and generates the text answer as output. We demonstrate that REVEAL achieves better results on the A-OKVQA dataset than earlier attempts that incorporate a fixed knowledge or the works that utilize large language models (e.g., GPT-3) as an implicit source of knowledge.
 |
| Visual question answering results on A-OKVQA. REVEAL achieves higher accuracy in comparison to previous works including ViLBERT, LXMERT, ClipCap, KRISP and GPV-2. |
We also evaluate REVEAL on the image captioning benchmarks using MSCOCO and NoCaps dataset. We directly fine-tune REVEAL on the MSCOCO training split via the cross-entropy generative objective. We measure our performance on the MSCOCO test split and NoCaps evaluation set using the CIDEr metric, which is based on the idea that good captions should be similar to reference captions in terms of word choice, grammar, meaning, and content. Our results on MSCOCO caption and NoCaps datasets are shown below.
 |
| Image Captioning results on MSCOCO and NoCaps using the CIDEr metric. REVEAL achieves a higher score in comparison to Flamingo, VinVL, SimVLM and CoCa. |
Below we show a couple of qualitative examples of how REVEAL retrieves relevant documents to answer visual questions.
 |
| REVEAL can use knowledge from different sources to correctly answer the question. |
Conclusion
We present an end-to-end retrieval-augmented visual language (REVEAL) model, which contains a knowledge retriever that learns to utilize a diverse set of knowledge sources with different modalities. We train REVEAL on a massive image-text corpus with four diverse knowledge corpora, and achieve state-of-the-art results on knowledge-intensive visual question answering and image caption tasks. In the future we would like to explore the ability of this model for attribution, and apply it to a broader class of multimodal tasks.
Acknowledgements
This research was conducted by Ziniu Hu, Ahmet Iscen, Chen Sun, Zirui Wang, Kai-Wei Chang, Yizhou Sun, Cordelia Schmid, David A. Ross and Alireza Fathi.
 Learn how AI is transforming financial services across use cases such as fraud detection, risk prediction models, contact centers, and more.
Learn how AI is transforming financial services across use cases such as fraud detection, risk prediction models, contact centers, and more.
Learn how AI is transforming financial services across use cases such as fraud detection, risk prediction models, contact centers, and more.
Neuralangelo, a new AI model by NVIDIA Research for 3D reconstruction using neural networks, turns 2D video clips into detailed 3D structures — generating lifelike virtual replicas of buildings, sculptures and other real-world objects. Like Michelangelo sculpting stunning, life-like visions from blocks of marble, Neuralangelo generates 3D structures with intricate details and textures. Creative professionals Read article >
The season of hot sun and longer days is here, so stay inside this summer with 20 games joining GeForce NOW in June. Or stream across devices by the pool, from grandma’s house or in the car — whichever way, GeForce NOW has you covered. Titles from the Age of Empires series are the next Read article >