Kino 프로젝트는 QS를 통해서 자신에 대해서 알고, 불필요한 일들을 자동화시키고 삶의 질을 증진시키기 위한 프로젝트 입니다. 이번 편에서는 그 동안 모아온 데이터에 대한 시각화와 대쉬보드에 대해서 다뤄보고자 합니다.
![]()
지금까지의 시리즈
- Personal Assistant Kino Part 1 – Overview
- Personal Assistant Kino Part 2 – Chatbot의 기본구조 Skill & Scheduler
- Personal Assistant Kino Part 3 – 작업을 최대한 간편하게 관리하고, 데이터를 기록하자
- Personal Assistant Kino Part 4 – 자주 읽은 글들은 자동으로 저장하는 Smart Feed
- Quantified Self Part 5 – 데이터 시각화와 대쉬보드 with KPI
- Quantified Self Part 6 – 생산적인 하루에 대한 정량적인 표현과 4년간의 데이터 이야기
Github: https://github.com/DongjunLee/quantified-self
데이터 시각화와 대쉬보드가 필요한 이유
어떠한 문제를 해결하고 싶다면, 어떻게 풀어나갈 것인지 생각하는 것보다 중요한 것은 문제 자체에 조금 더 파고 들어가 그 문제를 제대로 이해하는 것입니다. 저는 지금까지 QS 프로젝트를 진행하면서 여러가지 데이터들을 쌓아왔습니다. 데이터 종류에는 각종 작업들에 대한 데이터와, 행복도, 잠에 대한 것들을 포함되어 있습니다. 기본적으로 시계열 데이터의 형식으로 되어있으나, 다양한 범주로 구성되어 있을 것 입니다. 이러한 데이터에서 실제 문제를 발견하는 가장 좋은 방법이 무엇일까요?
바로 ‘시각화(Visualization)’ 입니다.
어떻게 시각화를 하였는지 바로 넘어가기 전에 ‘시각화’ 에 대해서 조금 더 이야기 해보는 것이 글을 이해하는데 있어 도움이 될 것 같습니다. ≪데이터 시각화 교과서≫ 라는 책을 지은 클라우스 윌케는 데이터 시각화에 대해 다음과 같이 이야기하고 있습니다.
데이터 시각화는 다양한 의미가 담긴 숫자들을 점으로, 선으로, 면으로 그려내는 작업입니다. 수학적 언어를 시각적 언어로 ‘번역’하는 작업이죠.
이렇게 숫자를 ‘보는’ 언어로 바꿔서 우리에게 보여주는 이유는 데이터가 가지고 있는 무언가를 알아내기 위함입니다. 윌케는 시각화에 목적에 대해서는 이렇게 이야기합니다.
데이터를 시각화하는 목적은 주로 소통이다. 우리에게는 데이터셋에서 얻은 통찰(insight)이 있고, 잠재 독자가 존재하며, 우리가 얻은 통찰을 독자에게 전달하고자 한다. 통찰한 결과를 성공적으로 알리려면 독자에게 의미 있고 흥미로운 이야기를 들려줘야 한다.
이번 시각화에서의 독자는 저 자신이며, 하루하루 지내면서 지나쳤던 삶의 패턴들을 발견하고 다양한 통찰을 스스로에게 전달하는 것이 목적이 될 것입니다.
그리고 몇가지 차트들을 엮어서, 화면을 구성하는 것을 보통 대쉬보드(Dashboard)라고 합니다. 위키백과에서는 대쉬보드를 다음과 같이 설명합니다.
대시 보드는 특정 목표 또는 비즈니스 프로세스와 관련된 주요 성과 지표를 한 눈에 볼 수있는 그래픽 사용자 인터페이스 유형입니다.
이 QS 프로젝트의 대쉬보드 역시, 저 스스로 목표로 하는 주요 성과 지표를 한 눈에 볼 수 있어야 할 것입니다.
Python 시각화 라이브러리, Ploty

시각화 및 대쉬보드에 사용된 라이브러리는 ploty 라는 라이브러리 입니다. 차트를 그리는데 있어서는 matplotlib 을 기본으로 다양하게 사용되기는 하지만, plotly를 선택한 이유는 다음과 같습니다.
- Plotly는 대쉬보드 용 프레임워크인 Dash 와 호환되어 지원합니다.
- 간단하게 Interactive 차트를 구현할 수 있습니다.
(Plotly에 적혀있는 소개 한 문장: The interactive graphing library for Python (includes Plotly Express)
최근에 업데이트 된 것과 더불어서 간단히 소개를 더 드리자면, 최근에는 Plotly Express 가 업데이트 되면서 다양한 차트들을 더 간단하게 그릴 수 있게 되었습니다.
import plotly.express as px
df = px.data.gapminder()
fig = px.scatter(
df.query("year==2007"),
x="gdpPercap",
y="lifeExp",
size="pop",
color="continent",
hover_name="country",
log_x=True,
size_max=60
)
fig.show()
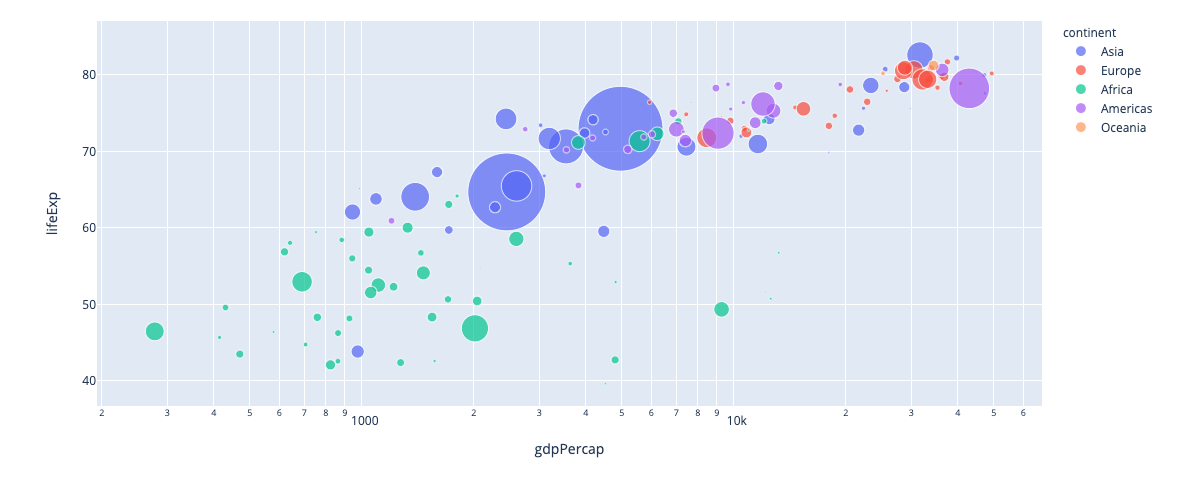
이미치 출처: https://plotly.com/python/plotly-express/ (링크에서는 Interactive Chart로 경험하실 수 있습니다.)
이제 도구가 정해졌으니, QS 데이터를 시각화에 대해서 설명드리고자 합니다.
QS를 위한 데이터 시각화
먼저 수집하고 있는 데이터에 대해서 알고 있어야, 무엇을 어떻게 시각화할 것인지 결정할 수 있을 것 입니다. 아래 데이터는 하루를 기준으로 수집되고 있는 데이터의 예시입니다.
- record: 2020-08-07.json
{
"activity": {
"task": [
{
"toggl_id": 123,
"start_time": "2020-08-07T00:27:45+09:00",
"end_time": "2020-08-07T00:54:23+09:00",
"project": "Review",
"description": "...",
"color": "#566614"
},
{
"toggl_id": 124,
"start_time": "2020-08-07T00:55:22+09:00",
"end_time": "2020-08-07T01:05:54+09:00",
"project": "Article",
"description": "...",
"color": "#e36a00"
},
...
],
"happy": [
{
"time": "2020-08-07T14:40:17+09:00",
"score": 4
},
{
"time": "2020-08-07T21:20:26+09:00",
"score": 5
}
],
"sleep": [
{
"is_main": true,
"start_time": "2020-08-07T01:52:00.000",
"end_time": "2020-08-07T09:25:00.000"
}
],
},
"summary": {
"habit": {
"exercise": true,
"bat": true,
"diary": true,
},
"productive_details": {
"rescue_time": 91.25,
"toggl": 100.0,
"github": 40.0,
"todoist": 88.0
},
"attention": 87.6,
"happy": 96.0,
"productive": 87.12,
"sleep": 100.0,
"repeat_task": 85.0,
"total": 96.76
}
}
- activity: 활동에 대한 로그들을 담고 있습니다. 활동로그의 대표는
task,happy그리고sleep입니다. 그 외에는in_home,out_company등.. 출퇴근 시간을 자동으로 추가한 로그 또한 포함되어 있습니다. - summary: 각 점수 기준에 맞춰서 계산된 점수들을 기본으로 가지고 있습니다. (계산하는 점수에 대해서는 다음 포스트에서 설명드릴 수 있도록 하려고 합니다.) 추가로 제가 중요하게 생각하는
habit즉, 습관에 대한 기록 또한true혹은false로서 저장이 됩니다.
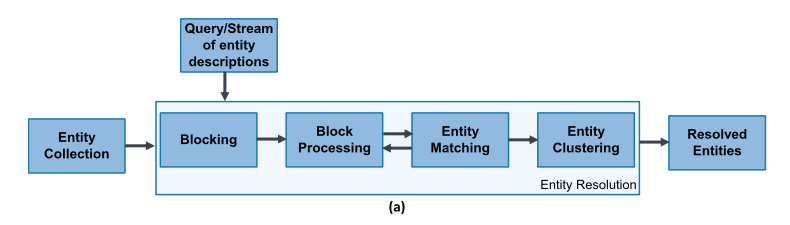
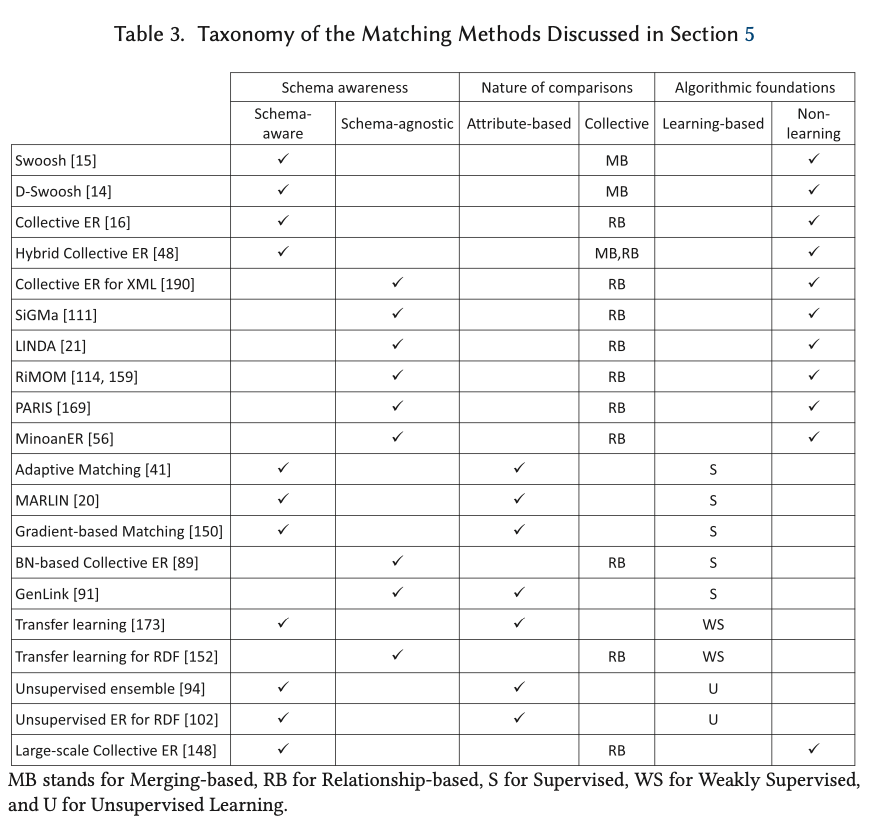
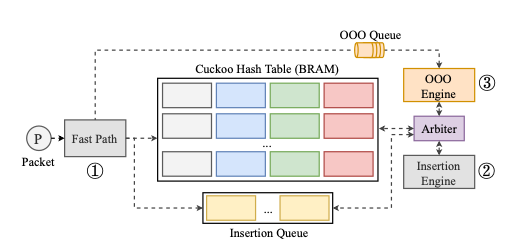
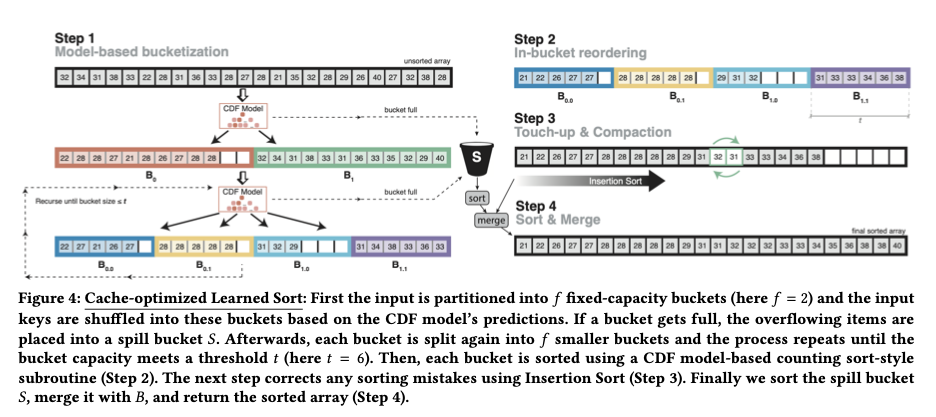
Daily Schedule
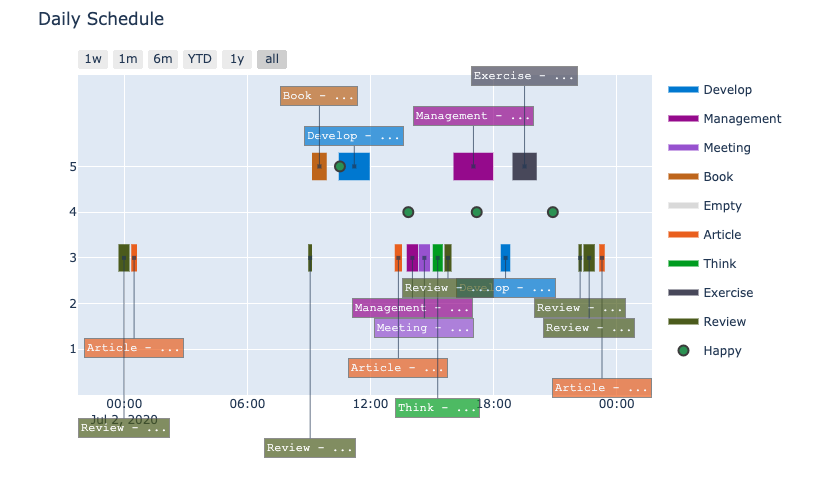
이 차트는 Gantt Chart 를 응용한 것으로서, 각 시간에 대한 작업들을 보여줍니다. 여기서 Y축은 집중도 로서 1~5점의 점수를 가지고 있습니다. 여기에 행복도 점수(초록색 동그라미)까지 더 해줌으로써, 어떤 작업들을 얼마나 집중하며 진행하였는지 그리고 각 시간 때의 기분에 대해서도 알 수가 있습니다. 하루를 대략적으로 돌아보기에 효과적인 차트입니다.
(원래 상세내역은 작업에 대해서 적혀 있지만, 위 차트에서는 ‘…’ 으로 표현하고 있습니다.)
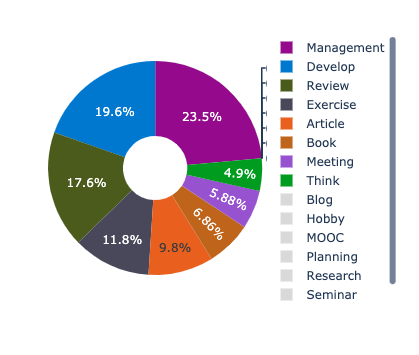
Pie Chart 는 비율을 보는 용도로 사용이 됩니다. 위의 Daily Schedule과 함께 하루에 어떤 작업을 위주로 하였는지 알 수가 있죠. 여기서 비율은 작업의 시간을 기준으로 합니다.
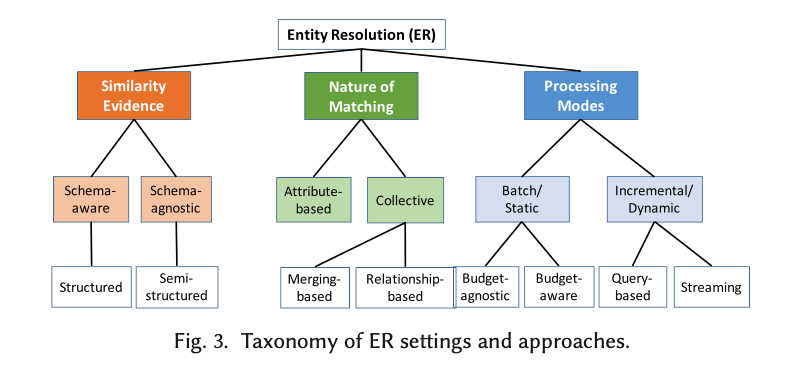
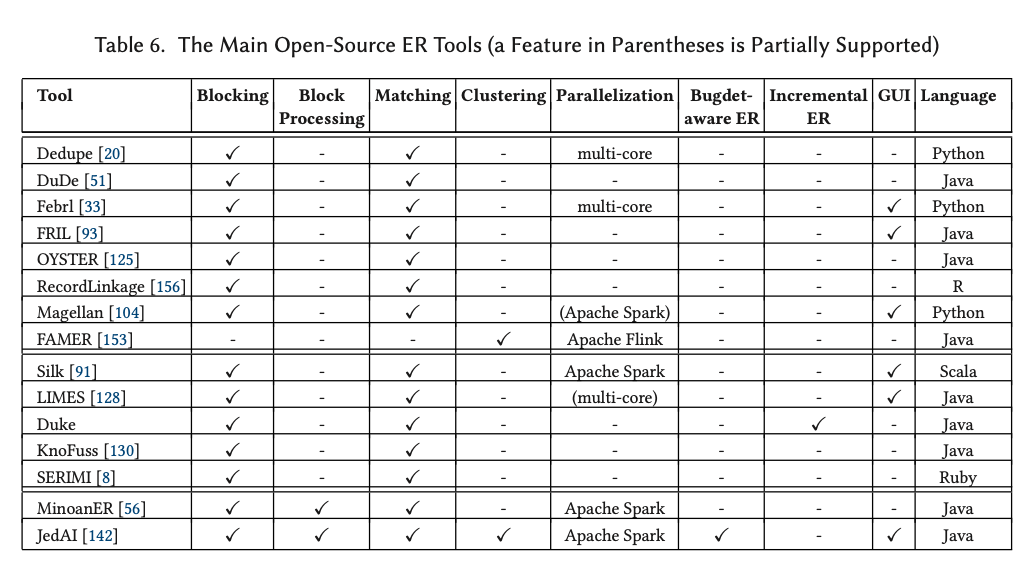
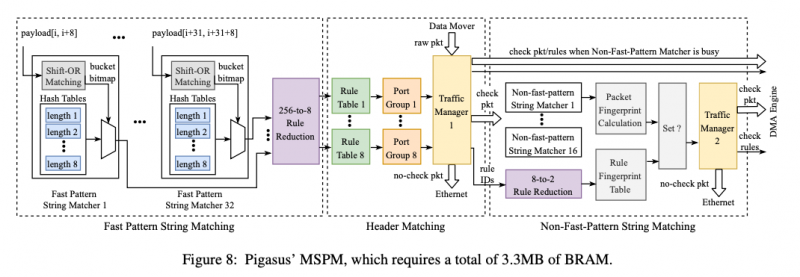
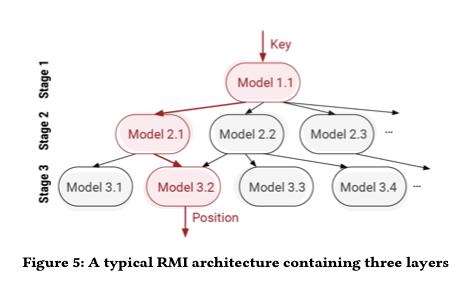
Daily Habit
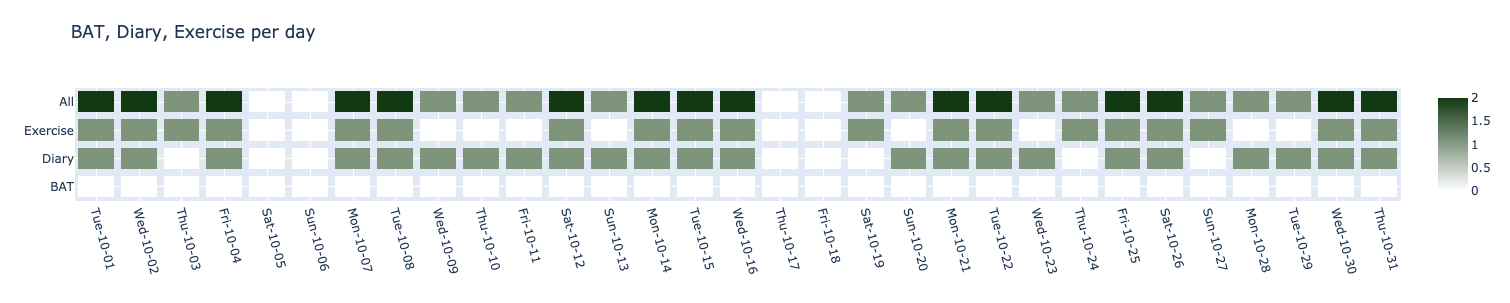
습관은 Heatmap 을 사용합니다. 보통 히트맵은 색상으로 각 데이터의 수를 표현할 때, 많이 사용합니다. 습관을 나타냄에 있어서 히트맵을 사용한 이유는 사실 단순합니다. Github의 개인 Contribution Chart와 같은 컨셉으로 만들고 싶었기 때문입니다.
이와 같이 만든 이유는 ‘일일커밋’ 때문입니다. 하루하루 꾸준히 커밋을 하는 것 역시 습관이라고 말할 수 있습니다. 위의 네모칸을 초록색으로 꽉 채우는 것이 습관을 잘 지켜 나가고 있다는 것을 보여줄 것입니다. 위 이미지의 기간 때에는 일기는 꾸준히 쓰지만, 운동은 중간중간 쉴때가 있고, BAT(공부한 것 정리)는 목표만 있지 실행되지 않던 때 이네요.
- 참고) Github Contribution Chart
이미지 출처: https://github.com/jbranchaud/commitart
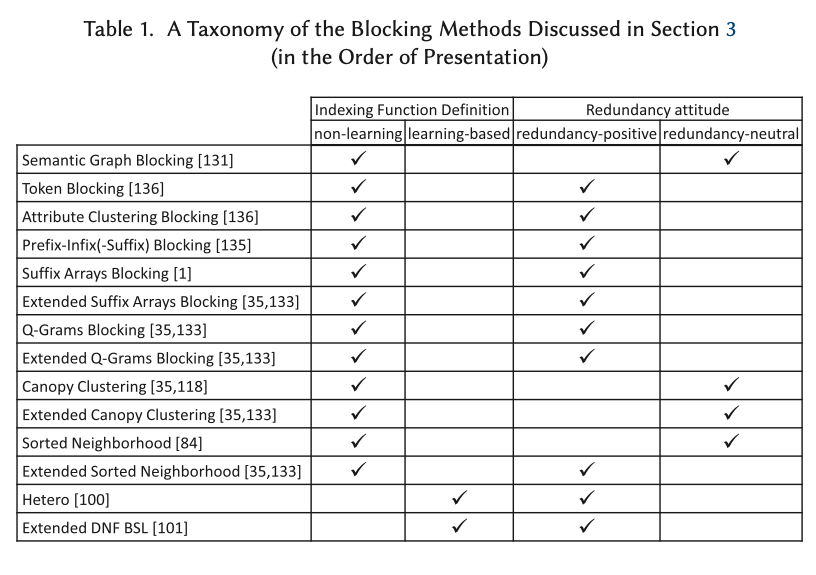
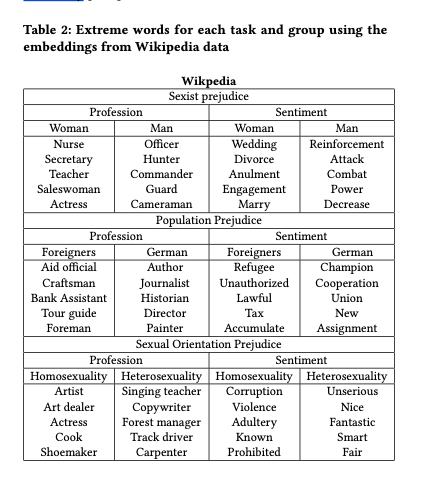
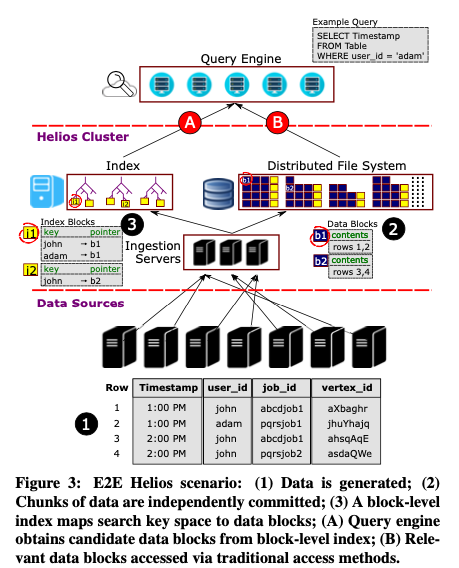
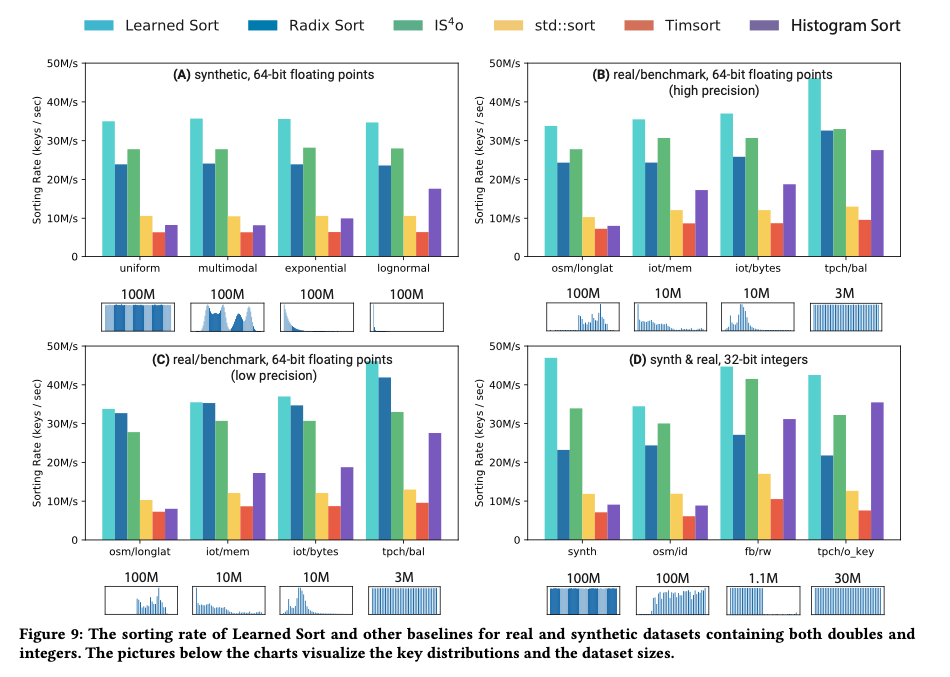
Daily Summary
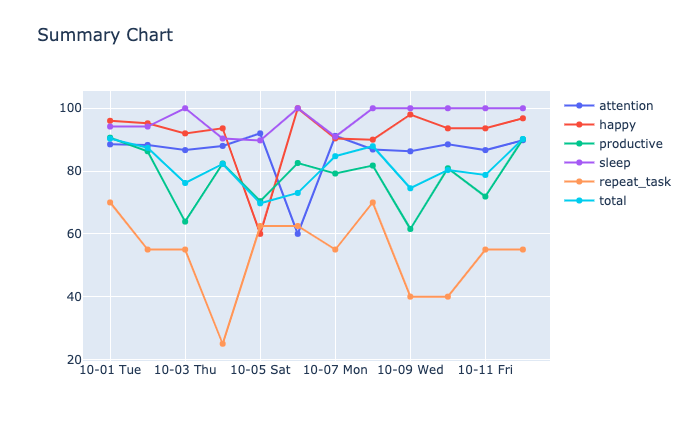
각 날짜 별로 summary 에 포함되어 있는 점수들이 Line Chart 로 표현이 됩니다. 이 값들을 통해서 어떤 것이 잘 지켜지고 있고, 아닌지 점수로서 확인을 할 수 있습니다. 간단하게 보았을 때, repeat_task 의 점수가 보통 가장 낮은 점수를 받고 있음을 알 수 있습니다. 보통 이 차트를 부면서 ‘가장 부족한 부분을 하나씩 끌어올려야겠다.’ 고 자신을 푸쉬하게 됩니다.
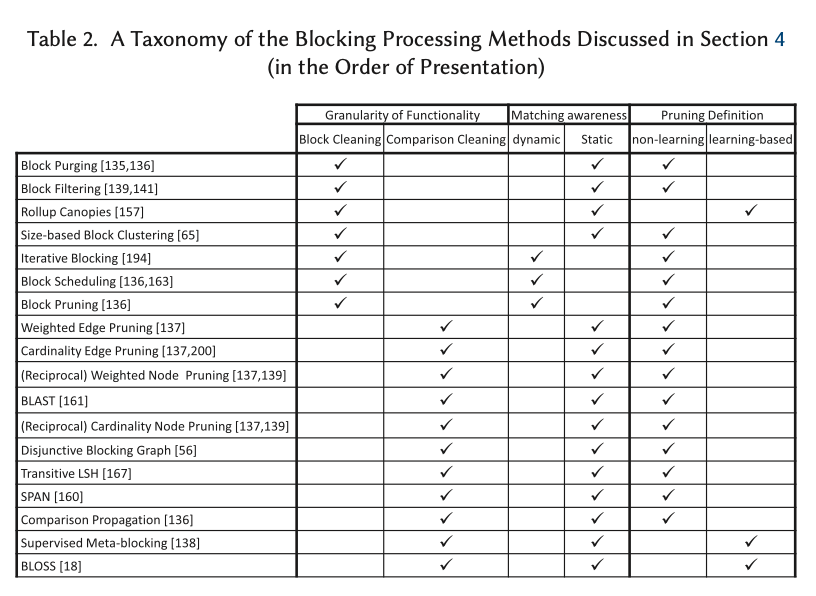
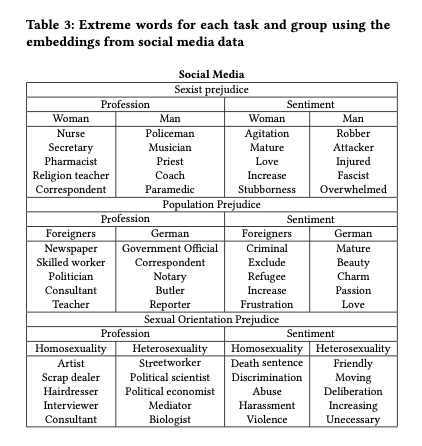
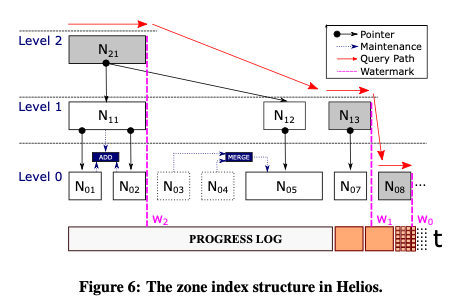
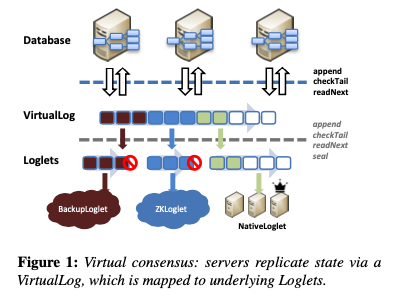
Task Report (Daily/Weekly)
하루 혹은 일주일을 기준으로 진행한 Task들을 Stacked Bar Chart 로 시각화합니다.
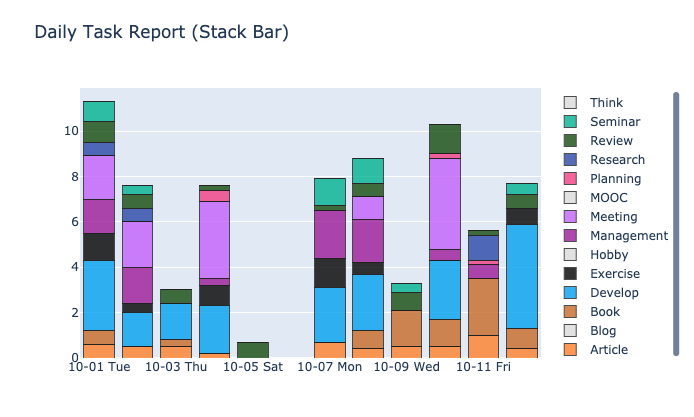
이러한 누적막대 그래프는 기준에 따라서 (하루 혹은 월요일~일요일까지의 일주일)의 시간 총량을 알 수 있으며, 각 카테고리 별 시간의 합 그리고 각각의 날들을 비교하기에 좋은 시각화 방식입니다. 위의 차트를 보았을 때, 미팅을 몰아서 하려는 성향과 개발에 대한 시간이 꾸준하게 포함되는 것을 확인할 수 있습니다.
주요 성과지표 관리 (KPI)
위의 각각의 차트들은 실제로 제가 어떻게 생활을 해왔는지에 대해서 시각적으로 말을 해주게 됩니다. 하지만 이 차트들은 바로 보자마자 1) 하루를 생산적으로 보냈는지, 2) 습관으로 만드려고 하는 목표들이 제대로 지켜지고 있는지 명확하게 말해주지 않습니다. 예를 들어, ‘일주일에 5시간 이상은 책을 읽겠다’ 라는 목표를 확인하기 위해서는 주간 Task Report 에서 Book 카테고리의 시간을 직접 확인해봐야 합니다. 그래서 위의 시각화와는 별개로 주요 성과지표를 명확하게 확인할 수 있는 대쉬보드를 따로 개발하였습니다.
먼저 성과의 기준을 가지고 있는 kpi.json 파일이 있습니다.
{
"daily": {
"task_hour": [5, 8],
"exercise": ["X", "O"],
...
},
"weekly": {
"book": [2.5, 5],
...
}
}
기준은 단순합니다. 각각의 항목에 대해서 왼쪽은 숫자의 경우 최소값, 오른쪽은 목표로 하는 수치입니다. 위의 값을 예시로 든다면, daily.task_hour 의 경우는 ‘최소 5시간 에서 최대 8시간 정도를 작업에 사용하라’ 는 지표를 의미하게 됩니다. 숫자가 아닌 daily.exercise 의 경우에는 운동을 안 했으면 X, 했으면 O로 인식이 될 것입니다. 이렇게 스스로 정한 KPI 에 맞춰서 대쉬보드가 제대로 하고 있는지 보여줍니다.

위의 보는 것처럼, Task Hour는 8시간을 넘어서 KPI를 달성했으므로 초록색으로, Diary의 경우는 아직 진행하지 않았기 때문에 빨간색으로 경고를 주고 있습니다. 위 대쉬보드는 Daily(하루 기준) 예시로서 Weekly(일주일 기준) 에서는 각 Task의 종류 별로 시간을 다루고 습니다. 예를 들어, KPI 첫 문단에서 이야기한 ‘일주일에 책 5시간은 보기’ 이러한 목표를 Weekly 대쉬보드로 확인할 수 있는 것입니다.
끝으로
그 동안 QS 프로젝트를 진행하면서, 데이터를 계속해서 모으고 있었습니다. 하지만 이 데이터들을 2020-08-07.json 과 같이 단순 텍스트 저장되어 있기 때문에 문제점을 정확하게 파악하고 있지 못했습니다. 대쉬보드를 만들면서 다양한 시각화 차트들을 그려보고 나니 실체가 적나라하게 보이는 느낌이였습니다. 이때 생산성 높은 생활패턴을 만드는 것과는 거리가 멀게 행동하고 있음을 알 수 있었습니다. 이것이 저에게는 데이터의 패턴을 변화시키는 자극제가 되어주었습니다. (물론, 계속해서 대쉬보드를 보다보면, 이것 또한 자극이 없어질 수도 있습니다..!) 글의 시작에서 이야기한 것처럼, 문제를 해결하기 위해서는 제대로 문제를 이해하는 것이 중요함을 다시 한 번 강조하고 싶습니다.
다음 포스트에서는 이 프로젝트의 1차 정리로서, 목표로 해왔던 ‘좋은 습관 만들기’ 에 대해서 지금까지의 데이터를 기반으로 정리해보려고 합니다.